Compare commits
264 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
805e3d51e8 | ||
|
|
f1f9a076c9 | ||
|
|
55cc49cd88 | ||
|
|
d52260468c | ||
|
|
aacd362203 | ||
|
|
38a651c42a | ||
|
|
55cc93e5e9 | ||
|
|
9ee21f081f | ||
|
|
bfbdd6e198 | ||
|
|
1e9e347f15 | ||
|
|
782dbee3a0 | ||
|
|
316ee72177 | ||
|
|
f88cf69173 | ||
|
|
e9758d5224 | ||
|
|
5456d5eafa | ||
|
|
dab4b1253a | ||
|
|
34bc4020c9 | ||
|
|
ab871d67fc | ||
|
|
371745b6dc | ||
|
|
991a46c4f0 | ||
|
|
eb5bdc48aa | ||
|
|
3634dfbcf8 | ||
|
|
57ad485913 | ||
|
|
ceaade29a6 | ||
|
|
9a4d410f66 | ||
|
|
34f353f399 | ||
|
|
1d8765100c | ||
|
|
5bdb57a392 | ||
|
|
0a18c819d4 | ||
|
|
982ea84906 | ||
|
|
68c233005e | ||
|
|
62cc4a7a54 | ||
|
|
6d3e5b0a1b | ||
|
|
c4d13b5802 | ||
|
|
c263d8e8f1 | ||
|
|
2a9e6f7a58 | ||
|
|
c02813623d | ||
|
|
1b5b07a020 | ||
|
|
8b16cd99dc | ||
|
|
20fc065567 | ||
|
|
802e389198 | ||
|
|
72a4ff0fca | ||
|
|
e22769ca63 | ||
|
|
d661f87f63 | ||
|
|
748b27c680 | ||
|
|
6a04e95f69 | ||
|
|
9e9b9ae631 | ||
|
|
a47623dbaf | ||
|
|
657c41ab37 | ||
|
|
4548cf08c7 | ||
|
|
e3ce573fbb | ||
|
|
5e1543bad5 | ||
|
|
282e6f453f | ||
|
|
a4f60c48ea | ||
|
|
f3f5227776 | ||
|
|
19bb29d5cd | ||
|
|
8cad12b154 | ||
|
|
384d381acf | ||
|
|
834352130c | ||
|
|
b0c8ade241 | ||
|
|
a33082235b | ||
|
|
ec6d01f7a5 | ||
|
|
1ce6466ef8 | ||
|
|
f677ed8798 | ||
|
|
12fa844c7f | ||
|
|
fd3df1ec58 | ||
|
|
24b8c358cc | ||
|
|
d58706a34b | ||
|
|
3168602610 | ||
|
|
756c80690d | ||
|
|
c5dbd7a6fb | ||
|
|
9318c2c0bc | ||
|
|
e431a658cc | ||
|
|
b97fa9e3b9 | ||
|
|
1b0ddd6df6 | ||
|
|
8a5c782425 | ||
|
|
aaa6599283 | ||
|
|
daf54a334f | ||
|
|
183d432f84 | ||
|
|
e1853583b0 | ||
|
|
f156f05b37 | ||
|
|
b03d4c7646 | ||
|
|
1ef12d2cbc | ||
|
|
fa9a5cc247 | ||
|
|
0d8688515c | ||
|
|
f51207fc32 | ||
|
|
64ee8eab2f | ||
|
|
2224540b71 | ||
|
|
fcc0cb7293 | ||
|
|
ac1b701000 | ||
|
|
a3143ec512 | ||
|
|
39c682dc07 | ||
|
|
eeb63693c9 | ||
|
|
023aeea7ea | ||
|
|
a27daaebe9 | ||
|
|
51851ff15a | ||
|
|
490f59451b | ||
|
|
5160ff9793 | ||
|
|
fca98b411e | ||
|
|
2f7396e2aa | ||
|
|
9677631bb2 | ||
|
|
0565118a01 | ||
|
|
24767f62c7 | ||
|
|
fdaf419a7e | ||
|
|
c2a86704eb | ||
|
|
8fbb31a928 | ||
|
|
ab41a708e9 | ||
|
|
5d5915c5d6 | ||
|
|
562d81e246 | ||
|
|
bddffbce50 | ||
|
|
6992ac6aa9 | ||
|
|
dddd6f5503 | ||
|
|
71fc785753 | ||
|
|
bc3ae34c26 | ||
|
|
8361d15a70 | ||
|
|
52b3057640 | ||
|
|
074b682312 | ||
|
|
f7e554a3c1 | ||
|
|
5b020bb8d2 | ||
|
|
6388d19f7a | ||
|
|
5573a84335 | ||
|
|
a1f5ddede8 | ||
|
|
481b6c7cec | ||
|
|
bc4192e7d1 | ||
|
|
440a23a054 | ||
|
|
785577b2e8 | ||
|
|
06cfc3113a | ||
|
|
ea9de1bcf1 | ||
|
|
6c308116d6 | ||
|
|
6834e563a8 | ||
|
|
938499706c | ||
|
|
42c9186e91 | ||
|
|
60ac1ddbb9 | ||
|
|
a4277706f2 | ||
|
|
35b2033949 | ||
|
|
20c1139632 | ||
|
|
d04b54140c | ||
|
|
89a31443a5 | ||
|
|
6b3ec52ed4 | ||
|
|
202b88632c | ||
|
|
8bcc40a182 | ||
|
|
24381ad5dc | ||
|
|
a4bd2d687e | ||
|
|
db0f7649d1 | ||
|
|
6454df57bf | ||
|
|
b589b7a5dc | ||
|
|
4bf0d834a0 | ||
|
|
68e0c21eb0 | ||
|
|
d5ec762954 | ||
|
|
7bb1982c48 | ||
|
|
f956073f4a | ||
|
|
ae30fef641 | ||
|
|
75390693b9 | ||
|
|
43b473dc53 | ||
|
|
30acfdd3f1 | ||
|
|
e87575240d | ||
|
|
39fa02dcb1 | ||
|
|
7e84863beb | ||
|
|
2a4fe4dceb | ||
|
|
ef15de18a9 | ||
|
|
2163015d06 | ||
|
|
3b38ac0f9b | ||
|
|
6f30ceea38 | ||
|
|
f51d2be303 | ||
|
|
9bd0bee2f6 | ||
|
|
a60a4babf6 | ||
|
|
a03315102a | ||
|
|
df801d17e1 | ||
|
|
d3c13f6c93 | ||
|
|
fe7aa10d2c | ||
|
|
17a581495c | ||
|
|
64180b5668 | ||
|
|
81aaadb2a3 | ||
|
|
b1110f7291 | ||
|
|
cb9e5b5ee3 | ||
|
|
af99cbccd9 | ||
|
|
97639508cb | ||
|
|
b269af7572 | ||
|
|
1987dccf48 | ||
|
|
d92214d412 | ||
|
|
751c2ac54b | ||
|
|
6aca09d485 | ||
|
|
56ce267f89 | ||
|
|
ef6690905e | ||
|
|
2d559d330d | ||
|
|
95ec520f13 | ||
|
|
8069c2eb6a | ||
|
|
9a33f191a7 | ||
|
|
dd83364326 | ||
|
|
977594fece | ||
|
|
cd6e7d9563 | ||
|
|
f4013b1343 | ||
|
|
09e419aeee | ||
|
|
d7160de9f1 | ||
|
|
ded8f865d8 | ||
|
|
1e95d22e1a | ||
|
|
49ff1984f0 | ||
|
|
f7fa110afe | ||
|
|
cbdb45473a | ||
|
|
42b5ac6aff | ||
|
|
ae17a604d0 | ||
|
|
933cbe4594 | ||
|
|
1e9ac63428 | ||
|
|
c99668b355 | ||
|
|
fa5df5d28e | ||
|
|
4b47f4929e | ||
|
|
e44b918af2 | ||
|
|
a4b268cdae | ||
|
|
d9ae4322ea | ||
|
|
a316521ea6 | ||
|
|
a214536a51 | ||
|
|
acca5be585 | ||
|
|
b622b3fc6a | ||
|
|
63953b85e9 | ||
|
|
6c0e0755b9 | ||
|
|
8e7a3d309f | ||
|
|
09a9ab7a34 | ||
|
|
c11ce4e06f | ||
|
|
8650af05f7 | ||
|
|
25f88b7ae9 | ||
|
|
e75f48d148 | ||
|
|
d8e27600be | ||
|
|
9e31429732 | ||
|
|
1e0020b56b | ||
|
|
79e6b1f5dd | ||
|
|
5a292426c9 | ||
|
|
d2df1b0fc9 | ||
|
|
fec9e54049 | ||
|
|
ea089de3b3 | ||
|
|
172b37239f | ||
|
|
388e5b56de | ||
|
|
532d5c1744 | ||
|
|
54af13e4b8 | ||
|
|
d65a118d8a | ||
|
|
af3d161f66 | ||
|
|
d3482a4aef | ||
|
|
3600e5a8fb | ||
|
|
3afee66aaa | ||
|
|
110c5c392c | ||
|
|
db4519a644 | ||
|
|
450fb877f6 | ||
|
|
b44f8383e4 | ||
|
|
5a84cc835a | ||
|
|
529cc04fd1 | ||
|
|
b7fec4d355 | ||
|
|
77559332bc | ||
|
|
321adb5df2 | ||
|
|
09acb134b7 | ||
|
|
3d5b66c2b7 | ||
|
|
41650f20f4 | ||
|
|
bd45a804a7 | ||
|
|
3d6b555deb | ||
|
|
8681cad77c | ||
|
|
28ea67f252 | ||
|
|
1255ecf86e | ||
|
|
2c9555015b | ||
|
|
1655d85a53 | ||
|
|
1df664d109 | ||
|
|
a2e92b9d74 | ||
|
|
1cdd6d21c5 | ||
|
|
6fd64f9408 | ||
|
|
69f5be3e31 | ||
|
|
a9ebe9606e | ||
|
|
d1f9f456bb |
13
.gitignore
vendored
@@ -76,16 +76,11 @@ scripts/nuke
|
||||
/static/
|
||||
|
||||
# Stored PDFs
|
||||
/media/documents/originals/*
|
||||
/media/documents/thumbnails/*
|
||||
|
||||
/data/classification_model.pickle
|
||||
/data/db.sqlite3
|
||||
/data/index
|
||||
|
||||
/media/
|
||||
/data/
|
||||
/paperless.conf
|
||||
/consume
|
||||
/export
|
||||
/consume/
|
||||
/export/
|
||||
/src-ui/.vscode
|
||||
|
||||
# this is where the compiled frontend is moved to.
|
||||
|
||||
39
.travis.yml
@@ -1,13 +1,42 @@
|
||||
language: python
|
||||
|
||||
python:
|
||||
- "3.6"
|
||||
- "3.7"
|
||||
- "3.8"
|
||||
dist: focal
|
||||
os: linux
|
||||
|
||||
jobs:
|
||||
include:
|
||||
- name: "Paperless on Python 3.6"
|
||||
python: "3.6"
|
||||
|
||||
- name: "Paperless on Python 3.7"
|
||||
python: "3.7"
|
||||
|
||||
- name: "Paperless on Python 3.8"
|
||||
python: "3.8"
|
||||
|
||||
- name: "Documentation"
|
||||
script:
|
||||
- cd docs/
|
||||
- make html
|
||||
after_success: true
|
||||
|
||||
- name: "Front end"
|
||||
language: node_js
|
||||
node_js:
|
||||
- 15
|
||||
before_install: true
|
||||
install:
|
||||
- cd src-ui/
|
||||
- npm install -g @angular/cli
|
||||
- npm install
|
||||
script:
|
||||
- ng build --prod
|
||||
after_success: true
|
||||
|
||||
|
||||
before_install:
|
||||
- sudo apt-get update -qq
|
||||
- sudo apt-get install -qq libpoppler-cpp-dev unpaper tesseract-ocr
|
||||
- sudo apt-get install -qq libpoppler-cpp-dev unpaper tesseract-ocr imagemagick ghostscript optipng
|
||||
|
||||
install:
|
||||
- pip install --upgrade pipenv
|
||||
|
||||
@@ -1,13 +1,26 @@
|
||||
# Contributing
|
||||
|
||||
If you feel that somethings is not working, please submit an issue. You can also ask questions on the issue tracker by tagging your question with the question tag.
|
||||
There's still lots of things to be done, just have a look at that issue log. If you feel like conctributing to the project, please do! Bug fixes and improvements to the front end (I just can't seem to get some of these CSS things right) are always welcome.
|
||||
|
||||
Pull requests are welcome, however, I will be a little bit more strict about what goes into the code and what does not. If you want to make a big change, please ask me about it first.
|
||||
If you want to implement something big: Please start a discussion about that in the issues! Maybe I've already had something similar in mind and we can make it happen together. However, keep in mind that the general roadmap is to make the existing features stable and get them tested. See the roadmap in the readme.
|
||||
|
||||
* When making additions to the project, consider if the majority of users will benefit from your change. If not, you're probably better of forking the project.
|
||||
* Also consider if your change will get in the way of other users. A good change is a change that enhances the experience of some users who want that change and does not affect users who do not care about the change.
|
||||
|
||||
However:
|
||||
## Python
|
||||
|
||||
* Bug fixes and are always welcome. Docker makes things easier, however, I alone cannot ensure that this runs on all platforms.
|
||||
* Improvements to the styling of the front-end are always welcome. I'm no expert in things UX, and simply copied one of the Bootstrap examples. I think it turned out rather good, but I just can't seem to get some things working properly.
|
||||
Use python 3.6 for development. Paperless supports python 3.6, 3.7 and 3.8.
|
||||
|
||||
## Branches
|
||||
|
||||
master always reflects the latest release.
|
||||
|
||||
dev contains all changes that will be part of the next release. Use this branch to start making your changes.
|
||||
|
||||
feature-X branches is for experimental stuff that will eventually be merged into dev, and then released as part of the next release.
|
||||
|
||||
## Testing:
|
||||
|
||||
I'm trying to get most of paperless tested, so please do the same for your code! I know its a hassle, but it makes sure that your code works now and will allow us to detect regressions easily.
|
||||
|
||||
To test your code, execute `pytest` in the src/ directory. Executing that in the project root is no good. This also generates a html coverage report, which you can use to see if you missed anything important during testing.
|
||||
|
||||
53
Pipfile
@@ -8,44 +8,49 @@ url = "https://www.piwheels.org/simple"
|
||||
verify_ssl = true
|
||||
name = "piwheels"
|
||||
|
||||
[requires]
|
||||
python_version = "3.6"
|
||||
|
||||
[packages]
|
||||
django = "~=3.1"
|
||||
pillow = "*"
|
||||
dateparser = "~=0.7"
|
||||
dateparser = "~=0.7.6"
|
||||
django = "~=3.1.3"
|
||||
django-cors-headers = "*"
|
||||
djangorestframework = "~=3.12"
|
||||
python-gnupg = "*"
|
||||
python-dotenv = "*"
|
||||
filemagic = "*"
|
||||
pyocr = "~=0.7"
|
||||
django-extensions = "*"
|
||||
django-filter = "~=2.4.0"
|
||||
django-q = "~=1.3.4"
|
||||
djangorestframework = "~=3.12.2"
|
||||
fuzzywuzzy = "*"
|
||||
gunicorn = "*"
|
||||
imap-tools = "*"
|
||||
langdetect = "*"
|
||||
pdftotext = "*"
|
||||
django-filter = "~=2.4"
|
||||
python-dateutil = "*"
|
||||
psycopg2-binary = "*"
|
||||
scikit-learn="~=0.23"
|
||||
whoosh="~=2.7"
|
||||
gunicorn = "*"
|
||||
whitenoise = "~=5.2"
|
||||
fuzzywuzzy = "*"
|
||||
python-Levenshtein = "*"
|
||||
django-extensions = "*"
|
||||
watchdog = "*"
|
||||
pathvalidate = "*"
|
||||
django-q = "*"
|
||||
pillow = "*"
|
||||
python-gnupg = "*"
|
||||
python-dotenv = "*"
|
||||
python-dateutil = "*"
|
||||
python-Levenshtein = "*"
|
||||
python-magic = "*"
|
||||
psycopg2-binary = "*"
|
||||
redis = "*"
|
||||
imap-tools = "*"
|
||||
scikit-learn="~=0.23.2"
|
||||
whitenoise = "~=5.2.0"
|
||||
watchdog = "*"
|
||||
whoosh="~=2.7.4"
|
||||
inotifyrecursive = "~=0.3.4"
|
||||
ocrmypdf = "*"
|
||||
tqdm = "*"
|
||||
|
||||
[dev-packages]
|
||||
coveralls = "*"
|
||||
factory-boy = "*"
|
||||
sphinx = "~=3.3"
|
||||
tox = "*"
|
||||
pycodestyle = "*"
|
||||
pytest = "*"
|
||||
pytest-cov = "*"
|
||||
pytest-django = "*"
|
||||
pytest-sugar = "*"
|
||||
pytest-env = "*"
|
||||
pytest-sugar = "*"
|
||||
pytest-xdist = "*"
|
||||
sphinx = "~=3.3"
|
||||
sphinx_rtd_theme = "*"
|
||||
tox = "*"
|
||||
|
||||
406
Pipfile.lock
generated
@@ -1,10 +1,12 @@
|
||||
{
|
||||
"_meta": {
|
||||
"hash": {
|
||||
"sha256": "abc7e5f5a8d075d4b013ceafd06ca07f57e597f053d670f73449ba210511b114"
|
||||
"sha256": "b10db53eb22d917723aa6107ff0970dc4e2aa886ee03d3ae08a994a856d57986"
|
||||
},
|
||||
"pipfile-spec": 6,
|
||||
"requires": {},
|
||||
"requires": {
|
||||
"python_version": "3.6"
|
||||
},
|
||||
"sources": [
|
||||
{
|
||||
"name": "pypi",
|
||||
@@ -37,10 +39,100 @@
|
||||
},
|
||||
"blessed": {
|
||||
"hashes": [
|
||||
"sha256:7d4914079a6e8e14fbe080dcaf14dee596a088057cdc598561080e3266123b48",
|
||||
"sha256:81125aa5b84cb9dfc09ff451886f64b4b923b75c5eaf51fde9d1c48a135eb797"
|
||||
"sha256:0a74a8d3f0366db600d061273df77d44f0db07daade7bb7a4d49c8bc22ed9f74",
|
||||
"sha256:580429e7e0c6f6a42ea81b0ae5a4993b6205c6ccbb635d034b4277af8175753e"
|
||||
],
|
||||
"version": "==1.17.11"
|
||||
"version": "==1.17.12"
|
||||
},
|
||||
"cffi": {
|
||||
"hashes": [
|
||||
"sha256:00a1ba5e2e95684448de9b89888ccd02c98d512064b4cb987d48f4b40aa0421e",
|
||||
"sha256:00e28066507bfc3fe865a31f325c8391a1ac2916219340f87dfad602c3e48e5d",
|
||||
"sha256:045d792900a75e8b1e1b0ab6787dd733a8190ffcf80e8c8ceb2fb10a29ff238a",
|
||||
"sha256:0638c3ae1a0edfb77c6765d487fee624d2b1ee1bdfeffc1f0b58c64d149e7eec",
|
||||
"sha256:105abaf8a6075dc96c1fe5ae7aae073f4696f2905fde6aeada4c9d2926752362",
|
||||
"sha256:155136b51fd733fa94e1c2ea5211dcd4c8879869008fc811648f16541bf99668",
|
||||
"sha256:1a465cbe98a7fd391d47dce4b8f7e5b921e6cd805ef421d04f5f66ba8f06086c",
|
||||
"sha256:1d2c4994f515e5b485fd6d3a73d05526aa0fcf248eb135996b088d25dfa1865b",
|
||||
"sha256:23f318bf74b170c6e9adb390e8bd282457f6de46c19d03b52f3fd042b5e19654",
|
||||
"sha256:2c24d61263f511551f740d1a065eb0212db1dbbbbd241db758f5244281590c06",
|
||||
"sha256:51a8b381b16ddd370178a65360ebe15fbc1c71cf6f584613a7ea08bfad946698",
|
||||
"sha256:594234691ac0e9b770aee9fcdb8fa02c22e43e5c619456efd0d6c2bf276f3eb2",
|
||||
"sha256:5cf4be6c304ad0b6602f5c4e90e2f59b47653ac1ed9c662ed379fe48a8f26b0c",
|
||||
"sha256:64081b3f8f6f3c3de6191ec89d7dc6c86a8a43911f7ecb422c60e90c70be41c7",
|
||||
"sha256:6bc25fc545a6b3d57b5f8618e59fc13d3a3a68431e8ca5fd4c13241cd70d0009",
|
||||
"sha256:798caa2a2384b1cbe8a2a139d80734c9db54f9cc155c99d7cc92441a23871c03",
|
||||
"sha256:7c6b1dece89874d9541fc974917b631406233ea0440d0bdfbb8e03bf39a49b3b",
|
||||
"sha256:840793c68105fe031f34d6a086eaea153a0cd5c491cde82a74b420edd0a2b909",
|
||||
"sha256:8d6603078baf4e11edc4168a514c5ce5b3ba6e3e9c374298cb88437957960a53",
|
||||
"sha256:9cc46bc107224ff5b6d04369e7c595acb700c3613ad7bcf2e2012f62ece80c35",
|
||||
"sha256:9f7a31251289b2ab6d4012f6e83e58bc3b96bd151f5b5262467f4bb6b34a7c26",
|
||||
"sha256:9ffb888f19d54a4d4dfd4b3f29bc2c16aa4972f1c2ab9c4ab09b8ab8685b9c2b",
|
||||
"sha256:a5ed8c05548b54b998b9498753fb9cadbfd92ee88e884641377d8a8b291bcc01",
|
||||
"sha256:a7711edca4dcef1a75257b50a2fbfe92a65187c47dab5a0f1b9b332c5919a3fb",
|
||||
"sha256:af5c59122a011049aad5dd87424b8e65a80e4a6477419c0c1015f73fb5ea0293",
|
||||
"sha256:b18e0a9ef57d2b41f5c68beefa32317d286c3d6ac0484efd10d6e07491bb95dd",
|
||||
"sha256:b4e248d1087abf9f4c10f3c398896c87ce82a9856494a7155823eb45a892395d",
|
||||
"sha256:ba4e9e0ae13fc41c6b23299545e5ef73055213e466bd107953e4a013a5ddd7e3",
|
||||
"sha256:be8661bcee1bc2fc4b033a6ab65bd1f87ce5008492601695d0b9a4e820c3bde5",
|
||||
"sha256:c6332685306b6417a91b1ff9fae889b3ba65c2292d64bd9245c093b1b284809d",
|
||||
"sha256:d5ff0621c88ce83a28a10d2ce719b2ee85635e85c515f12bac99a95306da4b2e",
|
||||
"sha256:d9efd8b7a3ef378dd61a1e77367f1924375befc2eba06168b6ebfa903a5e59ca",
|
||||
"sha256:df5169c4396adc04f9b0a05f13c074df878b6052430e03f50e68adf3a57aa28d",
|
||||
"sha256:ebb253464a5d0482b191274f1c8bf00e33f7e0b9c66405fbffc61ed2c839c775",
|
||||
"sha256:ec80dc47f54e6e9a78181ce05feb71a0353854cc26999db963695f950b5fb375",
|
||||
"sha256:f032b34669220030f905152045dfa27741ce1a6db3324a5bc0b96b6c7420c87b",
|
||||
"sha256:f60567825f791c6f8a592f3c6e3bd93dd2934e3f9dac189308426bd76b00ef3b",
|
||||
"sha256:f803eaa94c2fcda012c047e62bc7a51b0bdabda1cad7a92a522694ea2d76e49f"
|
||||
],
|
||||
"version": "==1.14.4"
|
||||
},
|
||||
"chardet": {
|
||||
"hashes": [
|
||||
"sha256:84ab92ed1c4d4f16916e05906b6b75a6c0fb5db821cc65e70cbd64a3e2a5eaae",
|
||||
"sha256:fc323ffcaeaed0e0a02bf4d117757b98aed530d9ed4531e3e15460124c106691"
|
||||
],
|
||||
"markers": "python_version >= '3.1'",
|
||||
"version": "==3.0.4"
|
||||
},
|
||||
"coloredlogs": {
|
||||
"hashes": [
|
||||
"sha256:346f58aad6afd48444c2468618623638dadab76e4e70d5e10822676f2d32226a",
|
||||
"sha256:a1fab193d2053aa6c0a97608c4342d031f1f93a3d1218432c59322441d31a505",
|
||||
"sha256:b0c2124367d4f72bd739f48e1f61491b4baf145d6bda33b606b4a53cb3f96a97"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3, 3.4'",
|
||||
"version": "==14.0"
|
||||
},
|
||||
"cryptography": {
|
||||
"hashes": [
|
||||
"sha256:07ca431b788249af92764e3be9a488aa1d39a0bc3be313d826bbec690417e538",
|
||||
"sha256:13b88a0bd044b4eae1ef40e265d006e34dbcde0c2f1e15eb9896501b2d8f6c6f",
|
||||
"sha256:257dab4f368fae15f378ea9a4d2799bf3696668062de0e9fa0ebb7a738a6917d",
|
||||
"sha256:32434673d8505b42c0de4de86da8c1620651abd24afe91ae0335597683ed1b77",
|
||||
"sha256:3cd75a683b15576cfc822c7c5742b3276e50b21a06672dc3a800a2d5da4ecd1b",
|
||||
"sha256:4e7268a0ca14536fecfdf2b00297d4e407da904718658c1ff1961c713f90fd33",
|
||||
"sha256:545a8550782dda68f8cdc75a6e3bf252017aa8f75f19f5a9ca940772fc0cb56e",
|
||||
"sha256:55d0b896631412b6f0c7de56e12eb3e261ac347fbaa5d5e705291a9016e5f8cb",
|
||||
"sha256:5849d59358547bf789ee7e0d7a9036b2d29e9a4ddf1ce5e06bb45634f995c53e",
|
||||
"sha256:59f7d4cfea9ef12eb9b14b83d79b432162a0a24a91ddc15c2c9bf76a68d96f2b",
|
||||
"sha256:6dc59630ecce8c1f558277ceb212c751d6730bd12c80ea96b4ac65637c4f55e7",
|
||||
"sha256:7117319b44ed1842c617d0a452383a5a052ec6aa726dfbaffa8b94c910444297",
|
||||
"sha256:75e8e6684cf0034f6bf2a97095cb95f81537b12b36a8fedf06e73050bb171c2d",
|
||||
"sha256:7b8d9d8d3a9bd240f453342981f765346c87ade811519f98664519696f8e6ab7",
|
||||
"sha256:a035a10686532b0587d58a606004aa20ad895c60c4d029afa245802347fab57b",
|
||||
"sha256:a4e27ed0b2504195f855b52052eadcc9795c59909c9d84314c5408687f933fc7",
|
||||
"sha256:a733671100cd26d816eed39507e585c156e4498293a907029969234e5e634bc4",
|
||||
"sha256:a75f306a16d9f9afebfbedc41c8c2351d8e61e818ba6b4c40815e2b5740bb6b8",
|
||||
"sha256:bd717aa029217b8ef94a7d21632a3bb5a4e7218a4513d2521c2a2fd63011e98b",
|
||||
"sha256:d25cecbac20713a7c3bc544372d42d8eafa89799f492a43b79e1dfd650484851",
|
||||
"sha256:d26a2557d8f9122f9bf445fc7034242f4375bd4e95ecda007667540270965b13",
|
||||
"sha256:d3545829ab42a66b84a9aaabf216a4dce7f16dbc76eb69be5c302ed6b8f4a29b",
|
||||
"sha256:d3d5e10be0cf2a12214ddee45c6bd203dab435e3d83b4560c03066eda600bfe3",
|
||||
"sha256:efe15aca4f64f3a7ea0c09c87826490e50ed166ce67368a68f315ea0807a20df"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3, 3.4'",
|
||||
"version": "==3.2.1"
|
||||
},
|
||||
"dateparser": {
|
||||
"hashes": [
|
||||
@@ -52,11 +144,11 @@
|
||||
},
|
||||
"django": {
|
||||
"hashes": [
|
||||
"sha256:14a4b7cd77297fba516fc0d92444cc2e2e388aa9de32d7a68d4a83d58f5a4927",
|
||||
"sha256:14b87775ffedab2ef6299b73343d1b4b41e5d4e2aa58c6581f114dbec01e3f8f"
|
||||
"sha256:5c866205f15e7a7123f1eec6ab939d22d5bde1416635cab259684af66d8e48a2",
|
||||
"sha256:edb10b5c45e7e9c0fb1dc00b76ec7449aca258a39ffd613dbd078c51d19c9f03"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==3.1.3"
|
||||
"version": "==3.1.4"
|
||||
},
|
||||
"django-cors-headers": {
|
||||
"hashes": [
|
||||
@@ -68,11 +160,11 @@
|
||||
},
|
||||
"django-extensions": {
|
||||
"hashes": [
|
||||
"sha256:6809c89ca952f0e08d4e0766bc0101dfaf508d7649aced1180c091d737046ea7",
|
||||
"sha256:dc663652ac9460fd06580a973576820430c6d428720e874ae46b041fa63e0efa"
|
||||
"sha256:7cd002495ff0a0e5eb6cdd6be759600905b4e4079232ea27618fc46bdd853651",
|
||||
"sha256:c7f88625a53f631745d4f2bef9ec4dcb999ed59476393bdbbe99db8596778846"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==3.0.9"
|
||||
"version": "==3.1.0"
|
||||
},
|
||||
"django-filter": {
|
||||
"hashes": [
|
||||
@@ -105,14 +197,6 @@
|
||||
"index": "pypi",
|
||||
"version": "==3.12.2"
|
||||
},
|
||||
"filemagic": {
|
||||
"hashes": [
|
||||
"sha256:b2fd77411975510e28673220c4b8868ed81b5eb5906339b6f4c233b32122d7d3",
|
||||
"sha256:e684359ef40820fe406f0ebc5bf8a78f89717bdb7fed688af68082d991d6dbf3"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.6"
|
||||
},
|
||||
"fuzzywuzzy": {
|
||||
"hashes": [
|
||||
"sha256:45016e92264780e58972dca1b3d939ac864b78437422beecebb3095f8efd00e8",
|
||||
@@ -129,13 +213,52 @@
|
||||
"index": "pypi",
|
||||
"version": "==20.0.4"
|
||||
},
|
||||
"humanfriendly": {
|
||||
"hashes": [
|
||||
"sha256:175ffa628aa76da2c17369a5da5856084562cc66dfe7f82ae93ca3ef175277a6",
|
||||
"sha256:3c9ab8d28e88e6cc998e41963357736dafd555ee5bb666b50e42f6ce28dd3e3d"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3, 3.4'",
|
||||
"version": "==9.0"
|
||||
},
|
||||
"imap-tools": {
|
||||
"hashes": [
|
||||
"sha256:070929b8ec429c0aad94588a37a2962eed656a119ab61dcf91489f20fe983f5d",
|
||||
"sha256:6232cd43748741496446871e889eb137351fc7a7e7f4c7888cd8c0fa28e20cda"
|
||||
