Compare commits
245 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
5009bd022f | ||
|
|
73163d893f | ||
|
|
506af7c9c2 | ||
|
|
c90ed2da1d | ||
|
|
cebb8b9fa2 | ||
|
|
46aca10a72 | ||
|
|
6384c698ad | ||
|
|
abf01be889 | ||
|
|
1e4928d2a0 | ||
|
|
503be90932 | ||
|
|
b5d6a82cc3 | ||
|
|
c073ba5272 | ||
|
|
d1e317ce21 | ||
|
|
d4abeafb34 | ||
|
|
4d96551619 | ||
|
|
178361b247 | ||
|
|
40f8ba23a4 | ||
|
|
bef2d94374 | ||
|
|
f39c7654a0 | ||
|
|
e9fff764cb | ||
|
|
87e466c47c | ||
|
|
bd0b593c4a | ||
|
|
7a8142df2b | ||
|
|
bbe3084eda | ||
|
|
89d42bd078 | ||
|
|
93efaf7a38 | ||
|
|
398575c70c | ||
|
|
4e21fa4830 | ||
|
|
d2d2d9edaf | ||
|
|
771c8bbbe4 | ||
|
|
20eeda19b8 | ||
|
|
5e40227bc3 | ||
|
|
5479942fc0 | ||
|
|
ce98019b49 | ||
|
|
9470154df2 | ||
|
|
5c59120c57 | ||
|
|
88736ff867 | ||
|
|
fd5b831979 | ||
|
|
3fcd1e2d7e | ||
|
|
2c81648d59 | ||
|
|
cd92c005e3 | ||
|
|
31c8cf020e | ||
|
|
e900a38983 | ||
|
|
7343a07ddd | ||
|
|
e20b4fb905 | ||
|
|
cbbc4d37d0 | ||
|
|
b140935843 | ||
|
|
9faf0a102e | ||
|
|
b747dd58c3 | ||
|
|
09e1b505e1 | ||
|
|
a6babffed8 | ||
|
|
0256e2dfbb | ||
|
|
7afa90b769 | ||
|
|
5796956235 | ||
|
|
3ca215e4dc | ||
|
|
16c4183333 | ||
|
|
6fe37678f2 | ||
|
|
b58188f805 | ||
|
|
f2a42ab6fe | ||
|
|
e236b7bf7b | ||
|
|
35004f434b | ||
|
|
75251ad694 | ||
|
|
870357968a | ||
|
|
a593798b4b | ||
|
|
4f070ba162 | ||
|
|
9517d27f40 | ||
|
|
35bb3dbcc2 | ||
|
|
06117929bb | ||
|
|
d1c8241947 | ||
|
|
4c38b28469 | ||
|
|
ad0f0a0b5d | ||
|
|
83746a9aeb | ||
|
|
6a36a4ec97 | ||
|
|
7e49d047b0 | ||
|
|
68cdeb7b3d | ||
|
|
76293084a4 | ||
|
|
e1cf2117f5 | ||
|
|
7d81de4edf | ||
|
|
37af5992c7 | ||
|
|
af4623e605 | ||
|
|
db8e116681 | ||
|
|
a8616ebfe2 | ||
|
|
a38d3bf7f8 | ||
|
|
1cb5bbd07d | ||
|
|
6edb5b912f | ||
|
|
ec20c7577e | ||
|
|
d6df9b3656 | ||
|
|
80a849fef7 | ||
|
|
bd67b53d50 | ||
|
|
e32ed09da3 | ||
|
|
c5632e5c04 | ||
|
|
4d2b71454d | ||
|
|
5cbb33b02b | ||
|
|
2c55aad6c0 | ||
|
|
1e039dcb32 | ||
|
|
6ca8da4858 | ||
|
|
67b492bcb7 | ||
|
|
360d1e2802 | ||
|
|
1cd76634a3 | ||
|
|
c65c5009e4 | ||
|
|
24fb6cefb9 | ||
|
|
d80e272b75 | ||
|
|
82f05e27c3 | ||
|
|
7a627e4ad8 | ||
|
|
73af9552ec | ||
|
|
e4854f2144 | ||
|
|
6f5c1ac4e1 | ||
|
|
22acc51284 | ||
|
|
a05644fc31 | ||
|
|
d1aa54caa9 | ||
|
|
e293f70a91 | ||
|
|
347986a2b3 | ||
|
|
ede274386b | ||
|
|
3e083354cc | ||
|
|
b2b4f6516a | ||
|
|
2ae702c7bb | ||
|
|
b748420a94 | ||
|
|
8a4546ce0d | ||
|
|
167412a003 | ||
|
|
e8d90b42a1 | ||
|
|
d8c7e9de5f | ||
|
|
2ac1b78a2c | ||
|
|
e8e38befb7 | ||
|
|
b30629dd60 | ||
|
|
f66d7e1c2d | ||
|
|
8417ac7eeb | ||
|
|
6342225b22 | ||
|
|
4460fb7004 | ||
|
|
6f635c74fc | ||
|
|
c82d45689c | ||
|
|
02e0543a02 | ||
|
|
fde0276d65 | ||
|
|
3d6289e4e1 | ||
|
|
5e55b971a8 | ||
|
|
0a43b84a96 | ||
|
|
dc74cc2db5 | ||
|
|
fc00a09318 | ||
|
|
19cf9d0b9a | ||
|
|
f81780cf88 | ||
|
|
c3a55c91dc | ||
|
|
482f02fbaa | ||
|
|
6bf7429ef6 | ||
|
|
4198de604f | ||
|
|
8c06dc2dd1 | ||
|
|
13b4610c1d | ||
|
|
0090128249 | ||
|
|
3153bbd6a8 | ||
|
|
7b1812a9be | ||
|
|
c647daace2 | ||
|
|
70dceb3b37 | ||
|
|
72b1ce5fe6 | ||
|
|
731942d855 | ||
|
|
058dad7ba7 | ||
|
|
fe43e5a717 | ||
|
|
34bab04310 | ||
|
|
18f7c4f31f | ||
|
|
3477b96d87 | ||
|
|
ac850b64aa | ||
|
|
279e421ad5 | ||
|
|
22c8049bed | ||
|
|
3f1392769d | ||
|
|
da71eab0ae | ||
|
|
2e0e6bb8d2 | ||
|
|
1f145c6cba | ||
|
|
c4d48181ee | ||
|
|
0c4ecad4a7 | ||
|
|
d25de5592a | ||
|
|
88fc35d8ea | ||
|
|
02730be871 | ||
|
|
c7876dbbe8 | ||
|
|
85fcb5fedf | ||
|
|
58cbfeb72a | ||
|
|
b2b6cbe9c8 | ||
|
|
4c05a511c2 | ||
|
|
b5bef13b46 | ||
|
|
bb47dc5e06 | ||
|
|
511f154e16 | ||
|
|
10ae2207df | ||
|
|
71df99ffb6 | ||
|
|
5eb26102d4 | ||
|
|
a7fa82a83f | ||
|
|
6ce27d225d | ||
|
|
819a0e1f57 | ||
|
|
702a60b7e7 | ||
|
|
057d5f149f | ||
|
|
d047dafd23 | ||
|
|
b449a7f6e2 | ||
|
|
f302874ae8 | ||
|
|
6af58203dd | ||
|
|
fa4924d5ba | ||
|
|
5b88ebf0e7 | ||
|
|
a0edc7d54d | ||
|
|
b876a0d0df | ||
|
|
27db4f7e51 | ||
|
|
426919fa9f | ||
|
|
e47c152b81 | ||
|
|
b7cb708053 | ||
|
|
7611c2b3d5 | ||
|
|
5f964830aa | ||
|
|
7ec4f906af | ||
|
|
b5f6c06b8b | ||
|
|
55e81ca4bb | ||
|
|
0f7bfc547a | ||
|
|
9525725c28 | ||
|
|
2a2196fa4d | ||
|
|
237efbcaa0 | ||
|
|
351cd06ef7 | ||
|
|
8b37160953 | ||
|
|
db64478d9f | ||
|
|
8bc2dfe4c6 | ||
|
|
3a427c9130 | ||
|
|
01da48693e | ||
|
|
499abd38f6 | ||
|
|
ca2a556259 | ||
|
|
7699a881d0 | ||
|
|
425f87618a | ||
|
|
701ef2f919 | ||
|
|
ce5c5f0837 | ||
|
|
75884285cf | ||
|
|
d7d9c1edc0 | ||
|
|
92db3fec2e | ||
|
|
69ea039e31 | ||
|
|
f640bef5fc | ||
|
|
88f9fb6fc8 | ||
|
|
855e9f6c83 | ||
|
|
e63e9e389e | ||
|
|
c646cd4977 | ||
|
|
6b53c0dc27 | ||
|
|
afb4e317f0 | ||
|
|
a698c69b4d | ||
|
|
4121876116 | ||
|
|
060d3011f7 | ||
|
|
1f0fea2937 | ||
|
|
92e178cc59 | ||
|
|
dc222cefd4 | ||
|
|
0defa9d0ba | ||
|
|
e3edb02090 | ||
|
|
a32625ca04 | ||
|
|
3c08fa9b33 | ||
|
|
e6526d3fd4 | ||
|
|
bee0867a2a | ||
|
|
1711030cb5 | ||
|
|
7b586e6857 | ||
|
|
350d2fb747 | ||
|
|
5b53cc2139 |
1
.gitignore
vendored
@@ -68,6 +68,7 @@ db.sqlite3
|
||||
.idea
|
||||
|
||||
# Other stuff that doesn't belong
|
||||
.virtualenv
|
||||
virtualenv
|
||||
.vagrant
|
||||
docker-compose.yml
|
||||
|
||||
10
.travis.yml
@@ -1,5 +1,9 @@
|
||||
language: python
|
||||
|
||||
before_install:
|
||||
- sudo apt-get update -qq
|
||||
- sudo apt-get install -qq libpoppler-cpp-dev unpaper tesseract-ocr tesseract-ocr-eng
|
||||
|
||||
sudo: false
|
||||
|
||||
matrix:
|
||||
@@ -8,8 +12,10 @@ matrix:
|
||||
env: TOXENV=py34
|
||||
- python: 3.5
|
||||
env: TOXENV=py35
|
||||
- python: 3.5
|
||||
env: TOXENV=pep8
|
||||
- python: 3.6
|
||||
env: TOXENV=py36
|
||||
- python: 3.6
|
||||
env: TOXENV=pycodestyle
|
||||
|
||||
install:
|
||||
- pip install --requirement requirements.txt
|
||||
|
||||
72
Dockerfile
@@ -1,46 +1,48 @@
|
||||
FROM python:3.5
|
||||
MAINTAINER Pit Kleyersburg <pitkley@googlemail.com>
|
||||
FROM alpine:3.7
|
||||
|
||||
# Install dependencies
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
sudo \
|
||||
tesseract-ocr tesseract-ocr-eng imagemagick ghostscript unpaper \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install python dependencies
|
||||
RUN mkdir -p /usr/src/paperless
|
||||
WORKDIR /usr/src/paperless
|
||||
COPY requirements.txt /usr/src/paperless/
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
LABEL maintainer="The Paperless Project https://github.com/danielquinn/paperless" \
|
||||
contributors="Guy Addadi <addadi@gmail.com>, Pit Kleyersburg <pitkley@googlemail.com>, \
|
||||
Sven Fischer <git-dev@linux4tw.de>"
|
||||
|
||||
# Copy application
|
||||
RUN mkdir -p /usr/src/paperless/src
|
||||
RUN mkdir -p /usr/src/paperless/data
|
||||
RUN mkdir -p /usr/src/paperless/media
|
||||
COPY requirements.txt /usr/src/paperless/
|
||||
COPY src/ /usr/src/paperless/src/
|
||||
COPY data/ /usr/src/paperless/data/
|
||||
COPY media/ /usr/src/paperless/media/
|
||||
|
||||
# Set consumption directory
|
||||
ENV PAPERLESS_CONSUMPTION_DIR /consume
|
||||
RUN mkdir -p $PAPERLESS_CONSUMPTION_DIR
|
||||
|
||||
# Migrate database
|
||||
WORKDIR /usr/src/paperless/src
|
||||
RUN ./manage.py migrate
|
||||
|
||||
# Create user
|
||||
RUN groupadd -g 1000 paperless \
|
||||
&& useradd -u 1000 -g 1000 -d /usr/src/paperless paperless \
|
||||
&& chown -Rh paperless:paperless /usr/src/paperless
|
||||
|
||||
# Setup entrypoint
|
||||
COPY scripts/docker-entrypoint.sh /sbin/docker-entrypoint.sh
|
||||
RUN chmod 755 /sbin/docker-entrypoint.sh
|
||||
|
||||
# Mount volumes
|
||||
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume"]
|
||||
# Set export and consumption directories
|
||||
ENV PAPERLESS_EXPORT_DIR=/export \
|
||||
PAPERLESS_CONSUMPTION_DIR=/consume
|
||||
|
||||
# Install dependencies
|
||||
RUN apk --no-cache --update add \
|
||||
python3 gnupg libmagic bash \
|
||||
sudo poppler tesseract-ocr imagemagick ghostscript unpaper && \
|
||||
apk --no-cache add --virtual .build-dependencies \
|
||||
python3-dev poppler-dev gcc g++ musl-dev zlib-dev jpeg-dev && \
|
||||
# Install python dependencies
|
||||
python3 -m ensurepip && \
|
||||
rm -r /usr/lib/python*/ensurepip && \
|
||||
cd /usr/src/paperless && \
|
||||
pip3 install --no-cache-dir -r requirements.txt && \
|
||||
# Remove build dependencies
|
||||
apk del .build-dependencies && \
|
||||
# Create the consumption directory
|
||||
mkdir -p $PAPERLESS_CONSUMPTION_DIR && \
|
||||
# Migrate database
|
||||
./src/manage.py migrate && \
|
||||
# Create user
|
||||
addgroup -g 1000 paperless && \
|
||||
adduser -D -u 1000 -G paperless -h /usr/src/paperless paperless && \
|
||||
chown -Rh paperless:paperless /usr/src/paperless && \
|
||||
mkdir -p $PAPERLESS_EXPORT_DIR && \
|
||||
# Setup entrypoint
|
||||
chmod 755 /sbin/docker-entrypoint.sh
|
||||
|
||||
WORKDIR /usr/src/paperless/src
|
||||
# Mount volumes and set Entrypoint
|
||||
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume", "/export"]
|
||||
ENTRYPOINT ["/sbin/docker-entrypoint.sh"]
|
||||
CMD ["--help"]
|
||||
|
||||
|
||||
70
README.md
Normal file
@@ -0,0 +1,70 @@
|
||||
# Paperless
|
||||
|
||||
  
|
||||
|
||||
Index and archive all of your scanned paper documents
|
||||
|
||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||
|
||||
* There's no search feature
|
||||
* It takes up physical space
|
||||
* Backups mean more paper
|
||||
|
||||
In the past few months I've been bitten more than a few times by the problem of not having the right document around. Sometimes I recycled a document I needed (who keeps water bills for two years?) and other times I just lost it... because paper. I wrote this to make my life easier.
|
||||
|
||||
|
||||
## How it Works
|
||||
|
||||
Paperless does not control your scanner, it only helps you deal with what your scanner produces
|
||||
|
||||
1. Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the [scanner recommendations](https://paperless.readthedocs.io/en/latest/scanners.html) page.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push scanned images to a server without you having to do anything. Of course if your scanner doesn't know how to automatically upload the file somewhere, you can always do that manually. Paperless doesn't care how the documents get into its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the file and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
5. Download the PDF you need/want via the web interface and do whatever you like with it. You can even print it and send it as if it's the original. In most cases, no one will care or notice.
|
||||
|
||||
Here's what you get:
|
||||
|
||||
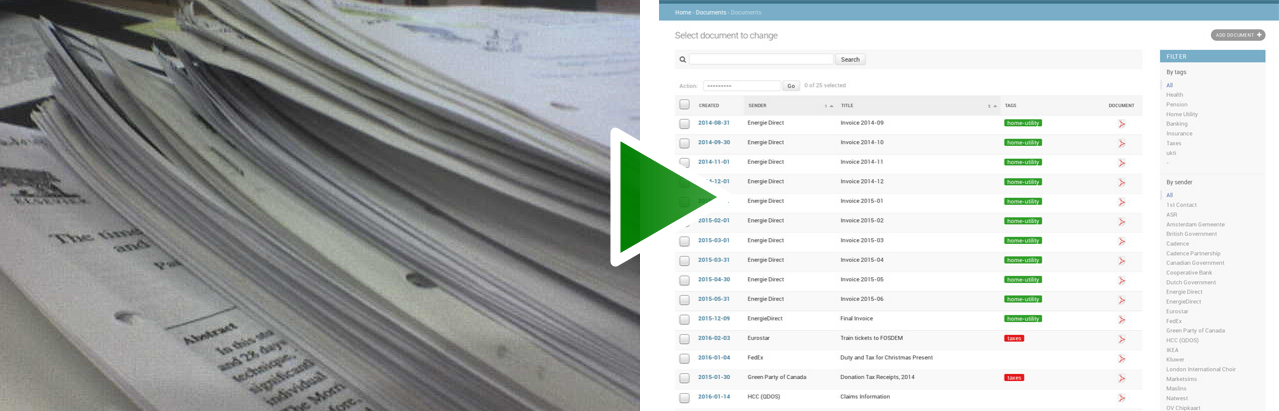
|
||||
|
||||
|
||||
## Documentation
|
||||
|
||||
It's all available on [ReadTheDocs](https://paperless.readthedocs.org/).
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
This is all really a quite simple, shiny, user-friendly wrapper around some very powerful tools.
|
||||
|
||||
* [ImageMagick](http://imagemagick.org/) converts the images between colour and greyscale.
|
||||
* [Tesseract](https://github.com/tesseract-ocr) does the character recognition.
|
||||
* [Unpaper](https://www.flameeyes.eu/projects/unpaper) despeckles and deskews the scanned image.
|
||||
* [GNU Privacy Guard](https://gnupg.org/) is used as the encryption backend.
|
||||
* [Python 3](https://python.org/) is the language of the project.
|
||||
* [Pillow](https://pypi.python.org/pypi/pillowfight/) loads the image data as a python object to be used with PyOCR.
|
||||
* [PyOCR](https://github.com/jflesch/pyocr) is a slick programmatic wrapper around tesseract.
|
||||
* [Django](https://www.djangoproject.com/) is the framework this project is written against.
|
||||
* [Python-GNUPG](http://pythonhosted.org/python-gnupg/) decrypts the PDFs on-the-fly to allow you to download unencrypted files, leaving the encrypted ones on-disk.
|
||||
|
||||
|
||||
## Stability
|
||||
|
||||
This project has been around since 2015, and there's lots of people using it, however it's still under active development (just look at the git commit history) so don't expect it to be 100% stable. You can backup the sqlite3 database, media directory and your configuration file to be on the safe side.
|
||||
|
||||
|
||||
## Similar Projects
|
||||
|
||||
There's another project out there called [Mayan EDMS](https://mayan.readthedocs.org/en/latest/) that has a surprising amount of technical overlap with Paperless. Also based on Django and using a consumer model with Tesseract and Unpaper, Mayan EDMS is *much* more featureful and comes with a slick UI as well, but still in Python 2. It may be that Paperless consumes fewer resources, but to be honest, this is just a guess as I haven't tested this myself. One thing's for certain though, *Paperless* is a **way** better name.
|
||||
|
||||
|
||||
## Important Note
|
||||
|
||||
Document scanners are typically used to scan sensitive documents. Things like your social insurance number, tax records, invoices, etc. While Paperless encrypts the original files via the consumption script, the OCR'd text is *not* encrypted and is therefore stored in the clear (it needs to be searchable, so if someone has ideas on how to do that on encrypted data, I'm all ears). This means that Paperless should never be run on an untrusted host. Instead, I recommend that if you do want to use it, run it locally on a server in your own home.
|
||||
|
||||
|
||||
## Donations
|
||||
|
||||
As with all Free software, the power is less in the finances and more in the collective efforts. I really appreciate every pull request and bug report offered up by Paperless' users, so please keep that stuff coming. If however, you're not one for coding/design/documentation, and would like to contribute financially, I won't say no ;-)
|
||||
|
||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to the [United Nations High Commissioner for Refugees](https://donate.unhcr.org/int-en/general). They're doing important work and they need the money a lot more than I do.
|
||||
140
README.rst
@@ -1,140 +0,0 @@
|
||||
Paperless
|
||||
#########
|
||||
|
||||
|Documentation|
|
||||
|Chat|
|
||||
|Travis|
|
||||
|Dependencies|
|
||||
|
||||
Scan, index, and archive all of your paper documents
|
||||
|
||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||
|
||||
* There's no search feature
|
||||
* It takes up physical space
|
||||
* Backups mean more paper
|
||||
|
||||
In the past few months I've been bitten more than a few times by the problem
|
||||
of not having the right document around. Sometimes I recycled a document I
|
||||
needed (who keeps water bills for two years?) and other times I just lost
|
||||
it... because paper. I wrote this to make my life easier.
|
||||
|
||||
|
||||
How it Works
|
||||
============
|
||||
|
||||
1. Buy a document scanner like `this one`_.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push
|
||||
scanned images to a server without you having to do anything. If your
|
||||
scanner doesn't know how to automatically upload the file somewhere, you can
|
||||
always do that manually. Paperless doesn't care how the documents get into
|
||||
its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the PDF
|
||||
and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
5. Download the PDF you need/want via the web interface and do whatever you
|
||||
like with it. You can even print it and send it as if it's the original.
|
||||
In most cases, no one will care or notice.
