mirror of
https://github.com/paperless-ngx/paperless-ngx.git
synced 2026-02-09 23:49:29 -06:00
Merge branch 'master' of https://github.com/danielquinn/paperless into disable_login
This commit is contained in:
@@ -2,7 +2,7 @@ language: python
|
|||||||
|
|
||||||
before_install:
|
before_install:
|
||||||
- sudo apt-get update -qq
|
- sudo apt-get update -qq
|
||||||
- sudo apt-get install -qq libpoppler-cpp-dev
|
- sudo apt-get install -qq libpoppler-cpp-dev unpaper tesseract-ocr tesseract-ocr-eng
|
||||||
|
|
||||||
sudo: false
|
sudo: false
|
||||||
|
|
||||||
|
|||||||
@@ -45,3 +45,4 @@ WORKDIR /usr/src/paperless/src
|
|||||||
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume", "/export"]
|
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume", "/export"]
|
||||||
ENTRYPOINT ["/sbin/docker-entrypoint.sh"]
|
ENTRYPOINT ["/sbin/docker-entrypoint.sh"]
|
||||||
CMD ["--help"]
|
CMD ["--help"]
|
||||||
|
|
||||||
|
|||||||
70
README.md
Normal file
70
README.md
Normal file
@@ -0,0 +1,70 @@
|
|||||||
|
# Paperless
|
||||||
|
|
||||||
|
  
|
||||||
|
|
||||||
|
Index and archive all of your scanned paper documents
|
||||||
|
|
||||||
|
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||||
|
|
||||||
|
* There's no search feature
|
||||||
|
* It takes up physical space
|
||||||
|
* Backups mean more paper
|
||||||
|
|
||||||
|
In the past few months I've been bitten more than a few times by the problem of not having the right document around. Sometimes I recycled a document I needed (who keeps water bills for two years?) and other times I just lost it... because paper. I wrote this to make my life easier.
|
||||||
|
|
||||||
|
|
||||||
|
## How it Works
|
||||||
|
|
||||||
|
Paperless does not control your scanner, it only helps you deal with what your scanner produces
|
||||||
|
|
||||||
|
1. Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the [scanner recommendations](https://paperless.readthedocs.io/en/latest/scanners.html) page.
|
||||||
|
2. Set it up to "scan to FTP" or something similar. It should be able to push scanned images to a server without you having to do anything. Of course if your scanner doesn't know how to automatically upload the file somewhere, you can always do that manually. Paperless doesn't care how the documents get into its local consumption directory.
|
||||||
|
3. Have the target server run the Paperless consumption script to OCR the file and index it into a local database.
|
||||||
|
4. Use the web frontend to sift through the database and find what you want.
|
||||||
|
5. Download the PDF you need/want via the web interface and do whatever you like with it. You can even print it and send it as if it's the original. In most cases, no one will care or notice.
|
||||||
|
|
||||||
|
Here's what you get:
|
||||||
|
|
||||||
|
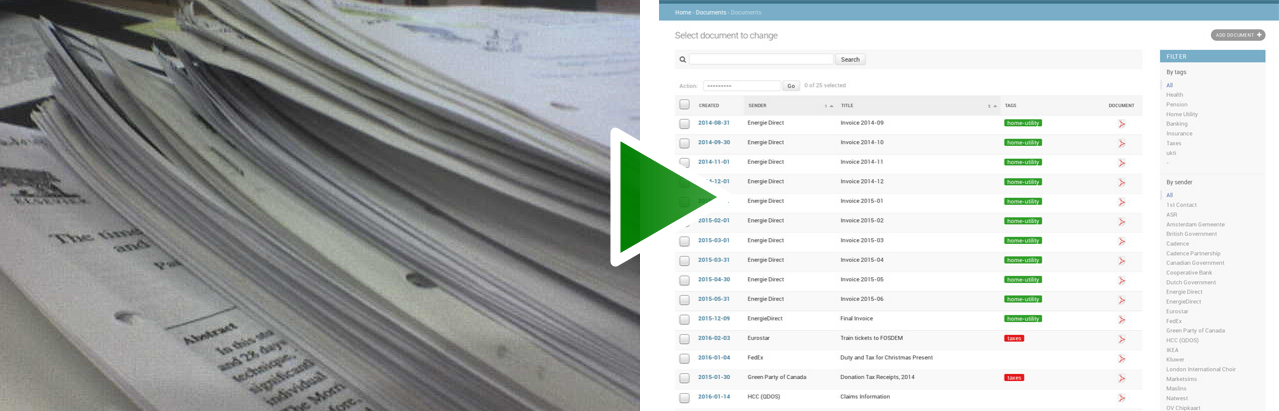
|
||||||
|
|
||||||
|
|
||||||
|
## Documentation
|
||||||
|
|
||||||
|
It's all available on [ReadTheDocs](https://paperless.readthedocs.org/).
|
||||||
|
|
||||||
|
|
||||||
|
## Requirements
|
||||||
|
|
||||||
|
This is all really a quite simple, shiny, user-friendly wrapper around some very powerful tools.
|
||||||
|
|
||||||
|
* [ImageMagick](http://imagemagick.org/) converts the images between colour and greyscale.
|
||||||
|
* [Tesseract](https://github.com/tesseract-ocr) does the character recognition.
|
||||||
|
* [Unpaper](https://www.flameeyes.eu/projects/unpaper) despeckles and deskews the scanned image.
|
||||||
|
* [GNU Privacy Guard](https://gnupg.org/) is used as the encryption backend.
|
||||||
|
* [Python 3](https://python.org/) is the language of the project.
|
||||||
|
* [Pillow](https://pypi.python.org/pypi/pillowfight/) loads the image data as a python object to be used with PyOCR.
|
||||||
|
* [PyOCR](https://github.com/jflesch/pyocr) is a slick programmatic wrapper around tesseract.
|
||||||
|
* [Django](https://www.djangoproject.com/) is the framework this project is written against.
|
||||||
|
* [Python-GNUPG](http://pythonhosted.org/python-gnupg/) decrypts the PDFs on-the-fly to allow you to download unencrypted files, leaving the encrypted ones on-disk.