"sha256:72bf46dc135b039a5d5b59f4e079242ac15eac02a30038e8cb2dec7b153cab65",
|
||||
"sha256:75dc1c72dd76d9e577df26a1e0ec3a809b5eebce77678851458dcd2eae127ac9"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.31.0"
|
||||
"version": "==0.33.0"
|
||||
},
|
||||
"img2pdf": {
|
||||
"hashes": [
|
||||
"sha256:57905015579b1026acf1605aa95859cd79b051fa1c35485573d165526fc9dbb5",
|
||||
"sha256:eaee690ab8403dd1a9cb4db10afee41dd3e6c7ed63bdace02a0121f9feadb0c9"
|
||||
],
|
||||
"version": "==0.4.0"
|
||||
},
|
||||
"importlib-metadata": {
|
||||
"hashes": [
|
||||
"sha256:6112e21359ef8f344e7178aa5b72dc6e62b38b0d008e6d3cb212c5b84df72013",
|
||||
"sha256:b0c2d3b226157ae4517d9625decf63591461c66b3a808c2666d538946519d170"
|
||||
],
|
||||
"markers": "python_version < '3.8'",
|
||||
"version": "==3.1.1"
|
||||
},
|
||||
"inotify-simple": {
|
||||
"hashes": [
|
||||
"sha256:8440ffe49c4ae81a8df57c1ae1eb4b6bfa7acb830099bfb3e305b383005cc128",
|
||||
"sha256:854f9ac752cc1fcff6ca34e9d3d875c9a94c9b7d6eb377f63be2d481a566c6ee"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==1.3.5"
|
||||
},
|
||||
"inotifyrecursive": {
|
||||
"hashes": [
|
||||
"sha256:7e5f4a2e1dc2bef0efa3b5f6b339c41fb4599055a2b54909d020e9e932cc8d2f",
|
||||
"sha256:a2c450b317693e4538416f90eb1d7858506dafe6b8b885037bd2dd9ae2dafa1e"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.3.5"
|
||||
},
|
||||
"joblib": {
|
||||
"hashes": [
|
||||
@@ -154,6 +277,51 @@
|
||||
"index": "pypi",
|
||||
"version": "==1.0.8"
|
||||
},
|
||||
"lxml": {
|
||||
"hashes": [
|
||||
"sha256:0448576c148c129594d890265b1a83b9cd76fd1f0a6a04620753d9a6bcfd0a4d",
|
||||
"sha256:127f76864468d6630e1b453d3ffbbd04b024c674f55cf0a30dc2595137892d37",
|
||||
"sha256:1471cee35eba321827d7d53d104e7b8c593ea3ad376aa2df89533ce8e1b24a01",
|
||||
"sha256:2363c35637d2d9d6f26f60a208819e7eafc4305ce39dc1d5005eccc4593331c2",
|
||||
"sha256:2e5cc908fe43fe1aa299e58046ad66981131a66aea3129aac7770c37f590a644",
|
||||
"sha256:2e6fd1b8acd005bd71e6c94f30c055594bbd0aa02ef51a22bbfa961ab63b2d75",
|
||||
"sha256:366cb750140f221523fa062d641393092813b81e15d0e25d9f7c6025f910ee80",
|
||||
"sha256:42ebca24ba2a21065fb546f3e6bd0c58c3fe9ac298f3a320147029a4850f51a2",
|
||||
"sha256:4e751e77006da34643ab782e4a5cc21ea7b755551db202bc4d3a423b307db780",
|
||||
"sha256:4fb85c447e288df535b17ebdebf0ec1cf3a3f1a8eba7e79169f4f37af43c6b98",
|
||||
"sha256:50c348995b47b5a4e330362cf39fc503b4a43b14a91c34c83b955e1805c8e308",
|
||||
"sha256:535332fe9d00c3cd455bd3dd7d4bacab86e2d564bdf7606079160fa6251caacf",
|
||||
"sha256:535f067002b0fd1a4e5296a8f1bf88193080ff992a195e66964ef2a6cfec5388",
|
||||
"sha256:5be4a2e212bb6aa045e37f7d48e3e1e4b6fd259882ed5a00786f82e8c37ce77d",
|
||||
"sha256:60a20bfc3bd234d54d49c388950195d23a5583d4108e1a1d47c9eef8d8c042b3",
|
||||
"sha256:648914abafe67f11be7d93c1a546068f8eff3c5fa938e1f94509e4a5d682b2d8",
|
||||
"sha256:681d75e1a38a69f1e64ab82fe4b1ed3fd758717bed735fb9aeaa124143f051af",
|
||||
"sha256:68a5d77e440df94011214b7db907ec8f19e439507a70c958f750c18d88f995d2",
|
||||
"sha256:69a63f83e88138ab7642d8f61418cf3180a4d8cd13995df87725cb8b893e950e",
|
||||
"sha256:6e4183800f16f3679076dfa8abf2db3083919d7e30764a069fb66b2b9eff9939",
|
||||
"sha256:6fd8d5903c2e53f49e99359b063df27fdf7acb89a52b6a12494208bf61345a03",
|
||||
"sha256:791394449e98243839fa822a637177dd42a95f4883ad3dec2a0ce6ac99fb0a9d",
|
||||
"sha256:7a7669ff50f41225ca5d6ee0a1ec8413f3a0d8aa2b109f86d540887b7ec0d72a",
|
||||
"sha256:7e9eac1e526386df7c70ef253b792a0a12dd86d833b1d329e038c7a235dfceb5",
|
||||
"sha256:7ee8af0b9f7de635c61cdd5b8534b76c52cd03536f29f51151b377f76e214a1a",
|
||||
"sha256:8246f30ca34dc712ab07e51dc34fea883c00b7ccb0e614651e49da2c49a30711",
|
||||
"sha256:8c88b599e226994ad4db29d93bc149aa1aff3dc3a4355dd5757569ba78632bdf",
|
||||
"sha256:91d6dace31b07ab47eeadd3f4384ded2f77b94b30446410cb2c3e660e047f7a7",
|
||||
"sha256:923963e989ffbceaa210ac37afc9b906acebe945d2723e9679b643513837b089",
|
||||
"sha256:94d55bd03d8671686e3f012577d9caa5421a07286dd351dfef64791cf7c6c505",
|
||||
"sha256:97db258793d193c7b62d4e2586c6ed98d51086e93f9a3af2b2034af01450a74b",
|
||||
"sha256:a9d6bc8642e2c67db33f1247a77c53476f3a166e09067c0474facb045756087f",
|
||||
"sha256:cd11c7e8d21af997ee8079037fff88f16fda188a9776eb4b81c7e4c9c0a7d7fc",
|
||||
"sha256:d8d3d4713f0c28bdc6c806a278d998546e8efc3498949e3ace6e117462ac0a5e",
|
||||
"sha256:e0bfe9bb028974a481410432dbe1b182e8191d5d40382e5b8ff39cdd2e5c5931",
|
||||
"sha256:e1dbb88a937126ab14d219a000728224702e0ec0fc7ceb7131c53606b7a76772",
|
||||
"sha256:f4822c0660c3754f1a41a655e37cb4dbbc9be3d35b125a37fab6f82d47674ebc",
|
||||
"sha256:f83d281bb2a6217cd806f4cf0ddded436790e66f393e124dfe9731f6b3fb9afe",
|
||||
"sha256:fc37870d6716b137e80d19241d0e2cff7a7643b925dfa49b4c8ebd1295eb506e"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3, 3.4'",
|
||||
"version": "==4.6.2"
|
||||
},
|
||||
"numpy": {
|
||||
"hashes": [
|
||||
"sha256:08308c38e44cc926bdfce99498b21eec1f848d24c302519e64203a8da99a97db",
|
||||
@@ -195,6 +363,14 @@
|
||||
"markers": "python_version >= '3.6'",
|
||||
"version": "==1.19.4"
|
||||
},
|
||||
"ocrmypdf": {
|
||||
"hashes": [
|
||||
"sha256:91e7394172cedb3be801a229dbd3d308fb5ae80cbc3a77879fa7954beea407b1",
|
||||
"sha256:e550b8e884150accab7ea41f4a576b5844594cb5cbd6ed514fbf1206720343ad"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==11.3.4"
|
||||
},
|
||||
"pathtools": {
|
||||
"hashes": [
|
||||
"sha256:7c35c5421a39bb82e58018febd90e3b6e5db34c5443aaaf742b3f33d4655f1c0",
|
||||
@@ -210,6 +386,14 @@
|
||||
"index": "pypi",
|
||||
"version": "==2.3.0"
|
||||
},
|
||||
"pdfminer.six": {
|
||||
"hashes": [
|
||||
"sha256:b9aac0ebeafb21c08bf65f2039f4b2c5f78a3449d0a41df711d72445649e952a",
|
||||
"sha256:d78877ba8d8bf957f3bb636c4f73f4f6f30f56c461993877ac22c39c20837509"
|
||||
],
|
||||
"markers": "python_version >= '3.4'",
|
||||
"version": "==20201018"
|
||||
},
|
||||
"pdftotext": {
|
||||
"hashes": [
|
||||
"sha256:98aeb8b07a4127e1a30223bd933ef080bbd29aa88f801717ca6c5618380b8aa6"
|
||||
@@ -217,6 +401,33 @@
|
||||
"index": "pypi",
|
||||
"version": "==2.1.5"
|
||||
},
|
||||
"pikepdf": {
|
||||
"hashes": [
|
||||
"sha256:0829bd5dacd73bb4a37e7575bae523f49603479755563c92ddb55c206700cab1",
|
||||
"sha256:0d2b631077cd6af6e4d1b396208020705842610a6f13fab489d5f9c47916baa2",
|
||||
"sha256:21c98af08fae4ac9fbcad02b613b6768a4ca300fda4cba867f4a4b6f73c2d04b",
|
||||
"sha256:2240372fed30124ddc35b0c15a613f2b687a426ea2f150091e0a0c58cca7a495",
|
||||
"sha256:2a97f5f1403e058d217d7f6861cf51fca200c5687bce0d052f5f2fa89b5bfa22",
|
||||
"sha256:3faaefca0ae80d19891acec8b0dd5e6235f59f2206d82375eb80d090285e9557",
|
||||
"sha256:48ef45b64882901c0d69af3b85d16a19bd0f3e95b43e614fefb53521d8caf36c",
|
||||
"sha256:5212fe41f2323fc7356ba67caa39737fe13080562cff37bcbb74a8094076c8d0",
|
||||
"sha256:56859c32170663c57bd0658189ce44e180533eebe813853446cd6413810be9eb",
|
||||
"sha256:5f8fd1cb3478c5534222018aca24fbbd2bc74460c899bda988ec76722c13caa9",
|
||||
"sha256:74300a32c41b3d578772f6933f23a88b19f74484185e71e5225ce2f7ea5aea78",
|
||||
"sha256:8cbc946bdd217148f4a9c029fcea62f4ae0f67d5346de4c865f4718cd0ddc37f",
|
||||
"sha256:9ceefd30076f732530cf84a1be2ecb2fa9931af932706ded760a6d37c73b96ad",
|
||||
"sha256:ad69c170fda41b07a4c6b668a3128e7a759f50d9aebcfcde0ccff1358abe0423",
|
||||
"sha256:b715fe182189fb6870fab5b0383bb2fb278c88c46eade346b0f4c1ed8818c09d",
|
||||
"sha256:bb01ecf95083ffcb9ad542dc5342ccc1059e46f1395fd966629d36d9cc766b4a",
|
||||
"sha256:bd6328547219cf48cefb4e0a1bc54442910594de1c5a5feae847d9ff3c629031",
|
||||
"sha256:edb128379bb1dea76b5bdbdacf5657a6e4754bacc2049640762725590d8ed905",
|
||||
"sha256:f8e687900557fcd4c51b4e72b9e337fdae9e2c81049d1d80b624bb2e88b5769d",
|
||||
"sha256:fe0ca120e3347c851c34a91041d574f3c588d832023906d8ae18d66d042e8a52",
|
||||
"sha256:fe8e0152672f24d8bfdecc725f97e9013f2de1b41849150959526ca3562bd3ef"
|
||||
],
|
||||
"markers": "python_version < '3.9'",
|
||||
"version": "==2.2.0"
|
||||
},
|
||||
"pillow": {
|
||||
"hashes": [
|
||||
"sha256:006de60d7580d81f4a1a7e9f0173dc90a932e3905cc4d47ea909bc946302311a",
|
||||
@@ -252,6 +463,14 @@
|
||||
"index": "pypi",
|
||||
"version": "==8.0.1"
|
||||
},
|
||||
"pluggy": {
|
||||
"hashes": [
|
||||
"sha256:15b2acde666561e1298d71b523007ed7364de07029219b604cf808bfa1c765b0",
|
||||
"sha256:966c145cd83c96502c3c3868f50408687b38434af77734af1e9ca461a4081d2d"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==0.13.1"
|
||||
},
|
||||
"psycopg2-binary": {
|
||||
"hashes": [
|
||||
"sha256:0deac2af1a587ae12836aa07970f5cb91964f05a7c6cdb69d8425ff4c15d4e2c",
|
||||
@@ -295,13 +514,13 @@
|
||||
"index": "pypi",
|
||||
"version": "==2.8.6"
|
||||
},
|
||||
"pyocr": {
|
||||
"pycparser": {
|
||||
"hashes": [
|
||||
"sha256:fa15adc7e1cf0d345a2990495fe125a947c6e09a60ddba0256a1c14b2e603179",
|
||||
"sha256:fd602af17b6e21985669aadc058a95f343ff921e962ed4aa6520ded32e4d1301"
|
||||
"sha256:2d475327684562c3a96cc71adf7dc8c4f0565175cf86b6d7a404ff4c771f15f0",
|
||||
"sha256:7582ad22678f0fcd81102833f60ef8d0e57288b6b5fb00323d101be910e35705"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.7.2"
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==2.20"
|
||||
},
|
||||
"python-dateutil": {
|
||||
"hashes": [
|
||||
@@ -337,6 +556,14 @@
|
||||
"index": "pypi",
|
||||
"version": "==0.12.0"
|
||||
},
|
||||
"python-magic": {
|
||||
"hashes": [
|
||||
"sha256:356efa93c8899047d1eb7d3eb91e871ba2f5b1376edbaf4cc305e3c872207355",
|
||||
"sha256:b757db2a5289ea3f1ced9e60f072965243ea43a2221430048fd8cacab17be0ce"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.4.18"
|
||||
},
|
||||
"pytz": {
|
||||
"hashes": [
|
||||
"sha256:3e6b7dd2d1e0a59084bcee14a17af60c5c562cdc16d828e8eba2e683d3a7e268",
|
||||
@@ -401,6 +628,53 @@
|
||||
],
|
||||
"version": "==2020.11.13"
|
||||
},
|
||||
"reportlab": {
|
||||
"hashes": [
|
||||
"sha256:0008b5baa39d7e3a8132c4b47ecae88d6858ad386518e754e5e7b8025ee4722b",
|
||||
"sha256:0ad5a540c336941272fe161ef3a9830da3d4b3a65a195531cebd3cad5db58b2a",
|
||||
"sha256:0c965a5691686d746f558ee1c52aa9c63a01a0e13cba61ffc661573948e32f61",
|
||||
"sha256:0fd568fa5615ae99f76289c52ff230207852ee942d4934f6c893c93d2a79544e",
|
||||
"sha256:1117d905a3404c696869c7aabec9454b43ed6acbbc73f9256c6fcea23e7ae93e",
|
||||
"sha256:1ea7c388e91ad9d823655ad6a13751ff67e8a0e7cf4065cf051b4c931cdd9450",
|
||||
"sha256:26c0ee8f62652cc7fcdc47a1cb3b34775a4d625738025c1a7edb8718bda5a315",
|
||||
"sha256:368c5b3fc3d5a541cb9dcacefa563fdb445365f517e3cbf64b4326631d1cf13c",
|
||||
"sha256:451d42fdcdd7d84587d6d9c8f5d9a7d0e997305efb606705063ca1fe8bcca551",
|
||||
"sha256:47394acba4da8e56ef8e55d8eb483b868521696ba49ab0f0fcf8a1a4a5ac6e49",
|
||||
"sha256:51b16e297f7b937fc530dd151e4b38f1d305b01c9aa10657bc32a5d2901b8ad7",
|
||||
"sha256:51c0cdcf606ded0a7b4b50050400f25125ea797fbfc3c817135993b38f8b764e",
|
||||
"sha256:55c672c579618843e0fd00140fb71f1ffebc4f1c542ac385c4f4999f2f5398d9",
|
||||
"sha256:5c34a96ecfbf595caf16178a06abcd26a5f8720e01fe1285d4c97333382cfaeb",
|
||||
"sha256:61aa89a00754b18c4f2956b8bff831f1fd3affef6476dc63462d92211941605e",
|
||||
"sha256:62234d29c97279917903e4587faf240a5dea4617be250db55386ff268eb5a7c5",
|
||||
"sha256:670f2a8dcc23bf798c39b95c64bf76ee387549b962f76783670821978a226663",
|
||||
"sha256:69387f171f6c7b55109caa6d061b17a18f2f9e724a0212c07cd692aeb369dd19",
|
||||
"sha256:6c5c8871b659f7c2975382d7b61f3c182701fa9eb62cf649c3c73ba8fc5e2595",
|
||||
"sha256:80139ceb3a568f5be908094f1701fd05391b71425e8b69aaed0d30db647ca2aa",
|
||||
"sha256:80661a76d0019b5e2c315ccd3bc7093d754067d6142b36a3a0ec4f416073d23b",
|
||||
"sha256:85a2236f324ae336da7f4b183fa99bed261bcc00ac1255ee91a504e68b086d00",
|
||||
"sha256:89a3acd98bd4478d6bbc5cb32e0665ea546c98bff8b58d5e1014659daa6ef75a",
|
||||
"sha256:8a39119fcab146bde41fd1c6d148f9ee1e2cca10c6f9c2b7eb4dd710a3a2c6ac",
|
||||
"sha256:9c31c2526401da6cc92018f68483f2aac0a731cb98435445ea4b72d46b438c84",
|
||||
"sha256:9e8ae1c3b8a1697147c5c97f00d66ab1c54d88c4615b0cdd9b1a667d7baf3eb7",
|
||||
"sha256:a479c38ab2b997ce05d3bef906783ac20cf4cb224a154e80c9018c5e4d943a35",
|
||||
"sha256:a79aab8d069543d5085d58260f18705a08acd92a4501a41261913fddc2137d46",
|
||||
"sha256:b0a8314383de853599ca531dfe55eaa49bb8d6b0bb663b2f8479b7a0f3385ea2",
|
||||
"sha256:b3d9926e64bd8008007b2d9819d7b30179b069ce95431d5060f71afc36885389",
|
||||
"sha256:c2a9a77ce4f25ffb52d705be82a9f41b47f6b0da23870ebc3587709e7242da30",
|
||||
"sha256:c578dd0799f70fb577474cd383f035c6e1057e4fe837278113f9cfa6eee4b076",
|
||||
"sha256:c5abd9d0023ad20030524ab0d5fa39d77aed025519b1fa426304ab2dd0328b89",
|
||||
"sha256:ced96125525ba21311e9512adf391170b9e149f89e27e45b06ff07b70f97a0b2",
|
||||
"sha256:d692fb88d6ef5e75242b00009b54953a0425eaa8bd3a36db9db8b396785e1f57",
|
||||
"sha256:d70c2104286459658e61388af9eee838b612986bd8a36e1d21ba36152983ac15",
|
||||
"sha256:de47c65c10ac6f0d2addb28f1b1657b1c707aca014d09d01b3b728cf19e8f791",
|
||||
"sha256:e6e7592527791841db0820a72c6afae52655a05b0b6d4df184fd2bafe82ee1ee",
|
||||
"sha256:e8a7e95ee6ea5566291b59ede5b9fadce809dca43ebfbfe11e3ff3d6492c6f0e",
|
||||
"sha256:f041759138b3a95508c4281b3db3bf9bb28636d84c554272a58a5ca7c9f9bbf4",
|
||||
"sha256:f39c7fc1fa2e4a1d9747a3effd70731a9d0e9eb5738247fa089c059eff19d43e",
|
||||
"sha256:f65ac89ee0ba569f5279360eae08783f7f2e95c9810a9846c957fbd5950f4896"
|
||||
],
|
||||
"version": "==3.5.56"
|
||||
},
|
||||
"scikit-learn": {
|
||||
"hashes": [
|
||||
"sha256:090bbf144fd5823c1f2efa3e1a9bf180295b24294ca8f478e75b40ed54f8036e",
|
||||
@@ -464,6 +738,13 @@
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==1.15.0"
|
||||
},
|
||||
"sortedcontainers": {
|
||||
"hashes": [
|
||||
"sha256:37257a32add0a3ee490bb170b599e93095eed89a55da91fa9f48753ea12fd73f",
|
||||
"sha256:59cc937650cf60d677c16775597c89a960658a09cf7c1a668f86e1e4464b10a1"
|
||||
],
|
||||
"version": "==2.3.0"
|
||||
},
|
||||
"sqlparse": {
|
||||
"hashes": [
|
||||
"sha256:017cde379adbd6a1f15a61873f43e8274179378e95ef3fede90b5aa64d304ed0",
|
||||
@@ -480,6 +761,14 @@
|
||||
"markers": "python_version >= '3.5'",
|
||||
"version": "==2.1.0"
|
||||
},
|
||||
"tqdm": {
|
||||
"hashes": [
|
||||
"sha256:38b658a3e4ecf9b4f6f8ff75ca16221ae3378b2e175d846b6b33ea3a20852cf5",
|
||||
"sha256:d4f413aecb61c9779888c64ddf0c62910ad56dcbe857d8922bb505d4dbff0df1"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==4.54.1"
|
||||
},
|
||||
"tzlocal": {
|
||||
"hashes": [
|
||||
"sha256:643c97c5294aedc737780a49d9df30889321cbe1204eac2c2ec6134035a92e44",
|
||||
@@ -489,11 +778,11 @@
|
||||
},
|
||||
"watchdog": {
|
||||
"hashes": [
|
||||
"sha256:034c85530b647486e8c8477410fe79476511282658f2ce496f97106d9e5acfb8",
|
||||
"sha256:4214e1379d128b0588021880ccaf40317ee156d4603ac388b9adcf29165e0c04"
|
||||
"sha256:3caefdcc8f06a57fdc5ef2d22aa7c0bfda4f55e71a0bee74cbf3176d97536ef3",
|
||||
"sha256:e38bffc89b15bafe2a131f0e1c74924cf07dcec020c2e0a26cccd208831fcd43"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.10.3"
|
||||
"version": "==0.10.4"
|
||||
},
|
||||
"wcwidth": {
|
||||
"hashes": [
|
||||
@@ -518,6 +807,14 @@
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.7.4"
|
||||
},
|
||||
"zipp": {
|
||||
"hashes": [
|
||||
"sha256:102c24ef8f171fd729d46599845e95c7ab894a4cf45f5de11a44cc7444fb1108",
|
||||
"sha256:ed5eee1974372595f9e416cc7bbeeb12335201d8081ca8a0743c954d4446e5cb"
|
||||
],
|
||||
"markers": "python_version >= '3.6'",
|
||||
"version": "==3.4.0"
|
||||
}
|
||||
},
|
||||
"develop": {
|
||||
@@ -571,6 +868,7 @@
|
||||
"sha256:84ab92ed1c4d4f16916e05906b6b75a6c0fb5db821cc65e70cbd64a3e2a5eaae",
|
||||
"sha256:fc323ffcaeaed0e0a02bf4d117757b98aed530d9ed4531e3e15460124c106691"
|
||||
],
|
||||
"markers": "python_version >= '3.1'",
|
||||
"version": "==3.0.4"
|
||||
},
|
||||
"coverage": {
|
||||
@@ -617,11 +915,11 @@
|
||||
},
|
||||
"coveralls": {
|
||||
"hashes": [
|
||||
"sha256:4430b862baabb3cf090d36d84d331966615e4288d8a8c5957e0fd456d0dd8bd6",
|
||||
"sha256:b3b60c17b03a0dee61952a91aed6f131e0b2ac8bd5da909389c53137811409e1"
|
||||
"sha256:2301a19500b06649d2ec4f2858f9c69638d7699a4c63027c5d53daba666147cc",
|
||||
"sha256:b990ba1f7bc4288e63340be0433698c1efe8217f78c689d254c2540af3d38617"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.1.2"
|
||||
"version": "==2.2.0"
|
||||
},
|
||||
"distlib": {
|
||||
"hashes": [
|
||||
@@ -663,11 +961,11 @@
|
||||
},
|
||||
"faker": {
|
||||
"hashes": [
|
||||
"sha256:4d038ba51ae5e0a956d79cadd684d856e5750bfd608b61dad1807f8f08b1da49",
|
||||
"sha256:f260f0375a44cd1e1a735c9b8c9b914304f607b5eef431d20e098c7c2f5b50a6"
|
||||
"sha256:7bca5b074299ac6532be2f72979e6793f1a2403ca8105cb4cf0b385a964469c4",
|
||||
"sha256:fb21a76064847561033d8cab1cfd11af436ddf2c6fe72eb51b3cda51dff86bdc"
|
||||
],
|
||||
"markers": "python_version >= '3.5'",
|
||||
"version": "==4.16.0"
|
||||
"version": "==5.0.0"
|
||||
},
|
||||
"filelock": {
|
||||
"hashes": [
|
||||
@@ -693,6 +991,22 @@
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==1.2.0"
|
||||
},
|
||||
"importlib-metadata": {
|
||||
"hashes": [
|
||||
"sha256:6112e21359ef8f344e7178aa5b72dc6e62b38b0d008e6d3cb212c5b84df72013",
|
||||
"sha256:b0c2d3b226157ae4517d9625decf63591461c66b3a808c2666d538946519d170"
|
||||
],
|
||||
"markers": "python_version < '3.8'",
|
||||
"version": "==3.1.1"
|
||||
},
|
||||
"importlib-resources": {
|
||||
"hashes": [
|
||||
"sha256:7b51f0106c8ec564b1bef3d9c588bc694ce2b92125bbb6278f4f2f5b54ec3592",
|
||||
"sha256:a3d34a8464ce1d5d7c92b0ea4e921e696d86f2aa212e684451cb1482c8d84ed5"
|
||||
],
|
||||
"markers": "python_version < '3.7'",
|
||||
"version": "==3.3.0"
|
||||
},
|
||||
"iniconfig": {
|
||||
"hashes": [
|
||||
"sha256:011e24c64b7f47f6ebd835bb12a743f2fbe9a26d4cecaa7f53bc4f35ee9da8b3",
|
||||
@@ -754,11 +1068,11 @@
|
||||
},
|
||||
"packaging": {
|
||||
"hashes": [
|
||||
"sha256:4357f74f47b9c12db93624a82154e9b120fa8293699949152b22065d556079f8",
|
||||
"sha256:998416ba6962ae7fbd6596850b80e17859a5753ba17c32284f67bfff33784181"
|
||||
"sha256:05af3bb85d320377db281cf254ab050e1a7ebcbf5410685a9a407e18a1f81236",
|
||||
"sha256:eb41423378682dadb7166144a4926e443093863024de508ca5c9737d6bc08376"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==20.4"
|
||||
"version": "==20.7"
|
||||
},
|
||||
"pluggy": {
|
||||
"hashes": [
|
||||
@@ -999,11 +1313,19 @@
|
||||
},
|
||||
"virtualenv": {
|
||||
"hashes": [
|
||||
"sha256:b0011228208944ce71052987437d3843e05690b2f23d1c7da4263fde104c97a2",
|
||||
"sha256:b8d6110f493af256a40d65e29846c69340a947669eec8ce784fcf3dd3af28380"
|
||||
"sha256:07cff122e9d343140366055f31be4dcd61fd598c69d11cd33a9d9c8df4546dd7",
|
||||
"sha256:e0aac7525e880a429764cefd3aaaff54afb5d9f25c82627563603f5d7de5a6e5"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version not in '3.0, 3.1, 3.2, 3.3'",
|
||||
"version": "==20.1.0"
|
||||
"version": "==20.2.1"
|
||||
},
|
||||
"zipp": {
|
||||
"hashes": [
|
||||
"sha256:102c24ef8f171fd729d46599845e95c7ab894a4cf45f5de11a44cc7444fb1108",
|
||||
"sha256:ed5eee1974372595f9e416cc7bbeeb12335201d8081ca8a0743c954d4446e5cb"
|
||||
],
|
||||
"markers": "python_version >= '3.6'",
|
||||
"version": "==3.4.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
69
README.md
@@ -15,7 +15,7 @@ This project is still in development and some things may not work as expected.
|
||||
|
||||
Paperless does not control your scanner, it only helps you deal with what your scanner produces.
|
||||
|
||||
1. Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the [scanner recommendations](https://paperless.readthedocs.io/en/latest/scanners.html) page.
|
||||
1. Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the [scanner recommendations](https://paperless-ng.readthedocs.io/en/latest/scanners.html) page.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push scanned images to a server without you having to do anything. Of course if your scanner doesn't know how to automatically upload the file somewhere, you can always do that manually. Paperless doesn't care how the documents get into its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the file and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
@@ -23,62 +23,85 @@ Paperless does not control your scanner, it only helps you deal with what your s
|
||||
|
||||
Here's what you get:
|
||||
|
||||
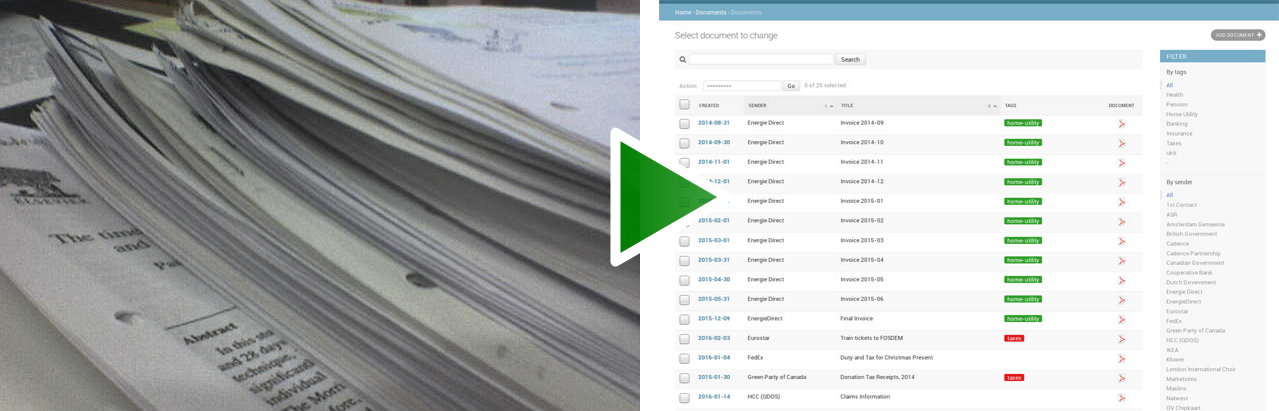
|
||||

|
||||
|
||||
# Why Paperless-ng?
|
||||
# Features
|
||||
|
||||
I wanted to make big changes to the project that will impact the way it is used by its users greatly. Among the users who currently use paperless in production there are probably many that don't want these changes right away. I also wanted to have more control over what goes into the code and what does not. Therefore, paperless-ng was created. NG stands for both Angular (the framework used for the Frontend) and next-gen. Publishing this project under a different name also avoids confusion between paperless and paperless-ng.