|
||||
|
||||
Here's what you get:
|
||||
|
||||
.. image:: docs/_static/screenshot.png
|
||||
:alt: The before and after
|
||||
:target: docs/_static/screenshot.png
|
||||
|
||||
|
||||
Stability
|
||||
=========
|
||||
|
||||
Paperless is still under active development (just look at the git commit
|
||||
history) so don't expect it to be 100% stable. I'm using it for my own
|
||||
documents, but I'm crazy like that. If you use this and it breaks something,
|
||||
you get to keep all the shiny pieces.
|
||||
|
||||
|
||||
Requirements
|
||||
============
|
||||
|
||||
This is all really a quite simple, shiny, user-friendly wrapper around some very
|
||||
powerful tools.
|
||||
|
||||
* `ImageMagick`_ converts the images between colour and greyscale.
|
||||
* `Tesseract`_ does the character recognition.
|
||||
* `Unpaper`_ despeckles and deskews the scanned image.
|
||||
* `GNU Privacy Guard`_ is used as the encryption backend.
|
||||
* `Python 3`_ is the language of the project.
|
||||
|
||||
* `Pillow`_ loads the image data as a python object to be used with PyOCR.
|
||||
* `PyOCR`_ is a slick programmatic wrapper around tesseract.
|
||||
* `Django`_ is the framework this project is written against.
|
||||
* `Python-GNUPG`_ decrypts the PDFs on-the-fly to allow you to download
|
||||
unencrypted files, leaving the encrypted ones on-disk.
|
||||
|
||||
|
||||
Documentation
|
||||
=============
|
||||
|
||||
It's all available on `ReadTheDocs`_.
|
||||
|
||||
|
||||
Similar Projects
|
||||
================
|
||||
|
||||
There's another project out there called `Mayan EDMS`_ that has a surprising
|
||||
amount of technical overlap with Paperless. Also based on Django and using
|
||||
a consumer model with Tesseract and unpaper, Mayan EDMS is *much* more
|
||||
featureful and comes with a slick UI as well. It may be that Paperless is
|
||||
better suited for low-resource environments (like a Rasberry Pi), but to be
|
||||
honest, this is just a guess as I haven't tested this myself. One thing's
|
||||
for certain though, *Paperless* is a **much** better name.
|
||||
|
||||
|
||||
Important Note
|
||||
==============
|
||||
|
||||
Document scanners are typically used to scan sensitive documents. Things like
|
||||
your social insurance number, tax records, invoices, etc. While paperless
|
||||
encrypts the original PDFs via the consumption script, the OCR'd text is *not*
|
||||
encrypted and is therefore stored in the clear (it needs to be searchable, so
|
||||
if someone has ideas on how to do that on encrypted data, I'm all ears). This
|
||||
means that paperless should never be run on an untrusted host. Instead, I
|
||||
recommend that if you do want to use it, run it locally on a server in your own
|
||||
home.
|
||||
|
||||
|
||||
Donations
|
||||
=========
|
||||
|
||||
As with all Free software, the power is less in the finances and more in the
|
||||
collective efforts. I really appreciate every pull request and bug report
|
||||
offered up by Paperless' users, so please keep that stuff coming. If however,
|
||||
you're not one for coding/design/documentation, and would like to contribute
|
||||
financially, I won't say no ;-)
|
||||
|
||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to
|
||||
the `United Nations High Commissioner for Refugees`_. They're doing important
|
||||
work and they need the money a lot more than I do.
|
||||
|
||||
.. _this one: http://www.brother.ca/en-CA/Scanners/11/ProductDetail/ADS1500W?ProductDetail=productdetail
|
||||
.. _ImageMagick: http://imagemagick.org/
|
||||
.. _Tesseract: https://github.com/tesseract-ocr
|
||||
.. _Unpaper: https://www.flameeyes.eu/projects/unpaper
|
||||
.. _GNU Privacy Guard: https://gnupg.org/
|
||||
.. _Python 3: https://python.org/
|
||||
.. _Pillow: https://pypi.python.org/pypi/pillowfight/
|
||||
.. _PyOCR: https://github.com/jflesch/pyocr
|
||||
.. _Django: https://www.djangoproject.com/
|
||||
.. _Python-GNUPG: http://pythonhosted.org/python-gnupg/
|
||||
.. _ReadTheDocs: https://paperless.readthedocs.org/
|
||||
.. _Mayan EDMS: https://mayan.readthedocs.org/en/latest/
|
||||
.. _United Nations High Commissioner for Refugees: https://donate.unhcr.org/int-en/general
|
||||
.. |Documentation| image:: https://readthedocs.org/projects/paperless/badge/?version=latest
|
||||
:alt: Read the documentation at https://paperless.readthedocs.org/
|
||||
:target: https://paperless.readthedocs.org/
|
||||
.. |Chat| image:: https://badges.gitter.im/danielquinn/paperless.svg
|
||||
:alt: Join the chat at https://gitter.im/danielquinn/paperless
|
||||
:target: https://gitter.im/danielquinn/paperless?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge
|
||||
.. |Travis| image:: https://travis-ci.org/danielquinn/paperless.svg?branch=master
|
||||
:target: https://travis-ci.org/danielquinn/paperless
|
||||
.. |Dependencies| image:: https://www.versioneye.com/user/projects/57b33b81d9f1b00016faa500/badge.svg?style=flat-square
|
||||
:target: https://www.versioneye.com/user/projects/57b33b81d9f1b00016faa500
|
||||
5
Vagrantfile
vendored
@@ -12,4 +12,9 @@ Vagrant.configure(VAGRANT_API_VERSION) do |config|
|
||||
|
||||
# Networking details
|
||||
config.vm.network "private_network", ip: "172.28.128.4"
|
||||
|
||||
config.vm.provider "virtualbox" do |vb|
|
||||
# Customize the amount of memory on the VM:
|
||||
vb.memory = "1024"
|
||||
end
|
||||
end
|
||||
|
||||
@@ -2,7 +2,7 @@ version: '2'
|
||||
|
||||
services:
|
||||
webserver:
|
||||
image: pitkley/paperless
|
||||
build: ./
|
||||
ports:
|
||||
# You can adapt the port you want Paperless to listen on by
|
||||
# modifying the part before the `:`.
|
||||
@@ -17,16 +17,16 @@ services:
|
||||
# value with nothing.
|
||||
environment:
|
||||
- PAPERLESS_OCR_LANGUAGES=
|
||||
command: ["runserver", "0.0.0.0:8000"]
|
||||
command: ["runserver", "--insecure", "0.0.0.0:8000"]
|
||||
|
||||
consumer:
|
||||
image: pitkley/paperless
|
||||
build: ./
|
||||
volumes:
|
||||
- data:/usr/src/paperless/data
|
||||
- media:/usr/src/paperless/media
|
||||
# You have to adapt the local path you want the consumption
|
||||
# directory to mount to by modifying the part before the ':'.
|
||||
- /path/to/arbitrary/place:/consume
|
||||
- ./consume:/consume
|
||||
# Likewise, you can add a local path to mount a directory for
|
||||
# exporting. This is not strictly needed for paperless to
|
||||
# function, only if you're exporting your files: uncomment
|
||||
|
||||
@@ -1,118 +1,302 @@
|
||||
Changelog
|
||||
#########
|
||||
|
||||
* 0.3.0
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
* Consumer loop time is now configurable for systems with slow writes. Just
|
||||
set ``PAPERLESS_CONSUMER_LOOP_TIME`` to a number of seconds. The default
|
||||
is 10.
|
||||
* As per `#44`_, we've removed support for ``PAPERLESS_CONVERT``,
|
||||
``PAPERLESS_CONSUME``, and ``PAPERLESS_SECRET``. Please use
|
||||
``PAPERLESS_CONVERT_BINARY``, ``PAPERLESS_CONSUMPTION_DIR``, and
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
1.2.0
|
||||
=====
|
||||
|
||||
* 0.2.0
|
||||
* New Docker image, now based on Alpine, thanks to the efforts of `addadi`_
|
||||
and `Pit`_. This new image is dramatically smaller than the Debian-based
|
||||
one, and it also has `a new home on Docker Hub`_. A proper thank-you to
|
||||
`Pit`_ for hosting the image on his Docker account all this time, but after
|
||||
some discussion, we decided the image needed a more *official-looking* home.
|
||||
* `BastianPoe`_ has added the long-awaited feature to automatically skip the
|
||||
OCR step when the PDF already contains text. This can be overridden by
|
||||
setting ``PAPERLESS_OCR_ALWAYS=YES`` either in your ``paperless.conf`` or
|
||||
in the environment. Note that this also means that Paperless now requires
|
||||
``libpoppler-cpp-dev`` to be installed. **Important**: You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update.
|
||||
* `BastianPoe`_ has also contributed a monumental amount of work (`#291`_) to
|
||||
solving `#158`_: setting the document creation date based on finding a date
|
||||
in the document text.
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#148`_: The database location (sqlite) is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#146`_: Fixed a bug that allowed unauthorised access to the `/fetch` URL.
|
||||
* `#131`_: Document files are now automatically removed from disk when
|
||||
they're deleted in Paperless.
|
||||
* `#121`_: Fixed a bug where Paperless wasn't setting document creation time
|
||||
based on the file naming scheme.
|
||||
* `#81`_: Added a hook to run an arbitrary script after every document is
|
||||
consumed.
|
||||
* `#98`_: Added optional environment variables for ImageMagick so that it
|
||||
doesn't explode when handling Very Large Documents or when it's just
|
||||
running on a low-memory system. Thanks to `Florian Harr`_ for his help on
|
||||
this one.
|
||||
* `#89`_ Ported the auto-tagging code to correspondents as well. Thanks to
|
||||
`Justin Snyman`_ for the pointers in the issue queue.
|
||||
* Added support for guessing the date from the file name along with the
|
||||
correspondent, title, and tags. Thanks to `Tikitu de Jager`_ for his pull
|
||||
request that I took forever to merge and to `Pit`_ for his efforts on the
|
||||
regex front.
|
||||
* `#94`_: Restored support for changing the created date in the UI. Thanks
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
1.1.0
|
||||
=====
|
||||
|
||||
* 0.1.1
|
||||
* Fix for `#283`_, a redirect bug which broke interactions with
|
||||
paperless-desktop. Thanks to `chris-aeviator`_ for reporting it.
|
||||
* Addition of an optional new financial year filter, courtesy of
|
||||
`David Martin`_ `#256`_
|
||||
* Fixed a typo in how thumbnails were named in exports `#285`_, courtesy of
|
||||
`Dan Panzarella`_
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
property (one could quite reasonably scan a document before sending it to
|
||||
someone.)
|
||||
* `#67`_: Rewrote the document exporter and added a new importer that allows
|
||||
for full metadata retention without depending on the file name and
|
||||
modification time. A big thanks to `Tikitu de Jager`_, `Pit`_,
|
||||
`Florian Jung`_, and `Christopher Luu`_ for their code snippets and
|
||||
contributing conversation that lead to this change.
|
||||
* `#20`_: Added *unpaper* support to help in cleaning up the scanned image
|
||||
before it's OCR'd. Thanks to `Pit`_ for this one.
|
||||
* `#71`_ Added (encrypted) thumbnails in anticipation of a proper UI.
|
||||
* `#68`_: Added support for using a proper config file at
|
||||
``/etc/paperless.conf`` and modified the systemd unit files to use it.
|
||||
* Refactored the Vagrant installation process to use environment variables
|
||||
rather than asking the user to modify ``settings.py``.
|
||||
* `#44`_: Harmonise environment variable names with constant names.
|
||||
* `#60`_: Setup logging to actually use the Python native logging framework.
|
||||
* `#53`_: Fixed an annoying bug that caused ``.jpeg`` and ``.JPG`` images
|
||||
to be imported but made unavailable.
|
||||
1.0.0
|
||||
=====
|
||||
|
||||
* 0.1.0
|
||||
* Upgrade to Django 1.11. **You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update**.
|
||||
* Replace the templatetag-based hack we had for document listing in favour of
|
||||
a slightly less ugly solution in the form of another template tag with less
|
||||
copypasta.
|
||||
* Support for multi-word-matches for auto-tagging thanks to an excellent
|
||||
patch from `ishirav`_ `#277`_.
|
||||
* Fixed a CSS bug reported by `Stefan Hagen`_ that caused an overlapping of
|
||||
the text and checkboxes under some resolutions `#272`_.
|
||||
* Patched the Docker config to force the serving of static files. Credit for
|
||||
this one goes to `dev-rke`_ via `#248`_.
|
||||
* Fix file permissions during Docker start up thanks to `Pit`_ on `#268`_.
|
||||
* Date fields in the admin are now expressed as HTML5 date fields thanks to
|
||||
`Lukas Winkler`_'s issue `#278`_
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
who spearheadded this effort.
|
||||
* A simple REST API is in place, but it should be considered unstable.
|
||||
* Cleaned up the consumer to use temporary directories instead of a single
|
||||
scratch space. (Thanks `Pit`_)
|
||||
* Improved the efficiency of the consumer by parsing pages more intelligently
|
||||
and introducing a threaded OCR process (thanks again `Pit`_).
|
||||
* `#45`_: Cleaned up the logic for tag matching. Reported by `darkmatter`_.
|
||||
* `#47`_: Auto-rotate landscape documents. Reported by `Paul`_ and fixed by
|
||||
`Pit`_.
|
||||
* `#48`_: Matching algorithms should do so on a word boundary (`darkmatter`_)
|
||||
* `#54`_: Documented the re-tagger (`zedster`_)
|
||||
* `#57`_: Make sure file is preserved on import failure (`darkmatter`_)
|
||||
* Added tox with pep8 checking
|
||||
0.8.0
|
||||
=====
|
||||
|
||||
* 0.0.6
|
||||
* Paperless can now run in a subdirectory on a host (``/paperless``), rather
|
||||
than always running in the root (``/``) thanks to `maphy-psd`_'s work on
|
||||
`#255`_.
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
0.7.0
|
||||
=====
|
||||
|
||||
* 0.0.5
|
||||
* **Potentially breaking change**: As per `#235`_, Paperless will no longer
|
||||
automatically delete documents attached to correspondents when those
|
||||
correspondents are themselves deleted. This was Django's default
|
||||
behaviour, but didn't make much sense in Paperless' case. Thanks to
|
||||
`Thomas Brueggemann`_ and `David Martin`_ for their input on this one.
|
||||
* Fix for `#232`_ wherein Paperless wasn't recognising ``.tif`` files
|
||||
properly. Thanks to `ayounggun`_ for reporting this one and to
|
||||
`Kusti Skytén`_ for posting the correct solution in the Github issue.
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
* Added IMAP mail support
|
||||
* Added a re-tagging utility
|
||||
* Documentation for the above as well as data migration
|
||||
0.6.0
|
||||
=====
|
||||
|
||||
* 0.0.4
|
||||
* Abandon the shared-secret trick we were using for the POST API in favour
|
||||
of BasicAuth or Django session.
|
||||
* Fix the POST API so it actually works. `#236`_
|
||||
* **Breaking change**: We've dropped the use of ``PAPERLESS_SHARED_SECRET``
|
||||
as it was being used both for the API (now replaced with a normal auth)
|
||||
and form email polling. Now that we're only using it for email, this
|
||||
variable has been renamed to ``PAPERLESS_EMAIL_SECRET``. The old value
|
||||
will still work for a while, but you should change your config if you've
|
||||
been using the email polling feature. Thanks to `Joshua Gilman`_ for all
|
||||
the help with this feature.
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
* Removed ``User`` and ``Group`` from the admin
|
||||
* Added ``pytz`` to the list of requirements
|
||||
0.5.0
|
||||
=====
|
||||
|
||||
* 0.0.3
|
||||
* Support for fuzzy matching in the auto-tagger & auto-correspondent systems
|
||||
thanks to `Jake Gysland`_'s patch `#220`_.
|
||||
* Modified the Dockerfile to prepare an export directory (`#212`_). Thanks
|
||||
to combined efforts from `Pit`_ and `Strubbl`_ in working out the kinks on
|
||||
this one.
|
||||
* Updated the import/export scripts to include support for thumbnails. Big
|
||||
thanks to `CkuT`_ for finding this shortcoming and doing the work to get
|
||||
it fixed in `#224`_.
|
||||
* All of the following changes are thanks to `David Martin`_:
|
||||
* Bumped the dependency on pyocr to 0.4.7 so new users can make use of
|
||||
Tesseract 4 if they so prefer (`#226`_).
|
||||
* Fixed a number of issues with the automated mail handler (`#227`_, `#228`_)
|
||||
* Amended the documentation for better handling of systemd service files (`#229`_)
|
||||
* Amended the Django Admin configuration to have nice headers (`#230`_)
|
||||
|
||||
* Added basic tagging
|
||||
0.4.1
|
||||
=====
|
||||
|
||||
* 0.0.2
|
||||
* Fix for `#206`_ wherein the pluggable parser didn't recognise files with
|
||||
all-caps suffixes like ``.PDF``
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
0.4.0
|
||||
=====
|
||||
|
||||
* 0.0.1
|
||||
* Introducing reminders. See `#199`_ for more information, but the short
|
||||
explanation is that you can now attach simple notes & times to documents
|
||||
which are made available via the API. Currently, the default API
|
||||
(basically just the Django admin) doesn't really make use of this, but
|
||||
`Thomas Brueggemann`_ over at `Paperless Desktop`_ has said that he would
|
||||
like to make use of this feature in his project.
|
||||
|
||||
* Initial release
|
||||
0.3.6
|
||||
=====
|
||||
|
||||
* Fix for `#200`_ (!!) where the API wasn't configured to allow updating the
|
||||
correspondent or the tags for a document.
|
||||
* The ``content`` field is now optional, to allow for the edge case of a
|
||||
purely graphical document.
|
||||
* You can no longer add documents via the admin. This never worked in the
|
||||
first place, so all I've done here is remove the link to the broken form.
|
||||
* The consumer code has been heavily refactored to support a pluggable
|
||||
interface. Install a paperless consumer via pip and tell paperless about
|
||||
it with an environment variable, and you're good to go. Proper
|
||||
documentation is on its way.
|
||||
|
||||
0.3.5
|
||||
=====
|
||||
|
||||
* A serious facelift for the documents listing page wherein we drop the
|
||||
tabular layout in favour of a tiled interface.
|
||||
* Users can now configure the number of items per page.
|
||||
* Fix for `#171`_: Allow users to specify their own ``SECRET_KEY`` value.
|
||||
* Moved the dotenv loading to the top of settings.py
|
||||
* Fix for `#112`_: Added checks for binaries required for document
|
||||
consumption.
|
||||
|
||||
0.3.4
|
||||
=====
|
||||
|
||||
* Removal of django-suit due to a licensing conflict I bumped into in 0.3.3.
|
||||
Note that you *can* use Django Suit with Paperless, but only in a
|
||||
non-profit situation as their free license prohibits for-profit use. As a
|
||||
result, I can't bundle Suit with Paperless without conflicting with the
|
||||
GPL. Further development will be done against the stock Django admin.
|
||||
* I shrunk the thumbnails a little 'cause they were too big for me, even on
|
||||
my high-DPI monitor.
|
||||
* BasicAuth support for document and thumbnail downloads, as well as the Push
|
||||
API thanks to @thomasbrueggemann. See `#179`_.
|
||||
|
||||
0.3.3
|
||||
=====
|
||||
|
||||
* Thumbnails in the UI and a Django-suit -based face-lift courtesy of @ekw!
|
||||
* Timezone, items per page, and default language are now all configurable,
|
||||
also thanks to @ekw.
|
||||
|
||||
0.3.2
|
||||
=====
|
||||
|
||||
* Fix for `#172`_: defaulting ALLOWED_HOSTS to ``["*"]`` and allowing the
|
||||
user to set her own value via ``PAPERLESS_ALLOWED_HOSTS`` should the need
|
||||
arise.
|
||||
|
||||
0.3.1
|
||||
=====
|
||||
|
||||
* Added a default value for ``CONVERT_BINARY``
|
||||
|
||||
0.3.0
|
||||
=====
|
||||
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
* Consumer loop time is now configurable for systems with slow writes. Just
|
||||
set ``PAPERLESS_CONSUMER_LOOP_TIME`` to a number of seconds. The default
|
||||
is 10.
|
||||
* As per `#44`_, we've removed support for ``PAPERLESS_CONVERT``,
|
||||
``PAPERLESS_CONSUME``, and ``PAPERLESS_SECRET``. Please use
|
||||
``PAPERLESS_CONVERT_BINARY``, ``PAPERLESS_CONSUMPTION_DIR``, and
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
|
||||
0.2.0
|
||||
=====
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#148`_: The database location (sqlite) is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#146`_: Fixed a bug that allowed unauthorised access to the ``/fetch``
|
||||
URL.
|
||||
* `#131`_: Document files are now automatically removed from disk when
|
||||
they're deleted in Paperless.
|
||||
* `#121`_: Fixed a bug where Paperless wasn't setting document creation time
|
||||
based on the file naming scheme.
|
||||
* `#81`_: Added a hook to run an arbitrary script after every document is
|
||||
consumed.
|
||||
* `#98`_: Added optional environment variables for ImageMagick so that it
|
||||
doesn't explode when handling Very Large Documents or when it's just
|
||||
running on a low-memory system. Thanks to `Florian Harr`_ for his help on
|
||||
this one.
|
||||
* `#89`_ Ported the auto-tagging code to correspondents as well. Thanks to
|
||||
`Justin Snyman`_ for the pointers in the issue queue.
|
||||
* Added support for guessing the date from the file name along with the
|
||||
correspondent, title, and tags. Thanks to `Tikitu de Jager`_ for his pull
|
||||
request that I took forever to merge and to `Pit`_ for his efforts on the
|
||||
regex front.