|
||||||
|
|
||||||
|
|
||||||
|
## Stability
|
||||||
|
|
||||||
|
This project has been around since 2015, and there's lots of people using it, however it's still under active development (just look at the git commit history) so don't expect it to be 100% stable. You can backup the sqlite3 database, media directory and your configuration file to be on the safe side.
|
||||||
|
|
||||||
|
|
||||||
|
## Similar Projects
|
||||||
|
|
||||||
|
There's another project out there called [Mayan EDMS](https://mayan.readthedocs.org/en/latest/) that has a surprising amount of technical overlap with Paperless. Also based on Django and using a consumer model with Tesseract and Unpaper, Mayan EDMS is *much* more featureful and comes with a slick UI as well, but still in Python 2. It may be that Paperless consumes fewer resources, but to be honest, this is just a guess as I haven't tested this myself. One thing's for certain though, *Paperless* is a **way** better name.
|
||||||
|
|
||||||
|
|
||||||
|
## Important Note
|
||||||
|
|
||||||
|
Document scanners are typically used to scan sensitive documents. Things like your social insurance number, tax records, invoices, etc. While Paperless encrypts the original files via the consumption script, the OCR'd text is *not* encrypted and is therefore stored in the clear (it needs to be searchable, so if someone has ideas on how to do that on encrypted data, I'm all ears). This means that Paperless should never be run on an untrusted host. Instead, I recommend that if you do want to use it, run it locally on a server in your own home.
|
||||||
|
|
||||||
|
|
||||||
|
## Donations
|
||||||
|
|
||||||
|
As with all Free software, the power is less in the finances and more in the collective efforts. I really appreciate every pull request and bug report offered up by Paperless' users, so please keep that stuff coming. If however, you're not one for coding/design/documentation, and would like to contribute financially, I won't say no ;-)
|
||||||
|
|
||||||
|
The thing is, I'm doing ok for money, so I would instead ask you to donate to the [United Nations High Commissioner for Refugees](https://donate.unhcr.org/int-en/general). They're doing important work and they need the money a lot more than I do.
|
||||||
140
README.rst
140
README.rst
@@ -1,140 +0,0 @@
|
|||||||
Paperless
|
|
||||||
#########
|
|
||||||
|
|
||||||
|Documentation|
|
|
||||||
|Chat|
|
|
||||||
|Travis|
|
|
||||||
|
|
||||||
Index and archive all of your scanned paper documents
|
|
||||||
|
|
||||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
|
||||||
|
|
||||||
* There's no search feature
|
|
||||||
* It takes up physical space
|
|
||||||
* Backups mean more paper
|
|
||||||
|
|
||||||
In the past few months I've been bitten more than a few times by the problem
|
|
||||||
of not having the right document around. Sometimes I recycled a document I
|
|
||||||
needed (who keeps water bills for two years?) and other times I just lost
|
|
||||||
it... because paper. I wrote this to make my life easier.
|
|
||||||
|
|
||||||
|
|
||||||
How it Works
|
|
||||||
============
|
|
||||||
|
|
||||||
Paperless does not control your scanner, it only helps you deal with what your
|
|
||||||
scanner produces
|
|
||||||
|
|
||||||
1. Buy a document scanner that can write to a place on your network. If you
|
|
||||||
need some inspiration, have a look at the `scanner recommendations`_ page.
|
|
||||||
2. Set it up to "scan to FTP" or something similar. It should be able to push
|
|
||||||
scanned images to a server without you having to do anything. Of course if
|
|
||||||
your scanner doesn't know how to automatically upload the file somewhere,
|
|
||||||
you can always do that manually. Paperless doesn't care how the documents
|
|
||||||
get into its local consumption directory.
|
|
||||||
3. Have the target server run the Paperless consumption script to OCR the file
|
|
||||||
and index it into a local database.
|
|
||||||
4. Use the web frontend to sift through the database and find what you want.
|
|
||||||
5. Download the PDF you need/want via the web interface and do whatever you
|
|
||||||
like with it. You can even print it and send it as if it's the original.
|
|
||||||
In most cases, no one will care or notice.
|
|
||||||
|
|
||||||
Here's what you get:
|
|
||||||
|
|
||||||
.. image:: docs/_static/screenshot.png
|
|
||||||
:alt: The before and after
|
|
||||||
:target: docs/_static/screenshot.png
|
|
||||||
|
|
||||||
|
|
||||||
Stability
|
|
||||||
=========
|
|
||||||
|
|
||||||
Paperless is still under active development (just look at the git commit
|
|
||||||
history) so don't expect it to be 100% stable. You can backup the sqlite3
|
|
||||||
database, media directory and your configuration file to be on the safe side.
|
|
||||||
|
|
||||||
|
|
||||||
Requirements
|
|
||||||
============
|
|
||||||
|
|
||||||
This is all really a quite simple, shiny, user-friendly wrapper around some
|
|
||||||
very powerful tools.
|
|
||||||
|
|
||||||
* `ImageMagick`_ converts the images between colour and greyscale.
|
|
||||||
* `Tesseract`_ does the character recognition.
|
|
||||||
* `Unpaper`_ despeckles and deskews the scanned image.
|
|
||||||
* `GNU Privacy Guard`_ is used as the encryption backend.
|
|
||||||
* `Python 3`_ is the language of the project.
|
|
||||||
|
|
||||||
* `Pillow`_ loads the image data as a python object to be used with PyOCR.
|
|
||||||
* `PyOCR`_ is a slick programmatic wrapper around tesseract.
|
|
||||||
* `Django`_ is the framework this project is written against.
|
|
||||||
* `Python-GNUPG`_ decrypts the PDFs on-the-fly to allow you to download
|
|
||||||
unencrypted files, leaving the encrypted ones on-disk.
|
|
||||||
|
|
||||||
|
|
||||||
Documentation
|
|
||||||
=============
|
|
||||||
|
|
||||||
It's all available on `ReadTheDocs`_.