|
||||
|
||||
The gist of the changes is the following:
|
||||
|
||||
* New front end. This will eventually be mobile friendly as well.
|
||||
* New full text search.
|
||||
* Performs OCR on your documents, adds selectable text to image only documents and adds tags, correspondents and document types to your documents.
|
||||
* Single page application front end. Should be pretty snappy. Will be mobile friendly in the future.
|
||||
* Includes a dashboard that shows basic statistics and has document upload.
|
||||
* Filtering by tags, correspondents, types, and more.
|
||||
* Customizable views can be saved and displayed on the dashboard.
|
||||
* Full text search with auto completion, scored results and query highlighting allows you to quickly find what you need.
|
||||
* Email processing: Paperless adds documents from your email accounts.
|
||||
* Configure multiple accounts and filters for each account.
|
||||
* When adding documents from mails, paperless can move these mails to a new folder, mark them as read, flag them or delete them.
|
||||
* Machine learning powered document matching.
|
||||
* Code cleanup in many, MANY areas.
|
||||
* Paperless learns from your documents and will be able to automatically assign tags, correspondents and types to documents once you've stored a few documents in paperless.
|
||||
* A task processor that processes documents in parallel and also tells you when something goes wrong. On modern multi core systems, consumption is blazing fast.
|
||||
* Code cleanup in many, MANY areas. Some of the code from OG paperless was just overly complicated.
|
||||
* More tests, more stability.
|
||||
|
||||
If you want to see some screenshots of paperless-ng in action, [some are available in the documentation](https://paperless-ng.readthedocs.io/en/latest/screenshots.html).
|
||||
|
||||
For a complete list of changes, check out the [changelog](https://paperless-ng.readthedocs.io/en/latest/changelog.html)
|
||||
For a complete list of changes from paperless, check out the [changelog](https://paperless-ng.readthedocs.io/en/latest/changelog.html)
|
||||
|
||||
## Planned
|
||||
# Roadmap for 1.0
|
||||
|
||||
These features will make it into the application at some point, sorted by priority.
|
||||
- Make the front end nice (except mobile).
|
||||
- Test coverage at 90%.
|
||||
- Store archived documents with an embedded OCR text layer, while keeping originals available. Making good progress in the `feature-ocrmypdf` branch.
|
||||
- Fix whatever bugs I and you find.
|
||||
|
||||
## Roadmap for versions beyond 1.0
|
||||
|
||||
These are things that I want to add to paperless eventually. They are sorted by priority.
|
||||
|
||||
- **Bulk editing**. Add/remove metadata from multiple documents at once.
|
||||
- **More search.** The search backend is incredibly versatile and customizable. Searching is the most important feature of this project and thus, I want to implement things like:
|
||||
- Group and limit search results by correspondent, show “more from this” links in the results.
|
||||
- Ability to search for “Similar documents” in the search results
|
||||
- Provide corrections for mispelled queries
|
||||
- **More robust consumer** that shows its progress on the web page.
|
||||
- **More rigid email processing**. Like, dont delete imported mail, provide filters, etc...
|
||||
- **Nested tags**. Organize tags in a hierarchical structure. This will combine the benefits of folders and tags in one coherent system.
|
||||
- **An interactive consumer** that shows its progress for documents it processes on the web page.
|
||||
- With live updates ans websockets. This already works on a dev branch, but requires a lot of new dependencies, which I'm not particular happy about.
|
||||
- Notifications when a document was added with buttons to open the new document right away.
|
||||
- **Arbitrary tag colors**. Allow the selection of any color with a color picker.
|
||||
|
||||
## On the chopping block.
|
||||
|
||||
I don't know if these features are used all that much. I don't exactly know how they work and will probably remove them at some point in the future.
|
||||
|
||||
- **GnuPG encrypion.** Since its disabled by default and the website allows transparent access to encrypted documents anyway, this doesn’t really provide any benefit over having the application stored on an encrypted file system.
|
||||
- **GnuPG encrypion.** [Here's a note about encryption in paperless](https://paperless-ng.readthedocs.io/en/latest/administration.html#managing-encryption). The gist of it is that I don't see which attacks this implementation protects against. It gives a false sense of security to users who don't care about how it works.
|
||||
|
||||
# Getting started
|
||||
|
||||
The recommended way to deploy paperless is docker-compose. Use the provided docker-compose.yml files to get started. This pulls the image from Docker hub. Alternatively, you can build the image yourself.
|
||||
The recommended way to deploy paperless is docker-compose. Don't clone the repository, grab the latest release to get started instead. The dockerfiles archive contains just the docker files which will pull the image from docker hub. The source archive contains everything you need to build the docker image yourself (i.e. if you want to run on Raspberry Pi).
|
||||
|
||||
Read the [documentation](https://paperless-ng.readthedocs.io/en/latest/setup.html#installation) on how to get started.
|
||||
|
||||
Alternatively, you can install the dependencies and setup apache and a database server yourself. Details for that will be available in the documentation.
|
||||
Alternatively, you can install the dependencies and setup apache and a database server yourself. The documenation has information about the individual components of paperless that you need to take care of.
|
||||
|
||||
# Migrating to paperless-ng
|
||||
|
||||
Read the section about [migration](https://paperless-ng.readthedocs.io/en/latest/setup.html#migration-to-paperless-ng) in the documentation.
|
||||
Read the section about [migration](https://paperless-ng.readthedocs.io/en/latest/setup.html#migration-to-paperless-ng) in the documentation. Its also entirely possible to go back to paperless by reverting the database migrations.
|
||||
|
||||
# Documentation
|
||||
|
||||
The documentation for Paperless-ng is available on [ReadTheDocs](https://paperless-ng.readthedocs.io/).
|
||||
|
||||
# Suggestions? Questions? Something not working?
|
||||
|
||||
Please open an issue and start a discussion about it!
|
||||
|
||||
## Feel like helping out?
|
||||
|
||||
There's still lots of things to be done, just have a look at that issue log. If you feel like contributing to the project, please do! Bug fixes and improvements to the front end (I just can't seem to get some of these CSS things right) are always welcome. The documentation has some basic information on how to get started.
|
||||
|
||||
If you want to implement something big: Please start a discussion about that in the issues! Maybe I've already had something similar in mind and we can make it happen together. However, keep in mind that the general roadmap is to make the existing features stable and get them tested. See the roadmap above.
|
||||
|
||||
# Affiliated Projects
|
||||
|
||||
Paperless has been around a while now, and people are starting to build stuff on top of it. If you're one of those people, we can add your project to this list:
|
||||
|
||||
* [Paperless App](https://github.com/bauerj/paperless_app): An Android/iOS app for Paperless.
|
||||
* [Paperless App](https://github.com/bauerj/paperless_app): An Android/iOS app for Paperless. We're working on making this compatible.
|
||||
* [Paperless Desktop](https://github.com/thomasbrueggemann/paperless-desktop): A desktop UI for your Paperless installation. Runs on Mac, Linux, and Windows.
|
||||
* [ansible-role-paperless](https://github.com/ovv/ansible-role-paperless): An easy way to get Paperless running via Ansible.
|
||||
* [paperless-cli](https://github.com/stgarf/paperless-cli): A golang command line binary to interact with a Paperless instance.
|
||||
|
||||
@@ -32,8 +32,3 @@
|
||||
# The default language to use for OCR. Set this to the language most of your
|
||||
# documents are written in.
|
||||
#PAPERLESS_OCR_LANGUAGE=eng
|
||||
|
||||
# By default Paperless does not OCR a document if the text can be retrieved from
|
||||
# the document directly. Set to true to always OCR documents. (i.e., if you
|
||||
# know that some of your documents have faulty/bad OCR data)
|
||||
#PAPERLESS_OCR_ALWAYS=true
|
||||
|
||||
@@ -15,8 +15,42 @@ map_uidgid() {
|
||||
fi
|
||||
}
|
||||
|
||||
|
||||
wait_for_postgres() {
|
||||
attempt_num=1
|
||||
max_attempts=5
|
||||
|
||||
echo "Waiting for PostgreSQL to start..."
|
||||
|
||||
host="${PAPERLESS_DBHOST}"
|
||||
|
||||
while !</dev/tcp/$host/5432 ;
|
||||
do
|
||||
|
||||
if [ $attempt_num -eq $max_attempts ]
|
||||
then
|
||||
echo "Unable to connect to database."
|
||||
exit 1
|
||||
else
|
||||
echo "Attempt $attempt_num failed! Trying again in 5 seconds..."
|
||||
|
||||
fi
|
||||
|
||||
attempt_num=$(expr "$attempt_num" + 1)
|
||||
sleep 5
|
||||
done
|
||||
|
||||
|
||||
}
|
||||
|
||||
|
||||
migrations() {
|
||||
|
||||
if [[ -n "${PAPERLESS_DBHOST}" ]]
|
||||
then
|
||||
wait_for_postgres
|
||||
fi
|
||||
|
||||
(
|
||||
# flock is in place to prevent multiple containers from doing migrations
|
||||
# simultaneously. This also ensures that the db is ready when the command
|
||||
|
||||
@@ -15,7 +15,7 @@ services:
|
||||
POSTGRES_PASSWORD: paperless
|
||||
|
||||
webserver:
|
||||
image: jonaswinkler/paperless-ng:0.9
|
||||
image: jonaswinkler/paperless-ng:0.9.5
|
||||
restart: always
|
||||
depends_on:
|
||||
- db
|
||||
@@ -5,7 +5,7 @@ services:
|
||||
restart: always
|
||||
|
||||
webserver:
|
||||
image: jonaswinkler/paperless-ng:0.9
|
||||
image: jonaswinkler/paperless-ng:0.9.5
|
||||
restart: always
|
||||
depends_on:
|
||||
- broker
|
||||
|
||||
@@ -1,7 +1,3 @@
|
||||
###############################################################################
|
||||
### Back end ###
|
||||
###############################################################################
|
||||
|
||||
FROM python:3.7-slim
|
||||
|
||||
WORKDIR /usr/src/paperless/
|
||||
@@ -15,12 +11,17 @@ RUN apt-get update \
|
||||
curl \
|
||||
ghostscript \
|
||||
gnupg \
|
||||
icc-profiles-free \
|
||||
imagemagick \
|
||||
libatlas-base-dev \
|
||||
liblept5 \
|
||||
libmagic-dev \
|
||||
libpoppler-cpp-dev \
|
||||
libpq-dev \
|
||||
libxml2 \
|
||||
optipng \
|
||||
pngquant \
|
||||
qpdf \
|
||||
sudo \
|
||||
tesseract-ocr \
|
||||
tesseract-ocr-eng \
|
||||
@@ -30,6 +31,7 @@ RUN apt-get update \
|
||||
tesseract-ocr-spa \
|
||||
tzdata \
|
||||
unpaper \
|
||||
zlib1g \
|
||||
&& pip3 install --upgrade supervisor setuptools \
|
||||
&& pip install --no-cache-dir -r requirements.txt \
|
||||
&& apt-get -y purge build-essential \
|
||||
|
||||
BIN
docs/_static/paperless-0-dashboard.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 52 KiB |
BIN
docs/_static/paperless-1-list-table.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 62 KiB |
BIN
docs/_static/paperless-10-mobile.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 56 KiB |
BIN
docs/_static/paperless-11-mail-filters.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 70 KiB |
BIN
docs/_static/paperless-2-list-smallcards.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 256 KiB |
BIN
docs/_static/paperless-3-list-largecards.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 224 KiB |
BIN
docs/_static/paperless-4-filter.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 101 KiB |
BIN
docs/_static/paperless-5-editing.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 196 KiB |
BIN
docs/_static/paperless-6-tags.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 50 KiB |
BIN
docs/_static/paperless-7-autocomplete.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 53 KiB |
BIN
docs/_static/paperless-8-search-results.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 214 KiB |
BIN
docs/_static/paperless-9-admin.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 50 KiB |
BIN
docs/_static/screenshots/correspondents.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 106 KiB |
BIN
docs/_static/screenshots/dashboard.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 167 KiB |
BIN
docs/_static/screenshots/documents-filter.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 28 KiB |
BIN
docs/_static/screenshots/documents-largecards.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 306 KiB |
BIN
docs/_static/screenshots/documents-smallcards.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 410 KiB |
BIN
docs/_static/screenshots/documents-table.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 137 KiB |
BIN
docs/_static/screenshots/editing.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 293 KiB |
BIN
docs/_static/screenshots/logs.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 260 KiB |
BIN
docs/_static/screenshots/mail-rules-edited.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 96 KiB |
BIN
docs/_static/screenshots/mobile.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 158 KiB |
BIN
docs/_static/screenshots/new-tag.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
docs/_static/screenshots/search-preview.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
BIN
docs/_static/screenshots/search-results.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 261 KiB |
@@ -30,7 +30,7 @@ Options available to docker installations:
|
||||
Paperless uses 3 volumes:
|
||||
|
||||
* ``paperless_media``: This is where your documents are stored.
|
||||
* ``paperless_data``: This is where auxilliary data is stored. This
|
||||
* ``paperless_data``: This is where auxillary data is stored. This
|
||||
folder also contains the SQLite database, if you use it.
|
||||
* ``paperless_pgdata``: Exists only if you use PostgreSQL and contains
|
||||
the database.
|
||||
@@ -69,7 +69,7 @@ First of all, ensure that paperless is stopped.
|
||||
|
||||
After that, :ref:`make a backup <administration-backup>`.
|
||||
|
||||
A. If you used the docker-compose file, simply download the files of the new release,
|
||||
A. If you used the dockerfiles archive, simply download the files of the new release,
|
||||
adjust the settings in the files (i.e., the path to your consumption directory),
|
||||
and replace your existing docker-compose files. Then start paperless as usual,
|
||||
which will pull the new image, and update your database, if necessary:
|
||||
@@ -82,6 +82,13 @@ A. If you used the docker-compose file, simply download the files of the new re
|
||||
If you see everything working, you can start paperless-ng with "-d" to have it
|
||||
run in the background.
|
||||
|
||||
.. hint::
|
||||
|
||||
The released docker-compose files specify exact versions to be pulled from the hub.
|
||||
This is to ensure that if the docker-compose files should change at some point
|
||||
(i.e., services updates/configured differently), you wont run into trouble due to
|
||||
docker pulling the ``latest`` image and running it in an older environment.
|
||||
|
||||
B. If you built the image yourself, grab the new archive and replace your current
|
||||
paperless folder with the new contents.
|
||||
|
||||
@@ -102,7 +109,7 @@ B. If you built the image yourself, grab the new archive and replace your curre
|
||||
.. hint::
|
||||
|
||||
You can usually keep your ``docker-compose.env`` file, since this file will
|
||||
never include mandantory configuration options. However, it is worth checking
|
||||
never include mandatory configuration options. However, it is worth checking
|
||||
out the new version of this file, since it might have new recommendations
|
||||
on what to configure.
|
||||
|
||||
@@ -119,6 +126,7 @@ After grabbing the new release and unpacking the contents, do the following:
|
||||
|
||||
$ pip install --upgrade pipenv
|
||||
$ cd /path/to/paperless
|
||||
$ pipenv clean
|
||||
$ pipenv install
|
||||
|
||||
This creates a new virtual environment (or uses your existing environment)
|
||||
@@ -143,7 +151,7 @@ Management utilities
|
||||
####################
|
||||
|
||||
Paperless comes with some management commands that perform various maintenance
|
||||
tasks on your paperless instance. You can invoce these commands either by
|
||||
tasks on your paperless instance. You can invoke these commands either by
|
||||
|
||||
.. code:: bash
|
||||
|
||||
@@ -239,12 +247,12 @@ your already processed documents.
|
||||
|
||||
When multiple document types or correspondents match a single document,
|
||||
the retagger won't assign these to the document. Specify ``--use-first``
|
||||
to override this behaviour and just use the first correspondent or type
|
||||
to override this behavior and just use the first correspondent or type
|
||||
it finds. This option does not apply to tags, since any amount of tags
|
||||
can be applied to a document.
|
||||
|
||||
Finally, ``-f`` specifies that you wish to overwrite already assigned
|
||||
correspondents, types and/or tags. The default behaviour is to not
|
||||
correspondents, types and/or tags. The default behavior is to not
|
||||
assign correspondents and types to documents that have this data already
|
||||
assigned. ``-f`` works differently for tags: By default, only additional tags get
|
||||
added to documents, no tags will be removed. With ``-f``, tags that don't
|
||||
@@ -266,6 +274,7 @@ management command:
|
||||
|
||||
This command takes no arguments.
|
||||
|
||||
.. _`administration-index`:
|
||||
|
||||
Managing the document search index
|
||||
==================================
|
||||
@@ -311,6 +320,55 @@ the naming scheme.
|
||||
The command takes no arguments and processes all your documents at once.
|
||||
|
||||
|
||||
Fetching e-mail
|
||||
===============
|
||||
|
||||
Paperless automatically fetches your e-mail every 10 minutes by default. If
|
||||
you want to invoke the email consumer manually, call the following management
|
||||
command:
|
||||
|
||||
.. code::
|
||||
|
||||
mail_fetcher
|
||||
|
||||
The command takes no arguments and processes all your mail accounts and rules.
|
||||
|
||||
.. _utilities-archiver:
|
||||
|
||||
Creating archived documents
|
||||
===========================
|
||||
|
||||
Paperless stores archived PDF/A documents alongside your original documents.
|
||||
These archived documents will also contain selectable text for image-only
|
||||
originals.
|
||||
These documents are derived from the originals, which are always stored
|
||||
unmodified. If coming from an earlier version of paperless, your documents
|
||||
won't have archived versions.
|
||||
|
||||
This command creates PDF/A documents for your documents.
|
||||
|
||||
.. code::
|
||||
|
||||
document_archiver --overwrite --document <id>
|
||||
|
||||
This command will only attempt to create archived documents when no archived
|
||||
document exists yet, unless ``--overwrite`` is specified. If ``--document <id>``
|
||||
is specified, the archiver will only process that document.
|
||||
|
||||
.. note::
|
||||
|
||||
This command essentially performs OCR on all your documents again,
|
||||
according to your settings. If you run this with ``PAPERLESS_OCR_MODE=redo``,
|
||||
it will potentially run for a very long time. You can cancel the command
|
||||
at any time, since this command will skip already archived versions the next time
|
||||
it is run.
|
||||
|
||||
.. note::
|
||||
|
||||
Some documents will cause errors and cannot be converted into PDF/A documents,
|
||||
such as encrypted PDF documents. The archiver will skip over these Documents
|
||||
each time it sees them.
|
||||
|
||||
.. _utilities-encyption:
|
||||
|
||||
Managing encryption
|
||||
@@ -320,7 +378,7 @@ Documents can be stored in Paperless using GnuPG encryption.
|
||||
|
||||
.. danger::
|
||||
|
||||
Decryption is depreceated since paperless-ng 0.9 and doesn't really provide any
|
||||
Encryption is deprecated since paperless-ng 0.9 and doesn't really provide any
|
||||
additional security, since you have to store the passphrase in a configuration
|
||||
file on the same system as the encrypted documents for paperless to work.
|
||||
Furthermore, the entire text content of the documents is stored plain in the
|
||||
@@ -332,39 +390,23 @@ Documents can be stored in Paperless using GnuPG encryption.
|
||||
Consider running paperless on an encrypted filesystem instead, which will then
|
||||
at least provide security against physical hardware theft.
|
||||
|
||||
.. code::
|
||||
|
||||
change_storage_type [--passphrase PASSPHRASE] {gpg,unencrypted} {gpg,unencrypted}
|
||||
|
||||
positional arguments:
|
||||
{gpg,unencrypted} The state you want to change your documents from
|
||||
{gpg,unencrypted} The state you want to change your documents to
|
||||
|
||||
optional arguments:
|
||||
--passphrase PASSPHRASE
|
||||
|
||||
Enabling encryption
|
||||
-------------------
|
||||
|
||||
Basic usage to enable encryption of your document store (**USE A MORE SECURE PASSPHRASE**):
|
||||
|
||||
(Note: If ``PAPERLESS_PASSPHRASE`` isn't set already, you need to specify it here)
|
||||
|
||||
.. code::
|
||||
|
||||
change_storage_type [--passphrase SECR3TP4SSPHRA$E] unencrypted gpg
|
||||
Enabling encryption is no longer supported.
|
||||
|
||||
|
||||
Disabling encryption
|
||||
--------------------
|
||||
|
||||
Basic usage to enable encryption of your document store:
|
||||
Basic usage to disable encryption of your document store:
|
||||
|
||||
(Note: Again, if ``PAPERLESS_PASSPHRASE`` isn't set already, you need to specify it here)
|
||||
(Note: If ``PAPERLESS_PASSPHRASE`` isn't set already, you need to specify it here)
|
||||
|
||||
.. code::
|
||||
|
||||
change_storage_type [--passphrase SECR3TP4SSPHRA$E] gpg unencrypted
|
||||
decrypt_documents [--passphrase SECR3TP4SSPHRA$E]
|
||||
|
||||
|
||||
.. _Pipenv: https://pipenv.pypa.io/en/latest/
|
||||
@@ -52,6 +52,8 @@ filename as described above.
|
||||
|
||||
.. _dateparser: https://github.com/scrapinghub/dateparser/blob/v0.7.0/docs/usage.rst#settings
|
||||
|
||||
.. _advanced-transforming_filenames:
|
||||
|
||||
Transforming filenames for parsing
|
||||
==================================
|
||||
|
||||
@@ -82,6 +84,8 @@ to the filename.
|
||||
PAPERLESS_FILENAME_PARSE_TRANSFORMS=[{"pattern":"^([a-z]+)_(\\d{8})_(\\d{6})_([0-9]+)\\.", "repl":"\\2\\3Z - \\4 - \\1."}, {"pattern":"^([a-z]+)_([0-9]+)\\.", "repl":" - \\2 - \\1."}]
|
||||
|
||||
|
||||
.. _advanced-matching:
|
||||
|
||||
Matching tags, correspondents and document types
|
||||
################################################
|
||||
|
||||
@@ -143,7 +147,9 @@ America are tagged with the tag "bofa_123" and the matching algorithm of this
|
||||
tag is set to *Auto*, this neural network will examine your documents and
|
||||
automatically learn when to assign this tag.
|
||||
|
||||
There are a couple caveats you need to keep in mind when using this feature:
|
||||
Paperless tries to hide much of the involved complexity with this approach.
|
||||
However, there are a couple caveats you need to keep in mind when using this
|
||||
feature:
|
||||
|
||||
* Changes to your documents are not immediately reflected by the matching
|
||||
algorithm. The neural network needs to be *trained* on your documents after
|
||||
@@ -163,6 +169,11 @@ There are a couple caveats you need to keep in mind when using this feature:
|
||||
has the correspondent "Very obscure web shop I bought something five years
|
||||
ago", it will probably not assign this correspondent automatically if you buy
|
||||
something from them again. The more documents, the better.
|
||||
* Paperless also needs a reasonable amount of negative examples to decide when
|
||||
not to assign a certain tag, correspondent or type. This will usually be the
|
||||
case as you start filling up paperless with documents. Example: If all your
|
||||
documents are either from "Webshop" and "Bank", paperless will assign one of
|
||||
these correspondents to ANY new document, if both are set to automatic matching.
|
||||
|
||||
Hooking into the consumption process
|
||||
####################################
|
||||
@@ -219,6 +230,7 @@ the consumption process will begin with the newly modified file.
|
||||
|
||||
.. _pdf2pdfocr.py: https://github.com/LeoFCardoso/pdf2pdfocr
|
||||
|
||||
.. _advanced-post_consume_script:
|
||||
|
||||
Post-consumption script
|
||||
=======================
|
||||
@@ -250,7 +262,7 @@ By default, paperless stores your documents in the media directory and renames t
|
||||
using the identifier which it has assigned to each document. You will end up getting
|
||||
files like ``0000123.pdf`` in your media directory. This isn't necessarily a bad
|
||||
thing, because you normally don't have to access these files manually. However, if
|
||||
you wish to name your files differently, you can do that by adjustng the
|
||||
you wish to name your files differently, you can do that by adjusting the
|
||||
``PAPERLESS_FILENAME_FORMAT`` settings variable.
|
||||
|
||||
This variable allows you to configure the filename (folders are allowed!) using
|
||||
@@ -275,7 +287,7 @@ will create a directory structure as follows:
|
||||
my_new_shoes-0000004.pdf
|
||||
|
||||
Paperless appends the unique identifier of each document to the filename. This
|
||||
avoides filename clashes.
|
||||
avoids filename clashes.
|
||||
|
||||
.. danger::
|
||||
|
||||
|
||||
71
docs/api.rst
@@ -38,6 +38,50 @@ individual documents:
|
||||
are in place. However, if you use these old URLs to access documents, you
|
||||
should update your app or script to use the new URLs.
|
||||
|
||||
.. note::
|
||||
|
||||
The document endpoint provides tags, document types and correspondents as
|
||||
ids in their corresponding fields. These are writeable. Paperless also
|
||||
offers read-only objects for assigned tags, types and correspondents,
|
||||
however, these might be removed in the future. As for now, the front end
|
||||
requires them.
|
||||
|
||||
Authorization
|
||||
#############
|
||||
|
||||
The REST api provides three different forms of authentication.
|
||||
|
||||
1. Basic authentication
|
||||
|
||||
Authorize by providing a HTTP header in the form
|
||||
|
||||
.. code::
|
||||
|
||||
Authorization: Basic <credentials>
|
||||
|
||||
where ``credentials`` is a base64-encoded string of ``<username>:<password>``
|
||||
|
||||
2. Session authentication
|
||||
|
||||
When you're logged into paperless in your browser, you're automatically
|
||||
logged into the API as well and don't need to provide any authorization
|
||||
headers.
|
||||
|
||||
3. Token authentication
|
||||
|
||||
Paperless also offers an endpoint to acquire authentication tokens.
|
||||
|
||||
POST a username and password as a form or json string to ``/api/token/``
|
||||
and paperless will respond with a token, if the login data is correct.
|
||||
This token can be used to authenticate other requests with the
|
||||
following HTTP header:
|
||||
|
||||
.. code::
|
||||
|
||||
Authorization: Token <token>
|
||||
|
||||
Tokens can be managed and revoked in the paperless admin.
|
||||
|
||||
Searching for documents
|
||||
#######################
|
||||
|
||||
@@ -65,6 +109,7 @@ Result list object returned by the endpoint:
|
||||
"count": 1,
|
||||
"page": 1,
|
||||
"page_count": 1,
|
||||
"corrected_query": "",
|
||||
"results": [
|
||||
|
||||
]
|
||||
@@ -75,6 +120,8 @@ Result list object returned by the endpoint:
|
||||
the page you requested, if you requested a page that is behind
|
||||
the last page. In that case, the last page is returned.
|
||||
* ``page_count``: The total number of pages.
|
||||
* ``corrected_query``: Corrected version of the query string. Can be null.
|
||||
If not null, can be used verbatim to start a new query.
|
||||
* ``results``: A list of result objects on the current page.
|
||||
|
||||
Result object:
|
||||
@@ -91,9 +138,10 @@ Result object:
|
||||
"document": {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
* ``id``: the primary key of the found document
|
||||
* ``highlights``: an object containing parseable highlights for the result.
|
||||
* ``highlights``: an object containing parsable highlights for the result.
|
||||
See below.
|
||||
* ``score``: The score assigned to the document. A higher score indicates a
|
||||
better match with the query. Search results are sorted descending by score.
|
||||
@@ -109,7 +157,7 @@ Each fragment contains a list of strings, and some of them are marked as a highl
|
||||
|
||||
.. code:: json
|
||||
|
||||
"highlights": [
|
||||
[
|
||||
[
|
||||
{"text": "This is a sample text with a "},
|
||||
{"text": "highlighted", "term": 0},
|
||||
@@ -120,6 +168,8 @@ Each fragment contains a list of strings, and some of them are marked as a highl
|
||||
{"text": " fragment with a highlight."}
|
||||
]
|
||||
]
|
||||
|
||||
|
||||
|
||||
When ``term`` is present within a string, the word within ``text`` should be highlighted.
|
||||
The term index groups multiple matches together and words with the same index
|
||||
@@ -163,8 +213,17 @@ The API provides a special endpoint for file uploads:
|
||||
|
||||
POST a multipart form to this endpoint, where the form field ``document`` contains
|
||||
the document that you want to upload to paperless. The filename is sanitized and
|
||||
then used to store the document in the consumption folder, where the consumer will
|
||||
detect the document and process it as any other document.
|
||||
then used to store the document in a temporary directory, and the consumer will
|
||||
be instructed to consume the document from there.
|
||||
|
||||
The endpoint will immediately return "OK." if the document was stored in the
|
||||
consumption directory.
|
||||
The endpoint supports the following optional form fields:
|
||||
|
||||
* ``title``: Specify a title that the consumer should use for the document.
|
||||
* ``correspondent``: Specify the ID of a correspondent that the consumer should use for the document.
|
||||
* ``document_type``: Similar to correspondent.
|
||||
* ``tags``: Similar to correspondent. Specify this multiple times to have multiple tags added
|
||||
to the document.
|
||||
|
||||
The endpoint will immediately return "OK" if the document consumption process
|
||||
was started successfully. No additional status information about the consumption
|
||||
process itself is available, since that happens in a different process.
|
||||
|
||||
@@ -5,6 +5,140 @@
|
||||
Changelog
|
||||
*********
|
||||
|
||||
paperless-ng 0.9.5
|
||||
##################
|
||||
|
||||
This release concludes the big changes I wanted to get rolled into paperless. The next releases before 1.0 will
|
||||
focus on fixing issues, primarily.