|
||||
* `#94`_: Restored support for changing the created date in the UI. Thanks
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
|
||||
0.1.1
|
||||
=====
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
property (one could quite reasonably scan a document before sending it to
|
||||
someone.)
|
||||
* `#67`_: Rewrote the document exporter and added a new importer that allows
|
||||
for full metadata retention without depending on the file name and
|
||||
modification time. A big thanks to `Tikitu de Jager`_, `Pit`_,
|
||||
`Florian Jung`_, and `Christopher Luu`_ for their code snippets and
|
||||
contributing conversation that lead to this change.
|
||||
* `#20`_: Added *unpaper* support to help in cleaning up the scanned image
|
||||
before it's OCR'd. Thanks to `Pit`_ for this one.
|
||||
* `#71`_ Added (encrypted) thumbnails in anticipation of a proper UI.
|
||||
* `#68`_: Added support for using a proper config file at
|
||||
``/etc/paperless.conf`` and modified the systemd unit files to use it.
|
||||
* Refactored the Vagrant installation process to use environment variables
|
||||
rather than asking the user to modify ``settings.py``.
|
||||
* `#44`_: Harmonise environment variable names with constant names.
|
||||
* `#60`_: Setup logging to actually use the Python native logging framework.
|
||||
* `#53`_: Fixed an annoying bug that caused ``.jpeg`` and ``.JPG`` images
|
||||
to be imported but made unavailable.
|
||||
|
||||
0.1.0
|
||||
=====
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
who spearheadded this effort.
|
||||
* A simple REST API is in place, but it should be considered unstable.
|
||||
* Cleaned up the consumer to use temporary directories instead of a single
|
||||
scratch space. (Thanks `Pit`_)
|
||||
* Improved the efficiency of the consumer by parsing pages more intelligently
|
||||
and introducing a threaded OCR process (thanks again `Pit`_).
|
||||
* `#45`_: Cleaned up the logic for tag matching. Reported by `darkmatter`_.
|
||||
* `#47`_: Auto-rotate landscape documents. Reported by `Paul`_ and fixed by
|
||||
`Pit`_.
|
||||
* `#48`_: Matching algorithms should do so on a word boundary (`darkmatter`_)
|
||||
* `#54`_: Documented the re-tagger (`zedster`_)
|
||||
* `#57`_: Make sure file is preserved on import failure (`darkmatter`_)
|
||||
* Added tox with pep8 checking
|
||||
|
||||
0.0.6
|
||||
=====
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
|
||||
0.0.5
|
||||
=====
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
* Added IMAP mail support
|
||||
* Added a re-tagging utility
|
||||
* Documentation for the above as well as data migration
|
||||
|
||||
0.0.4
|
||||
=====
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
* Removed ``User`` and ``Group`` from the admin
|
||||
* Added ``pytz`` to the list of requirements
|
||||
|
||||
0.0.3
|
||||
=====
|
||||
|
||||
* Added basic tagging
|
||||
|
||||
0.0.2
|
||||
=====
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
|
||||
0.0.1
|
||||
=====
|
||||
|
||||
* Initial release
|
||||
|
||||
.. _Brian Conn: https://github.com/TheConnMan
|
||||
.. _Christopher Luu: https://github.com/nuudles
|
||||
@@ -127,6 +311,24 @@ Changelog
|
||||
.. _Tim White: https://github.com/timwhite
|
||||
.. _Florian Harr: https://github.com/evils
|
||||
.. _Justin Snyman: https://github.com/stringlytyped
|
||||
.. _Thomas Brueggemann: https://github.com/thomasbrueggemann
|
||||
.. _Jake Gysland: https://github.com/jgysland
|
||||
.. _Strubbl: https://github.com/strubbl
|
||||
.. _CkuT: https://github.com/CkuT
|
||||
.. _David Martin: https://github.com/ddddavidmartin
|
||||
.. _Paperless Desktop: https://github.com/thomasbrueggemann/paperless-desktop
|
||||
.. _Joshua Gilman: https://github.com/jmgilman
|
||||
.. _ayounggun: https://github.com/ayounggun
|
||||
.. _Kusti Skytén: https://github.com/kskyten
|
||||
.. _maphy-psd: https://github.com/maphy-psd
|
||||
.. _ishirav: https://github.com/ishirav
|
||||
.. _Stefan Hagen: https://github.com/xkpd3
|
||||
.. _dev-rke: https://github.com/dev-rke
|
||||
.. _Lukas Winkler: https://github.com/Findus23
|
||||
.. _chris-aeviator: https://github.com/chris-aeviator
|
||||
.. _Dan Panzarella: https://github.com/pzl
|
||||
.. _addadi: https://github.com/addadi
|
||||
.. _BastianPoe: https://github.com/BastianPoe
|
||||
|
||||
.. _#20: https://github.com/danielquinn/paperless/issues/20
|
||||
.. _#44: https://github.com/danielquinn/paperless/issues/44
|
||||
@@ -144,8 +346,40 @@ Changelog
|
||||
.. _#89: https://github.com/danielquinn/paperless/issues/89
|
||||
.. _#94: https://github.com/danielquinn/paperless/issues/94
|
||||
.. _#98: https://github.com/danielquinn/paperless/issues/98
|
||||
.. _#112: https://github.com/danielquinn/paperless/issues/112
|
||||
.. _#121: https://github.com/danielquinn/paperless/issues/121
|
||||
.. _#131: https://github.com/danielquinn/paperless/issues/131
|
||||
.. _#146: https://github.com/danielquinn/paperless/issues/146
|
||||
.. _#148: https://github.com/danielquinn/paperless/pull/148
|
||||
.. _#150: https://github.com/danielquinn/paperless/pull/150
|
||||
.. _#158: https://github.com/danielquinn/paperless/issues/158
|
||||
.. _#171: https://github.com/danielquinn/paperless/issues/171
|
||||
.. _#172: https://github.com/danielquinn/paperless/issues/172
|
||||
.. _#179: https://github.com/danielquinn/paperless/pull/179
|
||||
.. _#199: https://github.com/danielquinn/paperless/issues/199
|
||||
.. _#200: https://github.com/danielquinn/paperless/issues/200
|
||||
.. _#206: https://github.com/danielquinn/paperless/issues/206
|
||||
.. _#212: https://github.com/danielquinn/paperless/pull/212
|
||||
.. _#220: https://github.com/danielquinn/paperless/pull/220
|
||||
.. _#224: https://github.com/danielquinn/paperless/pull/224
|
||||
.. _#226: https://github.com/danielquinn/paperless/pull/226
|
||||
.. _#227: https://github.com/danielquinn/paperless/pull/227
|
||||
.. _#228: https://github.com/danielquinn/paperless/pull/228
|
||||
.. _#229: https://github.com/danielquinn/paperless/pull/229
|
||||
.. _#230: https://github.com/danielquinn/paperless/pull/230
|
||||
.. _#232: https://github.com/danielquinn/paperless/issues/232
|
||||
.. _#235: https://github.com/danielquinn/paperless/issues/235
|
||||
.. _#236: https://github.com/danielquinn/paperless/issues/236
|
||||
.. _#255: https://github.com/danielquinn/paperless/pull/255
|
||||
.. _#268: https://github.com/danielquinn/paperless/pull/268
|
||||
.. _#277: https://github.com/danielquinn/paperless/pull/277
|
||||
.. _#272: https://github.com/danielquinn/paperless/issues/272
|
||||
.. _#248: https://github.com/danielquinn/paperless/issues/248
|
||||
.. _#278: https://github.com/danielquinn/paperless/issues/248
|
||||
.. _#283: https://github.com/danielquinn/paperless/issues/283
|
||||
.. _#256: https://github.com/danielquinn/paperless/pull/256
|
||||
.. _#285: https://github.com/danielquinn/paperless/pull/285
|
||||
.. _#291: https://github.com/danielquinn/paperless/pull/291
|
||||
|
||||
.. _pipenv: https://docs.pipenv.org/
|
||||
.. _a new home on Docker Hub: https://hub.docker.com/r/danielquinn/paperless/
|
||||
@@ -121,18 +121,21 @@ So, with all that in mind, here's what you do to get it running:
|
||||
|
||||
1. Setup a new email account somewhere, or if you're feeling daring, create a
|
||||
folder in an existing email box and note the path to that folder.
|
||||
2. In ``settings.py`` set all of the appropriate values in ``MAIL_CONSUMPTION``.
|
||||
2. In ``/etc/paperless.conf`` set all of the appropriate values in
|
||||
``PATHS AND FOLDERS`` and ``SECURITY``.
|
||||
If you decided to use a subfolder of an existing account, then make sure you
|
||||
set ``INBOX`` accordingly here. You also have to set the
|
||||
``UPLOAD_SHARED_SECRET`` to something you can remember 'cause you'll have to
|
||||
include that in every email you send.
|
||||
set ``PAPERLESS_CONSUME_MAIL_INBOX`` accordingly here. You also have to set
|
||||
the ``PAPERLESS_EMAIL_SECRET`` to something you can remember 'cause you'll
|
||||
have to include that in every email you send.
|
||||
3. Restart the :ref:`consumer <utilities-consumer>`. The consumer will check
|
||||
the configured email account every 10 minutes for something new and pull down
|
||||
whatever it finds.
|
||||
the configured email account at startup and from then on every 10 minutes
|
||||
for something new and pulls down whatever it finds.
|
||||
4. Send yourself an email! Note that the subject is treated as the file name,
|
||||
so if you set the subject to ``Correspondent - Title - tag,tag,tag``, you'll
|
||||
get what you expect. Also, you must include the aforementioned secret
|
||||
string in every email so the fetcher knows that it's safe to import.
|
||||
Note that Paperless only allows the email title to consist of safe characters
|
||||
to be imported. These consist of alpha-numeric characters and ``-_ ,.'``.
|
||||
5. After a few minutes, the consumer will poll your mailbox, pull down the
|
||||
message, and place the attachment in the consumption directory with the
|
||||
appropriate name. A few minutes later, the consumer will import it like any
|
||||
@@ -144,46 +147,83 @@ So, with all that in mind, here's what you do to get it running:
|
||||
HTTP POST
|
||||
=========
|
||||
|
||||
You can also submit a document via HTTP POST. It doesn't do tags yet, and the
|
||||
URL schema isn't concrete, but it's a start.
|
||||
|
||||
To push your document to Paperless, send an HTTP POST to the server with the
|
||||
following name/value pairs:
|
||||
You can also submit a document via HTTP POST, so long as you do so after
|
||||
authenticating. To push your document to Paperless, send an HTTP POST to the
|
||||
server with the following name/value pairs:
|
||||
|
||||
* ``correspondent``: The name of the document's correspondent. Note that there
|
||||
are restrictions on what characters you can use here. Specifically,
|
||||
alphanumeric characters, `-`, `,`, `.`, and `'` are ok, everything else it
|
||||
alphanumeric characters, `-`, `,`, `.`, and `'` are ok, everything else is
|
||||
out. You also can't use the sequence ` - ` (space, dash, space).
|
||||
* ``title``: The title of the document. The rules for characters is the same
|
||||
here as the correspondent.
|
||||
* ``signature``: For security reasons, we have the correspondent send a
|
||||
signature using a "shared secret" method to make sure that random strangers
|
||||
don't start uploading stuff to your server. The means of generating this
|
||||
signature is defined below.
|
||||
* ``document``: The file you're uploading
|
||||
|
||||
Specify ``enctype="multipart/form-data"``, and then POST your file with::
|
||||
|
||||
Content-Disposition: form-data; name="document"; filename="whatever.pdf"
|
||||
|
||||
An example of this in HTML is a typical form:
|
||||
|
||||
.. _consumption-http-signature:
|
||||
.. code:: html
|
||||
|
||||
Generating the Signature
|
||||
------------------------
|
||||
<form method="post" enctype="multipart/form-data">
|
||||
<input type="text" name="correspondent" value="My Correspondent" />
|
||||
<input type="text" name="title" value="My Title" />
|
||||
<input type="file" name="document" />
|
||||
<input type="submit" name="go" value="Do the thing" />
|
||||
</form>
|
||||
|
||||
Generating a signature based a shared secret is pretty simple: define a secret,
|
||||
and store it on the server and the client. Then use that secret, along with
|
||||
the text you want to verify to generate a string that you can use for
|
||||
verification.
|
||||
|
||||
In the case of Paperless, you configure the server with the secret by setting
|
||||
``UPLOAD_SHARED_SECRET``. Then on your client, you generate your signature by
|
||||
concatenating the correspondent, title, and the secret, and then using sha256
|
||||
to generate a hexdigest.
|
||||
|
||||
If you're using Python, this is what that looks like:
|
||||
But a potentially more useful way to do this would be in Python. Here we use
|
||||
the requests library to handle basic authentication and to send the POST data
|
||||
to the URL.
|
||||
|
||||
.. code:: python
|
||||
|
||||
import os
|
||||
|
||||
from hashlib import sha256
|
||||
signature = sha256(correspondent + title + secret).hexdigest()
|
||||
|
||||
import requests
|
||||
from requests.auth import HTTPBasicAuth
|
||||
|
||||
# You authenticate via BasicAuth or with a session id.
|
||||
# We use BasicAuth here
|
||||
username = "my-username"
|
||||
password = "my-super-secret-password"
|
||||
|
||||
# Where you have Paperless installed and listening
|
||||
url = "http://localhost:8000/push"
|
||||
|
||||
# Document metadata
|
||||
correspondent = "Test Correspondent"
|
||||
title = "Test Title"
|
||||
|
||||
# The local file you want to push
|
||||
path = "/path/to/some/directory/my-document.pdf"
|
||||
|
||||
|
||||
with open(path, "rb") as f:
|
||||
|
||||
response = requests.post(
|
||||
url=url,
|
||||
data={"title": title, "correspondent": correspondent},
|
||||
files={"document": (os.path.basename(path), f, "application/pdf")},
|
||||
auth=HTTPBasicAuth(username, password),
|
||||
allow_redirects=False
|
||||
)
|
||||
|
||||
if response.status_code == 202:
|
||||
|
||||
# Everything worked out ok
|
||||
print("Upload successful")
|
||||
|
||||
else:
|
||||
|
||||
# If you don't get a 202, it's probably because your credentials
|
||||
# are wrong or something. This will give you a rough idea of what
|
||||
# happened.
|
||||
|
||||
print("We got HTTP status code: {}".format(response.status_code))
|
||||
for k, v in response.headers.items():
|
||||
print("{}: {}".format(k, v))
|
||||
|
||||
104
docs/extending.rst
Normal file
@@ -0,0 +1,104 @@
|
||||
.. _extending:
|
||||
|
||||
Extending Paperless
|
||||
===================
|
||||
|
||||
For the most part, Paperless is monolithic, so extending it is often best
|
||||
managed by way of modifying the code directly and issuing a pull request on
|
||||
`GitHub`_. However, over time the project has been evolving to be a little
|
||||
more "pluggable" so that users can write their own stuff that talks to it.
|
||||
|
||||
.. _GitHub: https://github.com/danielquinn/paperless
|
||||
|
||||
|
||||
.. _extending-parsers:
|
||||
|
||||
Parsers
|
||||
-------
|
||||
|
||||
You can leverage Paperless' consumption model to have it consume files *other*
|
||||
than ones handled by default like ``.pdf``, ``.jpg``, and ``.tiff``. To do so,
|
||||
you simply follow Django's convention of creating a new app, with a few key
|
||||
requirements.
|
||||
|
||||
|
||||
.. _extending-parsers-parserspy:
|
||||
|
||||
parsers.py
|
||||
..........
|
||||
|
||||
In this file, you create a class that extends
|
||||
``documents.parsers.DocumentParser`` and go about implementing the three
|
||||
required methods:
|
||||
|
||||
* ``get_thumbnail()``: Returns the path to a file we can use as a thumbnail for
|
||||
this document.
|
||||
* ``get_text()``: Returns the text from the document and only the text.
|
||||
* ``get_date()``: If possible, this returns the date of the document, otherwise
|
||||
it should return ``None``.
|
||||
|
||||
|
||||
.. _extending-parsers-signalspy:
|
||||
|
||||
signals.py
|
||||
..........
|
||||
|
||||
At consumption time, Paperless emits a ``document_consumer_declaration``
|
||||
signal which your module has to react to in order to let the consumer know
|
||||
whether or not it's capable of handling a particular file. Think of it like
|
||||
this:
|
||||
|
||||
1. Consumer finds a file in the consumption directory.
|
||||
2. It asks all the available parsers: *"Hey, can you handle this file?"*
|
||||
3. The first parser that says yes gets to handle the file. The order in which
|
||||
the parsers are asked is handled by sorting ``INSTALLED_APPS`` in
|
||||
``settings.py``.
|
||||
|
||||
|
||||
.. _extending-parsers-appspy:
|
||||
|
||||
apps.py
|
||||
.......
|
||||
|
||||
This is a standard Django file, but you'll need to add some code to it to
|
||||
register your parser as being able to handle particular files.
|
||||
|
||||
|
||||
.. _extending-parsers-finally:
|
||||
|
||||
Finally
|
||||
.......
|
||||
|
||||
The last step is to update ``settings.py`` to include your new module.
|
||||
Eventually, this will be dynamic, but at the moment, you have to edit the
|
||||
``INSTALLED_APPS`` section manually. Simply add the path to your AppConfig to
|
||||
the list like this:
|
||||
|
||||
.. code:: python
|
||||
|
||||
INSTALLED_APPS = [
|
||||
...
|
||||
"my_module.apps.MyModuleConfig",
|
||||
"paperless_tesseract.apps.PaperlessTesseractConfig",
|
||||
...
|
||||
]
|
||||
|
||||
Note that we're placing our module *above* ``PaperlessTesseractConfig``. This
|
||||
is to ensure that if your module wants to handle any files typically handled by
|
||||
the default module, yours will win instead. If there's no conflict between
|
||||
what your module does and the default, then order doesn't matter.
|
||||
|
||||
|
||||
.. _extending-parsers-example:
|
||||
|
||||
An Example
|
||||
..........
|
||||
|
||||
The core Paperless functionality is based on this design, so if you want to see
|
||||
what a parser module should look like, have a look at `parsers.py`_,
|
||||
`signals.py`_, and `apps.py`_ in the `paperless_tesseract`_ module.
|
||||
|
||||
.. _parsers.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/parsers.py
|
||||
.. _signals.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/signals.py
|
||||
.. _apps.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/apps.py
|
||||
.. _paperless_tesseract: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/
|
||||
@@ -80,6 +80,12 @@ text and matching algorithm. From the help info there:
|
||||
uses a regex to match the PDF. If you don't know what a regex is, you
|
||||
probably don't want this option.
|
||||
|
||||
When using the "any" or "all" matching algorithms, you can search for terms that
|
||||
consist of multiple words by enclosing them in double quotes. For example, defining
|
||||
a match text of ``"Bank of America" BofA`` using the "any" algorithm, will match
|
||||
documents that contain either "Bank of America" or "BofA", but will not match
|
||||
documents containing "Bank of South America".
|
||||
|
||||
Then just save your tag/correspondent and run another document through the
|
||||
consumer. Once complete, you should see the newly-created document,
|
||||
automatically tagged with the appropriate data.
|
||||
|
||||
@@ -3,7 +3,11 @@
|
||||
Paperless
|
||||
=========
|
||||
|
||||
Scan, index, and archive all of your paper documents. Say goodbye to paper.
|
||||
Paperless is a simple Django application running in two parts:
|
||||
a :ref:`consumer <utilities-consumer>` (the thing that does the indexing) and
|
||||
the :ref:`webserver <utilities-webserver>` (the part that lets you search &
|
||||
download already-indexed documents). If you want to learn more about its
|
||||
functions keep on reading after the installation section.
|
||||
|
||||
|
||||
.. _index-why-this-exists:
|
||||
@@ -12,13 +16,15 @@ Why This Exists
|
||||
===============
|
||||
|
||||
Paper is a nightmare. Environmental issues aside, there's no excuse for it in
|
||||
the 21st century. It takes up space, collects dust, doesn't support any form of
|
||||
a search feature, indexing is tedious, it's heavy and prone to damage & loss.
|
||||
the 21st century. It takes up space, collects dust, doesn't support any form
|
||||
of a search feature, indexing is tedious, it's heavy and prone to damage &
|
||||
loss.
|
||||
|
||||
I wrote this to make "going paperless" easier. I do not have to worry about
|
||||
finding stuff again. I feed documents right from the post box into the scanner
|
||||
and then shred them. Perhaps you might find it useful too.
|
||||
|
||||
|
||||
I wrote this to make "going paperless" easier. I wanted to be able to feed
|
||||
documents right from the post box into the scanner and then shred them so I
|
||||
never have to worry about finding stuff again. Perhaps you might find it useful
|
||||
too.
|
||||
|
||||
|
||||
Contents
|
||||
@@ -34,5 +40,7 @@ Contents
|
||||
utilities
|
||||
guesswork
|
||||
migrating
|
||||
extending
|
||||
troubleshooting
|
||||
scanners
|
||||
changelog
|
||||
|
||||
@@ -4,31 +4,34 @@ Requirements
|
||||
============
|
||||
|
||||
You need a Linux machine or Unix-like setup (theoretically an Apple machine
|
||||
should work) that has the following software installed on it:
|
||||
should work) that has the following software installed:
|
||||
|
||||
* `Python3`_ (with development libraries, pip and virtualenv)
|
||||
* `GNU Privacy Guard`_
|
||||
* `Tesseract`_, plus its language files matching your document base.