|
|
||||||
|
|
||||||
|
|
||||||
Similar Projects
|
|
||||||
================
|
|
||||||
|
|
||||||
There's another project out there called `Mayan EDMS`_ that has a surprising
|
|
||||||
amount of technical overlap with Paperless. Also based on Django and using
|
|
||||||
a consumer model with Tesseract and Unpaper, Mayan EDMS is *much* more
|
|
||||||
featureful and comes with a slick UI as well, but still in Python 2. It may be
|
|
||||||
that Paperless consumes fewer resources, but to be honest, this is just a guess
|
|
||||||
as I haven't tested this myself. One thing's for certain though, *Paperless*
|
|
||||||
is a **much** better name.
|
|
||||||
|
|
||||||
|
|
||||||
Important Note
|
|
||||||
==============
|
|
||||||
|
|
||||||
Document scanners are typically used to scan sensitive documents. Things like
|
|
||||||
your social insurance number, tax records, invoices, etc. While Paperless
|
|
||||||
encrypts the original files via the consumption script, the OCR'd text is *not*
|
|
||||||
encrypted and is therefore stored in the clear (it needs to be searchable, so
|
|
||||||
if someone has ideas on how to do that on encrypted data, I'm all ears). This
|
|
||||||
means that Paperless should never be run on an untrusted host. Instead, I
|
|
||||||
recommend that if you do want to use it, run it locally on a server in your own
|
|
||||||
home.
|
|
||||||
|
|
||||||
|
|
||||||
Donations
|
|
||||||
=========
|
|
||||||
|
|
||||||
As with all Free software, the power is less in the finances and more in the
|
|
||||||
collective efforts. I really appreciate every pull request and bug report
|
|
||||||
offered up by Paperless' users, so please keep that stuff coming. If however,
|
|
||||||
you're not one for coding/design/documentation, and would like to contribute
|
|
||||||
financially, I won't say no ;-)
|
|
||||||
|
|
||||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to
|
|
||||||
the `United Nations High Commissioner for Refugees`_. They're doing important
|
|
||||||
work and they need the money a lot more than I do.
|
|
||||||
|
|
||||||
.. _scanner recommendations: https://paperless.readthedocs.io/en/latest/scanners.html
|
|
||||||
.. _ImageMagick: http://imagemagick.org/
|
|
||||||
.. _Tesseract: https://github.com/tesseract-ocr
|
|
||||||
.. _Unpaper: https://www.flameeyes.eu/projects/unpaper
|
|
||||||
.. _GNU Privacy Guard: https://gnupg.org/
|
|
||||||
.. _Python 3: https://python.org/
|
|
||||||
.. _Pillow: https://pypi.python.org/pypi/pillowfight/
|
|
||||||
.. _PyOCR: https://github.com/jflesch/pyocr
|
|
||||||
.. _Django: https://www.djangoproject.com/
|
|
||||||
.. _Python-GNUPG: http://pythonhosted.org/python-gnupg/
|
|
||||||
.. _ReadTheDocs: https://paperless.readthedocs.org/
|
|
||||||
.. _Mayan EDMS: https://mayan.readthedocs.org/en/latest/
|
|
||||||
.. _United Nations High Commissioner for Refugees: https://donate.unhcr.org/int-en/general
|
|
||||||
.. |Documentation| image:: https://readthedocs.org/projects/paperless/badge/?version=latest
|
|
||||||
:alt: Read the documentation at https://paperless.readthedocs.org/
|
|
||||||
:target: https://paperless.readthedocs.org/
|
|
||||||
.. |Chat| image:: https://badges.gitter.im/danielquinn/paperless.svg
|
|
||||||
:alt: Join the chat at https://gitter.im/danielquinn/paperless
|
|
||||||
:target: https://gitter.im/danielquinn/paperless?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge
|
|
||||||
.. |Travis| image:: https://travis-ci.org/danielquinn/paperless.svg?branch=master
|
|
||||||
:target: https://travis-ci.org/danielquinn/paperless
|
|
||||||
@@ -5,7 +5,10 @@ Changelog
|
|||||||
=====
|
=====
|
||||||
|
|
||||||
* New Docker image, now based on Alpine, thanks to the efforts of `addadi`_
|
* New Docker image, now based on Alpine, thanks to the efforts of `addadi`_
|
||||||
and `Pit`_.
|
and `Pit`_. This new image is dramatically smaller than the Debian-based
|
||||||
|
one, and it also has `a new home on Docker Hub`_. A proper thank-you to
|
||||||
|
`Pit`_ for hosting the image on his Docker account all this time, but after
|
||||||
|
some discussion, we decided the image needed a more *official-looking* home.
|
||||||
* `BastianPoe`_ has added the long-awaited feature to automatically skip the
|
* `BastianPoe`_ has added the long-awaited feature to automatically skip the
|
||||||
OCR step when the PDF already contains text. This can be overridden by
|
OCR step when the PDF already contains text. This can be overridden by
|
||||||
setting ``PAPERLESS_OCR_ALWAYS=YES`` either in your ``paperless.conf`` or
|
setting ``PAPERLESS_OCR_ALWAYS=YES`` either in your ``paperless.conf`` or
|
||||||
@@ -13,6 +16,9 @@ Changelog
|
|||||||
``libpoppler-cpp-dev`` to be installed. **Important**: You'll need to run
|
``libpoppler-cpp-dev`` to be installed. **Important**: You'll need to run
|
||||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||||
properly update.
|
properly update.
|
||||||
|
* `BastianPoe`_ has also contributed a monumental amount of work (`#291`_) to
|
||||||
|
solving `#158`_: setting the document creation date based on finding a date
|
||||||
|
in the document text.