|
||||
|
||||
* OCR
|
||||
|
||||
* Paperless now uses `OCRmyPDF <https://github.com/jbarlow83/OCRmyPDF>`_ to perform OCR on documents.
|
||||
It still uses tesseract under the hood, but the PDF parser of Paperless has changed considerably and
|
||||
will behave different for some douments.
|
||||
* OCRmyPDF creates archived PDF/A documents with embedded text that can be selected in the front end.
|
||||
* Paperless stores archived versions of documents alongside with the originals. The originals can be
|
||||
accessed on the document edit page. If available, a dropdown menu will appear next to the download button.
|
||||
* Many of the configuration options regarding OCR have changed. See :ref:`configuration-ocr` for details.
|
||||
* Paperless no longer guesses the language of your documents. It always uses the language that you
|
||||
specified with ``PAPERLESS_OCR_LANGUAGE``. Be sure to set this to the language the majority of your
|
||||
documents are in. Multiple languages can be specified, but that requires more CPU time.
|
||||
* The management command :ref:`document_archiver <utilities-archiver>` can be used to create archived versions for already
|
||||
existing documents.
|
||||
|
||||
* Tags from consumption folder.
|
||||
|
||||
* Thanks to `jayme-github`_, paperless now consumes files from sub folders in the consumption folder and is able to assign tags
|
||||
based on the sub folders a document was found in. This can be configured with ``PAPERLESS_CONSUMER_RECURSIVE`` and
|
||||
``PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS``.
|
||||
|
||||
* API
|
||||
|
||||
* The API now offers token authentication.
|
||||
* The endpoint for uploading documents now supports specifying custom titles, correspondents, tags and types.
|
||||
This can be used by clients to override the default behavior of paperless. See :ref:`api-file_uploads`.
|
||||
* The document endpoint of API now serves documents in this form:
|
||||
|
||||
* correspondents, document types and tags are referenced by their ID in the fields ``correspondent``, ``document_type`` and ``tags``. The ``*_id`` versions are gone. These fields are read/write.
|
||||
* paperless does not serve nested tags, correspondents or types anymore.
|
||||
|
||||
* Front end
|
||||
|
||||
* Paperless does some basic caching of correspondents, tags and types and will only request them from the server when necessary or when entirely reloading the page.
|
||||
* Document list fetching is about 10%-30% faster now, especially when lots of tags/correspondents are present.
|
||||
* Some minor improvements to the front end, such as document count in the document list, better highlighting of the current page, and improvements to the filter behavior.
|
||||
|
||||
* Fixes:
|
||||
|
||||
* A bug with the generation of filenames for files with unsupported types caused the exporter and
|
||||
document saving to crash.
|
||||
* Mail handling no longer exits entirely when encountering errors. It will skip the account/rule/message on which the error occured.
|
||||
* Assigning correspondents from mail sender names failed for very long names. Paperless no longer assigns correspondents in these cases.
|
||||
|
||||
paperless-ng 0.9.4
|
||||
##################
|
||||
|
||||
* Searching:
|
||||
|
||||
* Paperless now supports searching by tags, types and dates and correspondents. In order to have this applied to your
|
||||
existing documents, you need to perform a ``document_index reindex`` management command
|
||||
(see :ref:`administration-index`)
|
||||
that adds the data to the search index. You only need to do this once, since the schema of the search index changed.
|
||||
Paperless keeps the index updated after that whenever something changes.
|
||||
* Paperless now has spelling corrections ("Did you mean") for miss-typed queries.
|
||||
* The documentation contains :ref:`information about the query syntax <basic-searching>`.
|
||||
|
||||
* Front end:
|
||||
|
||||
* Clickable tags, correspondents and types allow quick filtering for related documents.
|
||||
* Saved views are now editable.
|
||||
* Preview documents directly in the browser.
|
||||
* Navigation from the dashboard to saved views.
|
||||
|
||||
* Fixes:
|
||||
|
||||
* A severe error when trying to use post consume scripts.
|
||||
* An error in the consumer that cause invalid messages of missing files to show up in the log.
|
||||
|
||||
* The documentation now contains information about bare metal installs and a section about
|
||||
how to setup the development environment.
|
||||
|
||||
paperless-ng 0.9.3
|
||||
##################
|
||||
|
||||
* Setting ``PAPERLESS_AUTO_LOGIN_USERNAME`` replaces ``PAPERLESS_DISABLE_LOGIN``.
|
||||
You have to specify your username.
|
||||
* Added a simple sanity checker that checks your documents for missing or orphaned files,
|
||||
files with wrong checksums, inaccessible files, and documents with empty content.
|
||||
* It is no longer possible to encrypt your documents. For the time being, paperless will
|
||||
continue to operate with already encrypted documents.
|
||||
* Fixes:
|
||||
|
||||
* Paperless now uses inotify again, since the watchdog was causing issues which I was not
|
||||
aware of.
|
||||
* Issue with the automatic classifier not working with only one tag.
|
||||
* A couple issues with the search index being opened to eagerly.
|
||||
|
||||
* Added lots of tests for various parts of the application.
|
||||
|
||||
paperless-ng 0.9.2
|
||||
##################
|
||||
|
||||
* Major changes to the front end (colors, logo, shadows, layout of the cards,
|
||||
better mobile support)
|
||||
|
||||
* Paperless now uses mime types and libmagic detection to determine
|
||||
if a file type is supported and which parser to use. Removes all
|
||||
file type checks that where present in MANY different places in
|
||||
paperless.
|
||||
|
||||
* Mail consumer now correctly consumes documents even when their
|
||||
content type was not set correctly. (i.e. PDF documents with
|
||||
content type ``application/octet-stream``)
|
||||
|
||||
* Basic sorting of mail rules added
|
||||
|
||||
* Much better admin for mail rule editing.
|
||||
|
||||
* Docker entrypoint script awaits the database server if it is
|
||||
configured.
|
||||
|
||||
* Disabled editing of logs.
|
||||
|
||||
* New setting ``PAPERLESS_OCR_PAGES`` limits the tesseract parser
|
||||
to the first n pages of scanned documents.
|
||||
|
||||
* Fixed a bug where tasks with too long task names would not show
|
||||
up in the admin.
|
||||
|
||||
paperless-ng 0.9.1
|
||||
##################
|
||||
|
||||
* Moved documentation of the settings to the actual documentation.
|
||||
* Updated release script to force the user to choose between SQLite
|
||||
and PostgreSQL. This avoids confusion when upgrading from paperless.
|
||||
|
||||
|
||||
paperless-ng 0.9.0
|
||||
##################
|
||||
|
||||
@@ -14,7 +148,7 @@ paperless-ng 0.9.0
|
||||
* **Added:** New frontend. Features:
|
||||
|
||||
* Single page application: It's much more responsive than the django admin pages.
|
||||
* Dashboard. Shows recently scanned documents, or todos, or other documents
|
||||
* Dashboard. Shows recently scanned documents, or todo notes, or other documents
|
||||
at wish. Allows uploading of documents. Shows basic statistics.
|
||||
* Better document list with multiple display options.
|
||||
* Full text search with result highlighting, auto completion and scoring based
|
||||
@@ -64,9 +198,8 @@ paperless-ng 0.9.0
|
||||
|
||||
* **Modified [breaking]:** PostgreSQL:
|
||||
|
||||
* If ``PAPERLESS_DBHOST`` is specified in the settings, paperless uses postgresql instead of sqlite.
|
||||
* If ``PAPERLESS_DBHOST`` is specified in the settings, paperless uses PostgreSQL instead of SQLite.
|
||||
Username, database and password all default to ``paperless`` if not specified.
|
||||
* **docker-compose.yml uses PostgreSQL by default.**
|
||||
|
||||
* **Modified [breaking]:** document_retagger management command rework. See
|
||||
:ref:`utilities-retagger` for details. Replaces ``document_correspondents``
|
||||
@@ -93,7 +226,7 @@ paperless-ng 0.9.0
|
||||
Certain language specifics such as umlauts may not get picked up properly.
|
||||
* ``PAPERLESS_DEBUG`` defaults to ``false``.
|
||||
* The presence of ``PAPERLESS_DBHOST`` now determines whether to use PostgreSQL or
|
||||
sqlite.
|
||||
SQLite.
|
||||
* ``PAPERLESS_OCR_THREADS`` is gone and replaced with ``PAPERLESS_TASK_WORKERS`` and
|
||||
``PAPERLESS_THREADS_PER_WORKER``. Refer to the config example for details.
|
||||
* ``PAPERLESS_OPTIMIZE_THUMBNAILS`` allows you to disable or enable thumbnail
|
||||
@@ -101,8 +234,11 @@ paperless-ng 0.9.0
|
||||
|
||||
* Many more small changes here and there. The usual stuff.
|
||||
|
||||
Paperless
|
||||
#########
|
||||
|
||||
2.7.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* `syntonym`_ submitted a pull request to catch IMAP connection errors `#475`_.
|
||||
* `Stéphane Brunner`_ added ``psycopg2`` to the Pipfile `#489`_. He also fixed
|
||||
@@ -119,7 +255,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.6.1
|
||||
#####
|
||||
=====
|
||||
|
||||
* We now have a logo, complete with a favicon :-)
|
||||
* Removed some problematic tests.
|
||||
@@ -131,7 +267,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.6.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Allow an infinite number of logs to be deleted. Thanks to `Ulli`_ for noting
|
||||
the problem in `#433`_.
|
||||
@@ -152,7 +288,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.5.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* **New dependency**: Paperless now optimises thumbnail generation with
|
||||
`optipng`_, so you'll need to install that somewhere in your PATH or declare
|
||||
@@ -196,7 +332,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.4.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* A new set of actions are now available thanks to `jonaswinkler`_'s very first
|
||||
pull request! You can now do nifty things like tag documents in bulk, or set
|
||||
@@ -217,7 +353,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.3.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Support for consuming plain text & markdown documents was added by
|
||||
`Joshua Taillon`_! This was a long-requested feature, and it's addition is
|
||||
@@ -235,14 +371,14 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.2.1
|
||||
#####
|
||||
=====
|
||||
|
||||
* `Kyle Lucy`_ reported a bug quickly after the release of 2.2.0 where we broke
|
||||
the ``DISABLE_LOGIN`` feature: `#392`_.
|
||||
|
||||
|
||||
2.2.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Thanks to `dadosch`_, `Wolfgang Mader`_, and `Tim Brooks`_ this is the first
|
||||
version of Paperless that supports Django 2.0! As a result of their hard
|
||||
@@ -259,7 +395,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.1.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* `Enno Lohmeier`_ added three simple features that make Paperless a lot more
|
||||
user (and developer) friendly:
|
||||
@@ -278,7 +414,7 @@ paperless-ng 0.9.0
|
||||
|
||||
|
||||
2.0.0
|
||||
#####
|
||||
=====
|
||||
|
||||
This is a big release as we've changed a core-functionality of Paperless: we no
|
||||
longer encrypt files with GPG by default.
|
||||
@@ -310,7 +446,7 @@ Special thanks to `erikarvstedt`_, `matthewmoto`_, and `mcronce`_ who did the
|
||||
bulk of the work on this big change.
|
||||
|
||||
1.4.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* `Quentin Dawans`_ has refactored the document consumer to allow for some
|
||||
command-line options. Notably, you can now direct it to consume from a
|
||||
@@ -345,7 +481,7 @@ bulk of the work on this big change.
|
||||
to some excellent work from `erikarvstedt`_ on `#351`_
|
||||
|
||||
1.3.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* You can now run Paperless without a login, though you'll still have to create
|
||||
at least one user. This is thanks to a pull-request from `matthewmoto`_:
|
||||
@@ -368,7 +504,7 @@ bulk of the work on this big change.
|
||||
problem and helping me find where to fix it.
|
||||
|
||||
1.2.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* New Docker image, now based on Alpine, thanks to the efforts of `addadi`_
|
||||
and `Pit`_. This new image is dramatically smaller than the Debian-based
|
||||
@@ -387,7 +523,7 @@ bulk of the work on this big change.
|
||||
in the document text.
|
||||
|
||||
1.1.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Fix for `#283`_, a redirect bug which broke interactions with
|
||||
paperless-desktop. Thanks to `chris-aeviator`_ for reporting it.
|
||||
@@ -397,7 +533,7 @@ bulk of the work on this big change.
|
||||
`Dan Panzarella`_
|
||||
|
||||
1.0.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Upgrade to Django 1.11. **You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
@@ -416,14 +552,14 @@ bulk of the work on this big change.
|
||||
`Lukas Winkler`_'s issue `#278`_
|
||||
|
||||
0.8.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Paperless can now run in a subdirectory on a host (``/paperless``), rather
|
||||
than always running in the root (``/``) thanks to `maphy-psd`_'s work on
|
||||
`#255`_.
|
||||
|
||||
0.7.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* **Potentially breaking change**: As per `#235`_, Paperless will no longer
|
||||
automatically delete documents attached to correspondents when those
|
||||
@@ -435,7 +571,7 @@ bulk of the work on this big change.
|
||||
`Kusti Skytén`_ for posting the correct solution in the Github issue.
|
||||
|
||||
0.6.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Abandon the shared-secret trick we were using for the POST API in favour
|
||||
of BasicAuth or Django session.
|
||||
@@ -449,7 +585,7 @@ bulk of the work on this big change.
|
||||
the help with this feature.
|
||||
|
||||
0.5.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Support for fuzzy matching in the auto-tagger & auto-correspondent systems
|
||||
thanks to `Jake Gysland`_'s patch `#220`_.
|
||||
@@ -467,13 +603,13 @@ bulk of the work on this big change.
|
||||
* Amended the Django Admin configuration to have nice headers (`#230`_)
|
||||
|
||||
0.4.1
|
||||
#####
|
||||
=====
|
||||
|
||||
* Fix for `#206`_ wherein the pluggable parser didn't recognise files with
|
||||
all-caps suffixes like ``.PDF``
|
||||
|
||||
0.4.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Introducing reminders. See `#199`_ for more information, but the short
|
||||
explanation is that you can now attach simple notes & times to documents
|
||||
@@ -483,7 +619,7 @@ bulk of the work on this big change.
|
||||
like to make use of this feature in his project.
|
||||
|
||||
0.3.6
|
||||
#####
|
||||
=====
|
||||
|
||||
* Fix for `#200`_ (!!) where the API wasn't configured to allow updating the
|
||||
correspondent or the tags for a document.
|
||||
@@ -497,7 +633,7 @@ bulk of the work on this big change.
|
||||
documentation is on its way.
|
||||
|
||||
0.3.5
|
||||
#####
|
||||
=====
|
||||
|
||||
* A serious facelift for the documents listing page wherein we drop the
|
||||
tabular layout in favour of a tiled interface.
|
||||
@@ -508,7 +644,7 @@ bulk of the work on this big change.
|
||||
consumption.
|
||||
|
||||
0.3.4
|
||||
#####
|
||||
=====
|
||||
|
||||
* Removal of django-suit due to a licensing conflict I bumped into in 0.3.3.
|
||||
Note that you *can* use Django Suit with Paperless, but only in a
|
||||
@@ -521,26 +657,26 @@ bulk of the work on this big change.
|
||||
API thanks to @thomasbrueggemann. See `#179`_.
|
||||
|
||||
0.3.3
|
||||
#####
|
||||
=====
|
||||
|
||||
* Thumbnails in the UI and a Django-suit -based face-lift courtesy of @ekw!
|
||||
* Timezone, items per page, and default language are now all configurable,
|
||||
also thanks to @ekw.
|
||||
|
||||
0.3.2
|
||||
#####
|
||||
=====
|
||||
|
||||
* Fix for `#172`_: defaulting ALLOWED_HOSTS to ``["*"]`` and allowing the
|
||||
user to set her own value via ``PAPERLESS_ALLOWED_HOSTS`` should the need
|
||||
arise.
|
||||
|
||||
0.3.1
|
||||
#####
|
||||
=====
|
||||
|
||||
* Added a default value for ``CONVERT_BINARY``
|
||||
|
||||
0.3.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
@@ -553,7 +689,7 @@ bulk of the work on this big change.
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
|
||||
0.2.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
@@ -581,7 +717,7 @@ bulk of the work on this big change.
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
|
||||
0.1.1
|
||||
#####
|
||||
=====
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
@@ -605,7 +741,7 @@ bulk of the work on this big change.
|
||||
to be imported but made unavailable.
|
||||
|
||||
0.1.0
|
||||
#####
|
||||
=====
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
@@ -624,14 +760,14 @@ bulk of the work on this big change.
|
||||
* Added tox with pep8 checking
|
||||
|
||||
0.0.6
|
||||
#####
|
||||
=====
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
|
||||
0.0.5
|
||||
#####
|
||||
=====
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
@@ -640,7 +776,7 @@ bulk of the work on this big change.
|
||||
* Documentation for the above as well as data migration
|
||||
|
||||
0.0.4
|
||||
#####
|
||||
=====
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
@@ -648,22 +784,23 @@ bulk of the work on this big change.
|
||||
* Added ``pytz`` to the list of requirements
|
||||
|
||||
0.0.3
|
||||
#####
|
||||
=====
|
||||
|
||||
* Added basic tagging
|
||||
|
||||
0.0.2
|
||||
#####
|
||||
=====
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
|
||||
0.0.1
|
||||
#####
|
||||
=====
|
||||
|
||||
* Initial release
|
||||
|
||||
.. _jayme-github: http://github.com/jayme-github
|
||||
.. _Brian Conn: https://github.com/TheConnMan
|
||||
.. _Christopher Luu: https://github.com/nuudles
|
||||
.. _Florian Jung: https://github.com/the01
|
||||
|
||||
51
docs/conf.py
@@ -1,48 +1,21 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
#
|
||||
# Paperless documentation build configuration file, created by
|
||||
# sphinx-quickstart on Mon Oct 26 18:36:52 2015.
|
||||
#
|
||||
# This file is execfile()d with the current directory set to its
|
||||
# containing dir.
|
||||
#
|
||||
# Note that not all possible configuration values are present in this
|
||||
# autogenerated file.
|
||||
#
|
||||
# All configuration values have a default; values that are commented out
|
||||
# serve to show the default.
|
||||
import sphinx_rtd_theme
|
||||
|
||||
|
||||
__version__ = None
|
||||
exec(open("../src/paperless/version.py").read())
|
||||
|
||||
|
||||
# Believe it or not, this is the officially sanctioned way to add custom CSS.
|
||||
def setup(app):
|
||||
app.add_stylesheet("custom.css")
|
||||
|
||||
# If extensions (or modules to document with autodoc) are in another directory,
|
||||
# add these directories to sys.path here. If the directory is relative to the
|
||||
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
||||
#sys.path.insert(0, os.path.abspath('.'))
|
||||
|
||||
# -- General configuration ------------------------------------------------
|
||||
|
||||
# If your documentation needs a minimal Sphinx version, state it here.
|
||||
#needs_sphinx = '1.0'
|
||||
|
||||
# Add any Sphinx extension module names here, as strings. They can be
|
||||
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
||||
# ones.
|
||||
extensions = [
|
||||
'sphinx.ext.autodoc',
|
||||
'sphinx.ext.intersphinx',
|
||||
'sphinx.ext.todo',
|
||||
'sphinx.ext.imgmath',
|
||||
'sphinx.ext.viewcode',
|
||||
'sphinx_rtd_theme',
|
||||
]
|
||||
|
||||
# Add any paths that contain templates here, relative to this directory.
|
||||
templates_path = ['_templates']
|
||||
# templates_path = ['_templates']
|
||||
|
||||
# The suffix of source filenames.
|
||||
source_suffix = '.rst'
|
||||
@@ -115,7 +88,7 @@ pygments_style = 'sphinx'
|
||||
|
||||
# The theme to use for HTML and HTML Help pages. See the documentation for
|
||||
# a list of builtin themes.
|
||||
html_theme = 'default'
|
||||
html_theme = 'sphinx_rtd_theme'
|
||||
|
||||
# Theme options are theme-specific and customize the look and feel of a theme
|
||||
# further. For a list of options available for each theme, see the
|
||||
@@ -195,20 +168,6 @@ html_static_path = ['_static']
|
||||
# Output file base name for HTML help builder.
|
||||
htmlhelp_basename = 'paperless'
|
||||
|
||||
|
||||
#
|
||||
# Attempt to use the ReadTheDocs theme. If it's not installed, fallback to
|
||||
# the default.
|
||||
#
|
||||
|
||||
try:
|
||||
import sphinx_rtd_theme
|
||||
html_theme = "sphinx_rtd_theme"
|
||||
html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
|
||||
except ImportError as e:
|
||||
print("error " + str(e))
|
||||
pass
|
||||
|
||||
# -- Options for LaTeX output ---------------------------------------------
|
||||
|
||||
latex_elements = {
|
||||
|
||||
@@ -1,9 +1,10 @@
|
||||
.. _configuration:
|
||||
|
||||
*************
|
||||
Configuration
|
||||
*************
|
||||
|
||||
Paperless provides a wide range of customizations.
|
||||
Have a look at ``paperless.conf.example`` for available configuration options.
|
||||
Depending on how you run paperless, these settings have to be defined in different
|
||||
places.
|
||||
|
||||
@@ -18,5 +19,398 @@ places.
|
||||
/etc/paperless.conf
|
||||
/usr/local/etc/paperless.conf
|
||||
|
||||
Copy ``paperless.conf.example`` to any of these locations and adjust it to your
|
||||
needs.
|
||||
|
||||
Required services
|
||||
#################
|
||||
|
||||
PAPERLESS_REDIS=<url>
|
||||
This is required for processing scheduled tasks such as email fetching, index
|
||||
optimization and for training the automatic document matcher.
|
||||
|
||||
Defaults to redis://localhost:6379.
|
||||
|
||||
PAPERLESS_DBHOST=<hostname>
|
||||
By default, sqlite is used as the database backend. This can be changed here.
|
||||
Set PAPERLESS_DBHOST and PostgreSQL will be used instead of mysql.
|
||||
|
||||
PAPERLESS_DBPORT=<port>
|
||||
Adjust port if necessary.
|
||||
|
||||
Default is 5432.
|
||||
|
||||
PAPERLESS_DBNAME=<name>
|
||||
Database name in PostgreSQL.
|
||||
|
||||
Defaults to "paperless".
|
||||
|
||||
PAPERLESS_DBUSER=<name>
|
||||
Database user in PostgreSQL.
|
||||
|
||||
Defaults to "paperless".
|
||||
|
||||
PAPERLESS_DBPASS=<password>
|
||||
Database password for PostgreSQL.
|
||||
|
||||
Defaults to "paperless".
|
||||
|
||||
|
||||
Paths and folders
|
||||
#################
|
||||
|
||||
PAPERLESS_CONSUMPTION_DIR=<path>
|
||||
This where your documents should go to be consumed. Make sure that it exists
|
||||
and that the user running the paperless service can read/write its contents
|
||||
before you start Paperless.
|
||||
|
||||
Don't change this when using docker, as it only changes the path within the
|
||||
container. Change the local consumption directory in the docker-compose.yml
|
||||
file instead.
|
||||
|
||||
Defaults to "../consume", relative to the "src" directory.
|
||||
|
||||
PAPERLESS_DATA_DIR=<path>
|
||||
This is where paperless stores all its data (search index, SQLite database,
|
||||
classification model, etc).
|
||||
|
||||
Defaults to "../data", relative to the "src" directory.
|
||||
|
||||
PAPERLESS_MEDIA_ROOT=<path>
|
||||
This is where your documents and thumbnails are stored.
|
||||
|
||||
You can set this and PAPERLESS_DATA_DIR to the same folder to have paperless
|
||||
store all its data within the same volume.
|
||||
|
||||
Defaults to "../media", relative to the "src" directory.
|
||||
|
||||
PAPERLESS_STATICDIR=<path>
|
||||
Override the default STATIC_ROOT here. This is where all static files
|
||||
created using "collectstatic" manager command are stored.
|
||||
|
||||
Unless you're doing something fancy, there is no need to override this.
|
||||
|
||||
Defaults to "../static", relative to the "src" directory.
|
||||
|
||||
PAPERLESS_FILENAME_FORMAT=<format>
|
||||
Changes the filenames paperless uses to store documents in the media directory.
|
||||
See :ref:`advanced-file_name_handling` for details.
|
||||
|
||||
Default is none, which disables this feature.
|
||||
|
||||
Hosting & Security
|
||||
##################
|
||||
|
||||
PAPERLESS_SECRET_KEY=<key>
|
||||
Paperless uses this to make session tokens. If you expose paperless on the
|
||||
internet, you need to change this, since the default secret is well known.
|
||||
|
||||
Use any sequence of characters. The more, the better. You don't need to
|
||||
remember this. Just face-roll your keyboard.
|
||||
|
||||
Default is listed in the file ``src/paperless/settings.py``.
|
||||
|
||||
PAPERLESS_ALLOWED_HOSTS<comma-separated-list>
|
||||
If you're planning on putting Paperless on the open internet, then you
|
||||
really should set this value to the domain name you're using. Failing to do
|
||||
so leaves you open to HTTP host header attacks:
|
||||
https://docs.djangoproject.com/en/3.1/topics/security/#host-header-validation
|
||||
|
||||
Just remember that this is a comma-separated list, so "example.com" is fine,
|
||||
as is "example.com,www.example.com", but NOT " example.com" or "example.com,"
|
||||
|
||||
Defaults to "*", which is all hosts.
|
||||
|
||||
PAPERLESS_CORS_ALLOWED_HOSTS<comma-separated-list>
|
||||
You need to add your servers to the list of allowed hosts that can do CORS
|
||||
calls. Set this to your public domain name.
|
||||
|
||||
Defaults to "http://localhost:8000".
|
||||
|
||||
PAPERLESS_FORCE_SCRIPT_NAME=<path>
|
||||
To host paperless under a subpath url like example.com/paperless you set
|
||||
this value to /paperless. No trailing slash!
|
||||
|
||||
.. note::
|
||||
|
||||
I don't know if this works in paperless-ng. Probably not.
|
||||
|
||||
Defaults to none, which hosts paperless at "/".
|
||||
|
||||
PAPERLESS_STATIC_URL=<path>
|
||||
Override the STATIC_URL here. Unless you're hosting Paperless off a
|
||||
subdomain like /paperless/, you probably don't need to change this.
|
||||
|
||||
Defaults to "/static/".
|
||||
|
||||
PAPERLESS_AUTO_LOGIN_USERNAME=<username>
|
||||
Specify a username here so that paperless will automatically perform login
|
||||
with the selected user.
|
||||
|
||||
.. danger::
|
||||
|
||||
Do not use this when exposing paperless on the internet. There are no
|
||||
checks in place that would prevent you from doing this.
|
||||
|
||||
Defaults to none, which disables this feature.
|
||||
|
||||
.. _configuration-ocr:
|
||||
|
||||
OCR settings
|
||||
############
|
||||
|
||||
Paperless uses `OCRmyPDF <https://ocrmypdf.readthedocs.io/en/latest/>`_ for
|
||||
performing OCR on documents and images. Paperless uses sensible defaults for
|
||||
most settings, but all of them can be configured to your needs.
|
||||
|
||||
|
||||
PAPERLESS_OCR_LANGUAGE=<lang>
|
||||
Customize the language that paperless will attempt to use when
|
||||
parsing documents.
|
||||
|
||||
It should be a 3-letter language code consistent with ISO
|
||||
639: https://www.loc.gov/standards/iso639-2/php/code_list.php
|
||||
|
||||
Set this to the language most of your documents are written in.
|
||||
|
||||
This can be a combination of multiple languages such as ``deu+eng``,
|
||||
in which case tesseract will use whatever language matches best.
|
||||
Keep in mind that tesseract uses much more cpu time with multiple
|
||||
languages enabled.
|
||||
|
||||
Defaults to "eng".
|
||||
|
||||
PAPERLESS_OCR_MODE=<mode>
|
||||
Tell paperless when and how to perform ocr on your documents. Four modes
|
||||
are available:
|
||||
|
||||
* ``skip``: Paperless skips all pages and will perform ocr only on pages
|
||||
where no text is present. This is the safest option.
|
||||
* ``skip_noarchive``: In addition to skip, paperless won't create an
|
||||
archived version of your documents when it finds any text in them.
|
||||
This is useful if you don't want to have two almost-identical versions
|
||||
of your digital documents in the media folder. This is the fastest option.
|
||||
* ``redo``: Paperless will OCR all pages of your documents and attempt to
|
||||
replace any existing text layers with new text. This will be useful for
|
||||
documents from scanners that already performed OCR with insufficient
|
||||
results. It will also perform OCR on purely digital documents.
|
||||
|
||||
This option may fail on some documents that have features that cannot
|
||||
be removed, such as forms. In this case, the text from the document is
|
||||
used instead.
|
||||
* ``force``: Paperless rasterizes your documents, converting any text
|
||||
into images and puts the OCRed text on top. This works for all documents,
|
||||
however, the resulting document may be significantly larger and text
|
||||
won't appear as sharp when zoomed in.
|
||||
|
||||
The default is ``skip``, which only performs OCR when necessary and always
|
||||
creates archived documents.
|
||||
|
||||
PAPERLESS_OCR_OUTPUT_TYPE=<type>
|
||||
Specify the the type of PDF documents that paperless should produce.
|
||||
|
||||
* ``pdf``: Modify the PDF document as little as possible.
|
||||
* ``pdfa``: Convert PDF documents into PDF/A-2b documents, which is a
|
||||
subset of the entire PDF specification and meant for storing
|
||||
documents long term.
|
||||
* ``pdfa-1``, ``pdfa-2``, ``pdfa-3`` to specify the exact version of
|
||||
PDF/A you wish to use.
|
||||
|
||||
If not specified, ``pdfa`` is used. Remember that paperless also keeps
|
||||
the original input file as well as the archived version.
|
||||
|
||||
|
||||
PAPERLESS_OCR_PAGES=<num>
|
||||
Tells paperless to use only the specified amount of pages for OCR. Documents
|
||||
with less than the specified amount of pages get OCR'ed completely.
|
||||
|
||||
Specifying 1 here will only use the first page.
|
||||
|
||||
When combined with ``PAPERLESS_OCR_MODE=redo`` or ``PAPERLESS_OCR_MODE=force``,
|
||||
paperless will not modify any text it finds on excluded pages and copy it
|
||||
verbatim.
|
||||
|
||||
Defaults to 0, which disables this feature and always uses all pages.
|
||||
|
||||
|
||||
PAPERLESS_OCR_IMAGE_DPI=<num>
|
||||
Paperless will OCR any images you put into the system and convert them
|
||||
into PDF documents. This is useful if your scanner produces images.
|
||||
In order to do so, paperless needs to know the DPI of the image.
|
||||
Most images from scanners will have this information embedded and
|
||||
paperless will detect and use that information. In case this fails, it
|
||||
uses this value as a fallback.