|
||||
* `Imagemagick`_ version 6.7.5 or higher
|
||||
* `unpaper`_
|
||||
* `libpoppler-cpp-dev`_ PDF rendering library
|
||||
|
||||
.. _Python3: https://python.org/
|
||||
.. _GNU Privacy Guard: https://gnupg.org
|
||||
.. _Tesseract: https://github.com/tesseract-ocr
|
||||
.. _Imagemagick: http://imagemagick.org/
|
||||
.. _unpaper: https://www.flameeyes.eu/projects/unpaper
|
||||
.. _libpoppler-cpp-dev: https://poppler.freedesktop.org/
|
||||
|
||||
Notably, you should confirm how you access your Python3 installation. Many
|
||||
Linux distributions will install Python3 in parallel to Python2, using the names
|
||||
``python3`` and ``python`` respectively. The same goes for ``pip3`` and
|
||||
``pip``. Using Python2 will likely break things, so make sure that you're using
|
||||
the right version.
|
||||
Linux distributions will install Python3 in parallel to Python2, using the
|
||||
names ``python3`` and ``python`` respectively. The same goes for ``pip3`` and
|
||||
``pip``. Running Paperless with Python2 will likely break things, so make sure
|
||||
that you're using the right version.
|
||||
|
||||
For the purposes of simplicity, ``python`` and ``pip`` is used everywhere to
|
||||
refer to their Python 3 versions.
|
||||
refer to their Python3 versions.
|
||||
|
||||
In addition to the above, there are a number of Python requirements, all of
|
||||
which are listed in a file called ``requirements.txt`` in the project root.
|
||||
which are listed in a file called ``requirements.txt`` in the project root
|
||||
directory.
|
||||
|
||||
If you're not working on a virtual environment (like Vagrant or Docker), you
|
||||
should probably be using a virtualenv, but that's your call. The reasons why
|
||||
@@ -39,12 +42,13 @@ probably figure that out before continuing.
|
||||
|
||||
.. _requirements-apple:
|
||||
|
||||
Apple-tastic Complications
|
||||
--------------------------
|
||||
Problems with Imagemagick & PDFs
|
||||
--------------------------------
|
||||
|
||||
Some users have `run into problems`_ with installing ImageMagick on Apple
|
||||
systems using HomeBrew. The solution appears to be to install ghostscript as
|
||||
well as ImageMagick:
|
||||
Some users have `run into problems`_ with getting ImageMagick to do its thing
|
||||
with PDFs. Often this is the case with Apple systems using HomeBrew, but other
|
||||
Linuxes have been a problem as well. The solution appears to be to install
|
||||
ghostscript as well as ImageMagick:
|
||||
|
||||
.. _run into problems: https://github.com/danielquinn/paperless/issues/25
|
||||
|
||||
@@ -67,7 +71,7 @@ dependencies is easy:
|
||||
|
||||
$ pip install --user --requirement /path/to/paperless/requirements.txt
|
||||
|
||||
This should download and install all of the requirements into
|
||||
This will download and install all of the requirements into
|
||||
``${HOME}/.local``. Remember that your distribution may be using ``pip3`` as
|
||||
mentioned above.
|
||||
|
||||
@@ -86,8 +90,8 @@ enter it, and install the requirements using the ``requirements.txt`` file:
|
||||
$ . /path/to/arbitrary/directory/bin/activate
|
||||
$ pip install --requirement /path/to/paperless/requirements.txt
|
||||
|
||||
Now you're ready to go. Just remember to enter your virtualenv whenever you
|
||||
want to use Paperless.
|
||||
Now you're ready to go. Just remember to enter (activate) your virtualenv
|
||||
whenever you want to use Paperless.
|
||||
|
||||
|
||||
.. _requirements-documentation:
|
||||
@@ -95,7 +99,7 @@ want to use Paperless.
|
||||
Documentation
|
||||
-------------
|
||||
|
||||
As generation of the documentation is not required for use of Paperless,
|
||||
As generation of the documentation is not required for the use of Paperless,
|
||||
dependencies for this process are not included in ``requirements.txt``. If
|
||||
you'd like to generate your own docs locally, you'll need to:
|
||||
|
||||
|
||||
29
docs/scanners.rst
Normal file
@@ -0,0 +1,29 @@
|
||||
.. _scanners:
|
||||
|
||||
Scanner Recommendations
|
||||
=======================
|
||||
|
||||
As Paperless operates by watching a folder for new files, doesn't care what
|
||||
scanner you use, but sometimes finding a scanner that will write to an FTP,
|
||||
NFS, or SMB server can be difficult. This page is here to help you find one
|
||||
that works right for you based on recommentations from other Paperless users.
|
||||
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Brand | Model | Supports | Recommended By |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| | | FTP | NFS | SMB | |
|
||||
+=========+================+=====+=====+=====+================+
|
||||
| Brother | `ADS-1500W`_ | yes | no | yes | `danielquinn`_ |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Brother | `MFC-J6930DW`_ | yes | | | `ayounggun`_ |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Fujitsu | `ix500`_ | yes | | yes | `eonist`_ |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
|
||||
.. _ADS-1500W: https://www.brother.ca/en/p/ads1500w
|
||||
.. _MFC-J6930DW: https://www.brother.ca/en/p/MFCJ6930DW
|
||||
.. _ix500: http://www.fujitsu.com/us/products/computing/peripheral/scanners/scansnap/ix500/
|
||||
|
||||
.. _danielquinn: https://github.com/danielquinn
|
||||
.. _ayounggun: https://github.com/ayounggun
|
||||
.. _eonist: https://github.com/eonist
|
||||
182
docs/setup.rst
@@ -4,7 +4,7 @@ Setup
|
||||
=====
|
||||
|
||||
Paperless isn't a very complicated app, but there are a few components, so some
|
||||
basic documentation is in order. If you go follow along in this document and
|
||||
basic documentation is in order. If you follow along in this document and
|
||||
still have trouble, please open an `issue on GitHub`_ so I can fill in the
|
||||
gaps.
|
||||
|
||||
@@ -28,6 +28,7 @@ or just download the tarball and go that route:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
$ cd to the directory where you want to run Paperless
|
||||
$ wget https://github.com/danielquinn/paperless/archive/master.zip
|
||||
$ unzip master.zip
|
||||
$ cd paperless-master
|
||||
@@ -43,7 +44,9 @@ route`_ is quick & easy, but means you're running a VM which comes with memory
|
||||
consumption etc. We also `support Docker`_, which you can use natively under
|
||||
Linux and in a VM with `Docker Machine`_ (this guide was written for native
|
||||
Docker usage under Linux, you might have to adapt it for Docker Machine.)
|
||||
Alternatively the standard, `bare metal`_ approach is a little more
|
||||
Not to forget the virtualenv, this is similar to `bare metal`_ with the
|
||||
exception that you have to activate the virtualenv first.
|
||||
Last but not least, the standard `bare metal`_ approach is a little more
|
||||
complicated, but worth it because it makes it easier should you want to
|
||||
contribute some code back.
|
||||
|
||||
@@ -59,9 +62,11 @@ Standard (Bare Metal)
|
||||
.....................
|
||||
|
||||
1. Install the requirements as per the :ref:`requirements <requirements>` page.
|
||||
2. Change to the ``src`` directory in this repo.
|
||||
3. Copy ``paperless.conf.example`` to ``/etc/paperless.conf`` and open it in
|
||||
your favourite editor. Set the values for:
|
||||
2. Within the extract of master.zip go to the ``src`` directory.
|
||||
3. Copy ``paperless.conf.example`` to ``/etc/paperless.conf`` also the virtual
|
||||
envrionment look there for it and open it in your favourite editor.
|
||||
Because this file contains passwords it should only be readable by user root
|
||||
and paperless ! Set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
@@ -70,18 +75,19 @@ Standard (Bare Metal)
|
||||
* ``PAPERLESS_OCR_THREADS``: this is the number of threads the OCR process
|
||||
will spawn to process document pages in parallel.
|
||||
|
||||
4. Initialise the database with ``./manage.py migrate``.
|
||||
4. Initialise the SQLite database with ``./manage.py migrate``.
|
||||
5. Create a user for your Paperless instance with
|
||||
``./manage.py createsuperuser``. Follow the prompts to create your user.
|
||||
6. Start the webserver with ``./manage.py runserver <IP>:<PORT>``.
|
||||
If no specifc IP or port are given, the default is ``127.0.0.1:8000``.
|
||||
You should now be able to visit your (empty) `Paperless webserver`_ at
|
||||
``127.0.0.1:8000`` (or whatever you chose). You can login with the
|
||||
user/pass you created in #5.
|
||||
If no specifc IP or port are given, the default is ``127.0.0.1:8000``
|
||||
also known as http://localhost:8000/.
|
||||
You should now be able to visit your (empty) at `Paperless webserver`_ or
|
||||
whatever you chose before. You can login with the user/pass you created in
|
||||
#5.
|
||||
7. In a separate window, change to the ``src`` directory in this repo again,
|
||||
but this time, you should start the consumer script with
|
||||
``./manage.py document_consumer``.
|
||||
8. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
8. Scan something or put a file into the ``CONSUMPTION_DIR``.
|
||||
9. Wait a few minutes
|
||||
10. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
@@ -89,48 +95,6 @@ Standard (Bare Metal)
|
||||
.. _Paperless webserver: http://127.0.0.1:8000
|
||||
|
||||
|
||||
.. _setup-installation-vagrant:
|
||||
|
||||
Vagrant Method
|
||||
..............
|
||||
|
||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||
provisioned...
|
||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||
``/etc/paperless.conf`` and set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document.
|
||||
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
||||
documents from mail or via the API. If you don't use either, leaving it
|
||||
blank is just fine.
|
||||
|
||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||
updates the environment to make use of the changes you made to the config
|
||||
file.
|
||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||
create your user.
|
||||
7. Start the webserver with
|
||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||
You can login with the user/pass you created in #6.
|
||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||
your vagrant instance, you should start the consumer script with
|
||||
``/opt/paperless/src/manage.py document_consumer``.
|
||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
10. Wait a few minutes
|
||||
11. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. _Vagrant: https://vagrantup.com/
|
||||
.. _Paperless server: http://172.28.128.4:8000
|
||||
|
||||
|
||||
.. _setup-installation-docker:
|
||||
|
||||
Docker Method
|
||||
@@ -169,7 +133,8 @@ Docker Method
|
||||
modified versions of the configuration files.
|
||||
4. Modify ``docker-compose.yml`` to your preferences, following the
|
||||
instructions in comments in the file. The only change that is a hard
|
||||
requirement is to specify where the consumption directory should mount.
|
||||
requirement is to specify where the consumption directory should
|
||||
mount.[#dockercomposeyml]_
|
||||
5. Modify ``docker-compose.env`` and adapt the following environment variables:
|
||||
|
||||
``PAPERLESS_PASSPHRASE``
|
||||
@@ -186,7 +151,7 @@ Docker Method
|
||||
default English, set this parameter to a space separated list of
|
||||
three-letter language-codes after `ISO 639-2/T`_. For a list of available
|
||||
languages -- including their three letter codes -- see the
|
||||
`Debian packagelist`_.
|
||||
`Alpine packagelist`_.
|
||||
|
||||
``USERMAP_UID`` and ``USERMAP_GID``
|
||||
If you want to mount the consumption volume (directory ``/consume`` within
|
||||
@@ -276,12 +241,60 @@ Docker Method
|
||||
.. _Docker: https://www.docker.com/
|
||||
.. _docker-compose: https://docs.docker.com/compose/install/
|
||||
.. _ISO 639-2/T: https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes
|
||||
.. _Debian packagelist: https://packages.debian.org/search?suite=jessie&searchon=names&keywords=tesseract-ocr-
|
||||
.. _Alpine packagelist: https://pkgs.alpinelinux.org/packages?name=tesseract-ocr-data*&arch=x86_64
|
||||
|
||||
.. [#compose] You of course don't have to use docker-compose, but it
|
||||
simplifies deployment immensely. If you know your way around Docker, feel
|
||||
free to tinker around without using compose!
|
||||
|
||||
.. [#dockercomposeyml] If you're upgrading your docker-compose images from
|
||||
version 1.1.0 or earlier, you might need to change in the
|
||||
``docker-compose.yml`` file the ``image: pitkley/paperless`` directive in
|
||||
both the ``webserver`` and ``consumer`` sections to ``build: ./`` as per the
|
||||
newer ``docker-compose.yml.example`` file
|
||||
|
||||
|
||||
.. _setup-installation-vagrant:
|
||||
|
||||
Vagrant Method
|
||||
..............
|
||||
|
||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||
provisioned...
|
||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||
``/etc/paperless.conf`` and set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document.
|
||||
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
||||
documents from mail or via the API. If you don't use either, leaving it
|
||||
blank is just fine.
|
||||
|
||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||
updates the environment to make use of the changes you made to the config
|
||||
file.
|
||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||
create your user.
|
||||
7. Start the webserver with
|
||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||
You can login with the user/pass you created in #6.
|
||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||
your vagrant instance, you should start the consumer script with
|
||||
``/opt/paperless/src/manage.py document_consumer``.
|
||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
10. Wait a few minutes
|
||||
11. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. _Vagrant: https://vagrantup.com/
|
||||
.. _Paperless server: http://172.28.128.4:8000
|
||||
|
||||
|
||||
.. _setup-permanent:
|
||||
|
||||
@@ -299,17 +312,21 @@ Standard (Bare Metal, Systemd)
|
||||
|
||||
If you're running on a bare metal system that's using Systemd, you can use the
|
||||
service unit files in the ``scripts`` directory to set this up. You'll need to
|
||||
create a user called ``paperless`` and setup Paperless to be in a place that
|
||||
this new user can read and write to. Be sure to edit the service scripts to point
|
||||
to the proper location of your paperless install, referencing the appropriate Python
|
||||
binary. For example: ``ExecStart=/path/to/python3 /path/to/paperless/src/manage.py document_consumer``.
|
||||
If you don't want to make a new user, you can change the ``Group`` and ``User`` variables
|
||||
accordingly.
|
||||
create a user called ``paperless`` (without login (if not already done so #5))
|
||||
and setup Paperless to be in a place that this new user can read and write to.
|
||||
Be sure to edit the service scripts to point to the proper location of your
|
||||
paperless install, referencing the appropriate Python binary. For example:
|
||||
``ExecStart=/path/to/python3 /path/to/paperless/src/manage.py document_consumer``.
|
||||
If you don't want to make a new user, you can change the ``Group`` and ``User``
|
||||
variables accordingly.
|
||||
|
||||
Then, you can just tell Systemd as ``root`` (or using ``sudo``) to enable the two ``.service`` files::
|
||||
Then, as ``root`` (or using ``sudo``) you can just copy the ``.service`` files
|
||||
to the Systemd directory and tell it to enable the two services::
|
||||
|
||||
# systemctl enable /path/to/paperless/scripts/paperless-consumer.service
|
||||
# systemctl enable /path/to/paperless/scripts/paperless-webserver.service
|
||||
# cp /path/to/paperless/scripts/paperless-consumer.service /etc/systemd/system/
|
||||
# cp /path/to/paperless/scripts/paperless-webserver.service /etc/systemd/system/
|
||||
# systemctl enable paperless-consumer
|
||||
# systemctl enable paperless-webserver
|
||||
# systemctl start paperless-consumer
|
||||
# systemctl start paperless-webserver
|
||||
|
||||
@@ -344,7 +361,7 @@ after restarting your system:
|
||||
If you are using a network interface other than ``eth0``, you will have to
|
||||
change ``IFACE=eth0``. For example, if you are connected via WiFi, you will
|
||||
likely need to replace ``eth0`` above with ``wlan0``. To see all interfaces,
|
||||
run ``ifconfig``.
|
||||
run ``ifconfig -a``.
|
||||
|
||||
Save the file.
|
||||
|
||||
@@ -384,7 +401,10 @@ Using a Real Webserver
|
||||
The default is to use Django's development server, as that's easy and does the
|
||||
job well enough on a home network. However, if you want to do things right,
|
||||
it's probably a good idea to use a webserver capable of handling more than one
|
||||
thread.
|
||||
thread. You will also have to let the webserver serve the static files (CSS,
|
||||
JavaScript) from the directory configured in ``PAPERLESS_STATICDIR``. For that,
|
||||
you need to run ``./manage.py collectstatic`` in the ``src`` directory. The
|
||||
default static files directory is ``../static``.
|
||||
|
||||
Apache
|
||||
~~~~~~
|
||||
@@ -550,7 +570,8 @@ your gunicorn instance. This should do the trick:
|
||||
Vagrant
|
||||
.......
|
||||
|
||||
You may use the Ubuntu explanation above. Replace ``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||
You may use the Ubuntu explanation above. Replace
|
||||
``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||
|
||||
.. _setup-permanent-docker:
|
||||
|
||||
@@ -562,3 +583,28 @@ If you're using Docker, you can set a restart-policy_ in the
|
||||
Docker daemon.
|
||||
|
||||
.. _restart-policy: https://docs.docker.com/engine/reference/commandline/run/#restart-policies-restart
|
||||
|
||||
|
||||
.. _setup-subdirectory:
|
||||
|
||||
Hosting Paperless in a Subdirectory
|
||||
-----------------------------------
|
||||
|
||||
Paperless was designed to run off the root of the hosting domain,
|
||||
(ie: ``https://example.com/``) but with a few changes, you can configure
|
||||
it to run in a subdirectory on your server
|
||||
(ie: ``https://example.com/paperless/``).
|
||||
|
||||
Thanks to the efforts of `maphy-psd`_ on `Github`_, running Paperless in a
|
||||
subdirectory is now as easy as setting a config variable. Simply set
|
||||
``PAPERLESS_FORCE_SCRIPT_NAME`` in your environment or
|
||||
``/etc/paperless.conf`` to the path you want Paperless hosted at, configure
|
||||
Nginx/Apache for your needs and you're done. So, if you want Paperless to live
|
||||
at ``https://example.com/arbitrary/path/to/paperless`` then you just set
|
||||
``PAPERLESS_FORCE_SCRIPT_NAME`` to ``/arbitrary/path/to/paperless``. Note the
|
||||
leading ``/`` there.
|
||||
|
||||
As to how to configure Nginx or Apache for this, that's on you :-)
|
||||
|
||||
.. _maphy-psd: https://github.com/maphy-psd
|
||||
.. _Github: https://github.com/danielquinn/paperless/pull/255
|
||||
|
||||
@@ -1,11 +1,34 @@
|
||||
# Sample paperless.conf
|
||||
# Copy this file to /etc/paperless.conf and modify it to suit your needs.
|
||||
# As this file contains passwords it should only be readable by the user
|
||||
# running paperless.
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Paths & Folders ####
|
||||
###############################################################################
|
||||
|
||||
# This where your documents should go to be consumed. Make sure that it exists
|
||||
# and that the user running the paperless service can read/write its contents
|
||||
# before you start Paperless.
|
||||
PAPERLESS_CONSUMPTION_DIR=""
|
||||
|
||||
|
||||
# You can specify where you want the SQLite database to be stored instead of
|
||||
# the default location of /data/ within the install directory.
|
||||
#PAPERLESS_DBDIR=/path/to/database/file
|
||||
|
||||
|
||||
# Override the default MEDIA_ROOT here. This is where all files are stored.
|
||||
# The default location is /media/documents/ within the install folder.
|
||||
#PAPERLESS_MEDIADIR=/path/to/media
|
||||
|
||||
|
||||
# Override the default STATIC_ROOT here. This is where all static files
|
||||
# created using "collectstatic" manager command are stored.
|
||||
#PAPERLESS_STATICDIR=""
|
||||
|
||||
|
||||
# These values are required if you want paperless to check a particular email
|
||||
# box every 10 minutes and attempt to consume documents from there. If you
|
||||
# don't define a HOST, mail checking will just be disabled.
|
||||
@@ -14,6 +37,19 @@ PAPERLESS_CONSUME_MAIL_PORT=""
|
||||
PAPERLESS_CONSUME_MAIL_USER=""
|
||||
PAPERLESS_CONSUME_MAIL_PASS=""
|
||||
|
||||
# Override the default IMAP inbox here. If not set Paperless defaults to
|
||||
# "INBOX".
|
||||
#PAPERLESS_CONSUME_MAIL_INBOX="INBOX"
|
||||
|
||||
# Any email sent to the target account that does not contain this text will be
|
||||
# ignored.
|
||||
PAPERLESS_EMAIL_SECRET=""
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Security ####
|
||||
###############################################################################
|
||||
|
||||
# You must have a passphrase in order for Paperless to work at all. If you set
|
||||
# this to "", GNUGPG will "encrypt" your PDF by writing it out as a zero-byte
|
||||
# file.
|
||||
@@ -28,20 +64,43 @@ PAPERLESS_CONSUME_MAIL_PASS=""
|
||||
# you've since changed it to a new one.
|
||||
PAPERLESS_PASSPHRASE="secret"
|
||||
|
||||
# If you intend to consume documents either via HTTP POST or by email, you must
|
||||
# have a shared secret here.
|
||||
PAPERLESS_SHARED_SECRET=""
|
||||
|
||||
# The secret key has a default that should be fine so long as you're hosting
|
||||
# Paperless on a closed network. However, if you're putting this anywhere
|
||||
# public, you should change the key to something unique and verbose.
|
||||
#PAPERLESS_SECRET_KEY="change-me"
|
||||
|
||||
|
||||
# If you're planning on putting Paperless on the open internet, then you
|
||||
# really should set this value to the domain name you're using. Failing to do
|
||||
# so leaves you open to HTTP host header attacks:
|
||||
# https://docs.djangoproject.com/en/1.10/topics/security/#host-headers-virtual-hosting
|
||||
#
|
||||
# Just remember that this is a comma-separated list, so "example.com" is fine,
|
||||
# as is "example.com,www.example.com", but NOT " example.com" or "example.com,"
|
||||
#PAPERLESS_ALLOWED_HOSTS="example.com,www.example.com"