|
||||||
|
|
||||||
1.1.0
|
1.1.0
|
||||||
=====
|
=====
|
||||||
@@ -346,6 +352,7 @@ Changelog
|
|||||||
.. _#146: https://github.com/danielquinn/paperless/issues/146
|
.. _#146: https://github.com/danielquinn/paperless/issues/146
|
||||||
.. _#148: https://github.com/danielquinn/paperless/pull/148
|
.. _#148: https://github.com/danielquinn/paperless/pull/148
|
||||||
.. _#150: https://github.com/danielquinn/paperless/pull/150
|
.. _#150: https://github.com/danielquinn/paperless/pull/150
|
||||||
|
.. _#158: https://github.com/danielquinn/paperless/issues/158
|
||||||
.. _#171: https://github.com/danielquinn/paperless/issues/171
|
.. _#171: https://github.com/danielquinn/paperless/issues/171
|
||||||
.. _#172: https://github.com/danielquinn/paperless/issues/172
|
.. _#172: https://github.com/danielquinn/paperless/issues/172
|
||||||
.. _#179: https://github.com/danielquinn/paperless/pull/179
|
.. _#179: https://github.com/danielquinn/paperless/pull/179
|
||||||
@@ -372,5 +379,7 @@ Changelog
|
|||||||
.. _#283: https://github.com/danielquinn/paperless/issues/283
|
.. _#283: https://github.com/danielquinn/paperless/issues/283
|
||||||
.. _#256: https://github.com/danielquinn/paperless/pull/256
|
.. _#256: https://github.com/danielquinn/paperless/pull/256
|
||||||
.. _#285: https://github.com/danielquinn/paperless/pull/285
|
.. _#285: https://github.com/danielquinn/paperless/pull/285
|
||||||
|
.. _#291: https://github.com/danielquinn/paperless/pull/291
|
||||||
|
|
||||||
.. _pipenv: https://docs.pipenv.org/
|
.. _pipenv: https://docs.pipenv.org/
|
||||||
|
.. _a new home on Docker Hub: https://hub.docker.com/r/danielquinn/paperless/
|
||||||
112
docs/extending.rst
Normal file
112
docs/extending.rst
Normal file
@@ -0,0 +1,112 @@
|
|||||||
|
.. _extending:
|
||||||
|
|
||||||
|
Extending Paperless
|
||||||
|
===================
|
||||||
|
|
||||||
|
For the most part, Paperless is monolithic, so extending it is often best
|
||||||
|
managed by way of modifying the code directly and issuing a pull request on
|
||||||
|
`GitHub`_. However, over time the project has been evolving to be a little
|
||||||
|
more "pluggable" so that users can write their own stuff that talks to it.
|
||||||
|
|
||||||
|
.. _GitHub: https://github.com/danielquinn/paperless
|
||||||
|
|
||||||
|
|
||||||
|
.. _extending-parsers:
|
||||||
|
|
||||||
|
Parsers
|
||||||
|
-------
|
||||||
|
|
||||||
|
You can leverage Paperless' consumption model to have it consume files *other*
|
||||||
|
than ones handled by default like ``.pdf``, ``.jpg``, and ``.tiff``. To do so,
|
||||||
|
you simply follow Django's convention of creating a new app, with a few key
|
||||||
|
requirements.
|
||||||
|
|
||||||
|
|
||||||
|
.. _extending-parsers-parserspy:
|
||||||
|
|
||||||
|
parsers.py
|
||||||
|
..........
|
||||||
|
|
||||||
|
In this file, you create a class that extends
|
||||||
|
``documents.parsers.DocumentParser`` and go about implementing the three
|
||||||
|
required methods:
|
||||||
|
|
||||||
|
* ``get_thumbnail()``: Returns the path to a file we can use as a thumbnail for
|
||||||
|
this document.
|
||||||
|
* ``get_text()``: Returns the text from the document and only the text.
|
||||||
|
* ``get_date()``: If possible, this returns the date of the document, otherwise
|
||||||
|
it should return ``None``.
|
||||||
|
|
||||||
|
|
||||||
|
.. _extending-parsers-signalspy:
|
||||||
|
|
||||||
|
signals.py
|
||||||
|
..........
|
||||||
|
|
||||||
|
At consumption time, Paperless emits a ``document_consumer_declaration``
|
||||||
|
signal which your module has to react to in order to let the consumer know
|
||||||
|
whether or not it's capable of handling a particular file. Think of it like
|
||||||
|
this:
|
||||||
|
|
||||||
|
1. Consumer finds a file in the consumption directory.
|
||||||
|
2. It asks all the available parsers: *"Hey, can you handle this file?"*
|
||||||
|
3. Each parser responds with either ``None`` meaning they can't handle the
|
||||||
|
file, or a dictionary in the following format:
|
||||||
|
|
||||||
|
.. code:: python
|
||||||
|
|
||||||
|
{
|
||||||
|
"parser": <the class name>,
|
||||||
|
"weight": <an integer>
|
||||||
|
}
|
||||||
|
|
||||||
|
The consumer compares the ``weight`` values from all respondents and uses the
|
||||||
|
class with the highest value to consume the document. The default parser,
|
||||||
|
``RasterisedDocumentParser`` has a weight of ``0``.
|
||||||
|
|
||||||
|
|
||||||
|
.. _extending-parsers-appspy:
|
||||||
|
|
||||||
|
apps.py
|
||||||
|
.......
|
||||||
|
|
||||||
|
This is a standard Django file, but you'll need to add some code to it to
|
||||||
|
connect your parser to the ``document_consumer_declaration`` signal.
|
||||||
|
|
||||||
|
|
||||||
|
.. _extending-parsers-finally:
|
||||||
|
|
||||||
|
Finally
|
||||||
|
.......
|
||||||
|
|
||||||
|
The last step is to update ``settings.py`` to include your new module.
|
||||||
|
Eventually, this will be dynamic, but at the moment, you have to edit the
|
||||||
|
``INSTALLED_APPS`` section manually. Simply add the path to your AppConfig to
|
||||||
|
the list like this:
|
||||||
|
|
||||||
|
.. code:: python
|
||||||
|
|
||||||
|
INSTALLED_APPS = [
|
||||||
|
...
|
||||||
|
"my_module.apps.MyModuleConfig",
|
||||||
|
...
|
||||||
|
]
|
||||||
|
|
||||||
|
Order doesn't matter, but generally it's a good idea to place your module lower
|
||||||
|
in the list so that you don't end up accidentally overriding project defaults
|
||||||
|
somewhere.
|
||||||
|
|
||||||
|
|
||||||
|
.. _extending-parsers-example:
|
||||||
|
|
||||||
|
An Example
|
||||||
|
..........
|
||||||
|
|
||||||
|
The core Paperless functionality is based on this design, so if you want to see
|
||||||
|
what a parser module should look like, have a look at `parsers.py`_,
|
||||||
|
`signals.py`_, and `apps.py`_ in the `paperless_tesseract`_ module.