|
||||
|
||||
Set this to the DPI your scanner produces images at.
|
||||
|
||||
Default is none, which causes paperless to fail if no DPI information is
|
||||
present in an image.
|
||||
|
||||
|
||||
PAPERLESS_OCR_USER_ARG=<json>
|
||||
OCRmyPDF offers many more options. Use this parameter to specify any
|
||||
additional arguments you wish to pass to OCRmyPDF. Since Paperless uses
|
||||
the API of OCRmyPDF, you have to specify these in a format that can be
|
||||
passed to the API. See `the API reference of OCRmyPDF <https://ocrmypdf.readthedocs.io/en/latest/api.html#reference>`_
|
||||
for valid parameters. All command line options are supported, but they
|
||||
use underscores instead of dashed.
|
||||
|
||||
.. caution::
|
||||
|
||||
Paperless has been tested to work with the OCR options provided
|
||||
above. There are many options that are incompatible with each other,
|
||||
so specifying invalid options may prevent paperless from consuming
|
||||
any documents.
|
||||
|
||||
Specify arguments as a JSON dictionary. Keep note of lower case booleans
|
||||
and double quoted parameter names and strings. Examples:
|
||||
|
||||
.. code:: json
|
||||
|
||||
{"deskew": true, "optimize": 3, "unpaper_args": "--pre-rotate 90"}
|
||||
|
||||
|
||||
Software tweaks
|
||||
###############
|
||||
|
||||
PAPERLESS_TASK_WORKERS=<num>
|
||||
Paperless does multiple things in the background: Maintain the search index,
|
||||
maintain the automatic matching algorithm, check emails, consume documents,
|
||||
etc. This variable specifies how many things it will do in parallel.
|
||||
|
||||
|
||||
PAPERLESS_THREADS_PER_WORKER=<num>
|
||||
Furthermore, paperless uses multiple threads when consuming documents to
|
||||
speed up OCR. This variable specifies how many pages paperless will process
|
||||
in parallel on a single document.
|
||||
|
||||
.. caution::
|
||||
|
||||
Ensure that the product
|
||||
|
||||
PAPERLESS_TASK_WORKERS * PAPERLESS_THREADS_PER_WORKER
|
||||
|
||||
does not exceed your CPU core count or else paperless will be extremely slow.
|
||||
If you want paperless to process many documents in parallel, choose a high
|
||||
worker count. If you want paperless to process very large documents faster,
|
||||
use a higher thread per worker count.
|
||||
|
||||
The default is a balance between the two, according to your CPU core count,
|
||||
with a slight favor towards threads per worker, and using as much cores as
|
||||
possible.
|
||||
|
||||
If you only specify PAPERLESS_TASK_WORKERS, paperless will adjust
|
||||
PAPERLESS_THREADS_PER_WORKER automatically.
|
||||
|
||||
|
||||
PAPERLESS_TIME_ZONE=<timezone>
|
||||
Set the time zone here.
|
||||
See https://docs.djangoproject.com/en/3.1/ref/settings/#std:setting-TIME_ZONE
|
||||
for details on how to set it.
|
||||
|
||||
Defaults to UTC.
|
||||
|
||||
|
||||
PAPERLESS_CONSUMER_POLLING=<num>
|
||||
If paperless won't find documents added to your consume folder, it might
|
||||
not be able to automatically detect filesystem changes. In that case,
|
||||
specify a polling interval in seconds here, which will then cause paperless
|
||||
to periodically check your consumption directory for changes.
|
||||
|
||||
Defaults to 0, which disables polling and uses filesystem notifications.
|
||||
|
||||
|
||||
PAPERLESS_CONSUMER_DELETE_DUPLICATES=<bool>
|
||||
When the consumer detects a duplicate document, it will not touch the
|
||||
original document. This default behavior can be changed here.
|
||||
|
||||
Defaults to false.
|
||||
|
||||
|
||||
PAPERLESS_CONSUMER_RECURSIVE=<bool>
|
||||
Enable recursive watching of the consumption directory. Paperless will
|
||||
then pickup files from files in subdirectories within your consumption
|
||||
directory as well.
|
||||
|
||||
Defaults to false.
|
||||
|
||||
|
||||
PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS=<bool>
|
||||
Set the names of subdirectories as tags for consumed files.
|
||||
E.g. <CONSUMPTION_DIR>/foo/bar/file.pdf will add the tags "foo" and "bar" to
|
||||
the consumed file. Paperless will create any tags that don't exist yet.
|
||||
|
||||
PAPERLESS_CONSUMER_RECURSIVE must be enabled for this to work.
|
||||
|
||||
Defaults to false.
|
||||
|
||||
|
||||
PAPERLESS_CONVERT_MEMORY_LIMIT=<num>
|
||||
On smaller systems, or even in the case of Very Large Documents, the consumer
|
||||
may explode, complaining about how it's "unable to extend pixel cache". In
|
||||
such cases, try setting this to a reasonably low value, like 32. The
|
||||
default is to use whatever is necessary to do everything without writing to
|
||||
disk, and units are in megabytes.
|
||||
|
||||
For more information on how to use this value, you should search
|
||||
the web for "MAGICK_MEMORY_LIMIT".
|
||||
|
||||
Defaults to 0, which disables the limit.
|
||||
|
||||
PAPERLESS_CONVERT_TMPDIR=<path>
|
||||
Similar to the memory limit, if you've got a small system and your OS mounts
|
||||
/tmp as tmpfs, you should set this to a path that's on a physical disk, like
|
||||
/home/your_user/tmp or something. ImageMagick will use this as scratch space
|
||||
when crunching through very large documents.
|
||||
|
||||
For more information on how to use this value, you should search
|
||||
the web for "MAGICK_TMPDIR".
|
||||
|
||||
Default is none, which disables the temporary directory.
|
||||
|
||||
PAPERLESS_OPTIMIZE_THUMBNAILS=<bool>
|
||||
Use optipng to optimize thumbnails. This usually reduces the size of
|
||||
thumbnails by about 20%, but uses considerable compute time during
|
||||
consumption.
|
||||
|
||||
Defaults to true.
|
||||
|
||||
PAPERLESS_POST_CONSUME_SCRIPT=<filename>
|
||||
After a document is consumed, Paperless can trigger an arbitrary script if
|
||||
you like. This script will be passed a number of arguments for you to work
|
||||
with. For more information, take a look at :ref:`advanced-post_consume_script`.
|
||||
|
||||
The default is blank, which means nothing will be executed.
|
||||
|
||||
PAPERLESS_FILENAME_DATE_ORDER=<format>
|
||||
Paperless will check the document text for document date information.
|
||||
Use this setting to enable checking the document filename for date
|
||||
information. The date order can be set to any option as specified in
|
||||
https://dateparser.readthedocs.io/en/latest/settings.html#date-order.
|
||||
The filename will be checked first, and if nothing is found, the document
|
||||
text will be checked as normal.
|
||||
|
||||
Defaults to none, which disables this feature.
|
||||
|
||||
PAPERLESS_FILENAME_PARSE_TRANSFORMS
|
||||
Transforms filenames before they are processed by paperless. See
|
||||
:ref:`advanced-transforming_filenames` for details.
|
||||
|
||||
Defaults to none, which disables this feature.
|
||||
|
||||
Binaries
|
||||
########
|
||||
|
||||
There are a few external software packages that Paperless expects to find on
|
||||
your system when it starts up. Unless you've done something creative with
|
||||
their installation, you probably won't need to edit any of these. However,
|
||||
if you've installed these programs somewhere where simply typing the name of
|
||||
the program doesn't automatically execute it (ie. the program isn't in your
|
||||
$PATH), then you'll need to specify the literal path for that program.
|
||||
|
||||
PAPERLESS_CONVERT_BINARY=<path>
|
||||
Defaults to "/usr/bin/convert".
|
||||
|
||||
PAPERLESS_GS_BINARY=<path>
|
||||
Defaults to "/usr/bin/gs".
|
||||
|
||||
PAPERLESS_OPTIPNG_BINARY=<path>
|
||||
Defaults to "/usr/bin/optipng".
|
||||
|
||||
@@ -85,7 +85,7 @@ quoted, or triple-quoted string will do:
|
||||
problematic_string = 'This is a "string" with "quotes" in it'
|
||||
|
||||
In HTML templates, please use double-quotes for tag attributes, and single
|
||||
quotes for arguments passed to Django tempalte tags:
|
||||
quotes for arguments passed to Django template tags:
|
||||
|
||||
.. code:: html
|
||||
|
||||
|
||||
@@ -1,5 +1,120 @@
|
||||
.. _extending:
|
||||
|
||||
Paperless development
|
||||
#####################
|
||||
|
||||
This section describes the steps you need to take to start development on paperless-ng.
|
||||
|
||||
1. Check out the source from github. The repository is organized in the following way:
|
||||
|
||||
* ``master`` always represents the latest release and will only see changes
|
||||
when a new release is made.
|
||||
* ``dev`` contains the code that will be in the next release.
|
||||
* ``feature-X`` contain bigger changes that will be in some release, but not
|
||||
necessarily the next one.
|
||||
|
||||
Apart from that, the folder structure is as follows:
|
||||
|
||||
* ``docs/`` - Documentation.
|
||||
* ``src-ui/`` - Code of the front end.
|
||||
* ``src/`` - Code of the back end.
|
||||
* ``scripts/`` - Various scripts that help with different parts of development.
|
||||
* ``docker/`` - Files required to build the docker image.
|
||||
|
||||
2. Install some dependencies.
|
||||
|
||||
* Python 3.6.
|
||||
* All dependencies listed in the :ref:`Bare metal route <setup-bare_metal>`
|
||||
* redis. You can either install redis or use the included scritps/start-redis.sh
|
||||
to use docker to fire up a redis instance.
|
||||
|
||||
Back end development
|
||||
====================
|
||||
|
||||
The backend is a django application. I use PyCharm for development, but you can use whatever
|
||||
you want.
|
||||
|
||||
Install the python dependencies by performing ``pipenv install --dev`` in the src/ directory.
|
||||
This will also create a virtual environment, which you can enter with ``pipenv shell`` or
|
||||
execute one-shot commands in with ``pipenv run``.
|
||||
|
||||
In ``src/paperless.conf``, enable debug mode.
|
||||
|
||||
Configure the IDE to use the src/ folder as the base source folder. Configure the following
|
||||
launch configurations in your IDE:
|
||||
|
||||
* python3 manage.py runserver
|
||||
* python3 manage.py qcluster
|
||||
* python3 manage.py consumer
|
||||
|
||||
Depending on which part of paperless you're developing for, you need to have some or all of
|
||||
them running.
|
||||
|
||||
Testing and code style:
|
||||
|
||||
* Run ``pytest`` in the src/ directory to execute all tests. This also generates a HTML coverage
|
||||
report. When runnings test, paperless.conf is loaded as well. However: the tests rely on the default
|
||||
configuration. This is not ideal. But for now, make sure no settings except for DEBUG are overridden when testing.
|
||||
* Run ``pycodestyle`` to test your code for issues with the configured code style settings.
|
||||
|
||||
.. note::
|
||||
|
||||
The line length rule E501 is generally useful for getting multiple source files
|
||||
next to each other on the screen. However, in some cases, its just not possible
|
||||
to make some lines fit, especially complicated IF cases. Append `` # NOQA: E501``
|
||||
to disable this check for certain lines.
|
||||
|
||||
Front end development
|
||||
=====================
|
||||
|
||||
The front end is build using angular. I use the ``Code - OSS`` IDE for development.
|
||||
|
||||
In order to get started, you need ``npm``. Install the Angular CLI interface with
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ npm install -g @angular/cli
|
||||
|
||||
and make sure that it's on your path. Next, in the src-ui/ directory, install the
|
||||
required dependencies of the project.
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ npm install
|
||||
|
||||
You can launch a development server by running
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ ng serve
|
||||
|
||||
This will automatically update whenever you save. However, in-place compilation might fail
|
||||
on syntax errors, in which case you need to restart it.
|
||||
|
||||
By default, the development server is available on ``http://localhost:4200/`` and is configured
|
||||
to access the API at ``http://localhost:8000/api/``, which is the default of the backend.
|
||||
If you enabled DEBUG on the back end, several security overrides for allowed hosts, CORS and
|
||||
X-Frame-Options are in place so that the front end behaves exactly as in production. This also
|
||||
relies on you being logged into the back end. Without a valid session, The front end will simply
|
||||
not work.
|
||||
|
||||
In order to build the front end and serve it as part of django, execute
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ ng build --prod --output-path ../src/documents/static/frontend/
|
||||
|
||||
This will build the front end and put it in a location from which the Django server will serve
|
||||
it as static content. This way, you can verify that authentication is working.
|
||||
|
||||
Making a release
|
||||
================
|
||||
|
||||
Execute the ``make-release.sh <ver>`` script.
|
||||
|
||||
This will test and assemble everything and also build and tag a docker image.
|
||||
|
||||
|
||||
Extending Paperless
|
||||
===================
|
||||
|
||||
|
||||
79
docs/faq.rst
@@ -3,6 +3,18 @@
|
||||
Frequently asked questions
|
||||
**************************
|
||||
|
||||
**Q:** *What's the general plan for Paperless-ng?*
|
||||
|
||||
**A:** Paperless-ng is already almost feature-complete. This project will remain
|
||||
as simple as it is right now. It will see improvements to features that are already there.
|
||||
If you need advanced features such as document versions,
|
||||
workflows or multi-user with customizable access to individual files, this is
|
||||
not the tool for you.
|
||||
|
||||
Features that *are* planned are some more quality of life extensions for the searching
|
||||
(i.e., search for similar documents, group results by correspondents with "more from this"
|
||||
links, etc), bulk editing and hierarchical tags.
|
||||
|
||||
**Q:** *I'm using docker. Where are my documents?*
|
||||
|
||||
**A:** Your documents are stored inside the docker volume ``paperless_media``.
|
||||
@@ -17,36 +29,46 @@ is
|
||||
|
||||
.. caution::
|
||||
|
||||
Dont mess with this folder. Don't change permissions and don't move
|
||||
Do not mess with this folder. Don't change permissions and don't move
|
||||
files around manually. This folder is meant to be entirely managed by docker
|
||||
and paperless.
|
||||
|
||||
**Q:** *Let's say you don't support this project anymore in a year. Can I easily move to other systems?*
|
||||
|
||||
**A:** Your documents are stored as plain files inside the media folder. You can always drag those files
|
||||
out of that folder to use them elsewhere. Here are a couple notes about that.
|
||||
|
||||
* Paperless never modifies your original documents. It keeps checksums of all documents and uses a
|
||||
scheduled sanity checker to check that they remain the same.
|
||||
* By default, paperless uses the internal ID of each document as its filename. This might not be very
|
||||
convenient for export. However, you can adjust the way files are stored in paperless by
|
||||
:ref:`configuring the filename format <advanced-file_name_handling>`.
|
||||
* :ref:`The exporter <utilities-exporter>` is another easy way to get your files out of paperless with reasonable file names.
|
||||
|
||||
**Q:** *What file types does paperless-ng support?*
|
||||
|
||||
**A:** Currently, the following files are supported:
|
||||
|
||||
* PDF documents, PNG images, JPEG images, TIFF images and GIF images are processed with OCR and converted into PDF documents.
|
||||
* Plain text documents are supported as well and are added verbatim
|
||||
to paperless.
|
||||
|
||||
Paperless determines the type of a file by inspecting its content. The
|
||||
file extensions do not matter.
|
||||
|
||||
**Q:** *Will paperless-ng run on Raspberry Pi?*
|
||||
|
||||
**A:** The short answer is yes. I've tested it on a Raspberry Pi 3 B.
|
||||
The long answer is that certain parts of
|
||||
Paperless will run very slow, such as the tesseract OCR. On Rasperry Pi,
|
||||
Paperless will run very slow, such as the tesseract OCR. On Raspberry Pi,
|
||||
try to OCR documents before feeding them into paperless so that paperless can
|
||||
reuse the text. The web interface should be alot snappier, since it runs
|
||||
reuse the text. The web interface should be a lot snappier, since it runs
|
||||
in your browser and paperless has to do much less work to serve the data.
|
||||
|
||||
.. note::
|
||||
|
||||
Consider setting ``PAPERLESS_OPTIMIZE_THUMBNAILS`` to false to speed up
|
||||
the consumption process. This takes quite a bit of time on Raspberry Pi.
|
||||
|
||||
.. note::
|
||||
|
||||
Updating the :ref:`automatic matching algorithm <advanced-automatic_matching>`
|
||||
takes quite a bit of time. However, the update mechanism checks if your
|
||||
data has changed before doing the heavy lifting. If you experience the
|
||||
algorithm taking too much cpu time, consider changing the schedule in the
|
||||
admin interface to daily or weekly. You can also manually invoke the task
|
||||
by changing the date and time of the next run to today/now.
|
||||
|
||||
The actual matching of the algorithm is fast and works on Raspberry Pi as
|
||||
well as on any other device.
|
||||
|
||||
You can adjust some of the settings so that paperless uses less processing
|
||||
power. See :ref:`setup-less_powerful_devices` for details.
|
||||
|
||||
|
||||
**Q:** *How do I install paperless-ng on Raspberry Pi?*
|
||||
@@ -55,3 +77,24 @@ in your browser and paperless has to do much less work to serve the data.
|
||||
that automatically, I'm all ears. For now, you have to grab the latest release
|
||||
archive from the project page and build the image yourself. The release comes
|
||||
with the front end already compiled, so you don't have to do this on the Pi.
|
||||
|
||||
**Q:** *How do I run this on my toaster?*
|
||||
|
||||
**A:** I honestly don't know! As for all other devices that might be able
|
||||
to run paperless, you're a bit on your own. If you can't run the docker image,
|
||||
the documentation has instructions for bare metal installs. I'm running
|
||||
paperless on an i3 processor from 2015 or so. This is also what I use to test
|
||||
new releases with. Apart from that, I also have a Raspberry Pi, which I
|
||||
occasionally build the image on and see if it works.
|
||||
|
||||
**Q:** *How do I proxy this with NGINX?*
|
||||
|
||||
.. code::
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:8000/
|
||||
}
|
||||
|
||||
And that's about it. Paperless serves everything, including static files by itself
|
||||
when running the docker image. If you want to do anything fancy, you have to
|
||||
install paperless bare metal.
|
||||
|
||||
@@ -25,14 +25,34 @@ and then shred them. Perhaps you might find it useful too.
|
||||
Paperless-ng
|
||||
============
|
||||
|
||||
I wanted to make big changes to the project that will impact the way it is used
|
||||
by its users greatly. Among the users who currently use paperless in production
|
||||
there are probably many that don't want these changes right away. I also wanted
|
||||
to have more control over what goes into the code and what does not. Therefore,
|
||||
paperless-ng was created. NG stands for both Angular (the framework used for the
|
||||
Paperless-ng is a fork of the original paperless project. It changes many
|
||||
things both on the surface and under the hood. Paperless-ng was created
|
||||
because I feel that these changes are too big to be pushed into the main
|
||||
repository right away.
|
||||
|
||||
NG stands for both Angular (the framework used for the
|
||||
Frontend) and next-gen. Publishing this project under a different name also
|
||||
avoids confusion between paperless and paperless-ng.
|
||||
|
||||
If you want to learn about what's different in paperless-ng, check out these
|
||||
resources in the documentation:
|
||||
|
||||
* :ref:`Some screenshots <screenshots>` of the new UI are available.
|
||||
* Read :ref:`this section <advanced-automatic_matching>` if you want to
|
||||
learn about how paperless automates all tagging using machine learning.
|
||||
* Paperless now comes with a :ref:`proper email consumer <usage-email>`
|
||||
that's fully tested and production ready.
|
||||
* Paperless creates searchable PDF/A documents from whatever you you put into
|
||||
the consumption directory. This means that you can select text in
|
||||
image-only documents coming from your scanner.
|
||||
* See :ref:`this note <utilities-encyption>` about GnuPG encryption in
|
||||
paperless-ng.
|
||||
* Paperless is now integrated with a
|
||||
:ref:`task processing queue <setup-task_processor>` that tells you
|
||||
at a glance when and why something is not working.
|
||||
* The :ref:`changelog <paperless_changelog>` contains a detailed list of all changes
|
||||
in paperless-ng.
|
||||
|
||||
It would be great if this project could eventually merge back into the main
|
||||
repository, but it needs a lot more work before that can happen.
|
||||
|
||||
|
||||
@@ -8,7 +8,7 @@ Scanner recommendations
|
||||
As Paperless operates by watching a folder for new files, doesn't care what
|
||||
scanner you use, but sometimes finding a scanner that will write to an FTP,
|
||||
NFS, or SMB server can be difficult. This page is here to help you find one
|
||||
that works right for you based on recommentations from other Paperless users.
|
||||
that works right for you based on recommendations from other Paperless users.
|
||||
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Brand | Model | Supports | Recommended By |
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
.. _screenshots:
|
||||
|
||||
***********
|
||||
Screenshots
|
||||
***********
|
||||
@@ -7,40 +9,37 @@ research papers though, its a horrible tool for that job.
|
||||
|
||||
The dashboard shows customizable views on your document and allows document uploads:
|
||||
|
||||
.. image:: _static/paperless-0-dashboard.png
|
||||
.. image:: _static/screenshots/dashboard.png
|
||||
|
||||
The document list provides three different styles to scroll through your documents:
|
||||
|
||||
.. image:: _static/paperless-1-list-table.png
|
||||
.. image:: _static/paperless-2-list-smallcards.png
|
||||
.. image:: _static/paperless-3-list-largecards.png
|
||||
.. image:: _static/screenshots/documents-table.png
|
||||
.. image:: _static/screenshots/documents-smallcards.png
|
||||
.. image:: _static/screenshots/documents-largecards.png
|
||||
|
||||
Extensive filtering mechanisms:
|
||||
|
||||
.. image:: _static/paperless-4-filter.png
|
||||
.. image:: _static/screenshots/documents-filter.png
|
||||
|
||||
Side-by-side editing of documents. Optmized for 1080p.
|
||||
Side-by-side editing of documents. Optimized for 1080p.
|
||||
|
||||
.. image:: _static/paperless-5-editing.png
|
||||
.. image:: _static/screenshots/editing.png
|
||||
|
||||
Tag editing. This looks about the same for correspondents and document types.
|
||||
|
||||
.. image:: _static/paperless-6-tags.png
|
||||
.. image:: _static/screenshots/new-tag.png
|
||||
|
||||
Searching provides auto complete and highlights the results.
|
||||
|
||||
.. image:: _static/paperless-7-autocomplete.png
|
||||
.. image:: _static/paperless-8-search-results.png
|
||||
|
||||
The old admin is still there and accessible!
|
||||
|
||||
.. image:: _static/paperless-9-admin.png
|
||||
.. image:: _static/screenshots/search-preview.png
|
||||
.. image:: _static/screenshots/search-results.png
|
||||
|
||||
Fancy mail filters!
|
||||
|
||||
.. image:: _static/paperless-11-mail-filters.png
|
||||
.. image:: _static/screenshots/mail-rules-edited.png
|
||||
|
||||
Mobile support in the future? This doesn't really work yet.
|
||||
Mobile support in the future? This kinda works, however some layouts are still
|
||||
too wide.
|
||||
|
||||
.. image:: _static/paperless-10-mobile.png
|
||||
.. image:: _static/screenshots/mobile.png
|
||||
|
||||
|
||||
413
docs/setup.rst
@@ -10,10 +10,10 @@ Go to the project page on GitHub and download the
|
||||
`latest release <https://github.com/jonaswinkler/paperless-ng/releases>`_.
|
||||
There are multiple options available.
|
||||
|
||||
* Download the docker-compose files if you want to pull paperless from
|
||||
* Download the dockerfiles archive if you want to pull paperless from
|
||||
Docker Hub.
|
||||
|
||||
* Download the archive and extract it if you want to build the docker image
|
||||
* Download the dist archive and extract it if you want to build the docker image
|
||||
yourself or want to install paperless without docker.
|
||||
|
||||
.. hint::
|
||||
@@ -22,26 +22,35 @@ There are multiple options available.
|
||||
is not to pull the entire git repository. Paperless-ng includes artifacts
|
||||
that need to be compiled, and that's already done for you in the release.
|
||||
|
||||
.. admonition:: Want to try out paperless-ng before migrating?
|
||||
|
||||
The release contains a file ``.env`` which sets the docker-compose project
|
||||
name to "paperless", which is the same as before and instructs docker-compose
|
||||
to reuse and upgrade your paperless volumes.
|
||||
|
||||
Just rename the project name in that file to anything else and docker-compose
|
||||
will create fresh volumes for you!
|
||||
|
||||
|
||||
Overview of Paperless-ng
|
||||
########################
|
||||
|
||||
Compared to paperless, paperless-ng works a little different under the hood and has
|
||||
more moving parts that work together. While this increases the complexity of
|
||||
the system, it also brings many benefits.
|
||||
the system, it also brings many benefits.
|
||||
|
||||
Paperless consists of the following components:
|
||||
|
||||
* **The webserver:** This is pretty much the same as in paperless. It serves
|
||||
* **The webserver:** This is pretty much the same as in paperless. It serves
|
||||
the administration pages, the API, and the new frontend. This is the main
|
||||
tool you'll be using to interact with paperless. You may start the webserver
|
||||
with
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
|
||||
$ cd /path/to/paperless/src/
|
||||
$ pipenv run gunicorn -c /usr/src/paperless/gunicorn.conf.py -b 0.0.0.0:8000 paperless.wsgi
|
||||
|
||||
|
||||
or by any other means such as Apache ``mod_wsgi``.
|
||||
|
||||
* **The consumer:** This is what watches your consumption folder for documents.
|
||||
@@ -53,15 +62,17 @@ Paperless consists of the following components:
|
||||
Start the consumer with the management command ``document_consumer``:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
|
||||
$ cd /path/to/paperless/src/
|
||||
$ pipenv run python3 manage.py document_consumer
|
||||
|
||||
.. _setup-task_processor:
|
||||
|
||||
* **The task processor:** Paperless relies on `Django Q <https://django-q.readthedocs.io/en/latest/>`_
|
||||
for doing much of the heavy lifting. This is a task queue that accepts tasks from
|
||||
multiple sources and processes tasks in parallel. It also comes with a scheduler that executes
|
||||
certain commands periodically.
|
||||
|
||||
|
||||
This task processor is responsible for:
|
||||
|
||||
* Consuming documents. When the consumer finds new documents, it notifies the task processor to
|
||||
@@ -72,17 +83,18 @@ Paperless consists of the following components:
|
||||
the web interface.
|
||||
* Maintain the search index and the automatic matching algorithm. These are things that paperless
|
||||
needs to do from time to time in order to operate properly.
|
||||
|
||||
|
||||
This allows paperless to process multiple documents from your consumption folder in parallel! On
|
||||
a modern multicore system, consumption with full ocr is blazing fast.
|
||||
a modern multi core system, consumption with full ocr is blazing fast.
|
||||
|
||||
The task processor comes with a built-in admin interface that you can use to see whenever any of the
|
||||
tasks fail and inspect the errors.
|
||||
tasks fail and inspect the errors (i.e., wrong email credentials, errors during consuming a specific
|
||||
file, etc).
|
||||
|
||||
You may start the task processor by executing:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
|
||||
$ cd /path/to/paperless/src/
|
||||
$ pipenv run python3 manage.py qcluster
|
||||
|
||||
@@ -90,8 +102,7 @@ Paperless consists of the following components:
|
||||
for getting the tasks from the webserver and consumer to the task scheduler. These run in different
|
||||
processes (maybe even on different machines!), and therefore, this is necessary.
|
||||
|
||||
* A database server. Paperless supports PostgreSQL and sqlite for storing its data. However, with the
|
||||
added concurrency, it is strongly advised to use PostgreSQL, as sqlite has its limits in that regard.
|
||||
* Optional: A database server. Paperless supports both PostgreSQL and SQLite for storing its data.
|
||||
|
||||
|
||||
Installation
|
||||
@@ -116,7 +127,7 @@ Docker Route
|
||||
|
||||
.. caution::
|
||||
|
||||
If you want to use the included ``docker-compose.yml.example`` file, you
|
||||
If you want to use the included ``docker-compose.*.yml`` file, you
|
||||
need to have at least Docker version **17.09.0** and docker-compose
|
||||
version **1.17.0**.
|
||||
|
||||
@@ -129,20 +140,28 @@ Docker Route
|
||||
.. _Docker installation guide: https://docs.docker.com/engine/installation/
|
||||
.. _docker-compose installation guide: https://docs.docker.com/compose/install/
|
||||
|
||||
2. Modify ``docker-compose.yml`` to your preferences. You should change the path
|
||||
2. Copy either ``docker-compose.sqlite.yml`` or ``docker-compose.postgres.yml`` to
|
||||
``docker-compose.yml``, depending on which database backend you want to use.
|
||||
|
||||
.. hint::
|
||||
|
||||
For new installations, it is recommended to use PostgreSQL as the database
|
||||
backend.
|
||||
|
||||
2. Modify ``docker-compose.yml`` to your preferences. You may want to change the path
|
||||
to the consumption directory in this file. Find the line that specifies where
|
||||
to mount the consumption directory:
|
||||
|
||||
.. code::
|
||||
|
||||
|
||||
- ./consume:/usr/src/paperless/consume
|
||||
|
||||
|
||||
Replace the part BEFORE the colon with a local directory of your choice:
|
||||
|
||||
.. code::
|
||||
|
||||
- /home/jonaswinkler/paperless-inbox:/usr/src/paperless/consume
|
||||
|
||||
|
||||
Don't change the part after the colon or paperless wont find your documents.
|
||||
|
||||
|
||||
@@ -154,6 +173,11 @@ Docker Route
|
||||
1000 (the default for the first normal user on most systems), it will
|
||||
work out of the box without any modifications.
|
||||
|
||||
.. note::
|
||||
|
||||
You can use any settings from the file ``paperless.conf`` in this file.
|
||||
Have a look at :ref:`configuration` to see whats available.
|
||||
|
||||
4. Run ``docker-compose up -d``. This will create and start the necessary
|
||||
containers. This will also build the image of paperless if you grabbed the
|
||||
source archive.
|
||||
@@ -180,13 +204,161 @@ Docker Route
|
||||
simplifies deployment immensely. If you know your way around Docker, feel
|
||||
free to tinker around without using compose!
|
||||
|
||||
.. _`setup-bare_metal`:
|
||||
|
||||
Bare Metal Route
|
||||
================
|
||||
|
||||
.. warning::
|
||||
Paperless runs on linux only. The following procedure has been tested on a minimal
|
||||
installation of Debian/Buster, which is the current stable release at the time of
|
||||
writing. Windows is not and will never be supported.
|
||||
|
||||
TBD. User docker for now.