|
||||
|
||||
# To host paperless under a subpath url like example.com/paperless you set
|
||||
# this value to /paperless. No trailing slash!
|
||||
#
|
||||
# https://docs.djangoproject.com/en/1.11/ref/settings/#force-script-name
|
||||
#PAPERLESS_FORCE_SCRIPT_NAME=""
|
||||
|
||||
###############################################################################
|
||||
#### Software Tweaks ####
|
||||
###############################################################################
|
||||
|
||||
# After a document is consumed, Paperless can trigger an arbitrary script if
|
||||
# you like. This script will be passed a number of arguments for you to work
|
||||
# with. The default is blank, which means nothing will be executed. For more
|
||||
# information, take a look at the docs: http://paperless.readthedocs.org/en/latest/consumption.html#hooking-into-the-consumption-process
|
||||
# information, take a look at the docs:
|
||||
# http://paperless.readthedocs.org/en/latest/consumption.html#hooking-into-the-consumption-process
|
||||
#PAPERLESS_POST_CONSUME_SCRIPT="/path/to/an/arbitrary/script.sh"
|
||||
|
||||
|
||||
#
|
||||
# The following values use sensible defaults for modern systems, but if you're
|
||||
# running Paperless on a low-resource machine (like a Raspberry Pi), modifying
|
||||
# running Paperless on a low-resource device (like a Raspberry Pi), modifying
|
||||
# some of these values may be necessary.
|
||||
#
|
||||
|
||||
@@ -51,8 +110,15 @@ PAPERLESS_SHARED_SECRET=""
|
||||
# an integer:
|
||||
#PAPERLESS_OCR_THREADS=1
|
||||
|
||||
|
||||
# Customize the default language that tesseract will attempt to use when
|
||||
# parsing documents. It should be a 3-letter language code consistent with ISO
|
||||
# 639: https://www.loc.gov/standards/iso639-2/php/code_list.php
|
||||
#PAPERLESS_OCR_LANGUAGE=eng
|
||||
|
||||
|
||||
# On smaller systems, or even in the case of Very Large Documents, the consumer
|
||||
# may explode, complaining about how it's "unable to extent pixel cache". In
|
||||
# may explode, complaining about how it's "unable to extend pixel cache". In
|
||||
# such cases, try setting this to a reasonably low value, like 32000000. The
|
||||
# default is to use whatever is necessary to do everything without writing to
|
||||
# disk, and units are in megabytes.
|
||||
@@ -61,16 +127,6 @@ PAPERLESS_SHARED_SECRET=""
|
||||
# the web for "MAGICK_MEMORY_LIMIT".
|
||||
#PAPERLESS_CONVERT_MEMORY_LIMIT=0
|
||||
|
||||
# By default the conversion density setting for documents is 300DPI, in some
|
||||
# cases it has proven useful to configure a lesser value.
|
||||
# This setting has a high impact on the physical size of tmp page files,
|
||||
# the speed of document conversion, and can affect the accuracy of OCR
|
||||
# results. Individual results can vary and this setting should be tested
|
||||
# thoroughly against the documents you are importing to see if it has any
|
||||
# impacts either negative or positive. Testing on limited document sets has
|
||||
# shown a setting of 200 can cut the size of tmp files by 1/3, and speed up
|
||||
# conversion by up to 4x with little impact to OCR accuracy.
|
||||
#PAPERLESS_CONVERT_DENSITY=300
|
||||
|
||||
# Similar to the memory limit, if you've got a small system and your OS mounts
|
||||
# /tmp as tmpfs, you should set this to a path that's on a physical disk, like
|
||||
@@ -81,14 +137,43 @@ PAPERLESS_SHARED_SECRET=""
|
||||
# the web for "MAGICK_TMPDIR".
|
||||
#PAPERLESS_CONVERT_TMPDIR=/var/tmp/paperless
|
||||
|
||||
# You can specify where you want the SQLite database to be stored instead of
|
||||
# the default location
|
||||
#PAPERLESS_DBDIR=/path/to/database/file
|
||||
|
||||
# Override the default MEDIA_ROOT here. This is where all files are stored.
|
||||
#PAPERLESS_MEDIADIR=/path/to/media
|
||||
# By default the conversion density setting for documents is 300DPI, in some
|
||||
# cases it has proven useful to configure a lesser value.
|
||||
# This setting has a high impact on the physical size of tmp page files,
|
||||
# the speed of document conversion, and can affect the accuracy of OCR
|
||||
# results. Individual results can vary and this setting should be tested
|
||||
# thoroughly against the documents you are importing to see if it has any
|
||||
# impacts either negative or positive.
|
||||
# Testing on limited document sets has shown a setting of 200 can cut the
|
||||
# size of tmp files by 1/3, and speed up conversion by up to 4x
|
||||
# with little impact to OCR accuracy.
|
||||
#PAPERLESS_CONVERT_DENSITY=300
|
||||
|
||||
|
||||
# The number of seconds that Paperless will wait between checking
|
||||
# PAPERLESS_CONSUMPTION_DIR. If you tend to write documents to this directory
|
||||
# very slowly, you may want to use a higher value than the default (10).
|
||||
# PAPERLESS_CONSUMER_LOOP_TIME=10
|
||||
# rarely, you may want to use a higher value than the default (10).
|
||||
#PAPERLESS_CONSUMER_LOOP_TIME=10
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Interface ####
|
||||
###############################################################################
|
||||
|
||||
# Override the default UTC time zone here.
|
||||
# See https://docs.djangoproject.com/en/1.10/ref/settings/#std:setting-TIME_ZONE
|
||||
# for details on how to set it.
|
||||
#PAPERLESS_TIME_ZONE=UTC
|
||||
|
||||
|
||||
# If set, Paperless will show document filters per financial year.
|
||||
# The dates must be in the format "mm-dd", for example "07-15" for July 15.
|
||||
#PAPERLESS_FINANCIAL_YEAR_START="mm-dd"
|
||||
#PAPERLESS_FINANCIAL_YEAR_END="mm-dd"
|
||||
|
||||
|
||||
# The number of items on each page in the web UI. This value must be a
|
||||
# positive integer, but if you don't define one in paperless.conf, a default of
|
||||
# 100 will be used.
|
||||
#PAPERLESS_LIST_PER_PAGE=100
|
||||
|
||||
@@ -1,22 +1,28 @@
|
||||
Django==1.10.4
|
||||
Django>=1.11,<2.0
|
||||
Pillow>=3.1.1
|
||||
django-crispy-forms>=1.6.0
|
||||
django-extensions>=1.6.1
|
||||
dateparser>=0.6.0
|
||||
django-crispy-forms>=1.6.1
|
||||
django-extensions>=1.7.6
|
||||
django-filter>=1.0
|
||||
djangorestframework>=3.4.4
|
||||
django-flat-responsive>=1.2.0
|
||||
djangorestframework>=3.5.3
|
||||
filemagic>=1.6
|
||||
langdetect>=1.0.5
|
||||
pyocr>=0.3.1
|
||||
python-dateutil>=2.4.2
|
||||
python-dotenv>=0.3.0
|
||||
python-gnupg>=0.3.8
|
||||
pytz>=2015.7
|
||||
gunicorn==19.6.0
|
||||
fuzzywuzzy[speedup]==0.15.0
|
||||
gunicorn>=19.7.1
|
||||
langdetect>=1.0.7
|
||||
pdftotext>=2.0.1
|
||||
pyocr>=0.4.7
|
||||
python-dateutil>=2.6.0
|
||||
python-dotenv>=0.6.2
|
||||
python-gnupg>=0.3.9
|
||||
pytz>=2016.10
|
||||
|
||||
# For the tests
|
||||
pytest
|
||||
factory-boy
|
||||
flake8
|
||||
pytest==3.3.2 # Newer versions break with pytest-sugar
|
||||
pytest-django
|
||||
pytest-sugar
|
||||
pep8
|
||||
flake8
|
||||
pytest-env
|
||||
pycodestyle
|
||||
tox
|
||||
|
||||
@@ -7,34 +7,37 @@ map_uidgid() {
|
||||
USERMAP_ORIG_UID=$(id -g paperless)
|
||||
USERMAP_GID=${USERMAP_GID:-${USERMAP_UID:-$USERMAP_ORIG_GID}}
|
||||
USERMAP_UID=${USERMAP_UID:-$USERMAP_ORIG_UID}
|
||||
if [[ ${USERMAP_UID} != ${USERMAP_ORIG_UID} || ${USERMAP_GID} != ${USERMAP_ORIG_GID} ]]; then
|
||||
if [[ ${USERMAP_UID} != "${USERMAP_ORIG_UID}" || ${USERMAP_GID} != "${USERMAP_ORIG_GID}" ]]; then
|
||||
echo "Mapping UID and GID for paperless:paperless to $USERMAP_UID:$USERMAP_GID"
|
||||
groupmod -g ${USERMAP_GID} paperless
|
||||
addgroup -g "${USERMAP_GID}" paperless
|
||||
sed -i -e "s|:${USERMAP_ORIG_UID}:${USERMAP_GID}:|:${USERMAP_UID}:${USERMAP_GID}:|" /etc/passwd
|
||||
fi
|
||||
}
|
||||
|
||||
set_permissions() {
|
||||
# Set permissions for consumption directory
|
||||
chgrp paperless "$PAPERLESS_CONSUMPTION_DIR" || {
|
||||
echo "Changing group of consumption directory:"
|
||||
echo " $PAPERLESS_CONSUMPTION_DIR"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`o+x\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
chmod g+x "$PAPERLESS_CONSUMPTION_DIR" || {
|
||||
echo "Changing group permissions of consumption directory:"
|
||||
echo " $PAPERLESS_CONSUMPTION_DIR"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`o+x\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
|
||||
# Set permissions for consumption and export directory
|
||||
for dir in PAPERLESS_CONSUMPTION_DIR PAPERLESS_EXPORT_DIR; do
|
||||
# Extract the name of the current directory from $dir for the error message
|
||||
cur_dir_name=$(echo "$dir" | awk -F'_' '{ print tolower($2); }')
|
||||
chgrp paperless "${!dir}" || {
|
||||
echo "Changing group of ${cur_dir_name} directory:"
|
||||
echo " ${!dir}"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`g+wx\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
chmod g+wx "${!dir}" || {
|
||||
echo "Changing group permissions of ${cur_dir_name} directory:"
|
||||
echo " ${!dir}"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`g+wx\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
done
|
||||
# Set permissions for application directory
|
||||
chown -Rh paperless:paperless /usr/src/paperless
|
||||
}
|
||||
@@ -53,25 +56,24 @@ install_languages() {
|
||||
return
|
||||
fi
|
||||
|
||||
# Update apt-lists
|
||||
apt-get update
|
||||
|
||||
# Loop over languages to be installed
|
||||
for lang in "${langs[@]}"; do
|
||||
pkg="tesseract-ocr-$lang"
|
||||
if dpkg -s "$pkg" 2>&1 > /dev/null; then
|
||||
pkg="tesseract-ocr-data-$lang"
|
||||
|
||||
# English is installed by default
|
||||
if [ "$lang" == "eng" ]; then
|
||||
continue
|
||||
fi
|
||||
|
||||
if apk info -e "$pkg" > /dev/null 2>&1; then
|
||||
continue
|
||||
fi
|
||||
if ! apk info "$pkg" > /dev/null 2>&1; then
|
||||
continue
|
||||
fi
|
||||
|
||||
if ! apt-cache show "$pkg" 2>&1 > /dev/null; then
|
||||
continue
|
||||
fi
|
||||
|
||||
apt-get install "$pkg"
|
||||
apk --no-cache --update add "$pkg"
|
||||
done
|
||||
|
||||
# Remove apt lists
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
}
|
||||
|
||||
|
||||
|
||||
@@ -1,3 +1,6 @@
|
||||
from datetime import datetime
|
||||
|
||||
from django.conf import settings
|
||||
from django.contrib import admin
|
||||
from django.contrib.auth.models import User, Group
|
||||
from django.core.urlresolvers import reverse
|
||||
@@ -31,21 +34,90 @@ class MonthListFilter(admin.SimpleListFilter):
|
||||
return queryset.filter(created__year=year, created__month=month)
|
||||
|
||||
|
||||
class CorrespondentAdmin(admin.ModelAdmin):
|
||||
class FinancialYearFilter(admin.SimpleListFilter):
|
||||
|
||||
title = "Financial Year"
|
||||
parameter_name = "fy"
|
||||
_fy_wraps = None
|
||||
|
||||
def _fy_start(self, year):
|
||||
"""Return date of the start of financial year for the given year."""
|
||||
fy_start = "{}-{}".format(str(year), settings.FY_START)
|
||||
return datetime.strptime(fy_start, "%Y-%m-%d").date()
|
||||
|
||||
def _fy_end(self, year):
|
||||
"""Return date of the end of financial year for the given year."""
|
||||
fy_end = "{}-{}".format(str(year), settings.FY_END)
|
||||
return datetime.strptime(fy_end, "%Y-%m-%d").date()
|
||||
|
||||
def _fy_does_wrap(self):
|
||||
"""Return whether the financial year spans across two years."""
|
||||
if self._fy_wraps is None:
|
||||
start = "{}".format(settings.FY_START)
|
||||
start = datetime.strptime(start, "%m-%d").date()
|
||||
end = "{}".format(settings.FY_END)
|
||||
end = datetime.strptime(end, "%m-%d").date()
|
||||
self._fy_wraps = end < start
|
||||
|
||||
return self._fy_wraps
|
||||
|
||||
def _determine_fy(self, date):
|
||||
"""Return a (query, display) financial year tuple of the given date."""
|
||||
if self._fy_does_wrap():
|
||||
fy_start = self._fy_start(date.year)
|
||||
|
||||
if date.date() >= fy_start:
|
||||
query = "{}-{}".format(date.year, date.year + 1)
|
||||
else:
|
||||
query = "{}-{}".format(date.year - 1, date.year)
|
||||
|
||||
# To keep it simple we use the same string for both
|
||||
# query parameter and the display.
|
||||
return (query, query)
|
||||
|
||||
else:
|
||||
query = "{0}-{0}".format(date.year)
|
||||
display = "{}".format(date.year)
|
||||
return (query, display)
|
||||
|
||||
def lookups(self, request, model_admin):
|
||||
if not settings.FY_START or not settings.FY_END:
|
||||
return None
|
||||
|
||||
r = []
|
||||
for document in Document.objects.all():
|
||||
r.append(self._determine_fy(document.created))
|
||||
|
||||
return sorted(set(r), key=lambda x: x[0], reverse=True)
|
||||
|
||||
def queryset(self, request, queryset):
|
||||
if not self.value() or not settings.FY_START or not settings.FY_END:
|
||||
return None
|
||||
|
||||
start, end = self.value().split("-")
|
||||
return queryset.filter(created__gte=self._fy_start(start),
|
||||
created__lte=self._fy_end(end))
|
||||
|
||||
|
||||
class CommonAdmin(admin.ModelAdmin):
|
||||
list_per_page = settings.PAPERLESS_LIST_PER_PAGE
|
||||
|
||||
|
||||
class CorrespondentAdmin(CommonAdmin):
|
||||
|
||||
list_display = ("name", "match", "matching_algorithm")
|
||||
list_filter = ("matching_algorithm",)
|
||||
list_editable = ("match", "matching_algorithm")
|
||||
|
||||
|
||||
class TagAdmin(admin.ModelAdmin):
|
||||
class TagAdmin(CommonAdmin):
|
||||
|
||||
list_display = ("name", "colour", "match", "matching_algorithm")
|
||||
list_filter = ("colour", "matching_algorithm")
|
||||
list_editable = ("colour", "match", "matching_algorithm")
|
||||
|
||||
|
||||
class DocumentAdmin(admin.ModelAdmin):
|
||||
class DocumentAdmin(CommonAdmin):
|
||||
|
||||
class Media:
|
||||
css = {
|
||||
@@ -53,12 +125,34 @@ class DocumentAdmin(admin.ModelAdmin):
|
||||
}
|
||||
|
||||
search_fields = ("correspondent__name", "title", "content")
|
||||
list_display = ("created", "correspondent", "title", "tags_", "document")
|
||||
list_filter = ("tags", "correspondent", MonthListFilter)
|
||||
list_per_page = 25
|
||||
list_display = ("title", "created", "thumbnail", "correspondent", "tags_")
|
||||
list_filter = ("tags", "correspondent", FinancialYearFilter,
|
||||
MonthListFilter)
|
||||
|
||||
ordering = ["-created", "correspondent"]
|
||||
|
||||
def has_add_permission(self, request):
|
||||
return False
|
||||
|
||||
def created_(self, obj):
|
||||
return obj.created.date().strftime("%Y-%m-%d")
|
||||
created_.short_description = "Created"
|
||||
|
||||
def thumbnail(self, obj):
|
||||
if settings.FORCE_SCRIPT_NAME:
|
||||
src_link = "{}/fetch/thumb/{}".format(
|
||||
settings.FORCE_SCRIPT_NAME, obj.id)
|
||||
else:
|
||||
src_link = "/fetch/thumb/{}".format(obj.id)
|
||||
png_img = self._html_tag(
|
||||
"img",
|
||||
src=src_link,
|
||||
width=180,
|
||||
alt="Thumbnail of {}".format(obj.file_name),
|
||||
title=obj.file_name
|
||||
)
|
||||
return self._html_tag("a", png_img, href=obj.download_url)
|
||||
thumbnail.allow_tags = True
|
||||
|
||||
def tags_(self, obj):
|
||||
r = ""
|
||||
@@ -108,7 +202,7 @@ class DocumentAdmin(admin.ModelAdmin):
|
||||
return "<{} {}/>".format(kind, " ".join(attributes))
|
||||
|
||||
|
||||
class LogAdmin(admin.ModelAdmin):
|
||||
class LogAdmin(CommonAdmin):
|
||||
|
||||
list_display = ("created", "message", "level",)
|
||||
list_filter = ("level", "created",)
|
||||
|
||||
@@ -1,35 +1,21 @@
|
||||
import datetime
|
||||
import hashlib
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import uuid
|
||||
import shutil
|
||||
import hashlib
|
||||
import logging
|
||||
import datetime
|
||||
import tempfile
|
||||
import itertools
|
||||
import subprocess
|
||||
from multiprocessing.pool import Pool
|
||||
|
||||
import pyocr
|
||||
import langdetect
|
||||
from PIL import Image
|
||||
from django.conf import settings
|
||||
from django.utils import timezone
|
||||
from paperless.db import GnuPG
|
||||
from pyocr.tesseract import TesseractError
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
|
||||
from .models import Tag, Document, FileInfo
|
||||
from .models import Document, FileInfo, Tag
|
||||
from .parsers import ParseError
|
||||
from .signals import (
|
||||
document_consumption_started,
|
||||
document_consumption_finished
|
||||
document_consumer_declaration,
|
||||
document_consumption_finished,
|
||||
document_consumption_started
|
||||
)
|
||||
from .languages import ISO639
|
||||
|
||||
|
||||
class OCRError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class ConsumerError(Exception):
|
||||
@@ -47,13 +33,7 @@ class Consumer(object):
|
||||
"""
|
||||
|
||||
SCRATCH = settings.SCRATCH_DIR
|
||||
CONVERT = settings.CONVERT_BINARY
|
||||
UNPAPER = settings.UNPAPER_BINARY
|
||||
CONSUME = settings.CONSUMPTION_DIR
|
||||
THREADS = int(settings.OCR_THREADS) if settings.OCR_THREADS else None
|
||||
DENSITY = settings.CONVERT_DENSITY if settings.CONVERT_DENSITY else 300
|
||||
|
||||
DEFAULT_OCR_LANGUAGE = settings.OCR_LANGUAGE
|
||||
|
||||
def __init__(self):
|
||||
|
||||
@@ -78,6 +58,16 @@ class Consumer(object):
|
||||
raise ConsumerError(
|
||||
"Consumption directory {} does not exist".format(self.CONSUME))
|
||||
|
||||
self.parsers = []
|
||||
for response in document_consumer_declaration.send(self):
|
||||
self.parsers.append(response[1])
|
||||
|
||||
if not self.parsers:
|
||||
raise ConsumerError(
|
||||
"No parsers could be found, not even the default. "
|
||||
"This is a problem."