|
||||||
|
|
||||||
|
.. _parsers.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/parsers.py
|
||||||
|
.. _signals.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/signals.py
|
||||||
|
.. _apps.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/apps.py
|
||||||
|
.. _paperless_tesseract: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/
|
||||||
@@ -5,9 +5,9 @@ Paperless
|
|||||||
|
|
||||||
Paperless is a simple Django application running in two parts:
|
Paperless is a simple Django application running in two parts:
|
||||||
a :ref:`consumer <utilities-consumer>` (the thing that does the indexing) and
|
a :ref:`consumer <utilities-consumer>` (the thing that does the indexing) and
|
||||||
the :ref:`webserver <utilities-webserver>` (the part that lets you search & download
|
the :ref:`webserver <utilities-webserver>` (the part that lets you search &
|
||||||
already-indexed documents). If you want to learn more about its functions keep on
|
download already-indexed documents). If you want to learn more about its
|
||||||
reading after the installation section.
|
functions keep on reading after the installation section.
|
||||||
|
|
||||||
|
|
||||||
.. _index-why-this-exists:
|
.. _index-why-this-exists:
|
||||||
@@ -16,12 +16,13 @@ Why This Exists
|
|||||||
===============
|
===============
|
||||||
|
|
||||||
Paper is a nightmare. Environmental issues aside, there's no excuse for it in
|
Paper is a nightmare. Environmental issues aside, there's no excuse for it in
|
||||||
the 21st century. It takes up space, collects dust, doesn't support any form of
|
the 21st century. It takes up space, collects dust, doesn't support any form
|
||||||
a search feature, indexing is tedious, it's heavy and prone to damage & loss.
|
of a search feature, indexing is tedious, it's heavy and prone to damage &
|
||||||
|
loss.
|
||||||
|
|
||||||
I wrote this to make "going paperless" easier. I do not have to worry about
|
I wrote this to make "going paperless" easier. I do not have to worry about
|
||||||
finding stuff again. I feed documents right from the post box into the scanner and
|
finding stuff again. I feed documents right from the post box into the scanner
|
||||||
then shred them. Perhaps you might find it useful too.
|
and then shred them. Perhaps you might find it useful too.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -39,6 +40,7 @@ Contents
|
|||||||
utilities
|
utilities
|
||||||
guesswork
|
guesswork
|
||||||
migrating
|
migrating
|
||||||
|
extending
|
||||||
troubleshooting
|
troubleshooting
|
||||||
scanners
|
scanners
|
||||||
changelog
|
changelog
|
||||||
|
|||||||
@@ -95,48 +95,6 @@ Standard (Bare Metal)
|
|||||||
.. _Paperless webserver: http://127.0.0.1:8000
|
.. _Paperless webserver: http://127.0.0.1:8000
|
||||||
|
|
||||||
|
|
||||||
.. _setup-installation-vagrant:
|
|
||||||
|
|
||||||
Vagrant Method
|
|
||||||
..............
|
|
||||||
|
|
||||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
|
||||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
|
||||||
provisioned...
|
|
||||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
|
||||||
``/etc/paperless.conf`` and set the values for:
|
|
||||||
|
|
||||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
|
||||||
dumped to be consumed by Paperless.
|
|
||||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
|
||||||
encrypt/decrypt the original document.
|
|
||||||
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
|
||||||
documents from mail or via the API. If you don't use either, leaving it
|
|
||||||
blank is just fine.
|
|
||||||
|
|
||||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
|
||||||
updates the environment to make use of the changes you made to the config
|
|
||||||
file.
|
|
||||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
|
||||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
|
||||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
|
||||||
create your user.
|
|
||||||
7. Start the webserver with
|
|
||||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
|
||||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
|
||||||
You can login with the user/pass you created in #6.
|
|
||||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
|
||||||
your vagrant instance, you should start the consumer script with
|
|
||||||
``/opt/paperless/src/manage.py document_consumer``.
|
|
||||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
|
||||||
10. Wait a few minutes
|
|
||||||
11. Visit the document list on your webserver, and it should be there, indexed
|
|
||||||
and downloadable.
|
|
||||||
|
|
||||||
.. _Vagrant: https://vagrantup.com/
|
|
||||||
.. _Paperless server: http://172.28.128.4:8000
|
|
||||||
|
|
||||||
|
|
||||||
.. _setup-installation-docker:
|
.. _setup-installation-docker:
|
||||||
|
|
||||||
Docker Method
|
Docker Method
|
||||||
@@ -295,6 +253,49 @@ Docker Method
|
|||||||
both the ``webserver`` and ``consumer`` sections to ``build: ./`` as per the
|
both the ``webserver`` and ``consumer`` sections to ``build: ./`` as per the
|
||||||
newer ``docker-compose.yml.example`` file
|
newer ``docker-compose.yml.example`` file
|
||||||
|
|
||||||
|
|
||||||
|
.. _setup-installation-vagrant:
|
||||||
|
|
||||||
|
Vagrant Method
|
||||||
|
..............
|
||||||
|
|
||||||
|
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||||
|
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||||
|
provisioned...
|
||||||
|
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||||
|
``/etc/paperless.conf`` and set the values for:
|
||||||
|
|
||||||
|
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||||
|
dumped to be consumed by Paperless.
|
||||||
|
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||||
|
encrypt/decrypt the original document.
|
||||||
|
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
||||||
|
documents from mail or via the API. If you don't use either, leaving it
|
||||||
|
blank is just fine.
|
||||||
|
|
||||||
|
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||||
|
updates the environment to make use of the changes you made to the config
|
||||||
|
file.
|
||||||
|
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||||
|
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||||
|
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||||
|
create your user.
|
||||||
|
7. Start the webserver with
|
||||||
|
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||||
|
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||||
|
You can login with the user/pass you created in #6.
|
||||||
|
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||||
|
your vagrant instance, you should start the consumer script with
|
||||||
|
``/opt/paperless/src/manage.py document_consumer``.
|
||||||
|
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||||
|
10. Wait a few minutes
|
||||||
|
11. Visit the document list on your webserver, and it should be there, indexed
|
||||||
|
and downloadable.