|
||||
1. Install dependencies. Paperless requires the following packages.
|
||||
|
||||
* ``python3`` 3.6, 3.7, 3.8 (3.9 is untested).
|
||||
* ``python3-pip``, optionally ``pipenv`` for package installation
|
||||
* ``python3-dev``
|
||||
|
||||
* ``imagemagick`` >= 6 for PDF conversion
|
||||
* ``optipng`` for optimising thumbnails
|
||||
* ``gnupg`` for handling encrypted documents
|
||||
* ``libpoppler-cpp-dev`` for PDF to text conversion
|
||||
* ``libmagic-dev`` for mime type detection
|
||||
* ``libpq-dev`` for PostgreSQL
|
||||
|
||||
These dependencies are required for OCRmyPDF, which is used for text recognition.
|
||||
|
||||
* ``unpaper``
|
||||
* ``ghostscript``
|
||||
* ``icc-profiles-free``
|
||||
* ``qpdf``
|
||||
* ``liblept5``
|
||||
* ``libxml2``
|
||||
* ``pngquant``
|
||||
* ``zlib1g``
|
||||
* ``tesseract-ocr`` >= 4.0.0 for OCR
|
||||
* ``tesseract-ocr`` language packs (``tesseract-ocr-eng``, ``tesseract-ocr-deu``, etc)
|
||||
|
||||
You will also need ``build-essential``, ``python3-setuptools`` and ``python3-wheel``
|
||||
for installing some of the python dependencies. You can remove that
|
||||
again after installation.
|
||||
|
||||
2. Install ``redis`` >= 5.0 and configure it to start automatically.
|
||||
|
||||
3. Optional. Install ``postgresql`` and configure a database, user and password for paperless. If you do not wish
|
||||
to use PostgreSQL, SQLite is avialable as well.
|
||||
|
||||
4. Get the release archive. If you pull the git repo as it is, you also have to compile the front end by yourself.
|
||||
Extract the frontend to a place from where you wish to execute it, such as ``/opt/paperless``.
|
||||
|
||||
5. Configure paperless. See :ref:`configuration` for details. Edit the included ``paperless.conf`` and adjust the
|
||||
settings to your needs. Required settings for getting paperless running are:
|
||||
|
||||
* ``PAPERLESS_REDIS`` should point to your redis server, such as redis://localhost:6379.
|
||||
* ``PAPERLESS_DBHOST`` should be the hostname on which your PostgreSQL server is running. Do not configure this
|
||||
to use SQLite instead. Also configure port, database name, user and password as necessary.
|
||||
* ``PAPERLESS_CONSUMPTION_DIR`` should point to a folder which paperless should watch for documents. You might
|
||||
want to have this somewhere else. Likewise, ``PAPERLESS_DATA_DIR`` and ``PAPERLESS_MEDIA_ROOT`` define where
|
||||
paperless stores its data. If you like, you can point both to the same directory.
|
||||
* ``PAPERLESS_SECRET_KEY`` should be a random sequence of characters. It's used for authentication. Failure
|
||||
to do so allows third parties to forge authentication credentials.
|
||||
|
||||
Many more adjustments can be made to paperless, especially the OCR part. The following options are recommended
|
||||
for everyone:
|
||||
|
||||
* Set ``PAPERLESS_OCR_LANGUAGE`` to the language most of your documents are written in.
|
||||
* Set ``PAPERLESS_TIME_ZONE`` to your local time zone.
|
||||
|
||||
6. Setup permissions. Create a system users under which you wish to run paperless. Ensure that these directories exist
|
||||
and that the user has write permissions to the following directories
|
||||
|
||||
* ``/opt/paperless/media``
|
||||
* ``/opt/paperless/data``
|
||||
* ``/opt/paperless/consume``
|
||||
|
||||
Adjust as necessary if you configured different folders.
|
||||
|
||||
7. Install python requirements. Paperless comes with both Pipfiles for ``pipenv`` as well as with a ``requirements.txt``.
|
||||
Both will install exactly the same requirements. It is up to you if you wish to use a virtual environment or not.
|
||||
|
||||
8. Go to ``/opt/paperless/src``, and execute the following commands:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
# This collects static files from paperless and django.
|
||||
python3 manage.py collectstatic --clear --no-input
|
||||
|
||||
# This creates the database schema.
|
||||
python3 manage.py migrate
|
||||
|
||||
# This creates your first paperless user
|
||||
python3 manage.py createsuperuser
|
||||
|
||||
9. Optional: Test that paperless is working by executing
|
||||
|
||||
.. code:: bash
|
||||
|
||||
# This collects static files from paperless and django.
|
||||
python3 manage.py runserver
|
||||
|
||||
and pointing your browser to http://localhost:8000/.
|
||||
|
||||
.. warning::
|
||||
|
||||
This is a development server which should not be used in
|
||||
production.
|
||||
|
||||
.. hint::
|
||||
|
||||
This will not start the consumer. Paperless does this in a
|
||||
separate process.
|
||||
|
||||
10. Setup systemd services to run paperless automatically. You may
|
||||
use the service definition files included in the ``scripts`` folder
|
||||
as a starting point.
|
||||
|
||||
Paperless needs the ``webserver`` script to run the webserver, the
|
||||
``consumer`` script to watch the input folder, and the ``scheduler``
|
||||
script to run tasks such as email checking and document consumption.
|
||||
|
||||
These services rely on redis and optionally the database server, but
|
||||
don't need to be started in any particular order. The example files
|
||||
depend on redis being started. If you use a database server, you should
|
||||
add additinal dependencies.
|
||||
|
||||
.. hint::
|
||||
|
||||
You may optionally set up your preferred web server to serve
|
||||
paperless as a wsgi application directly instead of running the
|
||||
``webserver`` service. The module containing the wsgi application
|
||||
is named ``paperless.wsgi``.
|
||||
|
||||
.. caution::
|
||||
|
||||
The included scripts run a ``gunicorn`` standalone server,
|
||||
which is fine for running paperless. It does support SSL,
|
||||
however, the documentation of GUnicorn states that you should
|
||||
use a proxy server in front of gunicorn instead.
|
||||
|
||||
11. Optional: Install a samba server and make the consumption folder
|
||||
available as a network share.
|
||||
|
||||
12. Configure ImageMagick to allow processing of PDF documents. Most distributions have
|
||||
this disabled by default, since PDF documents can contain malware. If
|
||||
you don't do this, paperless will fall back to ghostscript for certain steps
|
||||
such as thumbnail generation.
|
||||
|
||||
Edit ``/etc/ImageMagick-6/policy.xml`` and adjust
|
||||
|
||||
.. code::
|
||||
|
||||
<policy domain="coder" rights="none" pattern="PDF" />
|
||||
|
||||
to
|
||||
|
||||
.. code::
|
||||
|
||||
<policy domain="coder" rights="read|write" pattern="PDF" />
|
||||
|
||||
Migration to paperless-ng
|
||||
#########################
|
||||
@@ -196,15 +368,10 @@ things have changed under the hood, so you need to adapt your setup depending on
|
||||
how you installed paperless. The important things to keep in mind are as follows.
|
||||
|
||||
* Read the :ref:`changelog <paperless_changelog>` and take note of breaking changes.
|
||||
* It is recommended to use postgresql as the database now. The docker-compose
|
||||
deployment will automatically create a postgresql instance and instruct
|
||||
paperless to use it. This means that if you use the docker-compose script
|
||||
with your current paperless media and data volumes and used the default
|
||||
sqlite database, **it will not use your sqlite database and it may seem
|
||||
as if your documents are gone**. You may use the provided
|
||||
``docker-compose.sqlite.yml`` script instead, which does not use postgresql. See
|
||||
:ref:`setup-sqlite_to_psql` for details on how to move your data from
|
||||
sqlite to postgres.
|
||||
* You should decide if you want to stick with SQLite or want to migrate your database
|
||||
to PostgreSQL. See :ref:`setup-sqlite_to_psql` for details on how to move your data from
|
||||
SQLite to PostgreSQL. Both work fine with paperless. However, if you already have a
|
||||
database server running for other services, you might as well use it for paperless as well.
|
||||
* The task scheduler of paperless, which is used to execute periodic tasks
|
||||
such as email checking and maintenance, requires a `redis`_ message broker
|
||||
instance. The docker-compose route takes care of that.
|
||||
@@ -228,33 +395,193 @@ Migration to paperless-ng is then performed in a few simple steps:
|
||||
3. Download the latest release of paperless-ng. You can either go with the
|
||||
docker-compose files or use the archive to build the image yourself.
|
||||
You can either replace your current paperless folder or put paperless-ng
|
||||
in a different location. Paperless-ng will use the same docker volumes
|
||||
as paperless.
|
||||
in a different location.
|
||||
|
||||
4. Adjust ``docker-compose.yml`` and
|
||||
.. caution::
|
||||
|
||||
The release include a ``.env`` file. This will set the
|
||||
project name for docker compose to ``paperless`` so that paperless-ng will
|
||||
automatically reuse your existing paperless volumes. When you start it, it
|
||||
will migrate your existing data. After that, your old paperless installation
|
||||
will be incompatible with the migrated volumes.
|
||||
|
||||
4. Copy the ``docker-compose.sqlite.yml`` file to ``docker-compose.yml``.
|
||||
If you want to switch to PostgreSQL, do that after you migrated your existing
|
||||
SQLite database.
|
||||
|
||||
5. Adjust ``docker-compose.yml`` and
|
||||
``docker-compose.env`` to your needs.
|
||||
See `docker route`_ for details on which edits are required.
|
||||
See `docker route`_ for details on which edits are advised.
|
||||
|
||||
5. Update paperless. See :ref:`administration-updating` for details.
|
||||
6. Since ``docker-compose`` would just use the the old paperless image, we need to
|
||||
manually build a new image:
|
||||
|
||||
6. Start paperless-ng.
|
||||
.. code:: shell-session
|
||||
|
||||
$ docker-compose build
|
||||
|
||||
7. In order to find your existing documents with the new search feature, you need
|
||||
to invoke a one-time operation that will create the search index:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ docker-compose run --rm webserver document_index reindex
|
||||
|
||||
This will migrate your database and create the search index. After that,
|
||||
paperless will take care of maintaining the index by itself.
|
||||
|
||||
8. Start paperless-ng.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
$ docker-compose up -d
|
||||
|
||||
7. Paperless installed a permanent redirect to ``admin/`` in your browser. This
|
||||
redirect is still in place and prevents access to the new UI. Clear
|
||||
everything related to paperless in your browsers data in order to fix
|
||||
this issue.
|
||||
This will run paperless in the background and automatically start it on system boot.
|
||||
|
||||
9. Paperless installed a permanent redirect to ``admin/`` in your browser. This
|
||||
redirect is still in place and prevents access to the new UI. Clear
|
||||
browsing cache in order to fix this.
|
||||
|
||||
10. Optionally, follow the instructions below to migrate your existing data to PostgreSQL.
|
||||
|
||||
|
||||
.. _setup-sqlite_to_psql:
|
||||
|
||||
Moving data from sqlite to postgresql
|
||||
Moving data from SQLite to PostgreSQL
|
||||
=====================================
|
||||
|
||||
.. warning::
|
||||
Moving your data from SQLite to PostgreSQL is done via executing a series of django
|
||||
management commands as below.
|
||||
|
||||
.. caution::
|
||||
|
||||
Make sure that your SQLite database is migrated to the latest version.
|
||||
Starting paperless will make sure that this is the case. If your try to
|
||||
load data from an old database schema in SQLite into a newer database
|
||||
schema in PostgreSQL, you will run into trouble.
|
||||
|
||||
1. Stop paperless, if it is running.
|
||||
2. Tell paperless to use PostgreSQL:
|
||||
|
||||
a) With docker, copy the provided ``docker-compose.postgres.yml`` file to
|
||||
``docker-compose.yml``. Remember to adjust the consumption directory,
|
||||
if necessary.
|
||||
b) Without docker, configure the database in your ``paperless.conf`` file.
|
||||
See :ref:`configuration` for details.
|
||||
|
||||
3. Open a shell and initialize the database:
|
||||
|
||||
a) With docker, run the following command to open a shell within the paperless
|
||||
container:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ cd /path/to/paperless
|
||||
$ docker-compose run --rm webserver /bin/bash
|
||||
|
||||
This will launch the container and initialize the PostgreSQL database.
|
||||
|
||||
b) Without docker, open a shell in your virtual environment, switch to
|
||||
the ``src`` directory and create the database schema:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ cd /path/to/paperless
|
||||
$ pipenv shell
|
||||
$ cd src
|
||||
$ python3 manage.py migrate
|
||||
|
||||
This will not copy any data yet.
|
||||
|
||||
4. Dump your data from SQLite:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ python3 manage.py dumpdata --database=sqlite --exclude=contenttypes --exclude=auth.Permission > data.json
|
||||
|
||||
5. Load your data into PostgreSQL:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ python3 manage.py loaddata data.json
|
||||
|
||||
6. Exit the shell.
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ exit
|
||||
|
||||
7. Start paperless.
|
||||
|
||||
|
||||
Moving back to paperless
|
||||
========================
|
||||
|
||||
Lets say you migrated to Paperless-ng and used it for a while, but decided that
|
||||
you don't like it and want to move back (If you do, send me a mail about what
|
||||
part you didn't like!), you can totally do that with a few simple steps.
|
||||
|
||||
Paperless-ng modified the database schema slightly, however, these changes can
|
||||
be reverted while keeping your current data, so that your current data will
|
||||
be compatible with original Paperless.
|
||||
|
||||
Execute this:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ cd /path/to/paperless
|
||||
$ docker-compose run --rm webserver migrate documents 0023
|
||||
|
||||
Or without docker:
|
||||
|
||||
.. code:: shell-session
|
||||
|
||||
$ cd /path/to/paperless/src
|
||||
$ python3 manage.py migrate documents 0023
|
||||
|
||||
After that, you need to clear your cookies (Paperless-ng comes with updated
|
||||
dependencies that do cookie-processing differently) and probably your cache
|
||||
as well.
|
||||
|
||||
.. _setup-less_powerful_devices:
|
||||
|
||||
|
||||
Considerations for less powerful devices
|
||||
########################################
|
||||
|
||||
Paperless runs on Raspberry Pi. However, some things are rather slow on the Pi and
|
||||
configuring some options in paperless can help improve performance immensely:
|
||||
|
||||
* Stick with SQLite to save some resources.
|
||||
* Consider setting ``PAPERLESS_OCR_PAGES`` to 1, so that paperless will only OCR
|
||||
the first page of your documents.
|
||||
* ``PAPERLESS_TASK_WORKERS`` and ``PAPERLESS_THREADS_PER_WORKER`` are configured
|
||||
to use all cores. The Raspberry Pi models 3 and up have 4 cores, meaning that
|
||||
paperless will use 2 workers and 2 threads per worker. This may result in
|
||||
sluggish response times during consumption, so you might want to lower these
|
||||
settings (example: 2 workers and 1 thread to always have some computing power
|
||||
left for other tasks).
|
||||
* Keep ``PAPERLESS_OCR_MODE`` at its default value ``skip`` and consider OCR'ing
|
||||
your documents before feeding them into paperless. Some scanners are able to
|
||||
do this! You might want to even specify ``skip_noarchive`` to skip archive
|
||||
file generation for already ocr'ed documents entirely.
|
||||
* Set ``PAPERLESS_OPTIMIZE_THUMBNAILS`` to 'false' if you want faster consumption
|
||||
times. Thumbnails will be about 20% larger.
|
||||
|
||||
For details, refer to :ref:`configuration`.
|
||||
|
||||
.. note::
|
||||
|
||||
Updating the :ref:`automatic matching algorithm <advanced-automatic_matching>`
|
||||
takes quite a bit of time. However, the update mechanism checks if your
|
||||
data has changed before doing the heavy lifting. If you experience the
|
||||
algorithm taking too much cpu time, consider changing the schedule in the
|
||||
admin interface to daily. You can also manually invoke the task
|
||||
by changing the date and time of the next run to today/now.
|
||||
|
||||
The actual matching of the algorithm is fast and works on Raspberry Pi as
|
||||
well as on any other device.
|
||||
|
||||
|
||||
TBD.
|
||||
|
||||
.. _redis: https://redis.io/
|
||||
|
||||
@@ -29,75 +29,23 @@ Check for the following issues:
|
||||
Consumer fails to pickup any new files
|
||||
######################################
|
||||
|
||||
If you notice, that the consumer will only pickup files in the consumption
|
||||
If you notice that the consumer will only pickup files in the consumption
|
||||
directory at startup, but won't find any other files added later, check out
|
||||
the configuration file and enable filesystem polling with the setting
|
||||
``PAPERLESS_CONSUMER_POLLING``.
|
||||
|
||||
Operation not permitted
|
||||
#######################
|
||||
|
||||
Consumer warns ``OCR for XX failed``
|
||||
####################################
|
||||
You might see errors such as:
|
||||
|
||||
If you find the OCR accuracy to be too low, and/or the document consumer warns
|
||||
that ``OCR for XX failed, but we're going to stick with what we've got since
|
||||
FORGIVING_OCR is enabled``, then you might need to install the
|
||||
`Tesseract language files <http://packages.ubuntu.com/search?keywords=tesseract-ocr>`_
|
||||
marching your document's languages.
|
||||
.. code::
|
||||
|
||||
As an example, if you are running Paperless from any Ubuntu or Debian
|
||||
box, and your documents are written in Spanish you may need to run::
|
||||
chown: changing ownership of '../export': Operation not permitted
|
||||
|
||||
apt-get install -y tesseract-ocr-spa
|
||||
The container tries to set file ownership on the listed directories. This is
|
||||
required so that the user running paperless inside docker has write permissions
|
||||
to these folders. This happens when pointing these directories to NFS shares,
|
||||
for example.
|
||||
|
||||
|
||||
|
||||
Consumer dies with ``convert: unable to extent pixel cache``
|
||||
############################################################
|
||||
|
||||
During the consumption process, Paperless invokes ImageMagick's ``convert``
|
||||
program to translate the source document into something that the OCR engine can
|
||||
understand and this can burn a Very Large amount of memory if the original
|
||||
document is rather long. Similarly, if your system doesn't have a lot of
|
||||
memory to begin with (ie. a Raspberry Pi), then this can happen for even
|
||||
medium-sized documents.
|
||||
|
||||
The solution is to tell ImageMagick *not* to Use All The RAM, as is its
|
||||
default, and instead tell it to used a fixed amount. ``convert`` will then
|
||||
break up the job into hundreds of individual files and use them to slowly
|
||||
compile the finished image. Simply set ``PAPERLESS_CONVERT_MEMORY_LIMIT`` in
|
||||
``/etc/paperless.conf`` to something like ``32000000`` and you'll limit
|
||||
``convert`` to 32MB. Fiddle with this value as you like.
|
||||
|
||||
**HOWEVER**: Simply setting this value may not be enough on system where
|
||||
``/tmp`` is mounted as tmpfs, as this is where ``convert`` will write its
|
||||
temporary files. In these cases (most Systemd machines), you need to tell
|
||||
ImageMagick to use a different space for its scratch work. You do this by
|
||||
setting ``PAPERLESS_CONVERT_TMPDIR`` in ``/etc/paperless.conf`` to somewhere
|
||||
that's actually on a physical disk (and writable by the user running
|
||||
Paperless), like ``/var/tmp/paperless`` or ``/home/my_user/tmp`` in a pinch.
|
||||
|
||||
|
||||
DecompressionBombWarning and/or no text in the OCR output
|
||||
#########################################################
|
||||
|
||||
Some users have had issues using Paperless to consume PDFs that were created
|
||||
by merging Very Large Scanned Images into one PDF. If this happens to you,
|
||||
it's likely because the PDF you've created contains some very large pages
|
||||
(millions of pixels) and the process of converting the PDF to a OCR-friendly
|
||||
image is exploding.
|
||||
|
||||
Typically, this happens because the scanned images are created with a high
|
||||
DPI and then rolled into the PDF with an assumed DPI of 72 (the default).
|
||||
The best solution then is to specify the DPI used in the scan in the
|
||||
conversion-to-PDF step. So for example, if you scanned the original image
|
||||
with a DPI of 300, then merging the images into the single PDF with
|
||||
``convert`` should look like this:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
$ convert -density 300 *.jpg finished.pdf
|
||||
|
||||
For more information on this and situations like it, you should take a look
|
||||
at `Issue #118`_ as that's where this tip originated.
|
||||
|
||||
.. _Issue #118: https://github.com/the-paperless-project/paperless/issues/118
|
||||
Ensure that `chown` is possible on these directories.
|
||||
|
||||
@@ -5,13 +5,13 @@ Usage Overview
|
||||
Paperless is an application that manages your personal documents. With
|
||||
the help of a document scanner (see :ref:`scanners`), paperless transforms
|
||||
your wieldy physical document binders into a searchable archive and
|
||||
provices many utilities for finding and managing your documents.
|
||||
provides many utilities for finding and managing your documents.
|
||||
|
||||
|
||||
Terms and definitions
|
||||
#####################
|
||||
|
||||
Paperless esentially consists of two different parts for managing your
|
||||
Paperless essentially consists of two different parts for managing your
|
||||
documents:
|
||||
|
||||
* The *consumer* watches a specified folder and adds all documents in that
|
||||
@@ -30,12 +30,12 @@ Each document has a couple of fields that you can assign to them:
|
||||
tag, however, a single document can also have multiple tags. This is not
|
||||
possible with folders. The reason folders are not implemented in paperless
|
||||
is simply that tags are much more versatile than folders.
|
||||
* A *document type* is used to demarkate the type of a document such as letter,
|
||||
* A *document type* is used to demarcate the type of a document such as letter,
|
||||
bank statement, invoice, contract, etc. It is used to identify what a document
|
||||
is about.
|
||||
* The *date added* of a document is the date the document was scanned into
|
||||
paperless. You cannot and should not change this date.
|
||||
* The *date created* of a document is the date the document was intially issued.
|
||||
* The *date created* of a document is the date the document was initially issued.
|
||||
This can be the date you bought a product, the date you signed a contract, or
|
||||
the date a letter was sent to you.
|
||||
* The *archive serial number* (short: ASN) of a document is the identifier of
|
||||
@@ -60,6 +60,31 @@ Once you've got Paperless setup, you need to start feeding documents into it.
|
||||
Currently, there are three options: the consumption directory, IMAP (email), and
|
||||
HTTP POST.
|
||||
|
||||
When adding documents to paperless, it will perform the following operations on
|
||||
your documents:
|
||||
|
||||
1. OCR the document, if it has no text. Digital documents usually have text,
|
||||
and this step will be skipped for those documents.
|
||||
2. Paperless will create an archiveable PDF/A document from your document.
|
||||
If this document is coming from your scanner, it will have embedded selectable text.
|
||||
3. Paperless performs automatic matching of tags, correspondents and types on the
|
||||
document before storing it in the database.
|
||||
|
||||
.. hint::
|
||||
|
||||
This process can be configured to fit your needs. If you don't want paperless
|
||||
to create archived versions for digital documents, you can configure that by
|
||||
configuring ``PAPERLESS_OCR_MODE=skip_noarchive``. Please read the
|
||||
:ref:`relevant section in the documentation <configuration-ocr>`.
|
||||
|
||||
.. note::
|
||||
|
||||
No matter which options you choose, Paperless will always store the original
|
||||
document that it found in the consumption directory or in the mail and
|
||||
will never overwrite that document. Archived versions are stored alongside the
|
||||
digital versions.
|
||||
|
||||
|
||||
|
||||
The consumption directory
|
||||
=========================
|
||||
@@ -82,6 +107,7 @@ files from the scanner. Typically, you're looking at an FTP server like
|
||||
|
||||
.. TODO: hyperref to configuration of the location of this magic folder.
|
||||
|
||||
.. _usage-email:
|
||||
|
||||
IMAP (Email)
|
||||
============
|
||||
@@ -130,9 +156,14 @@ These are as follows:
|
||||
|
||||
With the correct set of rules, you can completely automate your email documents.
|
||||
Create rules for every correspondent you receive digital documents from and
|
||||
paperless will read them automatically. The default acion "mark as read" is
|
||||
paperless will read them automatically. The default action "mark as read" is
|
||||
pretty tame and will not cause any damage or data loss whatsoever.
|
||||
|
||||
You can also setup a special folder in your mail account for paperless and use
|
||||
your favorite mail client to move to be consumed mails into that folder
|
||||
automatically or manually and tell paperless to move them to yet another folder
|
||||
after consumption. It's up to you.
|
||||
|
||||
.. note::
|
||||
|
||||
Paperless will process the rules in the order defined in the admin page.
|
||||
@@ -150,6 +181,62 @@ REST API
|
||||
|
||||
You can also submit a document using the REST API, see :ref:`api-file_uploads` for details.
|
||||
|
||||
.. _basic-searching:
|
||||
|
||||
Searching
|
||||
#########
|
||||
|
||||
Paperless offers an extensive searching mechanism that is designed to allow you to quickly
|
||||
find a document you're looking for (for example, that thing that just broke and you bought
|
||||
a couple months ago, that contract you signed 8 years ago).
|
||||
|
||||
When you search paperless for a document, it tries to match this query against your documents.
|
||||
Paperless will look for matching documents by inspecting their content, title, correspondent,
|
||||
type and tags. Paperless returns a scored list of results, so that documents matching your query
|
||||
better will appear further up in the search results.
|
||||
|
||||
By default, paperless returns only documents which contain all words typed in the search bar.
|
||||
However, paperless also offers advanced search syntax if you want to drill down the results
|
||||
further.
|
||||
|
||||
Matching documents with logical expressions:
|
||||
|
||||
.. code::
|
||||
|
||||
shopname AND (product1 OR product2)
|
||||
|
||||
Matching specific tags, correspondents or types:
|
||||
|
||||
.. code::
|
||||
|
||||
type:invoice tag:unpaid
|
||||
correspondent:university certificate
|
||||
|
||||
Matching dates:
|
||||
|
||||
.. code::
|
||||
|
||||
created:[2005 to 2009]
|
||||
added:yesterday
|
||||
modified:today
|
||||
|
||||
Matching inexact words:
|
||||
|
||||
.. code::
|
||||
|
||||
produ*name
|
||||
|
||||
.. note::
|
||||
|
||||
Inexact terms are hard for search indexes. These queries might take a while to execute. That's why paperless offers
|
||||
auto complete and query correction.
|
||||
|
||||
All of these constructs can be combined as you see fit.
|
||||
If you want to learn more about the query language used by paperless, paperless uses Whoosh's default query language.
|
||||
Head over to `Whoosh query language <https://whoosh.readthedocs.io/en/latest/querylang.html>`_.
|
||||
For details on what date parsing utilities are available, see
|
||||
`Date parsing <https://whoosh.readthedocs.io/en/latest/dates.html#parsing-date-queries>`_.
|
||||
|
||||
|
||||
.. _usage-recommended_workflow:
|
||||
|
||||
@@ -176,7 +263,7 @@ Processing of the physical documents
|
||||
====================================
|
||||
|
||||
Keep a physical inbox. Whenever you receive a document that you need to
|
||||
archive, put it into your inbox. Regulary, do the following for all documents
|
||||
archive, put it into your inbox. Regularly, do the following for all documents
|
||||
in your inbox:
|
||||
|
||||
1. For each document, decide if you need to keep the document in physical
|
||||
@@ -211,18 +298,24 @@ Once you have scanned in a document, proceed in paperless as follows.
|
||||
|
||||
1. If the document has an ASN, assign the ASN to the document.
|
||||
2. Assign a correspondent to the document (i.e., your employer, bank, etc)
|
||||
This isnt strictly necessary but helps in finding a document when you need
|
||||
This isn't strictly necessary but helps in finding a document when you need
|
||||
it.
|
||||
3. Assign a document type (i.e., invoice, bank statement, etc) to the document
|
||||
This isnt strictly necessary but helps in finding a document when you need
|
||||
This isn't strictly necessary but helps in finding a document when you need
|
||||
it.
|
||||
4. Assign a proper title to the document (the name of an item you bought, the
|
||||
subject of the letter, etc)
|
||||
5. Check that the date of the document is corrent. Paperless tries to read
|
||||
5. Check that the date of the document is correct. Paperless tries to read
|
||||
the date from the content of the document, but this fails sometimes if the
|
||||
OCR is bad or multiple dates appear on the document.
|
||||
6. Remove inbox tags from the documents.
|
||||
|
||||
.. hint::
|
||||
|
||||
You can setup manual matching rules for your correspondents and tags and
|
||||
paperless will assign them automatically. After consuming a couple documents,
|
||||
you can even ask paperless to *learn* when to assign tags and correspondents
|
||||
by itself. For details on this feature, see :ref:`advanced-matching`.
|
||||
|
||||
Task management
|
||||
===============
|
||||
|
||||
@@ -1,287 +1,61 @@
|
||||
# Sample paperless.conf
|
||||
# Copy this file to /etc/paperless.conf and modify it to suit your needs.
|
||||
# As this file contains passwords it should only be readable by the user
|
||||
# running paperless.
|
||||
# Have a look at the docs for documentation.
|
||||
# https://paperless-ng.readthedocs.io/en/latest/configuration.html
|
||||
|
||||
###############################################################################
|
||||
#### Message Broker ####
|
||||
###############################################################################
|
||||
# Debug. Only enable this for development.
|
||||
|
||||
#PAPERLESS_DEBUG=false
|
||||
|
||||
# Required services
|
||||
|
||||
# This is required for processing scheduled tasks such as email fetching, index
|
||||
# optimization and for training the automatic document matcher.
|
||||
# Defaults to localhost:6379.
|
||||
#PAPERLESS_REDIS=redis://localhost:6379
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Database Settings ####
|
||||
###############################################################################
|
||||
|
||||
# By default, sqlite is used as the database backend. This can be changed here.
|
||||
# The docker-compose service definition uses a postgresql server. The
|
||||
# configuration for this is already done inside the docker-compose.env file.
|
||||
|
||||
#Set PAPERLESS_DBHOST and postgresql will be used instead of mysql.