|
||||
)
|
||||
|
||||
def log(self, level, message):
|
||||
getattr(self.logger, level)(message, extra={
|
||||
"group": self.logging_group
|
||||
@@ -109,6 +99,13 @@ class Consumer(object):
|
||||
self._ignore.append(doc)
|
||||
continue
|
||||
|
||||
parser_class = self._get_parser_class(doc)
|
||||
if not parser_class:
|
||||
self.log(
|
||||
"error", "No parsers could be found for {}".format(doc))
|
||||
self._ignore.append(doc)
|
||||
continue
|
||||
|
||||
self.logging_group = uuid.uuid4()
|
||||
|
||||
self.log("info", "Consuming {}".format(doc))
|
||||
@@ -119,25 +116,28 @@ class Consumer(object):
|
||||
logging_group=self.logging_group
|
||||
)
|
||||
|
||||
tempdir = tempfile.mkdtemp(prefix="paperless", dir=self.SCRATCH)
|
||||
imgs = self._get_greyscale(tempdir, doc)
|
||||
thumbnail = self._get_thumbnail(tempdir, doc)
|
||||
parsed_document = parser_class(doc)
|
||||
thumbnail = parsed_document.get_thumbnail()
|
||||
date = parsed_document.get_date()
|
||||
|
||||
try:
|
||||
|
||||
document = self._store(self._get_ocr(imgs), doc, thumbnail)
|
||||
|
||||
except OCRError as e:
|
||||
document = self._store(
|
||||
parsed_document.get_text(),
|
||||
doc,
|
||||
thumbnail,
|
||||
date
|
||||
)
|
||||
except ParseError as e:
|
||||
|
||||
self._ignore.append(doc)
|
||||
self.log("error", "OCR FAILURE for {}: {}".format(doc, e))
|
||||
self._cleanup_tempdir(tempdir)
|
||||
self.log("error", "PARSE FAILURE for {}: {}".format(doc, e))
|
||||
parsed_document.cleanup()
|
||||
|
||||
continue
|
||||
|
||||
else:
|
||||
|
||||
self._cleanup_tempdir(tempdir)
|
||||
parsed_document.cleanup()
|
||||
self._cleanup_doc(doc)
|
||||
|
||||
self.log(
|
||||
@@ -151,144 +151,32 @@ class Consumer(object):
|
||||
logging_group=self.logging_group
|
||||
)
|
||||
|
||||
def _get_greyscale(self, tempdir, doc):
|
||||
def _get_parser_class(self, doc):
|
||||
"""
|
||||
Greyscale images are easier for Tesseract to OCR
|
||||
Determine the appropriate parser class based on the file
|
||||
"""
|
||||
|
||||
self.log("info", "Generating greyscale image from {}".format(doc))
|
||||
options = []
|
||||
for parser in self.parsers:
|
||||
result = parser(doc)
|
||||
if result:
|
||||
options.append(result)
|
||||
|
||||
# Convert PDF to multiple PNMs
|
||||
pnm = os.path.join(tempdir, "convert-%04d.pnm")
|
||||
run_convert(
|
||||
self.CONVERT,
|
||||
"-density", str(self.DENSITY),
|
||||
"-depth", "8",
|
||||
"-type", "grayscale",
|
||||
doc, pnm,
|
||||
)
|
||||
|
||||
# Get a list of converted images
|
||||
pnms = []
|
||||
for f in os.listdir(tempdir):
|
||||
if f.endswith(".pnm"):
|
||||
pnms.append(os.path.join(tempdir, f))
|
||||
|
||||
# Run unpaper in parallel on converted images
|
||||
with Pool(processes=self.THREADS) as pool:
|
||||
pool.map(run_unpaper, itertools.product([self.UNPAPER], pnms))
|
||||
|
||||
# Return list of converted images, processed with unpaper
|
||||
pnms = []
|
||||
for f in os.listdir(tempdir):
|
||||
if f.endswith(".unpaper.pnm"):
|
||||
pnms.append(os.path.join(tempdir, f))
|
||||
|
||||
return sorted(filter(lambda __: os.path.isfile(__), pnms))
|
||||
|
||||
def _get_thumbnail(self, tempdir, doc):
|
||||
"""
|
||||
The thumbnail of a PDF is just a 500px wide image of the first page.
|
||||
"""
|
||||
|
||||
self.log("info", "Generating the thumbnail")
|
||||
|
||||
run_convert(
|
||||
self.CONVERT,
|
||||
"-scale", "500x5000",
|
||||
"-alpha", "remove",
|
||||
doc, os.path.join(tempdir, "convert-%04d.png")
|
||||
)
|
||||
|
||||
return os.path.join(tempdir, "convert-0000.png")
|
||||
|
||||
def _guess_language(self, text):
|
||||
try:
|
||||
guess = langdetect.detect(text)
|
||||
self.log("debug", "Language detected: {}".format(guess))
|
||||
return guess
|
||||
except Exception as e:
|
||||
self.log("warning", "Language detection error: {}".format(e))
|
||||
|
||||
def _get_ocr(self, imgs):
|
||||
"""
|
||||
Attempts to do the best job possible OCR'ing the document based on
|
||||
simple language detection trial & error.
|
||||
"""
|
||||
|
||||
if not imgs:
|
||||
raise OCRError("No images found")
|
||||
|
||||
self.log("info", "OCRing the document")
|
||||
|
||||
# Since the division gets rounded down by int, this calculation works
|
||||
# for every edge-case, i.e. 1
|
||||
middle = int(len(imgs) / 2)
|
||||
raw_text = self._ocr([imgs[middle]], self.DEFAULT_OCR_LANGUAGE)
|
||||
|
||||
guessed_language = self._guess_language(raw_text)
|
||||
|
||||
if not guessed_language or guessed_language not in ISO639:
|
||||
self.log("warning", "Language detection failed!")
|
||||
if settings.FORGIVING_OCR:
|
||||
self.log(
|
||||
"warning",
|
||||
"As FORGIVING_OCR is enabled, we're going to make the "
|
||||
"best with what we have."
|
||||
)
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
raise OCRError("Language detection failed")
|
||||
|
||||
if ISO639[guessed_language] == self.DEFAULT_OCR_LANGUAGE:
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
|
||||
try:
|
||||
return self._ocr(imgs, ISO639[guessed_language])
|
||||
except pyocr.pyocr.tesseract.TesseractError:
|
||||
if settings.FORGIVING_OCR:
|
||||
self.log(
|
||||
"warning",
|
||||
"OCR for {} failed, but we're going to stick with what "
|
||||
"we've got since FORGIVING_OCR is enabled.".format(
|
||||
guessed_language
|
||||
)
|
||||
)
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
raise OCRError(
|
||||
"The guessed language is not available in this instance of "
|
||||
"Tesseract."
|
||||
self.log(
|
||||
"info",
|
||||
"Parsers available: {}".format(
|
||||
", ".join([str(o["parser"].__name__) for o in options])
|
||||
)
|
||||
)
|
||||
|
||||
def _assemble_ocr_sections(self, imgs, middle, text):
|
||||
"""
|
||||
Given a `middle` value and the text that middle page represents, we OCR
|
||||
the remainder of the document and return the whole thing.
|
||||
"""
|
||||
text = self._ocr(imgs[:middle], self.DEFAULT_OCR_LANGUAGE) + text
|
||||
text += self._ocr(imgs[middle + 1:], self.DEFAULT_OCR_LANGUAGE)
|
||||
return text
|
||||
if not options:
|
||||
return None
|
||||
|
||||
def _ocr(self, imgs, lang):
|
||||
"""
|
||||
Performs a single OCR attempt.
|
||||
"""
|
||||
# Return the parser with the highest weight.
|
||||
return sorted(
|
||||
options, key=lambda _: _["weight"], reverse=True)[0]["parser"]
|
||||
|
||||
if not imgs:
|
||||
return ""
|
||||
|
||||
self.log("info", "Parsing for {}".format(lang))
|
||||
|
||||
with Pool(processes=self.THREADS) as pool:
|
||||
r = pool.map(image_to_string, itertools.product(imgs, [lang]))
|
||||
r = " ".join(r)
|
||||
|
||||
# Strip out excess white space to allow matching to go smoother
|
||||
return strip_excess_whitespace(r)
|
||||
|
||||
def _store(self, text, doc, thumbnail):
|
||||
def _store(self, text, doc, thumbnail, date):
|
||||
|
||||
file_info = FileInfo.from_path(doc)
|
||||
|
||||
@@ -296,7 +184,7 @@ class Consumer(object):
|
||||
|
||||
self.log("debug", "Saving record to database")
|
||||
|
||||
created = file_info.created or timezone.make_aware(
|
||||
created = file_info.created or date or timezone.make_aware(
|
||||
datetime.datetime.fromtimestamp(stats.st_mtime))
|
||||
|
||||
with open(doc, "rb") as f:
|
||||
@@ -332,10 +220,6 @@ class Consumer(object):
|
||||
|
||||
return document
|
||||
|
||||
def _cleanup_tempdir(self, d):
|
||||
self.log("debug", "Deleting directory {}".format(d))
|
||||
shutil.rmtree(d)
|
||||
|
||||
def _cleanup_doc(self, doc):
|
||||
self.log("debug", "Deleting document {}".format(doc))
|
||||
os.unlink(doc)
|
||||
@@ -361,41 +245,3 @@ class Consumer(object):
|
||||
with open(doc, "rb") as f:
|
||||
checksum = hashlib.md5(f.read()).hexdigest()
|
||||
return Document.objects.filter(checksum=checksum).exists()
|
||||
|
||||
|
||||
def strip_excess_whitespace(text):
|
||||
collapsed_spaces = re.sub(r"([^\S\r\n]+)", " ", text)
|
||||
no_leading_whitespace = re.sub(
|
||||
"([\n\r]+)([^\S\n\r]+)", '\\1', collapsed_spaces)
|
||||
no_trailing_whitespace = re.sub("([^\S\n\r]+)$", '', no_leading_whitespace)
|
||||
return no_trailing_whitespace
|
||||
|
||||
|
||||
def image_to_string(args):
|
||||
img, lang = args
|
||||
ocr = pyocr.get_available_tools()[0]
|
||||
with Image.open(os.path.join(Consumer.SCRATCH, img)) as f:
|
||||
if ocr.can_detect_orientation():
|
||||
try:
|
||||
orientation = ocr.detect_orientation(f, lang=lang)
|
||||
f = f.rotate(orientation["angle"], expand=1)
|
||||
except (TesseractError, OtherTesseractError):
|
||||
pass
|
||||
return ocr.image_to_string(f, lang=lang)
|
||||
|
||||
|
||||
def run_unpaper(args):
|
||||
unpaper, pnm = args
|
||||
subprocess.Popen(
|
||||
(unpaper, pnm, pnm.replace(".pnm", ".unpaper.pnm"))).wait()
|
||||
|
||||
|
||||
def run_convert(*args):
|
||||
|
||||
environment = os.environ.copy()
|
||||
if settings.CONVERT_MEMORY_LIMIT:
|
||||
environment["MAGICK_MEMORY_LIMIT"] = settings.CONVERT_MEMORY_LIMIT
|
||||
if settings.CONVERT_TMPDIR:
|
||||
environment["MAGICK_TMPDIR"] = settings.CONVERT_TMPDIR
|
||||
|
||||
subprocess.Popen(args, env=environment).wait()
|
||||
|
||||
@@ -8,7 +8,7 @@ class CorrespondentFilterSet(FilterSet):
|
||||
class Meta(object):
|
||||
model = Correspondent
|
||||
fields = {
|
||||
'name': [
|
||||
"name": [
|
||||
"startswith", "endswith", "contains",
|
||||
"istartswith", "iendswith", "icontains"
|
||||
],
|
||||
@@ -21,7 +21,7 @@ class TagFilterSet(FilterSet):
|
||||
class Meta(object):
|
||||
model = Tag
|
||||
fields = {
|
||||
'name': [
|
||||
"name": [
|
||||
"startswith", "endswith", "contains",
|
||||
"istartswith", "iendswith", "icontains"
|
||||
],
|
||||
|
||||
@@ -2,7 +2,6 @@ import magic
|
||||
import os
|
||||
|
||||
from datetime import datetime
|
||||
from hashlib import sha256
|
||||
from time import mktime
|
||||
|
||||
from django import forms
|
||||
@@ -14,7 +13,6 @@ from .consumer import Consumer
|
||||
|
||||
class UploadForm(forms.Form):
|
||||
|
||||
SECRET = settings.SHARED_SECRET
|
||||
TYPE_LOOKUP = {
|
||||
"application/pdf": Document.TYPE_PDF,
|
||||
"image/png": Document.TYPE_PNG,
|
||||
@@ -32,10 +30,9 @@ class UploadForm(forms.Form):
|
||||
required=False
|
||||
)
|
||||
document = forms.FileField()
|
||||
signature = forms.CharField(max_length=256)
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
forms.Form.__init__(*args, **kwargs)
|
||||
forms.Form.__init__(self, *args, **kwargs)
|
||||
self._file_type = None
|
||||
|
||||
def clean_correspondent(self):
|
||||
@@ -82,17 +79,6 @@ class UploadForm(forms.Form):
|
||||
|
||||
return document
|
||||
|
||||
def clean(self):
|
||||
|
||||
corresp = self.clened_data.get("correspondent")
|
||||
title = self.cleaned_data.get("title")
|
||||
signature = self.cleaned_data.get("signature")
|
||||
|
||||
if sha256(corresp + title + self.SECRET).hexdigest() == signature:
|
||||
return self.cleaned_data
|
||||
|
||||
raise forms.ValidationError("The signature provided did not validate")
|
||||
|
||||
def save(self):
|
||||
"""
|
||||
Since the consumer already does a lot of work, it's easier just to save
|
||||
@@ -100,11 +86,11 @@ class UploadForm(forms.Form):
|
||||
form do that as well. Think of it as a poor-man's queue server.
|
||||
"""
|
||||
|
||||
correspondent = self.clened_data.get("correspondent")
|
||||
correspondent = self.cleaned_data.get("correspondent")
|
||||
title = self.cleaned_data.get("title")
|
||||
document = self.cleaned_data.get("document")
|
||||
|
||||
t = int(mktime(datetime.now()))
|
||||
t = int(mktime(datetime.now().timetuple()))
|
||||
file_name = os.path.join(
|
||||
Consumer.CONSUME,
|
||||
"{} - {}.{}".format(correspondent, title, self._file_type)
|
||||
|
||||
@@ -43,7 +43,10 @@ class Message(Loggable):
|
||||
and n attachments, and that we don't care about the message body.
|
||||
"""
|
||||
|
||||
SECRET = settings.SHARED_SECRET
|
||||
SECRET = os.getenv(
|
||||
"PAPERLESS_EMAIL_SECRET",
|
||||
os.getenv("PAPERLESS_SHARED_SECRET") # TODO: Remove after 2017/09
|
||||
)
|
||||
|
||||
def __init__(self, data, group=None):
|
||||
"""
|
||||
@@ -153,11 +156,11 @@ class MailFetcher(Loggable):
|
||||
Loggable.__init__(self)
|
||||
|
||||
self._connection = None
|
||||
self._host = settings.MAIL_CONSUMPTION["HOST"]
|
||||
self._port = settings.MAIL_CONSUMPTION["PORT"]
|
||||
self._username = settings.MAIL_CONSUMPTION["USERNAME"]
|
||||
self._password = settings.MAIL_CONSUMPTION["PASSWORD"]
|
||||
self._inbox = settings.MAIL_CONSUMPTION["INBOX"]
|
||||
self._host = os.getenv("PAPERLESS_CONSUME_MAIL_HOST")
|
||||
self._port = os.getenv("PAPERLESS_CONSUME_MAIL_PORT")
|
||||
self._username = os.getenv("PAPERLESS_CONSUME_MAIL_USER")
|
||||
self._password = os.getenv("PAPERLESS_CONSUME_MAIL_PASS")
|
||||
self._inbox = os.getenv("PAPERLESS_CONSUME_MAIL_INBOX", "INBOX")
|
||||
|
||||
self._enabled = bool(self._host)
|
||||
|
||||
@@ -219,7 +222,7 @@ class MailFetcher(Loggable):
|
||||
if not login[0] == "OK":
|
||||
raise MailFetcherError("Can't log into mail: {}".format(login[1]))
|
||||
|
||||
inbox = self._connection.select("INBOX")
|
||||
inbox = self._connection.select(self._inbox)
|
||||
if not inbox[0] == "OK":
|
||||
raise MailFetcherError("Can't find the inbox: {}".format(inbox[1]))
|
||||
|
||||
|
||||
@@ -28,6 +28,7 @@ class Command(BaseCommand):
|
||||
|
||||
self.file_consumer = None
|
||||
self.mail_fetcher = None
|
||||
self.first_iteration = True
|
||||
|
||||
BaseCommand.__init__(self, *args, **kwargs)
|
||||
|
||||
@@ -66,6 +67,9 @@ class Command(BaseCommand):
|
||||
self.file_consumer.consume()
|
||||
|
||||
# Occasionally fetch mail and store it to be consumed on the next loop
|
||||
# We fetch email when we first start up so that it is not necessary to
|
||||
# wait for 10 minutes after making changes to the config file.
|
||||
delta = self.mail_fetcher.last_checked + self.MAIL_DELTA
|
||||
if delta < datetime.datetime.now():
|
||||
if self.first_iteration or delta < datetime.datetime.now():
|
||||
self.first_iteration = False
|
||||
self.mail_fetcher.pull()
|
||||
|
||||
@@ -10,6 +10,7 @@ from documents.models import Document, Correspondent, Tag
|
||||
from paperless.db import GnuPG
|
||||
|
||||
from ...mixins import Renderable
|
||||
from documents.settings import EXPORTER_FILE_NAME, EXPORTER_THUMBNAIL_NAME
|
||||
|
||||
|
||||
class Command(Renderable, BaseCommand):
|
||||
@@ -61,15 +62,24 @@ class Command(Renderable, BaseCommand):
|
||||
|
||||
document = document_map[document_dict["pk"]]
|
||||
|
||||
target = os.path.join(self.target, document.file_name)
|
||||
document_dict["__exported_file_name__"] = target
|
||||
file_target = os.path.join(self.target, document.file_name)
|
||||
|
||||
print("Exporting: {}".format(target))
|
||||
thumbnail_name = document.file_name + "-thumbnail.png"
|
||||
thumbnail_target = os.path.join(self.target, thumbnail_name)
|
||||
|
||||
with open(target, "wb") as f:
|
||||
document_dict[EXPORTER_FILE_NAME] = document.file_name
|
||||
document_dict[EXPORTER_THUMBNAIL_NAME] = thumbnail_name
|
||||
|
||||
print("Exporting: {}".format(file_target))
|
||||
|
||||
t = int(time.mktime(document.created.timetuple()))
|
||||
with open(file_target, "wb") as f:
|
||||
f.write(GnuPG.decrypted(document.source_file))
|
||||
t = int(time.mktime(document.created.timetuple()))
|
||||
os.utime(target, times=(t, t))
|
||||
os.utime(file_target, times=(t, t))
|
||||
|
||||
with open(thumbnail_target, "wb") as f:
|
||||
f.write(GnuPG.decrypted(document.thumbnail_file))
|
||||
os.utime(thumbnail_target, times=(t, t))
|
||||
|
||||
manifest += json.loads(
|
||||
serializers.serialize("json", Correspondent.objects.all()))
|
||||
|
||||
@@ -10,6 +10,8 @@ from paperless.db import GnuPG
|
||||
|
||||
from ...mixins import Renderable
|
||||
|
||||
from documents.settings import EXPORTER_FILE_NAME, EXPORTER_THUMBNAIL_NAME
|
||||
|
||||
|
||||
class Command(Renderable, BaseCommand):
|
||||
|
||||
@@ -70,13 +72,13 @@ class Command(Renderable, BaseCommand):
|
||||
if not record["model"] == "documents.document":
|
||||
continue
|
||||
|
||||
if "__exported_file_name__" not in record:
|
||||
if EXPORTER_FILE_NAME not in record:
|
||||
raise CommandError(
|
||||
'The manifest file contains a record which does not '
|
||||
'refer to an actual document file.'