|
||||||
|
|
||||||
|
.. _Vagrant: https://vagrantup.com/
|
||||||
|
.. _Paperless server: http://172.28.128.4:8000
|
||||||
|
|
||||||
|
|
||||||
.. _setup-permanent:
|
.. _setup-permanent:
|
||||||
|
|
||||||
Making Things a Little more Permanent
|
Making Things a Little more Permanent
|
||||||
@@ -569,7 +570,8 @@ your gunicorn instance. This should do the trick:
|
|||||||
Vagrant
|
Vagrant
|
||||||
.......
|
.......
|
||||||
|
|
||||||
You may use the Ubuntu explanation above. Replace ``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
You may use the Ubuntu explanation above. Replace
|
||||||
|
``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||||
|
|
||||||
.. _setup-permanent-docker:
|
.. _setup-permanent-docker:
|
||||||
|
|
||||||
@@ -583,7 +585,7 @@ Docker daemon.
|
|||||||
.. _restart-policy: https://docs.docker.com/engine/reference/commandline/run/#restart-policies-restart
|
.. _restart-policy: https://docs.docker.com/engine/reference/commandline/run/#restart-policies-restart
|
||||||
|
|
||||||
|
|
||||||
.. _setup-subdirectory
|
.. _setup-subdirectory:
|
||||||
|
|
||||||
Hosting Paperless in a Subdirectory
|
Hosting Paperless in a Subdirectory
|
||||||
-----------------------------------
|
-----------------------------------
|
||||||
|
|||||||
@@ -1,5 +1,6 @@
|
|||||||
Django>=1.11,<2.0
|
Django>=1.11,<2.0
|
||||||
Pillow>=3.1.1
|
Pillow>=3.1.1
|
||||||
|
dateparser>=0.6.0
|
||||||
django-crispy-forms>=1.6.1
|
django-crispy-forms>=1.6.1
|
||||||
django-extensions>=1.7.6
|
django-extensions>=1.7.6
|
||||||
django-filter>=1.0
|
django-filter>=1.0
|
||||||
@@ -7,21 +8,21 @@ django-flat-responsive>=1.2.0
|
|||||||
djangorestframework>=3.5.3
|
djangorestframework>=3.5.3
|
||||||
filemagic>=1.6
|
filemagic>=1.6
|
||||||
fuzzywuzzy[speedup]==0.15.0
|
fuzzywuzzy[speedup]==0.15.0
|
||||||
|
gunicorn>=19.7.1
|
||||||
langdetect>=1.0.7
|
langdetect>=1.0.7
|
||||||
|
pdftotext>=2.0.1
|
||||||
pyocr>=0.4.7
|
pyocr>=0.4.7
|
||||||
python-dateutil>=2.6.0
|
python-dateutil>=2.6.0
|
||||||
python-dotenv>=0.6.2
|
python-dotenv>=0.6.2
|
||||||
python-gnupg>=0.3.9
|
python-gnupg>=0.3.9
|
||||||
pytz>=2016.10
|
pytz>=2016.10
|
||||||
gunicorn==19.7.1
|
|
||||||
pdftotext>=2.0.1
|
|
||||||
|
|
||||||
# For the tests
|
# For the tests
|
||||||
factory-boy
|
factory-boy
|
||||||
|
flake8
|
||||||
pytest==3.3.2 # Newer versions break with pytest-sugar
|
pytest==3.3.2 # Newer versions break with pytest-sugar
|
||||||
pytest-django
|
pytest-django
|
||||||
pytest-sugar
|
pytest-sugar
|
||||||
pytest-env
|
pytest-env
|
||||||
pycodestyle
|
pycodestyle
|
||||||
flake8
|
|
||||||
tox
|
tox
|
||||||
|
|||||||
@@ -118,12 +118,14 @@ class Consumer(object):
|
|||||||
|
|
||||||
parsed_document = parser_class(doc)
|
parsed_document = parser_class(doc)
|
||||||
thumbnail = parsed_document.get_thumbnail()
|
thumbnail = parsed_document.get_thumbnail()
|
||||||
|
date = parsed_document.get_date()
|
||||||
|
|
||||||
try:
|
try:
|
||||||
document = self._store(
|
document = self._store(
|
||||||
parsed_document.get_text(),
|
parsed_document.get_text(),
|
||||||
doc,
|
doc,
|
||||||
thumbnail
|
thumbnail,
|
||||||
|
date
|
||||||
)
|
)
|
||||||
except ParseError as e:
|
except ParseError as e:
|
||||||
|
|
||||||
@@ -174,7 +176,7 @@ class Consumer(object):
|
|||||||
return sorted(
|
return sorted(
|
||||||
options, key=lambda _: _["weight"], reverse=True)[0]["parser"]
|
options, key=lambda _: _["weight"], reverse=True)[0]["parser"]
|
||||||
|
|
||||||
def _store(self, text, doc, thumbnail):
|
def _store(self, text, doc, thumbnail, date):
|
||||||
|
|
||||||
file_info = FileInfo.from_path(doc)
|
file_info = FileInfo.from_path(doc)
|
||||||
|
|
||||||
@@ -182,7 +184,7 @@ class Consumer(object):
|
|||||||
|
|
||||||
self.log("debug", "Saving record to database")
|
self.log("debug", "Saving record to database")
|
||||||
|
|
||||||
created = file_info.created or timezone.make_aware(
|
created = file_info.created or date or timezone.make_aware(
|
||||||
datetime.datetime.fromtimestamp(stats.st_mtime))
|
datetime.datetime.fromtimestamp(stats.st_mtime))
|
||||||
|
|
||||||
with open(doc, "rb") as f:
|
with open(doc, "rb") as f:
|
||||||
|
|||||||
@@ -135,8 +135,10 @@ class MatchingModel(models.Model):
|
|||||||
"""
|
"""
|
||||||
findterms = re.compile(r'"([^"]+)"|(\S+)').findall
|
findterms = re.compile(r'"([^"]+)"|(\S+)').findall
|
||||||
normspace = re.compile(r"\s+").sub
|
normspace = re.compile(r"\s+").sub
|
||||||
return [normspace(r"\s+", (t[0] or t[1]).strip())
|
return [
|
||||||
for t in findterms(self.match)]
|
normspace(" ", (t[0] or t[1]).strip()).replace(" ", r"\s+")
|
||||||
|
for t in findterms(self.match)
|
||||||
|
]
|
||||||
|
|
||||||
def save(self, *args, **kwargs):
|
def save(self, *args, **kwargs):
|
||||||
|
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ class ParseError(Exception):
|
|||||||
pass
|
pass
|
||||||
|
|
||||||
|
|
||||||
class DocumentParser(object):
|
class DocumentParser:
|
||||||
"""
|
"""
|
||||||
Subclass this to make your own parser. Have a look at
|
Subclass this to make your own parser. Have a look at
|
||||||
`paperless_tesseract.parsers` for inspiration.