|
||||
#PAPERLESS_DBHOST=localhost
|
||||
|
||||
#Adjust port if necessary
|
||||
#PAPERLESS_DBPORT=
|
||||
|
||||
#name, user and pass all default to "paperless"
|
||||
#PAPERLESS_DBPORT=5432
|
||||
#PAPERLESS_DBNAME=paperless
|
||||
#PAPERLESS_DBUSER=paperless
|
||||
#PAPERLESS_DBPASS=paperless
|
||||
|
||||
# Paths and folders
|
||||
|
||||
###############################################################################
|
||||
#### Paths & Folders ####
|
||||
###############################################################################
|
||||
|
||||
# This where your documents should go to be consumed. Make sure that it exists
|
||||
# and that the user running the paperless service can read/write its contents
|
||||
# before you start Paperless.
|
||||
PAPERLESS_CONSUMPTION_DIR=../consume
|
||||
|
||||
# This is where paperless stores all its data (search index, sqlite database,
|
||||
# classification model, etc).
|
||||
#PAPERLESS_CONSUMPTION_DIR=../consume
|
||||
#PAPERLESS_DATA_DIR=../data
|
||||
|
||||
# This is where your documents and thumbnails are stored.
|
||||
#PAPERLESS_MEDIA_ROOT=../media
|
||||
|
||||
# Override the default STATIC_ROOT here. This is where all static files
|
||||
# created using "collectstatic" manager command are stored.
|
||||
#PAPERLESS_STATICDIR=../static
|
||||
|
||||
|
||||
# Override the STATIC_URL here. Unless you're hosting Paperless off a
|
||||
# subdomain like /paperless/, you probably don't need to change this.
|
||||
#PAPERLESS_STATIC_URL=/static/
|
||||
|
||||
|
||||
# Specify a filename format for the document (directories are supported)
|
||||
# Use the following placeholders:
|
||||
# * {correspondent}
|
||||
# * {title}
|
||||
# * {created}
|
||||
# * {added}
|
||||
# * {tags[KEY]} If your tags conform to key_value or key-value
|
||||
# * {tags[INDEX]} If your tags are strings, select the tag by index
|
||||
# Uniqueness of filenames is ensured, as an incrementing counter is attached
|
||||
# to each filename.
|
||||
#PAPERLESS_FILENAME_FORMAT=
|
||||
|
||||
###############################################################################
|
||||
#### Security ####
|
||||
###############################################################################
|
||||
# Security and hosting
|
||||
|
||||
# Controls whether django's debug mode is enabled. Disable this on production
|
||||
# systems. Debug mode is disabled by default.
|
||||
#PAPERLESS_DEBUG=false
|
||||
|
||||
# GnuPG encryption is deprecated and will be removed in future versions.
|
||||
#
|
||||
# Dont use it. It does not provide any security at all.
|
||||
#
|
||||
# Paperless can be instructed to attempt to encrypt your PDF files with GPG
|
||||
# using the PAPERLESS_PASSPHRASE specified below. If however you're not
|
||||
# concerned about encrypting these files (for example if you have disk
|
||||
# encryption locally) then you don't need this and can safely leave this value
|
||||
# un-set.
|
||||
#
|
||||
# One final note about the passphrase. Once you've consumed a document with
|
||||
# one passphrase, DON'T CHANGE IT. Paperless assumes this to be a constant and
|
||||
# can't properly export documents that were encrypted with an old passphrase if
|
||||
# you've since changed it to a new one.
|
||||
#
|
||||
# The default is to not use encryption at all.
|
||||
#PAPERLESS_PASSPHRASE=secret
|
||||
|
||||
|
||||
# The secret key has a default that should be fine so long as you're hosting
|
||||
# Paperless on a closed network. However, if you're putting this anywhere
|
||||
# public, you should change the key to something unique and verbose.
|
||||
#PAPERLESS_SECRET_KEY=change-me
|
||||
|
||||
|
||||
# If you're planning on putting Paperless on the open internet, then you
|
||||
# really should set this value to the domain name you're using. Failing to do
|
||||
# so leaves you open to HTTP host header attacks:
|
||||
# https://docs.djangoproject.com/en/1.10/topics/security/#host-headers-virtual-hosting
|
||||
#
|
||||
# Just remember that this is a comma-separated list, so "example.com" is fine,
|
||||
# as is "example.com,www.example.com", but NOT " example.com" or "example.com,"
|
||||
#PAPERLESS_ALLOWED_HOSTS=example.com,www.example.com
|
||||
|
||||
# If you decide to use the Paperless API in an ajax call, you need to add your
|
||||
# servers to the list of allowed hosts that can do CORS calls. By default
|
||||
# Paperless allows calls from localhost:8080, but you'd like to change that,
|
||||
# you can set this value to a comma-separated list.
|
||||
#PAPERLESS_CORS_ALLOWED_HOSTS=localhost:8080,example.com,localhost:8000
|
||||
|
||||
# To host paperless under a subpath url like example.com/paperless you set
|
||||
# this value to /paperless. No trailing slash!
|
||||
#
|
||||
# https://docs.djangoproject.com/en/1.11/ref/settings/#force-script-name
|
||||
#PAPERLESS_FORCE_SCRIPT_NAME=
|
||||
#PAPERLESS_STATIC_URL=/static/
|
||||
#PAPERLESS_AUTO_LOGIN_USERNAME=
|
||||
|
||||
###############################################################################
|
||||
#### Software Tweaks ####
|
||||
###############################################################################
|
||||
# OCR settings
|
||||
|
||||
# Paperless does multiple things in the background: Maintain the search index,
|
||||
# maintain the automatic matching algorithm, check emails, consume documents,
|
||||
# etc. This variable specifies how many things it will do in parallel.
|
||||
#PAPERLESS_TASK_WORKERS=1
|
||||
|
||||
# Furthermore, paperless uses multiple threads when consuming documents to
|
||||
# speed up OCR. This variable specifies how many pages paperless will process
|
||||
# in parallel on a single document.
|
||||
#PAPERLESS_THREADS_PER_WORKER=1
|
||||
|
||||
# Ensure that the product
|
||||
# PAPERLESS_TASK_WORKERS * PAPERLESS_THREADS_PER_WORKER
|
||||
# does not exceed your CPU core count or else paperless will be extremely slow.
|
||||
# If you want paperless to process many documents in parallel, choose a high
|
||||
# worker count. If you want paperless to process very large documents faster,
|
||||
# use a higher thread per worker count.
|
||||
# The default is a balance between the two, according to your CPU core count,
|
||||
# with a slight favor towards threads per worker, and using as much cores as
|
||||
# possible.
|
||||
# If you only specify PAPERLESS_TASK_WORKERS, paperless will adjust
|
||||
# PAPERLESS_THREADS_PER_WORKER automatically.
|
||||
|
||||
# If paperless won't find documents added to your consume folder, it might
|
||||
# not be able to automatically detect filesystem changes. In that case,
|
||||
# specify a polling interval in seconds below, which will then cause paperless
|
||||
# to periodically check your consumption directory for changes.
|
||||
#PAPERLESS_CONSUMER_POLLING=10
|
||||
|
||||
|
||||
# When the consumer detects a duplicate document, it will not touch the
|
||||
# original document. This default behavior can be changed here.
|
||||
#PAPERLESS_CONSUMER_DELETE_DUPLICATES=false
|
||||
|
||||
# Use optipng to optimize thumbnails. This usually reduces the sice of
|
||||
# thumbnails by about 20%, but uses considerable compute time during
|
||||
# consumption.
|
||||
#PAPERLESS_OPTIMIZE_THUMBNAILS=true
|
||||
|
||||
# After a document is consumed, Paperless can trigger an arbitrary script if
|
||||
# you like. This script will be passed a number of arguments for you to work
|
||||
# with. The default is blank, which means nothing will be executed. For more
|
||||
# information, take a look at the docs:
|
||||
# http://paperless.readthedocs.org/en/latest/consumption.html#hooking-into-the-consumption-process
|
||||
#PAPERLESS_POST_CONSUME_SCRIPT=/path/to/an/arbitrary/script.sh
|
||||
|
||||
# By default, paperless will check the document text for document date information.
|
||||
# Uncomment the line below to enable checking the document filename for date
|
||||
# information. The date order can be set to any option as specified in
|
||||
# https://dateparser.readthedocs.io/en/latest/#settings. The filename will be
|
||||
# checked first, and if nothing is found, the document text will be checked
|
||||
# as normal.
|
||||
#PAPERLESS_FILENAME_DATE_ORDER=YMD
|
||||
|
||||
# Sometimes devices won't create filenames which can be parsed properly
|
||||
# by the filename parser (see
|
||||
# https://paperless.readthedocs.io/en/latest/guesswork.html).
|
||||
#
|
||||
# This setting allows to specify a list of transformations
|
||||
# in regular expression syntax, which are passed in order to re.sub.
|
||||
# Transformation stops after the first match, so at most one transformation
|
||||
# is applied.
|
||||
#
|
||||
# Syntax is a JSON array of dictionaries containing "pattern" and "repl"
|
||||
# as keys.
|
||||
#
|
||||
# The example below transforms filenames created by a Brother ADS-2400N
|
||||
# document scanner in its standard configuration `Name_Date_Count', so that
|
||||
# count is used as title, name as tag and date can be parsed by paperless.
|
||||
#PAPERLESS_FILENAME_PARSE_TRANSFORMS=[{"pattern":"^([a-z]+)_(\\d{8})_(\\d{6})_([0-9]+)\\.", "repl":"\\2\\3Z - \\4 - \\1."}]
|
||||
|
||||
#
|
||||
# The following values use sensible defaults for modern systems, but if you're
|
||||
# running Paperless on a low-resource device (like a Raspberry Pi), modifying
|
||||
# some of these values may be necessary.
|
||||
#
|
||||
|
||||
|
||||
# Customize the default language that tesseract will attempt to use when
|
||||
# parsing documents. The default language is used whenever
|
||||
# - No language could be detected on a document
|
||||
# - No tesseract data files are available for the detected language
|
||||
# It should be a 3-letter language code consistent with ISO
|
||||
# 639: https://www.loc.gov/standards/iso639-2/php/code_list.php
|
||||
#PAPERLESS_OCR_LANGUAGE=eng
|
||||
|
||||
|
||||
# On smaller systems, or even in the case of Very Large Documents, the consumer
|
||||
# may explode, complaining about how it's "unable to extend pixel cache". In
|
||||
# such cases, try setting this to a reasonably low value, like 32000000. The
|
||||
# default is to use whatever is necessary to do everything without writing to
|
||||
# disk, and units are in megabytes.
|
||||
#
|
||||
# For more information on how to use this value, you should probably search
|
||||
# the web for "MAGICK_MEMORY_LIMIT".
|
||||
#PAPERLESS_OCR_MODE=skip
|
||||
#PAPERLESS_OCR_OUTPUT_TYPE=pdfa
|
||||
#PAPERLESS_OCR_PAGES=1
|
||||
#PAPERLESS_OCR_IMAGE_DPI=300
|
||||
#PAPERLESS_OCR_USER_ARG={}
|
||||
#PAPERLESS_CONVERT_MEMORY_LIMIT=0
|
||||
|
||||
|
||||
# Similar to the memory limit, if you've got a small system and your OS mounts
|
||||
# /tmp as tmpfs, you should set this to a path that's on a physical disk, like
|
||||
# /home/your_user/tmp or something. ImageMagick will use this as scratch space
|
||||
# when crunching through very large documents.
|
||||
#
|
||||
# For more information on how to use this value, you should probably search
|
||||
# the web for "MAGICK_TMPDIR".
|
||||
#PAPERLESS_CONVERT_TMPDIR=/var/tmp/paperless
|
||||
|
||||
# Software tweaks
|
||||
|
||||
# By default the conversion density setting for documents is 300DPI, in some
|
||||
# cases it has proven useful to configure a lesser value.
|
||||
# This setting has a high impact on the physical size of tmp page files,
|
||||
# the speed of document conversion, and can affect the accuracy of OCR
|
||||
# results. Individual results can vary and this setting should be tested
|
||||
# thoroughly against the documents you are importing to see if it has any
|
||||
# impacts either negative or positive.
|
||||
# Testing on limited document sets has shown a setting of 200 can cut the
|
||||
# size of tmp files by 1/3, and speed up conversion by up to 4x
|
||||
# with little impact to OCR accuracy.
|
||||
#PAPERLESS_CONVERT_DENSITY=300
|
||||
|
||||
# By default Paperless does not OCR a document if the text can be retrieved from
|
||||
# the document directly. Set to true to always OCR documents.
|
||||
#PAPERLESS_OCR_ALWAYS=false
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Interface ####
|
||||
###############################################################################
|
||||
|
||||
# Override the default UTC time zone here.
|
||||
# See https://docs.djangoproject.com/en/1.10/ref/settings/#std:setting-TIME_ZONE
|
||||
# for details on how to set it.
|
||||
#PAPERLESS_TASK_WORKERS=1
|
||||
#PAPERLESS_THREADS_PER_WORKER=1
|
||||
#PAPERLESS_TIME_ZONE=UTC
|
||||
#PAPERLESS_CONSUMER_POLLING=10
|
||||
#PAPERLESS_CONSUMER_DELETE_DUPLICATES=false
|
||||
#PAPERLESS_OPTIMIZE_THUMBNAILS=true
|
||||
#PAPERLESS_POST_CONSUME_SCRIPT=/path/to/an/arbitrary/script.sh
|
||||
#PAPERLESS_FILENAME_DATE_ORDER=YMD
|
||||
#PAPERLESS_FILENAME_PARSE_TRANSFORMS=[]
|
||||
|
||||
# Binaries
|
||||
|
||||
###############################################################################
|
||||
#### Third-Party Binaries ####
|
||||
###############################################################################
|
||||
|
||||
# There are a few external software packages that Paperless expects to find on
|
||||
# your system when it starts up. Unless you've done something creative with
|
||||
# their installation, you probably won't need to edit any of these. However,
|
||||
# if you've installed these programs somewhere where simply typing the name of
|
||||
# the program doesn't automatically execute it (ie. the program isn't in your
|
||||
# $PATH), then you'll need to specify the literal path for that program here.
|
||||
|
||||
# Convert (part of the ImageMagick suite)
|
||||
#PAPERLESS_CONVERT_BINARY=/usr/bin/convert
|
||||
|
||||
# Ghostscript
|
||||
#PAPERLESS_GS_BINARY=/usr/bin/gs
|
||||
|
||||
# Unpaper
|
||||
#PAPERLESS_UNPAPER_BINARY=/usr/bin/unpaper
|
||||
|
||||
# Optipng (for optimising thumbnail sizes)
|
||||
#PAPERLESS_OPTIPNG_BINARY=/usr/bin/optipng
|
||||
|
||||
@@ -1,5 +1,19 @@
|
||||
#!/bin/bash
|
||||
|
||||
# Release checklist
|
||||
# - wait for travis build.
|
||||
# adjust src/paperless/version.py
|
||||
# changelog in the documentation
|
||||
# adjust versions in docker/hub/*
|
||||
# If docker-compose was modified: all compose files are the same.
|
||||
|
||||
# Steps:
|
||||
# run release script "dev", push
|
||||
# if it works: new tag, merge into master
|
||||
# on master: make release "lastest", push
|
||||
# on master: make release "version-tag", push
|
||||
# publish release files
|
||||
|
||||
set -e
|
||||
|
||||
|
||||
@@ -17,6 +31,7 @@ PAPERLESS_ROOT=$(git rev-parse --show-toplevel)
|
||||
# output directory
|
||||
PAPERLESS_DIST="$PAPERLESS_ROOT/dist"
|
||||
PAPERLESS_DIST_APP="$PAPERLESS_DIST/paperless-ng"
|
||||
PAPERLESS_DIST_DOCKERFILES="$PAPERLESS_DIST/paperless-ng-dockerfiles"
|
||||
|
||||
if [ -d "$PAPERLESS_DIST" ]
|
||||
then
|
||||
@@ -27,6 +42,8 @@ fi
|
||||
mkdir "$PAPERLESS_DIST"
|
||||
mkdir "$PAPERLESS_DIST_APP"
|
||||
mkdir "$PAPERLESS_DIST_APP/docker"
|
||||
mkdir "$PAPERLESS_DIST_APP/scripts"
|
||||
mkdir "$PAPERLESS_DIST_DOCKERFILES"
|
||||
|
||||
# setup dependencies.
|
||||
|
||||
@@ -78,8 +95,9 @@ cp "$PAPERLESS_ROOT/docker/local/"* "$PAPERLESS_DIST_APP"
|
||||
cp "$PAPERLESS_ROOT/docker/docker-compose.env" "$PAPERLESS_DIST_APP"
|
||||
|
||||
# docker files for pulling from docker hub
|
||||
cp "$PAPERLESS_ROOT/docker/hub/"* "$PAPERLESS_DIST"
|
||||
cp "$PAPERLESS_ROOT/docker/docker-compose.env" "$PAPERLESS_DIST"
|
||||
cp "$PAPERLESS_ROOT/docker/hub/"* "$PAPERLESS_DIST_DOCKERFILES"
|
||||
cp "$PAPERLESS_ROOT/.env" "$PAPERLESS_DIST_DOCKERFILES"
|
||||
cp "$PAPERLESS_ROOT/docker/docker-compose.env" "$PAPERLESS_DIST_DOCKERFILES"
|
||||
|
||||
# auxiliary files required for the docker image
|
||||
cp "$PAPERLESS_ROOT/docker/docker-entrypoint.sh" "$PAPERLESS_DIST_APP/docker/"
|
||||
@@ -87,6 +105,11 @@ cp "$PAPERLESS_ROOT/docker/gunicorn.conf.py" "$PAPERLESS_DIST_APP/docker/"
|
||||
cp "$PAPERLESS_ROOT/docker/imagemagick-policy.xml" "$PAPERLESS_DIST_APP/docker/"
|
||||
cp "$PAPERLESS_ROOT/docker/supervisord.conf" "$PAPERLESS_DIST_APP/docker/"
|
||||
|
||||
# auxiliary files for bare metal installs
|
||||
cp "$PAPERLESS_ROOT/scripts/paperless-webserver.service" "$PAPERLESS_DIST_APP/scripts/"
|
||||
cp "$PAPERLESS_ROOT/scripts/paperless-consumer.service" "$PAPERLESS_DIST_APP/scripts/"
|
||||
cp "$PAPERLESS_ROOT/scripts/paperless-scheduler.service" "$PAPERLESS_DIST_APP/scripts/"
|
||||
|
||||
# try to make the docker build.
|
||||
|
||||
cd "$PAPERLESS_DIST_APP"
|
||||
@@ -98,3 +121,4 @@ docker build . -t "jonaswinkler/paperless-ng:$VERSION"
|
||||
cd "$PAPERLESS_DIST"
|
||||
|
||||
tar -cJf "paperless-ng-$VERSION.tar.xz" paperless-ng/
|
||||
tar -cJf "paperless-ng-$VERSION-dockerfiles.tar.xz" paperless-ng-dockerfiles/
|
||||
|
||||
@@ -1,10 +1,12 @@
|
||||
[Unit]
|
||||
Description=Paperless consumer
|
||||
Requires=redis.service
|
||||
|
||||
[Service]
|
||||
User=paperless
|
||||
Group=paperless
|
||||
ExecStart=/home/paperless/project/virtualenv/bin/python /home/paperless/project/src/manage.py document_consumer
|
||||
WorkingDirectory=/opt/paperless/src
|
||||
ExecStart=python3 manage.py document_consumer
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
12
scripts/paperless-scheduler.service
Normal file
@@ -0,0 +1,12 @@
|
||||
[Unit]
|
||||
Description=Paperless consumer
|
||||
Requires=redis.service
|
||||
|
||||
[Service]
|
||||
User=paperless
|
||||
Group=paperless
|
||||
WorkingDirectory=/opt/paperless/src
|
||||
ExecStart=python3 manage.py qcluster
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
@@ -2,11 +2,13 @@
|
||||
Description=Paperless webserver
|
||||
After=network.target
|
||||
Wants=network.target
|
||||
Requires=redis.service
|
||||
|
||||
[Service]
|
||||
User=paperless
|
||||
Group=paperless
|
||||
ExecStart=/home/paperless/project/virtualenv/bin/gunicorn --pythonpath=/home/paperless/project/src paperless.wsgi -w 2
|
||||
WorkingDirectory=/opt/paperless/src
|
||||
ExecStart=/opt/paperless/.local/bin/gunicorn paperless.wsgi -w 2 -b 0.0.0.0:8000
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
@@ -1,126 +1,130 @@
|
||||
{
|
||||
"$schema": "./node_modules/@angular/cli/lib/config/schema.json",
|
||||
"version": 1,
|
||||
"newProjectRoot": "projects",
|
||||
"projects": {
|
||||
"paperless-ui": {
|
||||
"projectType": "application",
|
||||
"schematics": {},
|
||||
"root": "",
|
||||
"sourceRoot": "src",
|
||||
"prefix": "app",
|
||||
"architect": {
|
||||
"build": {
|
||||
"builder": "@angular-devkit/build-angular:browser",
|
||||
"options": {
|
||||
"outputPath": "dist/paperless-ui",
|
||||
"outputHashing": "none",
|
||||
"index": "src/index.html",
|
||||
"main": "src/main.ts",
|
||||
"polyfills": "src/polyfills.ts",
|
||||
"tsConfig": "tsconfig.app.json",
|
||||
"aot": true,
|
||||
"assets": [
|
||||
"src/favicon.ico",
|
||||
"src/assets"
|
||||
],
|
||||
"styles": [
|
||||
"node_modules/bootstrap/dist/css/bootstrap.min.css",
|
||||
"src/styles.css"
|
||||
],
|
||||
"scripts": []
|
||||
},
|
||||
"configurations": {
|
||||
"production": {
|
||||
"fileReplacements": [
|
||||
{
|
||||
"replace": "src/environments/environment.ts",
|
||||
"with": "src/environments/environment.prod.ts"
|
||||
}
|
||||
],
|
||||
"optimization": true,
|
||||
"outputHashing": "none",
|
||||
"sourceMap": false,
|
||||
"extractCss": true,
|
||||
"namedChunks": false,
|
||||
"extractLicenses": true,
|
||||
"vendorChunk": false,
|
||||
"buildOptimizer": true,
|
||||
"budgets": [
|
||||
{
|
||||
"type": "initial",
|
||||
"maximumWarning": "2mb",
|
||||
"maximumError": "5mb"
|
||||
},
|
||||
{
|
||||
"type": "anyComponentStyle",
|
||||
"maximumWarning": "6kb",
|
||||
"maximumError": "10kb"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"serve": {
|
||||
"builder": "@angular-devkit/build-angular:dev-server",
|
||||
"options": {
|
||||
"browserTarget": "paperless-ui:build"
|
||||
},
|
||||
"configurations": {
|
||||
"production": {
|
||||
"browserTarget": "paperless-ui:build:production"
|
||||
}
|
||||
}
|
||||
},
|
||||
"extract-i18n": {
|
||||
"builder": "@angular-devkit/build-angular:extract-i18n",
|
||||
"options": {
|
||||
"browserTarget": "paperless-ui:build"
|
||||
}
|
||||
},
|
||||
"test": {
|
||||
"builder": "@angular-devkit/build-angular:karma",
|
||||
"options": {
|
||||
"main": "src/test.ts",
|
||||
"polyfills": "src/polyfills.ts",
|
||||
"tsConfig": "tsconfig.spec.json",
|
||||
"karmaConfig": "karma.conf.js",
|
||||
"assets": [
|
||||
"src/favicon.ico",
|
||||
"src/assets"
|
||||
],
|
||||
"styles": [
|
||||
"src/styles.css"
|
||||
],
|
||||
"scripts": []
|
||||
}
|
||||
},
|
||||
"lint": {
|
||||
"builder": "@angular-devkit/build-angular:tslint",
|
||||
"options": {
|
||||
"tsConfig": [
|
||||
"tsconfig.app.json",
|
||||
"tsconfig.spec.json",
|
||||
"e2e/tsconfig.json"
|
||||
],
|
||||
"exclude": [
|
||||
"**/node_modules/**"
|
||||
]
|
||||
}
|
||||
},
|
||||
"e2e": {
|
||||
"builder": "@angular-devkit/build-angular:protractor",
|
||||
"options": {
|
||||
"protractorConfig": "e2e/protractor.conf.js",
|
||||
"devServerTarget": "paperless-ui:serve"
|
||||
},
|
||||
"configurations": {
|
||||
"production": {
|
||||
"devServerTarget": "paperless-ui:serve:production"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}},
|
||||
"defaultProject": "paperless-ui"
|
||||
}
|
||||
"$schema": "./node_modules/@angular/cli/lib/config/schema.json",
|
||||
"version": 1,
|
||||
"newProjectRoot": "projects",
|
||||
"projects": {
|
||||
"paperless-ui": {
|
||||
"projectType": "application",
|
||||
"schematics": {
|
||||
"@schematics/angular:component": {
|
||||
"style": "scss"
|
||||
}
|
||||
},
|
||||
"root": "",
|
||||
"sourceRoot": "src",
|
||||
"prefix": "app",
|
||||
"architect": {
|
||||
"build": {
|
||||
"builder": "@angular-devkit/build-angular:browser",
|
||||
"options": {
|
||||
"outputPath": "dist/paperless-ui",
|
||||
"outputHashing": "none",
|
||||
"index": "src/index.html",
|
||||
"main": "src/main.ts",
|
||||
"polyfills": "src/polyfills.ts",
|
||||
"tsConfig": "tsconfig.app.json",
|
||||
"aot": true,
|
||||
"assets": [
|
||||
"src/favicon.ico",
|
||||
"src/assets"
|
||||
],
|
||||
"styles": [
|
||||
"src/styles.scss"
|
||||
],
|
||||
"scripts": []
|
||||
},
|
||||
"configurations": {
|
||||
"production": {
|
||||
"fileReplacements": [
|
||||
{
|
||||
"replace": "src/environments/environment.ts",
|
||||
"with": "src/environments/environment.prod.ts"
|
||||
}
|
||||
],
|
||||
"optimization": true,
|
||||
"outputHashing": "none",
|
||||
"sourceMap": false,
|
||||
"extractCss": true,
|
||||
"namedChunks": false,
|
||||
"extractLicenses": true,
|
||||
"vendorChunk": false,
|
||||
"buildOptimizer": true,
|
||||
"budgets": [
|
||||
{
|
||||
"type": "initial",
|
||||
"maximumWarning": "2mb",
|
||||
"maximumError": "5mb"
|
||||
},
|
||||
{
|
||||
"type": "anyComponentStyle",
|
||||
"maximumWarning": "6kb",
|
||||
"maximumError": "10kb"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"serve": {
|
||||
"builder": "@angular-devkit/build-angular:dev-server",
|
||||
"options": {
|
||||
"browserTarget": "paperless-ui:build"
|
||||
},
|
||||
"configurations": {
|
||||
"production": {
|
||||
"browserTarget": "paperless-ui:build:production"
|
||||
}
|
||||
}
|
||||
},
|
||||
"extract-i18n": {
|
||||
"builder": "@angular-devkit/build-angular:extract-i18n",
|
||||
"options": {
|
||||
"browserTarget": "paperless-ui:build"
|
||||
}
|
||||
},
|
||||
"test": {
|
||||
"builder": "@angular-devkit/build-angular:karma",
|
||||
"options": {
|
||||
"main": "src/test.ts",
|
||||
"polyfills": "src/polyfills.ts",
|
||||
"tsConfig": "tsconfig.spec.json",
|
||||
"karmaConfig": "karma.conf.js",
|
||||
"assets": [
|
||||
"src/favicon.ico",
|
||||
"src/assets"
|
||||
],
|
||||
"styles": [
|
||||
"src/styles.scss"
|
||||
],
|
||||
"scripts": []
|
||||
}
|
||||
},
|
||||
"lint": {
|
||||
"builder": "@angular-devkit/build-angular:tslint",
|
||||
"options": {
|
||||
"tsConfig": [
|
||||
"tsconfig.app.json",
|
||||
"tsconfig.spec.json",
|
||||
"e2e/tsconfig.json"
|
||||
],
|
||||
"exclude": [
|
||||
"**/node_modules/**"
|
||||
]
|
||||
}
|
||||
},
|
||||
"e2e": {
|
||||
"builder": "@angular-devkit/build-angular:protractor",
|
||||
"options": {
|
||||
"protractorConfig": "e2e/protractor.conf.js",
|
||||
"devServerTarget": "paperless-ui:serve"
|
||||
},
|
||||
"configurations": {
|
||||
"production": {
|
||||
"devServerTarget": "paperless-ui:serve:production"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"defaultProject": "paperless-ui"
|
||||
}
|
||||
@@ -3,7 +3,7 @@ import { Component } from '@angular/core';
|
||||
@Component({
|
||||
selector: 'app-root',
|
||||
templateUrl: './app.component.html',
|
||||
styleUrls: ['./app.component.css']
|
||||
styleUrls: ['./app.component.scss']
|
||||
})
|
||||
export class AppComponent {
|
||||
|
||||
|
||||
@@ -23,7 +23,7 @@ import { TagEditDialogComponent } from './components/manage/tag-list/tag-edit-di
|
||||
import { DocumentTypeEditDialogComponent } from './components/manage/document-type-list/document-type-edit-dialog/document-type-edit-dialog.component';
|
||||
import { TagComponent } from './components/common/tag/tag.component';
|
||||
import { SearchComponent } from './components/search/search.component';
|
||||
import { ResultHightlightComponent } from './components/search/result-hightlight/result-hightlight.component';
|
||||
import { ResultHighlightComponent } from './components/search/result-highlight/result-highlight.component';
|
||||
import { PageHeaderComponent } from './components/common/page-header/page-header.component';
|
||||
import { AppFrameComponent } from './components/app-frame/app-frame.component';
|
||||
import { ToastsComponent } from './components/common/toasts/toasts.component';
|
||||
@@ -41,6 +41,10 @@ import { TagsComponent } from './components/common/input/tags/tags.component';
|
||||
import { SortableDirective } from './directives/sortable.directive';
|
||||
import { CookieService } from 'ngx-cookie-service';
|
||||
import { CsrfInterceptor } from './interceptors/csrf.interceptor';
|
||||
import { SavedViewWidgetComponent } from './components/dashboard/widgets/saved-view-widget/saved-view-widget.component';
|
||||
import { StatisticsWidgetComponent } from './components/dashboard/widgets/statistics-widget/statistics-widget.component';
|
||||
import { UploadFileWidgetComponent } from './components/dashboard/widgets/upload-file-widget/upload-file-widget.component';
|
||||
import { WidgetFrameComponent } from './components/dashboard/widgets/widget-frame/widget-frame.component';
|
||||
|
||||
@NgModule({
|
||||
declarations: [
|
||||
@@ -61,7 +65,7 @@ import { CsrfInterceptor } from './interceptors/csrf.interceptor';
|
||||
DocumentTypeEditDialogComponent,
|
||||
TagComponent,
|
||||
SearchComponent,
|
||||
ResultHightlightComponent,
|
||||
ResultHighlightComponent,
|
||||
PageHeaderComponent,
|
||||
AppFrameComponent,
|
||||
ToastsComponent,
|
||||
@@ -74,7 +78,11 @@ import { CsrfInterceptor } from './interceptors/csrf.interceptor';
|
||||
SaveViewConfigDialogComponent,
|
||||
DateTimeComponent,
|
||||
TagsComponent,
|
||||
SortableDirective
|
||||
SortableDirective,
|
||||
SavedViewWidgetComponent,
|
||||
StatisticsWidgetComponent,
|
||||
UploadFileWidgetComponent,
|
||||
WidgetFrameComponent
|
||||
],
|
||||
imports: [
|
||||
BrowserModule,
|
||||
|
||||
@@ -1,32 +1,26 @@
|
||||
<nav class="navbar navbar-dark sticky-top bg-dark flex-md-nowrap p-0 shadow">
|
||||
<span class="navbar-brand col-md-3 col-lg-2 mr-0 px-3" href="#">Paperless-ng</span>
|
||||
<nav class="navbar navbar-dark sticky-top bg-primary flex-md-nowrap p-0 shadow">
|
||||
<span class="navbar-brand col-md-3 col-lg-2 mr-0 px-3" href="#">
|
||||
<img src="assets/logo-dark-notext.svg" height="18px" class="mr-2">
|
||||
Paperless-ng
|
||||
</span>
|
||||
<button class="navbar-toggler position-absolute d-md-none collapsed" type="button" data-toggle="collapse"
|
||||
data-target="#sidebarMenu" aria-controls="sidebarMenu" aria-expanded="false" aria-label="Toggle navigation">
|
||||
data-target="#sidebarMenu" aria-controls="sidebarMenu" aria-expanded="false" aria-label="Toggle navigation"
|
||||
(click)="isMenuCollapsed = !isMenuCollapsed">
|
||||
<span class="navbar-toggler-icon"></span>
|
||||
</button>
|
||||
<form (ngSubmit)="search()" class="w-100">
|
||||
<form (ngSubmit)="search()" class="w-100 m-1">
|
||||
<input class="form-control form-control-dark" type="text" placeholder="Search" aria-label="Search"
|
||||
[formControl]="searchField" [ngbTypeahead]="searchAutoComplete" (selectItem)="itemSelected($event)">
|
||||
</form>
|
||||
<ul class="navbar-nav px-3">
|
||||
<li class="nav-item text-nowrap">
|
||||
<a class="nav-link" href="accounts/logout/">
|
||||
<svg class="buttonicon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#door-closed"/>
|
||||
</svg>
|
||||
Logout
|
||||
</a>
|
||||
</li>
|
||||
</ul>
|
||||
</nav>
|
||||
|
||||
<div class="container-fluid">
|
||||
<div class="row">
|
||||
<nav id="sidebarMenu" class="col-md-3 col-lg-2 d-md-block bg-light sidebar collapse">
|
||||
<nav id="sidebarMenu" class="col-md-3 col-lg-2 d-md-block bg-light sidebar collapse" [ngbCollapse]="isMenuCollapsed">
|
||||
<div class="sidebar-sticky pt-3">
|
||||
<ul class="nav flex-column">
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="dashboard" routerLinkActive="active">
|
||||
<a class="nav-link" routerLink="dashboard" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#house"/>
|
||||
</svg>
|
||||
@@ -34,7 +28,7 @@
|
||||
</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="documents" routerLinkActive="active" [routerLinkActiveOptions]="{exact: true}">
|
||||
<a class="nav-link" routerLink="documents" routerLinkActive="active" [routerLinkActiveOptions]="{exact: true}" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#files"/>
|
||||
</svg>
|
||||
@@ -48,7 +42,7 @@
|
||||
</h6>
|
||||
<ul class="nav flex-column mb-2">
|
||||
<li class="nav-item w-100" *ngFor='let config of viewConfigService.getSideBarConfigs()'>
|
||||
<a class="nav-link text-truncate" routerLink="view/{{config.id}}" routerLinkActive="active">
|
||||
<a class="nav-link text-truncate" routerLink="view/{{config.id}}" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#funnel"/>
|
||||
</svg>
|
||||
@@ -62,7 +56,7 @@
|
||||
</h6>
|
||||
<ul class="nav flex-column mb-2">
|
||||
<li class="nav-item w-100" *ngFor='let d of openDocuments'>
|
||||
<a class="nav-link text-truncate" routerLink="documents/{{d.id}}" routerLinkActive="active">
|
||||
<a class="nav-link text-truncate" routerLink="documents/{{d.id}}" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#file-text"/>
|
||||
</svg>
|
||||
@@ -84,7 +78,7 @@
|
||||
</h6>
|
||||
<ul class="nav flex-column mb-2">
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="correspondents" routerLinkActive="active">
|
||||
<a class="nav-link" routerLink="correspondents" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#person"/>
|
||||
</svg>
|
||||
@@ -92,7 +86,7 @@
|
||||
</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="tags" routerLinkActive="active">
|
||||
<a class="nav-link" routerLink="tags" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#tags"/>
|
||||
</svg>
|
||||
@@ -100,7 +94,7 @@
|
||||
</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="documenttypes" routerLinkActive="active">
|
||||
<a class="nav-link" routerLink="documenttypes" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#hash"/>
|
||||
</svg>
|
||||
@@ -108,7 +102,7 @@
|
||||
</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="logs" routerLinkActive="active">
|
||||
<a class="nav-link" routerLink="logs" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#text-left"/>
|
||||
</svg>
|
||||
@@ -116,7 +110,7 @@
|
||||
</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" routerLink="settings" routerLinkActive="active">
|
||||
<a class="nav-link" routerLink="settings" routerLinkActive="active" (click)="closeMenu()">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#gear"/>
|
||||
</svg>
|
||||
@@ -150,7 +144,15 @@
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#link"/>
|
||||
</svg>
|
||||
Github
|
||||
GitHub
|
||||
</a>
|
||||
</li>
|
||||
<li class="nav-item">
|
||||
<a class="nav-link" href="accounts/logout/">
|
||||
<svg class="sidebaricon" fill="currentColor">
|
||||
<use xlink:href="assets/bootstrap-icons.svg#door-open"/>
|
||||
</svg>
|
||||
Logout
|
||||
</a>
|
||||
</li>
|
||||
</ul>
|
||||
@@ -161,4 +163,4 @@
|
||||
<router-outlet></router-outlet>
|
||||
</main>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -1,4 +1,6 @@
|
||||
|
||||
@import "/src/theme";
|
||||
|
||||
/*
|
||||
* Sidebar
|
||||
*/
|
||||
@@ -15,14 +17,15 @@
|
||||
|
||||
@media (max-width: 767.98px) {
|
||||
.sidebar {
|
||||
top: 5rem;
|
||||
top: 3rem;
|
||||
}
|
||||
}
|
||||
|
||||
.sidebar-sticky {
|
||||
position: relative;
|
||||
top: 0;
|
||||
height: calc(100vh - 48px);
|
||||
/* height: calc(100vh - 48px); */
|
||||
height: 100%;
|
||||
padding-top: .5rem;
|
||||
overflow-x: hidden;
|
||||
overflow-y: auto; /* Scrollable contents if viewport is shorter than content. */
|
||||
@@ -46,7 +49,8 @@
|
||||
}
|
||||
|
||||
.sidebar .nav-link.active {
|
||||
color: #007bff;
|
||||
color: $primary;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
.sidebar .nav-link:hover .sidebaricon,
|
||||
@@ -12,7 +12,7 @@ import { DocumentDetailComponent } from '../document-detail/document-detail.comp
|
||||
@Component({
|
||||
selector: 'app-app-frame',
|
||||
templateUrl: './app-frame.component.html',
|
||||
styleUrls: ['./app-frame.component.css']
|
||||
styleUrls: ['./app-frame.component.scss']
|
||||
})
|
||||
export class AppFrameComponent implements OnInit, OnDestroy {
|
||||
|
||||
@@ -25,6 +25,12 @@ export class AppFrameComponent implements OnInit, OnDestroy {
|
||||
) {
|
||||
}
|
||||
|
||||
isMenuCollapsed: boolean = true
|
||||
|
||||
closeMenu() {
|
||||
this.isMenuCollapsed = true
|
||||
}
|
||||
|
||||
searchField = new FormControl('')
|
||||
|
||||
openDocuments: PaperlessDocument[] = []
|
||||
@@ -61,10 +67,12 @@ export class AppFrameComponent implements OnInit, OnDestroy {
|
||||
}
|
||||
|
||||
search() {
|
||||
this.closeMenu()
|
||||
this.router.navigate(['search'], {queryParams: {query: this.searchField.value}})
|
||||
}
|
||||
|
||||
closeAll() {
|
||||
this.closeMenu()
|
||||
this.openDocumentsService.closeAll()
|
||||
|
||||
// TODO: is there a better way to do this?