|
||||
)
|
||||
|
||||
doc_file = record["__exported_file_name__"]
|
||||
doc_file = record[EXPORTER_FILE_NAME]
|
||||
if not os.path.exists(os.path.join(self.source, doc_file)):
|
||||
raise CommandError(
|
||||
'The manifest file refers to "{}" which does not '
|
||||
@@ -90,10 +92,21 @@ class Command(Renderable, BaseCommand):
|
||||
if not record["model"] == "documents.document":
|
||||
continue
|
||||
|
||||
doc_file = record["__exported_file_name__"]
|
||||
doc_file = record[EXPORTER_FILE_NAME]
|
||||
thumb_file = record[EXPORTER_THUMBNAIL_NAME]
|
||||
document = Document.objects.get(pk=record["pk"])
|
||||
with open(doc_file, "rb") as unencrypted:
|
||||
|
||||
document_path = os.path.join(self.source, doc_file)
|
||||
thumbnail_path = os.path.join(self.source, thumb_file)
|
||||
|
||||
with open(document_path, "rb") as unencrypted:
|
||||
with open(document.source_path, "wb") as encrypted:
|
||||
print("Encrypting {} and saving it to {}".format(
|
||||
doc_file, document.source_path))
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
|
||||
with open(thumbnail_path, "rb") as unencrypted:
|
||||
with open(document.thumbnail_path, "wb") as encrypted:
|
||||
print("Encrypting {} and saving it to {}".format(
|
||||
thumb_file, document.thumbnail_path))
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
|
||||
@@ -50,7 +50,7 @@ class GroupConcat(models.Aggregate):
|
||||
|
||||
def _get_template(self, separator):
|
||||
if self.engine == self.ENGINE_MYSQL:
|
||||
return "%(function)s(%(expressions)s, SEPARATOR '{}')".format(
|
||||
return "%(function)s(%(expressions)s SEPARATOR '{}')".format(
|
||||
separator)
|
||||
return "%(function)s(%(expressions)s, '{}')".format(separator)
|
||||
|
||||
|
||||
@@ -3,6 +3,7 @@
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
@@ -19,7 +20,7 @@ class Migration(migrations.Migration):
|
||||
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
|
||||
('sender', models.CharField(blank=True, db_index=True, max_length=128)),
|
||||
('title', models.CharField(blank=True, db_index=True, max_length=128)),
|
||||
('content', models.TextField(db_index=True)),
|
||||
('content', models.TextField(db_index=("mysql" not in settings.DATABASES["default"]["ENGINE"]))),
|
||||
('created', models.DateTimeField(auto_now_add=True)),
|
||||
('modified', models.DateTimeField(auto_now=True)),
|
||||
],
|
||||
|
||||
@@ -47,7 +47,11 @@ class Migration(migrations.Migration):
|
||||
],
|
||||
),
|
||||
migrations.RunPython(move_sender_strings_to_sender_model),
|
||||
migrations.AlterField(
|
||||
migrations.RemoveField(
|
||||
model_name='document',
|
||||
name='sender',
|
||||
),
|
||||
migrations.AddField(
|
||||
model_name='document',
|
||||
name='sender',
|
||||
field=models.ForeignKey(blank=True, on_delete=django.db.models.deletion.CASCADE, to='documents.Sender'),
|
||||
|
||||
@@ -38,6 +38,9 @@ class GnuPG(object):
|
||||
|
||||
def move_documents_and_create_thumbnails(apps, schema_editor):
|
||||
|
||||
os.makedirs(os.path.join(settings.MEDIA_ROOT, "documents", "originals"), exist_ok=True)
|
||||
os.makedirs(os.path.join(settings.MEDIA_ROOT, "documents", "thumbnails"), exist_ok=True)
|
||||
|
||||
documents = os.listdir(os.path.join(settings.MEDIA_ROOT, "documents"))
|
||||
|
||||
if set(documents) == {"originals", "thumbnails"}:
|
||||
|
||||
20
src/documents/migrations/0016_auto_20170325_1558.py
Normal file
@@ -0,0 +1,20 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-03-25 15:58
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0015_add_insensitive_to_match'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='content',
|
||||
field=models.TextField(blank=True, db_index=True, help_text='The raw, text-only data of the document. This field is primarily used for searching.'),
|
||||
),
|
||||
]
|
||||
25
src/documents/migrations/0017_auto_20170512_0507.py
Normal file
@@ -0,0 +1,25 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-05-12 05:07
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0016_auto_20170325_1558'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='correspondent',
|
||||
name='matching_algorithm',
|
||||
field=models.PositiveIntegerField(choices=[(1, 'Any'), (2, 'All'), (3, 'Literal'), (4, 'Regular Expression'), (5, 'Fuzzy Match')], default=1, help_text='Which algorithm you want to use when matching text to the OCR\'d PDF. Here, "any" looks for any occurrence of any word provided in the PDF, while "all" requires that every word provided appear in the PDF, albeit not in the order provided. A "literal" match means that the text you enter must appear in the PDF exactly as you\'ve entered it, and "regular expression" uses a regex to match the PDF. (If you don\'t know what a regex is, you probably don\'t want this option.) Finally, a "fuzzy match" looks for words or phrases that are mostly—but not exactly—the same, which can be useful for matching against documents containg imperfections that foil accurate OCR.'),
|
||||
),
|
||||
migrations.AlterField(
|
||||
model_name='tag',
|
||||
name='matching_algorithm',
|
||||
field=models.PositiveIntegerField(choices=[(1, 'Any'), (2, 'All'), (3, 'Literal'), (4, 'Regular Expression'), (5, 'Fuzzy Match')], default=1, help_text='Which algorithm you want to use when matching text to the OCR\'d PDF. Here, "any" looks for any occurrence of any word provided in the PDF, while "all" requires that every word provided appear in the PDF, albeit not in the order provided. A "literal" match means that the text you enter must appear in the PDF exactly as you\'ve entered it, and "regular expression" uses a regex to match the PDF. (If you don\'t know what a regex is, you probably don\'t want this option.) Finally, a "fuzzy match" looks for words or phrases that are mostly—but not exactly—the same, which can be useful for matching against documents containg imperfections that foil accurate OCR.'),
|
||||
),
|
||||
]
|
||||
21
src/documents/migrations/0018_auto_20170715_1712.py
Normal file
@@ -0,0 +1,21 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-07-15 17:12
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
import django.db.models.deletion
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0017_auto_20170512_0507'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='correspondent',
|
||||
field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, related_name='documents', to='documents.Correspondent'),
|
||||
),
|
||||
]
|
||||
@@ -1,3 +1,5 @@
|
||||
# coding=utf-8
|
||||
|
||||
import dateutil.parser
|
||||
import logging
|
||||
import os
|
||||
@@ -5,6 +7,7 @@ import re
|
||||
import uuid
|
||||
|
||||
from collections import OrderedDict
|
||||
from fuzzywuzzy import fuzz
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.urlresolvers import reverse
|
||||
@@ -21,11 +24,13 @@ class MatchingModel(models.Model):
|
||||
MATCH_ALL = 2
|
||||
MATCH_LITERAL = 3
|
||||
MATCH_REGEX = 4
|
||||
MATCH_FUZZY = 5
|
||||
MATCHING_ALGORITHMS = (
|
||||
(MATCH_ANY, "Any"),
|
||||
(MATCH_ALL, "All"),
|
||||
(MATCH_LITERAL, "Literal"),
|
||||
(MATCH_REGEX, "Regular Expression"),
|
||||
(MATCH_FUZZY, "Fuzzy Match"),
|
||||
)
|
||||
|
||||
name = models.CharField(max_length=128, unique=True)
|
||||
@@ -42,8 +47,11 @@ class MatchingModel(models.Model):
|
||||
"provided appear in the PDF, albeit not in the order provided. A "
|
||||
"\"literal\" match means that the text you enter must appear in "
|
||||
"the PDF exactly as you've entered it, and \"regular expression\" "
|
||||
"uses a regex to match the PDF. If you don't know what a regex "
|
||||
"is, you probably don't want this option."
|
||||
"uses a regex to match the PDF. (If you don't know what a regex "
|
||||
"is, you probably don't want this option.) Finally, a \"fuzzy "
|
||||
"match\" looks for words or phrases that are mostly—but not "
|
||||
"exactly—the same, which can be useful for matching against "
|
||||
"documents containg imperfections that foil accurate OCR."
|
||||
)
|
||||
)
|
||||
|
||||
@@ -83,7 +91,7 @@ class MatchingModel(models.Model):
|
||||
search_kwargs = {"flags": re.IGNORECASE}
|
||||
|
||||
if self.matching_algorithm == self.MATCH_ALL:
|
||||
for word in self.match.split(" "):
|
||||
for word in self._split_match():
|
||||
search_result = re.search(
|
||||
r"\b{}\b".format(word), text, **search_kwargs)
|
||||
if not search_result:
|
||||
@@ -91,7 +99,7 @@ class MatchingModel(models.Model):
|
||||
return True
|
||||
|
||||
if self.matching_algorithm == self.MATCH_ANY:
|
||||
for word in self.match.split(" "):
|
||||
for word in self._split_match():
|
||||
if re.search(r"\b{}\b".format(word), text, **search_kwargs):
|
||||
return True
|
||||
return False
|
||||
@@ -104,8 +112,34 @@ class MatchingModel(models.Model):
|
||||
return bool(re.search(
|
||||
re.compile(self.match, **search_kwargs), text))
|
||||
|
||||
if self.matching_algorithm == self.MATCH_FUZZY:
|
||||
match = re.sub(r'[^\w\s]', '', self.match)
|
||||
text = re.sub(r'[^\w\s]', '', text)
|
||||
if self.is_insensitive:
|
||||
match = match.lower()
|
||||
text = text.lower()
|
||||
|
||||
return True if fuzz.partial_ratio(match, text) >= 90 else False
|
||||
|
||||
raise NotImplementedError("Unsupported matching algorithm")
|
||||
|
||||
def _split_match(self):
|
||||
"""
|
||||
Splits the match to individual keywords, getting rid of unnecessary
|
||||
spaces and grouping quoted words together.
|
||||
|
||||
Example:
|
||||
' some random words "with quotes " and spaces'
|
||||
==>
|
||||
["some", "random", "words", "with\s+quotes", "and", "spaces"]
|
||||
"""
|
||||
findterms = re.compile(r'"([^"]+)"|(\S+)').findall
|
||||
normspace = re.compile(r"\s+").sub
|
||||
return [
|
||||
normspace(" ", (t[0] or t[1]).strip()).replace(" ", r"\s+")
|
||||
for t in findterms(self.match)
|
||||
]
|
||||
|
||||
def save(self, *args, **kwargs):
|
||||
|
||||
self.match = self.match.lower()
|
||||
@@ -157,14 +191,28 @@ class Document(models.Model):
|
||||
TYPES = (TYPE_PDF, TYPE_PNG, TYPE_JPG, TYPE_GIF, TYPE_TIF,)
|
||||
|
||||
correspondent = models.ForeignKey(
|
||||
Correspondent, blank=True, null=True, related_name="documents")
|
||||
Correspondent,
|
||||
blank=True,
|
||||
null=True,
|
||||
related_name="documents",
|
||||
on_delete=models.SET_NULL
|
||||
)
|
||||
|
||||
title = models.CharField(max_length=128, blank=True, db_index=True)
|
||||
content = models.TextField(db_index=True)
|
||||
|
||||
content = models.TextField(
|
||||
db_index=True,
|
||||
blank=True,
|
||||
help_text="The raw, text-only data of the document. This field is "
|
||||
"primarily used for searching."
|
||||
)
|
||||
|
||||
file_type = models.CharField(
|
||||
max_length=4,
|
||||
editable=False,
|
||||
choices=tuple([(t, t.upper()) for t in TYPES])
|
||||
)
|
||||
|
||||
tags = models.ManyToManyField(
|
||||
Tag, related_name="documents", blank=True)
|
||||
|
||||
@@ -292,45 +340,45 @@ class FileInfo(object):
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*) - "
|
||||
r"(?P<tags>[a-z0-9\-,]*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("created-title-tags", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<title>.*) - "
|
||||
r"(?P<tags>[a-z0-9\-,]*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("created-correspondent-title", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("created-title", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<title>.*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("correspondent-title-tags", re.compile(
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*) - "
|
||||
r"(?P<tags>[a-z0-9\-,]*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("correspondent-title", re.compile(
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*)?"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("title", re.compile(
|
||||
r"(?P<title>.*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff?)$",
|
||||
flags=re.IGNORECASE
|
||||
))
|
||||
])
|
||||
@@ -373,6 +421,8 @@ class FileInfo(object):
|
||||
r = extension.lower()
|
||||
if r == "jpeg":
|
||||
return "jpg"
|
||||
if r == "tif":
|
||||
return "tiff"
|
||||
return r
|
||||
|
||||
@classmethod
|
||||
|
||||
51
src/documents/parsers.py
Normal file
@@ -0,0 +1,51 @@
|
||||
import logging
|
||||
import shutil
|
||||
import tempfile
|
||||
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class ParseError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class DocumentParser:
|
||||
"""
|
||||
Subclass this to make your own parser. Have a look at
|
||||
`paperless_tesseract.parsers` for inspiration.
|
||||
"""
|
||||
|
||||
SCRATCH = settings.SCRATCH_DIR
|
||||
|
||||
def __init__(self, path):
|
||||
self.document_path = path
|
||||
self.tempdir = tempfile.mkdtemp(prefix="paperless-", dir=self.SCRATCH)
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.logging_group = None
|
||||
|
||||
def get_thumbnail(self):
|
||||
"""
|
||||
Returns the path to a file we can use as a thumbnail for this document.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def get_text(self):
|
||||
"""
|
||||
Returns the text from the document and only the text.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def get_date(self):
|
||||
"""
|
||||
Returns the date of the document.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def log(self, level, message):
|
||||
getattr(self.logger, level)(message, extra={
|
||||
"group": self.logging_group
|
||||
})
|
||||
|
||||
def cleanup(self):
|
||||
self.log("debug", "Deleting directory {}".format(self.tempdir))
|
||||
shutil.rmtree(self.tempdir)
|
||||
@@ -18,12 +18,21 @@ class TagSerializer(serializers.HyperlinkedModelSerializer):
|
||||
"id", "slug", "name", "colour", "match", "matching_algorithm")
|
||||
|
||||
|
||||
class CorrespondentField(serializers.HyperlinkedRelatedField):
|
||||
def get_queryset(self):
|
||||
return Correspondent.objects.all()
|
||||
|
||||
|
||||
class TagsField(serializers.HyperlinkedRelatedField):
|
||||
def get_queryset(self):
|
||||
return Tag.objects.all()
|
||||
|
||||
|
||||
class DocumentSerializer(serializers.ModelSerializer):
|
||||
|
||||
correspondent = serializers.HyperlinkedRelatedField(
|
||||
read_only=True, view_name="drf:correspondent-detail", allow_null=True)
|
||||
tags = serializers.HyperlinkedRelatedField(
|
||||
read_only=True, view_name="drf:tag-detail", many=True)
|
||||
correspondent = CorrespondentField(
|
||||
view_name="drf:correspondent-detail", allow_null=True)
|
||||
tags = TagsField(view_name="drf:tag-detail", many=True)
|
||||
|
||||
class Meta(object):
|
||||
model = Document
|
||||
|
||||
4
src/documents/settings.py
Normal file
@@ -0,0 +1,4 @@
|
||||
# Defines the names of file/thumbnail for the manifest
|
||||
# for exporting/importing commands
|
||||
EXPORTER_FILE_NAME = "__exported_file_name__"
|
||||
EXPORTER_THUMBNAIL_NAME = "__exported_thumbnail_name__"
|
||||
@@ -2,3 +2,4 @@ from django.dispatch import Signal
|
||||
|
||||
document_consumption_started = Signal(providing_args=["filename"])
|
||||
document_consumption_finished = Signal(providing_args=["document"])
|
||||
document_consumer_declaration = Signal(providing_args=[])
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
import logging
|
||||
import os
|
||||
|
||||
from subprocess import Popen
|
||||
|
||||
from django.conf import settings
|
||||
|
||||
@@ -10,3 +10,14 @@ td a.tag {
|
||||
margin: 1px;
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
#result_list th.column-note {
|
||||
text-align: right;
|
||||
}
|
||||
#result_list td.field-note {
|
||||
text-align: right;
|
||||
}
|
||||
#result_list td textarea {
|
||||
width: 90%;
|
||||
height: 5em;
|
||||
}
|
||||
@@ -0,0 +1,13 @@
|
||||
{% extends 'admin/change_form.html' %}
|
||||
|
||||
|
||||
{% block footer %}
|
||||
|
||||
{{ block.super }}
|
||||
|
||||
{# Hack to force Django to make the created date a date input rather than `text` (the default) #}
|
||||
<script>
|
||||
django.jQuery(".field-created input").first().attr("type", "date")
|
||||
</script>
|
||||
|
||||
{% endblock footer %}
|
||||
@@ -0,0 +1,12 @@
|
||||
{% extends 'admin/change_list.html' %}
|
||||
|
||||
|
||||
{% load admin_actions from admin_list%}
|
||||
{% load result_list from hacks %}
|
||||
|
||||
|
||||
{% block result_list %}
|
||||
{% if action_form and actions_on_top and cl.show_admin_actions %}{% admin_actions %}{% endif %}
|
||||
{% result_list cl %}
|
||||
{% if action_form and actions_on_bottom and cl.show_admin_actions %}{% admin_actions %}{% endif %}
|
||||
{% endblock %}
|
||||
@@ -0,0 +1,162 @@
|
||||
{% load i18n %}
|
||||
|
||||
<style>
|
||||
.grid *, .grid *:after, .grid *:before {
|
||||
-webkit-box-sizing: border-box;
|
||||
-moz-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
.box {
|
||||
width: 12.5%;
|
||||
padding: 1em;
|
||||
float: left;
|
||||
opacity: 0.7;
|
||||
transition: all 0.5s;
|
||||
}
|
||||
.box:hover {
|
||||
opacity: 1;
|
||||
transition: all 0.5s;
|
||||
}
|
||||
.box:last-of-type {
|
||||
padding-right: 0;
|
||||
}
|
||||
.result {
|
||||
border: 1px solid #cccccc;
|
||||
border-radius: 2%;
|
||||
overflow: hidden;
|
||||
height: 300px;
|
||||
}
|
||||
.result .header {
|
||||
padding: 5px;
|
||||
background-color: #79AEC8;
|
||||
}
|
||||
.result .header .checkbox{
|
||||
width: 5%;
|
||||
float: left;
|
||||
}
|
||||
.result .header .info {
|
||||
margin-left: 10%;
|
||||
}
|
||||
.result .header a,
|
||||
.result a.tag {
|
||||
color: #ffffff;
|
||||
}
|
||||
.result .date {
|
||||
padding: 5px;
|
||||
}
|
||||
.result .tags {
|
||||
float: left;
|
||||
}
|
||||
.result .tags a.tag {
|
||||
padding: 2px 5px;
|
||||
border-radius: 2px;
|
||||
display: inline-block;
|
||||
margin: 2px;
|
||||
}
|
||||
.result .date {
|
||||
float: right;
|
||||
color: #cccccc;
|
||||
}
|
||||
.result .image img {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.grid {
|
||||
margin-right: 260px;
|
||||
}
|
||||
.grid:after {
|
||||
content: "";
|
||||
display: table;
|
||||
clear: both;
|
||||
}
|
||||
|
||||
@media (max-width: 1600px) {
|
||||
.box {
|
||||
width: 25%
|
||||
}
|
||||
}
|
||||
|
||||
@media (max-width: 991px) {
|
||||
.grid {
|
||||
margin-right: 220px;
|
||||
}
|
||||
.box {
|
||||
width: 50%
|
||||
}
|
||||
}
|
||||
|
||||
@media (max-width: 767px) {
|
||||
.grid {
|
||||
margin-right: 0;
|
||||
}
|
||||
}
|
||||
|
||||
@media (max-width: 500px) {
|
||||
.box {
|
||||
width: 100%
|
||||
}
|
||||
}
|
||||
|
||||
</style>
|
||||
|
||||
|
||||
{# This is just copypasta from the parent change_list_results.html file #}
|
||||
<table id="result_list">
|
||||
<thead>
|
||||
<tr>
|
||||
{% for header in result_headers %}
|
||||
<th scope="col" {{ header.class_attrib }}>
|
||||
{% if header.sortable %}
|
||||
{% if header.sort_priority > 0 %}
|
||||
<div class="sortoptions">
|
||||
<a class="sortremove" href="{{ header.url_remove }}" title="{% trans "Remove from sorting" %}"></a>
|
||||
{% if num_sorted_fields > 1 %}<span class="sortpriority" title="{% blocktrans with priority_number=header.sort_priority %}Sorting priority: {{ priority_number }}{% endblocktrans %}">{{ header.sort_priority }}</span>{% endif %}
|
||||
<a href="{{ header.url_toggle }}" class="toggle {% if header.ascending %}ascending{% else %}descending{% endif %}" title="{% trans "Toggle sorting" %}"></a>
|
||||
</div>
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
<div class="text">{% if header.sortable %}<a href="{{ header.url_primary }}">{{ header.text|capfirst }}</a>{% else %}<span>{{ header.text|capfirst }}</span>{% endif %}</div>
|
||||
<div class="clear"></div>
|
||||
</th>{% endfor %}
|
||||
</tr>
|
||||
</thead>
|
||||
</table>
|
||||
{# /copypasta #}
|
||||
|
||||
|
||||
<div class="grid">
|
||||
{% for result in results %}
|
||||
{# 0: Checkbox #}
|
||||
{# 1: Title #}
|
||||
{# 2: Date #}
|
||||
{# 3: Image #}
|
||||
{# 4: Correspondent #}
|
||||
{# 5: Tags #}
|
||||
<div class="box">
|
||||
<div class="result">
|
||||
<div class="header">
|
||||
<div class="checkbox">{{ result.0 }}</div>
|
||||
<div class="info">
|
||||
{{ result.4 }}<br />
|
||||
{{ result.1 }}
|
||||
</div>
|
||||
<div style="clear: both;"></div>
|
||||
</div>
|
||||
<div class="tags">{{ result.5 }}</div>
|
||||
<div class="date">{{ result.2 }}</div>
|
||||
<div style="clear: both;"></div>
|
||||
<div class="image">{{ result.3 }}</div>
|
||||
</div>
|
||||
</div>
|
||||
{% endfor %}
|
||||
</div>
|
||||
|
||||
|
||||
<script>
|
||||
// We need to re-build the select-all functionality as the old logic pointed
|
||||
// to a table and we're using divs now.
|
||||
django.jQuery("#action-toggle").on("change", function(){
|
||||
django.jQuery(".grid .box .result .checkbox input")
|
||||
.prop("checked", this.checked);
|
||||
});
|
||||
</script>
|
||||
@@ -6,5 +6,6 @@
|
||||
<meta charset="utf-8">
|
||||
</head>
|
||||
<body>
|
||||
{# One day someone (maybe even myself) is going to write a proper web front-end for Paperless, and this is where it'll start. #}
|
||||
</body>
|
||||
</html>
|
||||
|
||||
0
src/documents/templatetags/__init__.py
Normal file
28
src/documents/templatetags/hacks.py
Normal file
@@ -0,0 +1,28 @@
|
||||
from django.contrib.admin.templatetags.admin_list import (
|
||||
result_headers,
|
||||
result_hidden_fields,
|
||||
results
|
||||
)
|
||||
from django.template import Library
|
||||
|
||||
|
||||
register = Library()
|
||||
|
||||
|
||||
@register.inclusion_tag("admin/documents/document/change_list_results.html")
|
||||
def result_list(cl):
|
||||
"""
|
||||
Copy/pasted from django.contrib.admin.templatetags.admin_list just so I can
|
||||
modify the value passed to `.inclusion_tag()` in the decorator here. There
|
||||
must be a cleaner way... right?