|
`paperless_tesseract.parsers` for inspiration.
|
||||||
@@ -19,7 +19,7 @@ class DocumentParser(object):
|
|||||||
|
|
||||||
def __init__(self, path):
|
def __init__(self, path):
|
||||||
self.document_path = path
|
self.document_path = path
|
||||||
self.tempdir = tempfile.mkdtemp(prefix="paperless", dir=self.SCRATCH)
|
self.tempdir = tempfile.mkdtemp(prefix="paperless-", dir=self.SCRATCH)
|
||||||
self.logger = logging.getLogger(__name__)
|
self.logger = logging.getLogger(__name__)
|
||||||
self.logging_group = None
|
self.logging_group = None
|
||||||
|
|
||||||
@@ -35,6 +35,12 @@ class DocumentParser(object):
|
|||||||
"""
|
"""
|
||||||
raise NotImplementedError()
|
raise NotImplementedError()
|
||||||
|
|
||||||
|
def get_date(self):
|
||||||
|
"""
|
||||||
|
Returns the date of the document.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError()
|
||||||
|
|
||||||
def log(self, level, message):
|
def log(self, level, message):
|
||||||
getattr(self.logger, level)(message, extra={
|
getattr(self.logger, level)(message, extra={
|
||||||
"group": self.logging_group
|
"group": self.logging_group
|
||||||
|
|||||||
@@ -30,15 +30,8 @@ from .serialisers import (
|
|||||||
|
|
||||||
|
|
||||||
class IndexView(TemplateView):
|
class IndexView(TemplateView):
|
||||||
|
|
||||||
template_name = "documents/index.html"
|
template_name = "documents/index.html"
|
||||||
|
|
||||||
def get_context_data(self, **kwargs):
|
|
||||||
print(kwargs)
|
|
||||||
print(self.request.GET)
|
|
||||||
print(self.request.POST)
|
|
||||||
return TemplateView.get_context_data(self, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class FetchView(SessionOrBasicAuthMixin, DetailView):
|
class FetchView(SessionOrBasicAuthMixin, DetailView):
|
||||||
|
|
||||||
|
|||||||
@@ -270,3 +270,6 @@ PAPERLESS_LIST_PER_PAGE = int(os.getenv("PAPERLESS_LIST_PER_PAGE", 100))
|
|||||||
|
|
||||||
FY_START = os.getenv("PAPERLESS_FINANCIAL_YEAR_START")
|
FY_START = os.getenv("PAPERLESS_FINANCIAL_YEAR_START")
|
||||||
FY_END = os.getenv("PAPERLESS_FINANCIAL_YEAR_END")
|
FY_END = os.getenv("PAPERLESS_FINANCIAL_YEAR_END")
|
||||||
|
|
||||||
|
# Specify the default date order (for autodetected dates)
|
||||||
|
DATE_ORDER = os.getenv("PAPERLESS_DATE_ORDER", "DMY")
|
||||||
|
|||||||
@@ -3,6 +3,7 @@ import os
|
|||||||
import re
|
import re
|
||||||
import subprocess
|
import subprocess
|
||||||
from multiprocessing.pool import Pool
|
from multiprocessing.pool import Pool
|
||||||
|
import dateparser
|
||||||
import pdftotext
|
import pdftotext
|
||||||
|
|
||||||
import langdetect
|
import langdetect
|
||||||
@@ -31,8 +32,10 @@ class RasterisedDocumentParser(DocumentParser):
|
|||||||
DENSITY = settings.CONVERT_DENSITY if settings.CONVERT_DENSITY else 300
|
DENSITY = settings.CONVERT_DENSITY if settings.CONVERT_DENSITY else 300
|
||||||
THREADS = int(settings.OCR_THREADS) if settings.OCR_THREADS else None
|
THREADS = int(settings.OCR_THREADS) if settings.OCR_THREADS else None
|
||||||
UNPAPER = settings.UNPAPER_BINARY
|
UNPAPER = settings.UNPAPER_BINARY
|
||||||
|
DATE_ORDER = settings.DATE_ORDER
|
||||||
DEFAULT_OCR_LANGUAGE = settings.OCR_LANGUAGE
|
DEFAULT_OCR_LANGUAGE = settings.OCR_LANGUAGE
|
||||||
OCR_ALWAYS = settings.OCR_ALWAYS
|
OCR_ALWAYS = settings.OCR_ALWAYS
|
||||||
|
TEXT_CACHE = None
|
||||||
|
|
||||||
def get_thumbnail(self):
|
def get_thumbnail(self):
|
||||||
"""
|
"""
|
||||||
@@ -60,15 +63,20 @@ class RasterisedDocumentParser(DocumentParser):
|
|||||||
return False
|
return False
|
||||||
|
|
||||||
def get_text(self):
|
def get_text(self):
|
||||||
|
if self.TEXT_CACHE is not None:
|
||||||
|
return self.TEXT_CACHE
|
||||||
|
|
||||||
if not self.OCR_ALWAYS and self._is_ocred():
|
if not self.OCR_ALWAYS and self._is_ocred():
|
||||||
self.log("info", "Skipping OCR, using Text from PDF")
|
self.log("info", "Skipping OCR, using Text from PDF")
|
||||||
return get_text_from_pdf(self.document_path)
|
self.TEXT_CACHE = get_text_from_pdf(self.document_path)
|
||||||
|
return self.TEXT_CACHE
|
||||||
|
|
||||||
images = self._get_greyscale()
|
images = self._get_greyscale()
|
||||||
|
|
||||||
try:
|
try:
|
||||||
|
|
||||||
return self._get_ocr(images)
|
self.TEXT_CACHE = self._get_ocr(images)
|
||||||
|
return self.TEXT_CACHE
|
||||||
except OCRError as e:
|
except OCRError as e:
|
||||||
raise ParseError(e)
|
raise ParseError(e)
|
||||||
|
|
||||||
@@ -191,6 +199,29 @@ class RasterisedDocumentParser(DocumentParser):
|
|||||||
text += self._ocr(imgs[middle + 1:], self.DEFAULT_OCR_LANGUAGE)
|
text += self._ocr(imgs[middle + 1:], self.DEFAULT_OCR_LANGUAGE)
|
||||||
return text
|
return text
|
||||||
|
|
||||||
|
def get_date(self):
|
||||||
|
text = self.get_text()
|
||||||
|
|
||||||
|
# This regular expression will try to find dates in the document at
|
||||||
|
# hand and will match the following formats:
|
||||||
|
# - XX.YY.ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||||
|
# - XX/YY/ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||||
|
# - XX-YY-ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||||
|
# - XX. MONTH ZZZZ with XX being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||||
|
# - MONTH ZZZZ
|
||||||
|
m = re.search(
|
||||||
|
r'\b([0-9]{1,2})[\.\/-]([0-9]{1,2})[\.\/-]([0-9]{4}|[0-9]{2})\b|' +
|
||||||
|
r'\b([0-9]{1,2}\. [^ ]{3,9} ([0-9]{4}|[0-9]{2}))\b|' +
|
||||||
|
r'\b([^ ]{3,9} [0-9]{4})\b', text)
|
||||||
|
|
||||||
|
if m is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
return dateparser.parse(m.group(0),
|
||||||
|
settings={'DATE_ORDER': self.DATE_ORDER,
|
||||||
|
'PREFER_DAY_OF_MONTH': 'first',
|
||||||
|
'RETURN_AS_TIMEZONE_AWARE': True})
|
||||||
|
|
||||||
|
|
||||||
def run_convert(*args):
|
def run_convert(*args):
|
||||||
|
|
||||||
@@ -235,6 +266,6 @@ def get_text_from_pdf(pdf_file):
|
|||||||
try:
|
try:
|
||||||
pdf = pdftotext.PDF(f)
|
pdf = pdftotext.PDF(f)
|
||||||
except pdftotext.Error:
|
except pdftotext.Error:
|
||||||
return False
|
return ""
|
||||||
|
|
||||||
return "\n".join(pdf)
|