|
||||
@@ -82,7 +90,9 @@ export class AppFrameComponent implements OnInit, OnDestroy {
|
||||
}
|
||||
|
||||
ngOnDestroy() {
|
||||
this.openDocumentsSubscription.unsubscribe()
|
||||
if (this.openDocumentsSubscription) {
|
||||
this.openDocumentsSubscription.unsubscribe()
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -4,7 +4,7 @@ import { NgbActiveModal } from '@ng-bootstrap/ng-bootstrap';
|
||||
@Component({
|
||||
selector: 'app-delete-dialog',
|
||||
templateUrl: './delete-dialog.component.html',
|
||||
styleUrls: ['./delete-dialog.component.css']
|
||||
styleUrls: ['./delete-dialog.component.scss']
|
||||
})
|
||||
export class DeleteDialogComponent implements OnInit {
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
<div class="form-group form-check">
|
||||
<input type="checkbox" class="form-check-input" [id]="inputId" [(ngModel)]="value" (change)="onChange(value)" (blur)="onTouched()" [disabled]="disabled">
|
||||
<label class="form-check-label" [for]="inputId">{{title}}</label>
|
||||
<div class="form-group custom-control custom-checkbox">
|
||||
<input type="checkbox" class="custom-control-input" [id]="inputId" [(ngModel)]="value" (change)="onChange(value)" (blur)="onTouched()" [disabled]="disabled">
|
||||
<label class="custom-control-label" [for]="inputId">{{title}}</label>
|
||||
<small *ngIf="hint" class="form-text text-muted">{{hint}}</small>
|
||||
</div>
|
||||
@@ -11,7 +11,7 @@ import { AbstractInputComponent } from '../abstract-input';
|
||||
}],
|
||||
selector: 'app-input-check',
|
||||
templateUrl: './check.component.html',
|
||||
styleUrls: ['./check.component.css']
|
||||
styleUrls: ['./check.component.scss']
|
||||
})
|
||||
export class CheckComponent extends AbstractInputComponent<boolean> {
|
||||
|
||||
|
||||
@@ -11,7 +11,7 @@ import { AbstractInputComponent } from '../abstract-input';
|
||||
}],
|
||||
selector: 'app-input-date-time',
|
||||
templateUrl: './date-time.component.html',
|
||||
styleUrls: ['./date-time.component.css']
|
||||
styleUrls: ['./date-time.component.scss']
|
||||
})
|
||||
export class DateTimeComponent implements OnInit,ControlValueAccessor {
|
||||
|
||||
|
||||
@@ -10,7 +10,7 @@ import { AbstractInputComponent } from '../abstract-input';
|
||||
}],
|
||||
selector: 'app-input-select',
|
||||
templateUrl: './select.component.html',
|
||||
styleUrls: ['./select.component.css']
|
||||
styleUrls: ['./select.component.scss']
|
||||
})
|
||||
export class SelectComponent extends AbstractInputComponent<number> {
|
||||
|
||||
|
||||
@@ -15,7 +15,7 @@ import { TagService } from 'src/app/services/rest/tag.service';
|
||||
}],
|
||||
selector: 'app-input-tags',
|
||||
templateUrl: './tags.component.html',
|
||||
styleUrls: ['./tags.component.css']
|
||||
styleUrls: ['./tags.component.scss']
|
||||
})
|
||||
export class TagsComponent implements OnInit, ControlValueAccessor {
|
||||
|
||||
|
||||
@@ -11,7 +11,7 @@ import { AbstractInputComponent } from '../abstract-input';
|
||||
}],
|
||||
selector: 'app-input-text',
|
||||
templateUrl: './text.component.html',
|
||||
styleUrls: ['./text.component.css']
|
||||
styleUrls: ['./text.component.scss']
|
||||
})
|
||||
export class TextComponent extends AbstractInputComponent<string> {
|
||||
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
<div class="row pt-3 pb-1 mb-3 border-bottom align-items-center" >
|
||||
<div class="col text-truncate">
|
||||
<h1 class="h2 text-truncate" style="line-height: 1.4">{{title}}</h1>
|
||||
<div class="col-md text-truncate">
|
||||
<p class="h2 text-truncate" style="line-height: 1.4">{{title}}</p>
|
||||
<p *ngIf="subTitle" class="h5 text-truncate" style="line-height: 1.4">{{subTitle}}</p>
|
||||
</div>
|
||||
<div class="btn-toolbar col-auto">
|
||||
<ng-content></ng-content>
|
||||
|
||||
@@ -3,7 +3,7 @@ import { Component, Input, OnInit } from '@angular/core';
|
||||
@Component({
|
||||
selector: 'app-page-header',
|
||||
templateUrl: './page-header.component.html',
|
||||
styleUrls: ['./page-header.component.css']
|
||||
styleUrls: ['./page-header.component.scss']
|
||||
})
|
||||
export class PageHeaderComponent implements OnInit {
|
||||
|
||||
@@ -12,6 +12,9 @@ export class PageHeaderComponent implements OnInit {
|
||||
@Input()
|
||||
title: string = ""
|
||||
|
||||
@Input()
|
||||
subTitle: string = ""
|
||||
|
||||
ngOnInit(): void {
|
||||
}
|
||||
|
||||
|
||||
@@ -1,2 +1,2 @@
|
||||
<span *ngIf="!clickable" class="badge" [style.background]="getColour().value" [style.color]="getColour().textColor">{{tag.name}}</span>
|
||||
<a [routerLink]="" *ngIf="clickable" class="badge" [style.background]="getColour().value" [style.color]="getColour().textColor">{{tag.name}}</a>
|
||||
<a [routerLink]="" [title]="linkTitle" *ngIf="clickable" class="badge" [style.background]="getColour().value" [style.color]="getColour().textColor">{{tag.name}}</a>
|
||||
@@ -4,7 +4,7 @@ import { TAG_COLOURS, PaperlessTag } from 'src/app/data/paperless-tag';
|
||||
@Component({
|
||||
selector: 'app-tag',
|
||||
templateUrl: './tag.component.html',
|
||||
styleUrls: ['./tag.component.css']
|
||||
styleUrls: ['./tag.component.scss']
|
||||
})
|
||||
export class TagComponent implements OnInit {
|
||||
|
||||
@@ -14,10 +14,10 @@ export class TagComponent implements OnInit {
|
||||
tag: PaperlessTag
|
||||
|
||||
@Input()
|
||||
clickable: boolean = false
|
||||
linkTitle: string = ""
|
||||
|
||||
@Output()
|
||||
click = new EventEmitter()
|
||||
@Input()
|
||||
clickable: boolean = false
|
||||
|
||||
ngOnInit(): void {
|
||||
}
|
||||
|
||||
@@ -5,7 +5,7 @@ import { Toast, ToastService } from 'src/app/services/toast.service';
|
||||
@Component({
|
||||
selector: 'app-toasts',
|
||||
templateUrl: './toasts.component.html',
|
||||
styleUrls: ['./toasts.component.css']
|
||||
styleUrls: ['./toasts.component.scss']
|
||||
})
|
||||
export class ToastsComponent implements OnInit, OnDestroy {
|
||||
|
||||
|
||||
@@ -1,50 +1,25 @@
|
||||
|
||||
<app-page-header title="Dashboard">
|
||||
<app-page-header title="Dashboard" subTitle="Welcome to paperless-ng!">
|
||||
<img src="assets/logo.svg" height="80" class="m-2 d-none d-md-block">
|
||||
</app-page-header>
|
||||
|
||||
<p>Welcome to paperless-ng!</p>
|
||||
|
||||
<div class='row'>
|
||||
<div class="col-lg">
|
||||
<ng-container *ngFor="let v of savedDashboardViews">
|
||||
<h4>{{v.viewConfig.title}}</h4>
|
||||
<div class="col-lg-8">
|
||||
<app-widget-frame title="Saved views" *ngIf="savedViews.length == 0">
|
||||
<p class="card-text">This space is reserved to display your saved views. Go to your documents and save a view
|
||||
to have it displayed
|
||||
here!</p>
|
||||
</app-widget-frame>
|
||||
|
||||
<table class="table table-sm table-hover table-borderless">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Created</th>
|
||||
<th scope="col">Title</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr *ngFor="let doc of v.documents" routerLink="/documents/{{doc.id}}">
|
||||
<td>{{doc.created | date}}</td>
|
||||
<td>{{doc.title}}<app-tag [tag]="t" *ngFor="let t of doc.tags" class="ml-1"></app-tag>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
</ng-container>
|
||||
<ng-container *ngIf="savedDashboardViews.length == 0">
|
||||
<h4>Saved views</h4>
|
||||
<p>This space is reserved to display your saved views. Go to your documents and save a view to have it displayed here!</p>
|
||||
<ng-container *ngFor="let v of savedViews">
|
||||
<app-saved-view-widget [savedView]="v"></app-saved-view-widget>
|
||||
</ng-container>
|
||||
|
||||
</div>
|
||||
<div class="col-lg">
|
||||
<h4>Statistics</h4>
|
||||
<p>Documents in inbox: {{statistics.documents_inbox}}</p>
|
||||
<p>Total documents: {{statistics.documents_total}}</p>
|
||||
<h4>Upload new Document</h4>
|
||||
<form>
|
||||
<ngx-file-drop
|
||||
dropZoneLabel="Drop documents here"
|
||||
(onFileDrop)="dropped($event)"
|
||||
(onFileOver)="fileOver($event)"
|
||||
(onFileLeave)="fileLeave($event)"
|
||||
dropZoneClassName="bg-light mt-4 card">
|
||||
<div class="col-lg-4">
|
||||
|
||||
<app-statistics-widget></app-statistics-widget>
|
||||
|
||||
<app-upload-file-widget></app-upload-file-widget>
|
||||
|
||||
</ngx-file-drop>
|
||||
</form>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
@@ -1,71 +1,22 @@
|
||||
import { HttpClient } from '@angular/common/http';
|
||||
import { Component, OnInit } from '@angular/core';
|
||||
import { FileSystemFileEntry, NgxFileDropEntry } from 'ngx-file-drop';
|
||||
import { Observable } from 'rxjs';
|
||||
import { DocumentService } from 'src/app/services/rest/document.service';
|
||||
import { SavedViewConfigService } from 'src/app/services/saved-view-config.service';
|
||||
import { Toast, ToastService } from 'src/app/services/toast.service';
|
||||
import { environment } from 'src/environments/environment';
|
||||
|
||||
export interface Statistics {
|
||||
documents_total?: number
|
||||
documents_inbox?: number
|
||||
}
|
||||
|
||||
@Component({
|
||||
selector: 'app-dashboard',
|
||||
templateUrl: './dashboard.component.html',
|
||||
styleUrls: ['./dashboard.component.css']
|
||||
styleUrls: ['./dashboard.component.scss']
|
||||
})
|
||||
export class DashboardComponent implements OnInit {
|
||||
|
||||
constructor(private documentService: DocumentService, private toastService: ToastService,
|
||||
public savedViewConfigService: SavedViewConfigService, private http: HttpClient) { }
|
||||
constructor(
|
||||
public savedViewConfigService: SavedViewConfigService) { }
|
||||
|
||||
|
||||
savedDashboardViews = []
|
||||
statistics: Statistics = {}
|
||||
savedViews = []
|
||||
|
||||
ngOnInit(): void {
|
||||
this.savedViewConfigService.getDashboardConfigs().forEach(config => {
|
||||
this.documentService.list(1,10,config.sortField,config.sortDirection,config.filterRules).subscribe(result => {
|
||||
this.savedDashboardViews.push({viewConfig: config, documents: result.results})
|
||||
})
|
||||
})
|
||||
this.getStatistics().subscribe(statistics => {
|
||||
this.statistics = statistics
|
||||
})
|
||||
this.savedViews = this.savedViewConfigService.getDashboardConfigs()
|
||||
}
|
||||
|
||||
getStatistics(): Observable<Statistics> {
|
||||
return this.http.get(`${environment.apiBaseUrl}statistics/`)
|
||||
}
|
||||
|
||||
|
||||
public fileOver(event){
|
||||
console.log(event);
|
||||
}
|
||||
|
||||
public fileLeave(event){
|
||||
console.log(event);
|
||||
}
|
||||
|
||||
public dropped(files: NgxFileDropEntry[]) {
|
||||
for (const droppedFile of files) {
|
||||
if (droppedFile.fileEntry.isFile) {
|
||||
const fileEntry = droppedFile.fileEntry as FileSystemFileEntry;
|
||||
console.log(fileEntry)
|
||||
fileEntry.file((file: File) => {
|
||||
console.log(file)
|
||||
const formData = new FormData()
|
||||
formData.append('document', file, file.name)
|
||||
this.documentService.uploadDocument(formData).subscribe(result => {
|
||||
this.toastService.showToast(Toast.make("Information", "The document has been uploaded and will be processed by the consumer shortly."))
|
||||
}, error => {
|
||||
this.toastService.showToast(Toast.makeError("An error has occured while uploading the document. Sorry!"))
|
||||
})
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -0,0 +1,21 @@
|
||||
<app-widget-frame [title]="savedView.title">
|
||||
|
||||
<a header-buttons [routerLink]="" (click)="showAll()">Show all</a>
|
||||
|
||||
|
||||
<table content class="table table-sm table-hover table-borderless">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Created</th>
|
||||
<th scope="col">Title</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr *ngFor="let doc of documents" routerLink="/documents/{{doc.id}}">
|
||||
<td>{{doc.created | date}}</td>
|
||||
<td>{{doc.title}}<app-tag [tag]="t" *ngFor="let t of doc.tags$ | async" class="ml-1"></app-tag>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
</app-widget-frame>
|
||||
@@ -0,0 +1,25 @@
|
||||
import { ComponentFixture, TestBed } from '@angular/core/testing';
|
||||
|
||||
import { SavedViewWidgetComponent } from './saved-view-widget.component';
|
||||
|
||||
describe('SavedViewWidgetComponent', () => {
|
||||
let component: SavedViewWidgetComponent;
|
||||
let fixture: ComponentFixture<SavedViewWidgetComponent>;
|
||||
|
||||
beforeEach(async () => {
|
||||
await TestBed.configureTestingModule({
|
||||
declarations: [ SavedViewWidgetComponent ]
|
||||
})
|
||||
.compileComponents();
|
||||
});
|
||||
|
||||
beforeEach(() => {
|
||||
fixture = TestBed.createComponent(SavedViewWidgetComponent);
|
||||
component = fixture.componentInstance;
|
||||
fixture.detectChanges();
|
||||
});
|
||||
|
||||
it('should create', () => {
|
||||
expect(component).toBeTruthy();
|
||||
});
|
||||
});
|
||||
@@ -0,0 +1,36 @@
|
||||
import { Component, Input, OnInit } from '@angular/core';
|
||||
import { Router } from '@angular/router';
|
||||
import { PaperlessDocument } from 'src/app/data/paperless-document';
|
||||
import { SavedViewConfig } from 'src/app/data/saved-view-config';
|
||||
import { DocumentListViewService } from 'src/app/services/document-list-view.service';
|
||||
import { DocumentService } from 'src/app/services/rest/document.service';
|
||||
|
||||
@Component({
|
||||
selector: 'app-saved-view-widget',
|
||||
templateUrl: './saved-view-widget.component.html',
|
||||
styleUrls: ['./saved-view-widget.component.scss']
|
||||
})
|
||||
export class SavedViewWidgetComponent implements OnInit {
|
||||
|
||||
constructor(
|
||||
private documentService: DocumentService,
|
||||
private router: Router,
|
||||
private list: DocumentListViewService) { }
|
||||
|
||||
@Input()
|
||||
savedView: SavedViewConfig
|
||||
|
||||
documents: PaperlessDocument[] = []
|
||||
|
||||
ngOnInit(): void {
|
||||
this.documentService.list(1,10,this.savedView.sortField,this.savedView.sortDirection,this.savedView.filterRules).subscribe(result => {
|
||||
this.documents = result.results
|
||||
})
|
||||
}
|
||||
|
||||
showAll() {
|
||||
this.list.load(this.savedView)
|
||||
this.router.navigate(["documents"])
|
||||
}
|
||||
|
||||
}
|
||||
@@ -0,0 +1,6 @@
|
||||
<app-widget-frame title="Statistics">
|
||||
<ng-container content>
|
||||
<p class="card-text">Documents in inbox: {{statistics.documents_inbox}}</p>
|
||||
<p class="card-text">Total documents: {{statistics.documents_total}}</p>
|
||||
</ng-container>
|
||||
</app-widget-frame>
|
||||
@@ -1,20 +1,20 @@
|
||||
import { ComponentFixture, TestBed } from '@angular/core/testing';
|
||||
|
||||
import { ResultHightlightComponent } from './result-hightlight.component';
|
||||
import { StatisticsWidgetComponent } from './statistics-widget.component';
|
||||
|
||||
describe('ResultHightlightComponent', () => {
|
||||
let component: ResultHightlightComponent;
|
||||
let fixture: ComponentFixture<ResultHightlightComponent>;
|
||||
describe('StatisticsWidgetComponent', () => {
|
||||
let component: StatisticsWidgetComponent;
|
||||
let fixture: ComponentFixture<StatisticsWidgetComponent>;
|
||||
|
||||
beforeEach(async () => {
|
||||
await TestBed.configureTestingModule({
|
||||
declarations: [ ResultHightlightComponent ]
|
||||
declarations: [ StatisticsWidgetComponent ]
|
||||
})
|
||||
.compileComponents();
|
||||
});
|
||||
|
||||
beforeEach(() => {
|
||||
fixture = TestBed.createComponent(ResultHightlightComponent);
|
||||
fixture = TestBed.createComponent(StatisticsWidgetComponent);
|
||||
component = fixture.componentInstance;
|
||||
fixture.detectChanges();
|
||||
});
|
||||
@@ -0,0 +1,33 @@
|
||||
import { HttpClient } from '@angular/common/http';
|
||||
import { Component, OnInit } from '@angular/core';
|
||||
import { Observable } from 'rxjs';
|
||||
import { environment } from 'src/environments/environment';
|
||||
|
||||
export interface Statistics {
|
||||
documents_total?: number
|
||||
documents_inbox?: number
|
||||
}
|
||||
|
||||
|
||||
@Component({
|
||||
selector: 'app-statistics-widget',
|
||||
templateUrl: './statistics-widget.component.html',
|
||||
styleUrls: ['./statistics-widget.component.scss']
|
||||
})
|
||||
export class StatisticsWidgetComponent implements OnInit {
|
||||
|
||||
constructor(private http: HttpClient) { }
|
||||
|
||||
statistics: Statistics = {}
|
||||
|
||||
getStatistics(): Observable<Statistics> {
|
||||
return this.http.get(`${environment.apiBaseUrl}statistics/`)
|
||||
}
|
||||
|
||||
ngOnInit(): void {
|
||||
this.getStatistics().subscribe(statistics => {
|
||||
this.statistics = statistics
|
||||
})
|
||||
}
|
||||
|
||||
}
|
||||
@@ -0,0 +1,15 @@
|
||||
<app-widget-frame title="Upload new documents">
|
||||
|
||||
<form content>
|
||||
<ngx-file-drop
|
||||
dropZoneLabel="Drop documents here or" (onFileDrop)="dropped($event)"
|
||||
(onFileOver)="fileOver($event)" (onFileLeave)="fileLeave($event)"
|
||||
dropZoneClassName="bg-light card"
|
||||
multiple="true"
|
||||
contentClassName="justify-content-center d-flex align-items-center p-5"
|
||||
[showBrowseBtn]=true
|
||||
browseBtnClassName="btn btn-sm btn-outline-primary ml-2">
|
||||
|
||||
</ngx-file-drop>
|
||||
</form>
|
||||
</app-widget-frame>
|
||||
@@ -0,0 +1,25 @@
|
||||
import { ComponentFixture, TestBed } from '@angular/core/testing';
|
||||
|
||||
import { UploadFileWidgetComponent } from './upload-file-widget.component';
|
||||
|
||||
describe('UploadFileWidgetComponent', () => {
|
||||
let component: UploadFileWidgetComponent;
|
||||
let fixture: ComponentFixture<UploadFileWidgetComponent>;
|
||||
|
||||
beforeEach(async () => {
|
||||
await TestBed.configureTestingModule({
|
||||
declarations: [ UploadFileWidgetComponent ]
|
||||
})
|
||||
.compileComponents();
|
||||
});
|
||||
|
||||
beforeEach(() => {
|
||||
fixture = TestBed.createComponent(UploadFileWidgetComponent);
|
||||
component = fixture.componentInstance;
|
||||
fixture.detectChanges();
|
||||
});
|
||||
|
||||
it('should create', () => {
|
||||
expect(component).toBeTruthy();
|
||||
});
|
||||
});
|
||||
@@ -0,0 +1,44 @@
|
||||
import { Component, OnInit } from '@angular/core';
|
||||
import { FileSystemFileEntry, NgxFileDropEntry } from 'ngx-file-drop';
|
||||
import { DocumentService } from 'src/app/services/rest/document.service';
|
||||
import { Toast, ToastService } from 'src/app/services/toast.service';
|
||||
|
||||
@Component({
|
||||
selector: 'app-upload-file-widget',
|
||||
templateUrl: './upload-file-widget.component.html',
|
||||
styleUrls: ['./upload-file-widget.component.scss']
|
||||
})
|
||||
export class UploadFileWidgetComponent implements OnInit {
|
||||
|
||||
constructor(private documentService: DocumentService, private toastService: ToastService) { }
|
||||
|
||||
ngOnInit(): void {
|
||||
}
|
||||
|
||||
public fileOver(event){
|
||||
console.log(event);
|
||||
}
|
||||
|
||||
public fileLeave(event){
|
||||
console.log(event);
|
||||
}
|
||||
|
||||
public dropped(files: NgxFileDropEntry[]) {
|
||||
for (const droppedFile of files) {
|
||||
if (droppedFile.fileEntry.isFile) {
|
||||
const fileEntry = droppedFile.fileEntry as FileSystemFileEntry;
|
||||
console.log(fileEntry)
|
||||
fileEntry.file((file: File) => {
|
||||
console.log(file)
|
||||
const formData = new FormData()
|
||||
formData.append('document', file, file.name)
|
||||
this.documentService.uploadDocument(formData).subscribe(result => {
|
||||
this.toastService.showToast(Toast.make("Information", "The document has been uploaded and will be processed by the consumer shortly."))
|
||||
}, error => {
|
||||
this.toastService.showToast(Toast.makeError("An error has occured while uploading the document. Sorry!"))
|
||||
})
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||