return "\n".join(pdf)
|
||||||
|
|||||||
@@ -3,7 +3,7 @@ import re
|
|||||||
from .parsers import RasterisedDocumentParser
|
from .parsers import RasterisedDocumentParser
|
||||||
|
|
||||||
|
|
||||||
class ConsumerDeclaration(object):
|
class ConsumerDeclaration:
|
||||||
|
|
||||||
MATCHING_FILES = re.compile("^.*\.(pdf|jpe?g|gif|png|tiff?|pnm|bmp)$")
|
MATCHING_FILES = re.compile("^.*\.(pdf|jpe?g|gif|png|tiff?|pnm|bmp)$")
|
||||||
|
|
||||||
|
|||||||
BIN
src/paperless_tesseract/tests/samples/tests_date_1.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_1.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_1.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_1.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_2.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_2.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_2.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_2.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 135 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_3.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_3.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_3.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_3.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 138 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_4.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_4.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_4.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_4.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 138 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_5.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_5.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_5.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_5.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_6.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_6.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_6.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_6.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_7.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_7.pdf
Normal file
Binary file not shown.
215
src/paperless_tesseract/tests/test_date.py
Normal file
215
src/paperless_tesseract/tests/test_date.py
Normal file
@@ -0,0 +1,215 @@
|
|||||||
|
import datetime
|
||||||
|
import os
|
||||||
|
import shutil
|
||||||
|
from unittest import mock
|
||||||
|
from uuid import uuid4
|
||||||
|
|
||||||
|
from dateutil import tz
|
||||||
|
from django.test import TestCase
|
||||||
|
|
||||||
|
from ..parsers import RasterisedDocumentParser
|
||||||
|
|
||||||
|
|
||||||
|
class TestDate(TestCase):
|
||||||
|
|
||||||
|
SAMPLE_FILES = os.path.join(os.path.dirname(__file__), "samples")
|
||||||
|
SCRATCH = "/tmp/paperless-tests-{}".format(str(uuid4())[:8])
|
||||||
|
|
||||||
|
def setUp(self):
|
||||||
|
os.makedirs(self.SCRATCH, exist_ok=True)
|
||||||
|
|
||||||
|
def tearDown(self):
|
||||||
|
shutil.rmtree(self.SCRATCH)
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_1_pdf(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_1.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 4, 1, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_1_png(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_1.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 4, 1, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_2_pdf(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_2.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2013, 2, 1, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_2_png(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_2.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2013, 2, 1, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_3_pdf(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_3.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 10, 5, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_3_png(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_3.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 10, 5, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_4_pdf(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_4.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 10, 5, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_4_png(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_4.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 10, 5, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_5_pdf(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_5.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 12, 17, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_5_png(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_5.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 12, 17, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_6_pdf_us(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
document.DATE_ORDER = "MDY"
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 12, 17, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_6_png_us(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
document.DATE_ORDER = "MDY"
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 12, 17, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_6_pdf_eu(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(), None)
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_6_png_eu(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.png")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), False)
|
||||||
|
self.assertEqual(document.get_date(), None)
|
||||||
|
|
||||||
|
@mock.patch(
|
||||||
|
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||||
|
SCRATCH
|
||||||
|
)
|
||||||
|
def test_get_text_7_pdf(self):
|
||||||
|
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_7.pdf")
|
||||||
|
document = RasterisedDocumentParser(input_file)
|
||||||
|
document.get_text()
|
||||||
|
self.assertEqual(document._is_ocred(), True)
|
||||||
|
self.assertEqual(document.get_date(),
|
||||||
|
datetime.datetime(2018, 4, 1, 0, 0,
|
||||||
|
tzinfo=tz.tzutc()))
|
||||||
Reference in New Issue
Block a user