|
||||
"""
|
||||
headers = list(result_headers(cl))
|
||||
num_sorted_fields = 0
|
||||
for h in headers:
|
||||
if h['sortable'] and h['sorted']:
|
||||
num_sorted_fields += 1
|
||||
return {'cl': cl,
|
||||
'result_hidden_fields': list(result_hidden_fields(cl)),
|
||||
'result_headers': headers,
|
||||
'num_sorted_fields': num_sorted_fields,
|
||||
'results': list(results(cl))}
|
||||
17
src/documents/tests/factories.py
Normal file
@@ -0,0 +1,17 @@
|
||||
import factory
|
||||
|
||||
from ..models import Document, Correspondent
|
||||
|
||||
|
||||
class CorrespondentFactory(factory.DjangoModelFactory):
|
||||
|
||||
class Meta:
|
||||
model = Correspondent
|
||||
|
||||
name = factory.Faker("name")
|
||||
|
||||
|
||||
class DocumentFactory(factory.DjangoModelFactory):
|
||||
|
||||
class Meta:
|
||||
model = Document
|
||||
@@ -1,22 +1,66 @@
|
||||
import os
|
||||
from unittest import mock, skipIf
|
||||
|
||||
import pyocr
|
||||
from django.test import TestCase
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
from unittest import mock
|
||||
|
||||
from ..consumer import Consumer
|
||||
from ..models import FileInfo
|
||||
from ..consumer import image_to_string, strip_excess_whitespace
|
||||
|
||||
|
||||
class TestConsumer(TestCase):
|
||||
|
||||
class DummyParser(object):
|
||||
pass
|
||||
|
||||
def test__get_parser_class_1_parser(self):
|
||||
self.assertEqual(
|
||||
self._get_consumer()._get_parser_class("doc.pdf"),
|
||||
self.DummyParser
|
||||
)
|
||||
|
||||
@mock.patch("documents.consumer.Consumer.CONSUME")
|
||||
@mock.patch("documents.consumer.os.makedirs")
|
||||
@mock.patch("documents.consumer.os.path.exists", return_value=True)
|
||||
@mock.patch("documents.consumer.document_consumer_declaration.send")
|
||||
def test__get_parser_class_n_parsers(self, m, *args):
|
||||
|
||||
class DummyParser1(object):
|
||||
pass
|
||||
|
||||
class DummyParser2(object):
|
||||
pass
|
||||
|
||||
m.return_value = (
|
||||
(None, lambda _: {"weight": 0, "parser": DummyParser1}),
|
||||
(None, lambda _: {"weight": 1, "parser": DummyParser2}),
|
||||
)
|
||||
|
||||
self.assertEqual(Consumer()._get_parser_class("doc.pdf"), DummyParser2)
|
||||
|
||||
@mock.patch("documents.consumer.Consumer.CONSUME")
|
||||
@mock.patch("documents.consumer.os.makedirs")
|
||||
@mock.patch("documents.consumer.os.path.exists", return_value=True)
|
||||
@mock.patch("documents.consumer.document_consumer_declaration.send")
|
||||
def test__get_parser_class_0_parsers(self, m, *args):
|
||||
m.return_value = ((None, lambda _: None),)
|
||||
self.assertIsNone(Consumer()._get_parser_class("doc.pdf"))
|
||||
|
||||
@mock.patch("documents.consumer.Consumer.CONSUME")
|
||||
@mock.patch("documents.consumer.os.makedirs")
|
||||
@mock.patch("documents.consumer.os.path.exists", return_value=True)
|
||||
@mock.patch("documents.consumer.document_consumer_declaration.send")
|
||||
def _get_consumer(self, m, *args):
|
||||
m.return_value = (
|
||||
(None, lambda _: {"weight": 0, "parser": self.DummyParser}),
|
||||
)
|
||||
return Consumer()
|
||||
|
||||
|
||||
class TestAttributes(TestCase):
|
||||
|
||||
TAGS = ("tag1", "tag2", "tag3")
|
||||
EXTENSIONS = (
|
||||
"pdf", "png", "jpg", "jpeg", "gif",
|
||||
"PDF", "PNG", "JPG", "JPEG", "GIF",
|
||||
"PdF", "PnG", "JpG", "JPeG", "GiF",
|
||||
"pdf", "png", "jpg", "jpeg", "gif", "tiff", "tif",
|
||||
"PDF", "PNG", "JPG", "JPEG", "GIF", "TIFF", "TIF",
|
||||
"PdF", "PnG", "JpG", "JPeG", "GiF", "TiFf", "TiF",
|
||||
)
|
||||
|
||||
def _test_guess_attributes_from_name(self, path, sender, title, tags):
|
||||
@@ -36,6 +80,8 @@ class TestAttributes(TestCase):
|
||||
self.assertEqual(tuple([t.slug for t in file_info.tags]), tags, f)
|
||||
if extension.lower() == "jpeg":
|
||||
self.assertEqual(file_info.extension, "jpg", f)
|
||||
elif extension.lower() == "tif":
|
||||
self.assertEqual(file_info.extension, "tiff", f)
|
||||
else:
|
||||
self.assertEqual(file_info.extension, extension.lower(), f)
|
||||
|
||||
@@ -308,71 +354,3 @@ class TestFieldPermutations(TestCase):
|
||||
}
|
||||
self._test_guessed_attributes(
|
||||
template.format(**spec), **spec)
|
||||
|
||||
|
||||
class FakeTesseract(object):
|
||||
|
||||
@staticmethod
|
||||
def can_detect_orientation():
|
||||
return True
|
||||
|
||||
@staticmethod
|
||||
def detect_orientation(file_handle, lang):
|
||||
raise OtherTesseractError("arbitrary status", "message")
|
||||
|
||||
@staticmethod
|
||||
def image_to_string(file_handle, lang):
|
||||
return "This is test text"
|
||||
|
||||
|
||||
class FakePyOcr(object):
|
||||
|
||||
@staticmethod
|
||||
def get_available_tools():
|
||||
return [FakeTesseract]
|
||||
|
||||
|
||||
class TestOCR(TestCase):
|
||||
|
||||
text_cases = [
|
||||
("simple string", "simple string"),
|
||||
(
|
||||
"simple newline\n testing string",
|
||||
"simple newline\ntesting string"
|
||||
),
|
||||
(
|
||||
"utf-8 строка с пробелами в конце ",
|
||||
"utf-8 строка с пробелами в конце"
|
||||
)
|
||||
]
|
||||
|
||||
SAMPLE_FILES = os.path.join(os.path.dirname(__file__), "samples")
|
||||
TESSERACT_INSTALLED = bool(pyocr.get_available_tools())
|
||||
|
||||
def test_strip_excess_whitespace(self):
|
||||
for source, result in self.text_cases:
|
||||
actual_result = strip_excess_whitespace(source)
|
||||
self.assertEqual(
|
||||
result,
|
||||
actual_result,
|
||||
"strip_exceess_whitespace({}) != '{}', but '{}'".format(
|
||||
source,
|
||||
result,
|
||||
actual_result
|
||||
)
|
||||
)
|
||||
|
||||
@skipIf(not TESSERACT_INSTALLED, "Tesseract not installed. Skipping")
|
||||
@mock.patch("documents.consumer.Consumer.SCRATCH", SAMPLE_FILES)
|
||||
@mock.patch("documents.consumer.pyocr", FakePyOcr)
|
||||
def test_image_to_string_with_text_free_page(self):
|
||||
"""
|
||||
This test is sort of silly, since it's really just reproducing an odd
|
||||
exception thrown by pyocr when it encounters a page with no text.
|
||||
Actually running this test against an installation of Tesseract results
|
||||
in a segmentation fault rooted somewhere deep inside pyocr where I
|
||||
don't care to dig. Regardless, if you run the consumer normally,
|
||||
text-free pages are now handled correctly so long as we work around
|
||||
this weird exception.
|
||||
"""
|
||||
image_to_string(["no-text.png", "en"])
|
||||
|
||||
@@ -3,6 +3,8 @@ from django.test import TestCase
|
||||
|
||||
from ..management.commands.document_importer import Command
|
||||
|
||||
from documents.settings import EXPORTER_FILE_NAME
|
||||
|
||||
|
||||
class TestImporter(TestCase):
|
||||
|
||||
@@ -27,7 +29,7 @@ class TestImporter(TestCase):
|
||||
|
||||
cmd.manifest = [{
|
||||
"model": "documents.document",
|
||||
"__exported_file_name__": "noexist.pdf"
|
||||
EXPORTER_FILE_NAME: "noexist.pdf"
|
||||
}]
|
||||
# self.assertRaises(CommandError, cmd._check_manifest)
|
||||
with self.assertRaises(CommandError) as cm:
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from random import randint
|
||||
|
||||
from django.test import TestCase
|
||||
from django.test import TestCase, override_settings
|
||||
|
||||
from ..models import Correspondent, Document, Tag
|
||||
from ..signals import document_consumption_finished
|
||||
@@ -16,9 +16,15 @@ class TestMatching(TestCase):
|
||||
matching_algorithm=getattr(klass, algorithm)
|
||||
)
|
||||
for string in true:
|
||||
self.assertTrue(instance.matches(string))
|
||||
self.assertTrue(
|
||||
instance.matches(string),
|
||||
'"%s" should match "%s" but it does not' % (text, string)
|
||||
)
|
||||
for string in false:
|
||||
self.assertFalse(instance.matches(string))
|
||||
self.assertFalse(
|
||||
instance.matches(string),
|
||||
'"%s" should not match "%s" but it does' % (text, string)
|
||||
)
|
||||
|
||||
def test_match_all(self):
|
||||
|
||||
@@ -54,6 +60,21 @@ class TestMatching(TestCase):
|
||||
)
|
||||
)
|
||||
|
||||
self._test_matching(
|
||||
'brown fox "lazy dogs"',
|
||||
"MATCH_ALL",
|
||||
(
|
||||
"the quick brown fox jumped over the lazy dogs",
|
||||
"the quick brown fox jumped over the lazy dogs",
|
||||
),
|
||||
(
|
||||
"the quick fox jumped over the lazy dogs",
|
||||
"the quick brown wolf jumped over the lazy dogs",
|
||||
"the quick brown fox jumped over the fat dogs",
|
||||
"the quick brown fox jumped over the lazy... dogs",
|
||||
)
|
||||
)
|
||||
|
||||
def test_match_any(self):
|
||||
|
||||
self._test_matching(
|
||||
@@ -89,6 +110,18 @@ class TestMatching(TestCase):
|
||||
)
|
||||
)
|
||||
|
||||
self._test_matching(
|
||||
'"brown fox" " lazy dogs "',
|
||||
"MATCH_ANY",
|
||||
(
|
||||
"the quick brown fox",
|
||||
"jumped over the lazy dogs.",
|
||||
),
|
||||
(
|
||||
"the lazy fox jumped over the brown dogs",
|
||||
)
|
||||
)
|
||||
|
||||
def test_match_literal(self):
|
||||
|
||||
self._test_matching(
|
||||
@@ -149,8 +182,25 @@ class TestMatching(TestCase):
|
||||
)
|
||||
)
|
||||
|
||||
def test_match_fuzzy(self):
|
||||
|
||||
class TestApplications(TestCase):
|
||||
self._test_matching(
|
||||
"Springfield, Miss.",
|
||||
"MATCH_FUZZY",
|
||||
(
|
||||
"1220 Main Street, Springf eld, Miss.",
|
||||
"1220 Main Street, Spring field, Miss.",
|
||||
"1220 Main Street, Springfeld, Miss.",
|
||||
"1220 Main Street Springfield Miss",
|
||||
),
|
||||
(
|
||||
"1220 Main Street, Springfield, Mich.",
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@override_settings(POST_CONSUME_SCRIPT=None)
|
||||
class TestDocumentConsumptionFinishedSignal(TestCase):
|
||||
"""
|
||||
We make use of document_consumption_finished, so we should test that it's
|
||||
doing what we expect wrt to tag & correspondent matching.
|
||||
|
||||
31
src/documents/tests/test_models.py
Normal file
@@ -0,0 +1,31 @@
|
||||
from django.test import TestCase
|
||||
|
||||
from ..models import Document, Correspondent
|
||||
from .factories import DocumentFactory, CorrespondentFactory
|
||||
|
||||
|
||||
class CorrespondentTestCase(TestCase):
|
||||
|
||||
def test___str__(self):
|
||||
for s in ("test", "οχι", "test with fun_charÅc'\"terß"):
|
||||
correspondent = CorrespondentFactory.create(name=s)
|
||||
self.assertEqual(str(correspondent), s)
|
||||
|
||||
|
||||
class DocumentTestCase(TestCase):
|
||||
|
||||
def test_correspondent_deletion_does_not_cascade(self):
|
||||
|
||||
self.assertEqual(Correspondent.objects.all().count(), 0)
|
||||
correspondent = CorrespondentFactory.create()
|
||||
self.assertEqual(Correspondent.objects.all().count(), 1)
|
||||
|
||||
self.assertEqual(Document.objects.all().count(), 0)
|
||||
DocumentFactory.create(correspondent=correspondent)
|
||||
self.assertEqual(Document.objects.all().count(), 1)
|
||||
self.assertIsNotNone(Document.objects.all().first().correspondent)
|
||||
|
||||
correspondent.delete()
|
||||
self.assertEqual(Correspondent.objects.all().count(), 0)
|
||||
self.assertEqual(Document.objects.all().count(), 1)
|
||||
self.assertIsNone(Document.objects.all().first().correspondent)
|
||||
@@ -1,17 +1,16 @@
|
||||
from django.contrib.auth.mixins import LoginRequiredMixin
|
||||
from django.http import HttpResponse
|
||||
from django.views.decorators.csrf import csrf_exempt
|
||||
from django.http import HttpResponse, HttpResponseBadRequest
|
||||
from django.views.generic import DetailView, FormView, TemplateView
|
||||
from django_filters.rest_framework import DjangoFilterBackend
|
||||
from rest_framework.filters import SearchFilter, OrderingFilter
|
||||
from paperless.db import GnuPG
|
||||
from paperless.mixins import SessionOrBasicAuthMixin
|
||||
from paperless.views import StandardPagination
|
||||
from rest_framework.filters import OrderingFilter, SearchFilter
|
||||
from rest_framework.mixins import (
|
||||
DestroyModelMixin,
|
||||
ListModelMixin,
|
||||
RetrieveModelMixin,
|
||||
UpdateModelMixin
|
||||
)
|
||||
from rest_framework.pagination import PageNumberPagination
|
||||
from rest_framework.permissions import IsAuthenticated
|
||||
from rest_framework.viewsets import (
|
||||
GenericViewSet,
|
||||
@@ -41,7 +40,7 @@ class IndexView(TemplateView):
|
||||
return TemplateView.get_context_data(self, **kwargs)
|
||||
|
||||
|
||||
class FetchView(LoginRequiredMixin, DetailView):
|
||||
class FetchView(SessionOrBasicAuthMixin, DetailView):
|
||||
|
||||
model = Document
|
||||
|
||||
@@ -74,28 +73,19 @@ class FetchView(LoginRequiredMixin, DetailView):
|
||||
return response
|
||||
|
||||
|
||||
class PushView(LoginRequiredMixin, FormView):
|
||||
class PushView(SessionOrBasicAuthMixin, FormView):
|
||||
"""
|
||||
A crude REST-ish API for creating documents.
|
||||
"""
|
||||
|
||||
form_class = UploadForm
|
||||
|
||||
@classmethod
|
||||
def as_view(cls, **kwargs):
|
||||
return csrf_exempt(FormView.as_view(**kwargs))
|
||||
|
||||
def form_valid(self, form):
|
||||
return HttpResponse("1")
|
||||
form.save()
|
||||
return HttpResponse("1", status=202)
|
||||
|
||||
def form_invalid(self, form):
|
||||
return HttpResponse("0")
|
||||
|
||||
|
||||
class StandardPagination(PageNumberPagination):
|
||||
page_size = 25
|
||||
page_size_query_param = "page-size"
|
||||
max_page_size = 100000
|
||||
return HttpResponseBadRequest(str(form.errors))
|
||||
|
||||
|
||||
class CorrespondentViewSet(ModelViewSet):
|
||||
|
||||
@@ -1 +1 @@
|
||||
from .checks import paths_check
|
||||
from .checks import paths_check, binaries_check
|
||||
|
||||
@@ -1,10 +1,15 @@
|
||||
import os
|
||||
import shutil
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.checks import Error, register, Warning
|
||||
|
||||
|
||||
@register()
|
||||
def paths_check(app_configs, **kwargs):
|
||||
"""
|
||||
Check the various paths for existence, readability and writeability
|
||||
"""
|
||||
|
||||
check_messages = []
|
||||
|
||||
@@ -44,4 +49,55 @@ def paths_check(app_configs, **kwargs):
|
||||
writeable_hint.format(directory)
|
||||
))
|
||||
|
||||
directory = os.getenv("PAPERLESS_STATICDIR")
|
||||
if directory:
|
||||
if not os.path.exists(directory):
|
||||
check_messages.append(Error(
|
||||
exists_message.format("PAPERLESS_STATICDIR"),
|
||||
exists_hint.format(directory)
|
||||
))
|
||||
if not check_messages:
|
||||
if not os.access(directory, os.W_OK | os.X_OK):
|
||||
check_messages.append(Error(
|
||||
writeable_message.format("PAPERLESS_STATICDIR"),
|
||||
writeable_hint.format(directory)
|
||||
))
|
||||
|
||||
return check_messages
|
||||
|
||||
|
||||
@register()
|
||||
def binaries_check(app_configs, **kwargs):
|
||||
"""
|
||||
Paperless requires the existence of a few binaries, so we do some checks
|
||||
for those here.
|
||||
"""
|
||||
|
||||
error = "Paperless can't find {}. Without it, consumption is impossible."
|
||||
hint = "Either it's not in your ${PATH} or it's not installed."
|
||||
|
||||
binaries = (settings.CONVERT_BINARY, settings.UNPAPER_BINARY, "tesseract")
|
||||
|
||||
check_messages = []
|
||||
for binary in binaries:
|
||||
if shutil.which(binary) is None:
|
||||
check_messages.append(Warning(error.format(binary), hint))
|
||||
|
||||
return check_messages
|
||||
|
||||
|
||||
@register()
|
||||
def config_check(app_configs, **kwargs):
|
||||
warning = (
|
||||
"It looks like you have PAPERLESS_SHARED_SECRET defined. Note that "
|
||||
"in the \npast, this variable was used for both API authentication "
|
||||
"and as the mail \nkeyword. As the API no no longer uses it, this "
|
||||
"variable has been renamed to \nPAPERLESS_EMAIL_SECRET, so if you're "
|
||||
"using the mail feature, you'd best update \nyour variable name.\n\n"
|
||||
"The old variable will stop working in a few months."
|
||||
)
|
||||
|
||||
if os.getenv("PAPERLESS_SHARED_SECRET"):
|
||||
return [Warning(warning)]
|
||||
|
||||
return []
|
||||
|
||||
46
src/paperless/mixins.py
Normal file
@@ -0,0 +1,46 @@
|
||||
from django.contrib.auth.mixins import AccessMixin
|
||||
from django.contrib.auth import authenticate, login
|
||||
import base64
|
||||
|
||||
|
||||
class SessionOrBasicAuthMixin(AccessMixin):
|
||||
"""
|
||||
Session or Basic Authentication mixin for Django.
|
||||
It determines if the requester is already logged in or if they have
|
||||
provided proper http-authorization and returning the view if all goes
|
||||
well, otherwise responding with a 401.
|
||||
|
||||
Base for mixin found here: https://djangosnippets.org/snippets/3073/
|
||||
"""
|
||||
|
||||
def dispatch(self, request, *args, **kwargs):
|
||||
|
||||
# check if user is authenticated via the session
|
||||
if request.user.is_authenticated:
|
||||
|
||||
# Already logged in, just return the view.
|
||||
return super(SessionOrBasicAuthMixin, self).dispatch(
|
||||
request, *args, **kwargs
|
||||
)
|
||||
|
||||
# apparently not authenticated via session, maybe via HTTP Basic?
|
||||
if 'HTTP_AUTHORIZATION' in request.META:
|
||||
auth = request.META['HTTP_AUTHORIZATION'].split()
|
||||
if len(auth) == 2:
|
||||
# NOTE: Support for only basic authentication
|
||||
if auth[0].lower() == "basic":
|
||||
authString = base64.b64decode(auth[1]).decode('utf-8')
|
||||
uname, passwd = authString.split(':')
|
||||
user = authenticate(username=uname, password=passwd)
|
||||
if user is not None:
|
||||
if user.is_active:
|
||||
login(request, user)
|
||||
request.user = user
|
||||
return super(
|
||||
SessionOrBasicAuthMixin, self
|
||||
).dispatch(
|
||||
request, *args, **kwargs
|
||||
)
|
||||
|
||||
# nope, really not authenticated
|
||||
return self.handle_no_permission()
|
||||
@@ -4,58 +4,79 @@ Django settings for paperless project.
|
||||
Generated by 'django-admin startproject' using Django 1.9.
|
||||
|
||||
For more information on this file, see
|
||||
https://docs.djangoproject.com/en/1.9/topics/settings/
|
||||
https://docs.djangoproject.com/en/1.10/topics/settings/
|
||||
|
||||
For the full list of settings and their values, see
|
||||
https://docs.djangoproject.com/en/1.9/ref/settings/
|
||||
https://docs.djangoproject.com/en/1.10/ref/settings/
|
||||
"""
|
||||
|
||||
import os
|
||||
|
||||
from dotenv import load_dotenv
|
||||
|
||||
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
|
||||
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||
|
||||
|
||||
# Quick-start development settings - unsuitable for production
|
||||
# See https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/
|
||||
|
||||
# SECURITY WARNING: keep the secret key used in production secret!
|
||||
SECRET_KEY = 'e11fl1oa-*ytql8p)(06fbj4ukrlo+n7k&q5+$1md7i+mge=ee'
|
||||
|
||||
# SECURITY WARNING: don't run with debug turned on in production!
|
||||
DEBUG = True
|
||||
|
||||
LOGIN_URL = '/admin/login'
|
||||
|
||||
ALLOWED_HOSTS = []
|
||||
|
||||
# Tap paperless.conf if it's available
|
||||
if os.path.exists("/etc/paperless.conf"):
|
||||
load_dotenv("/etc/paperless.conf")
|
||||
|
||||
|
||||
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
|
||||
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||
|
||||
|
||||
# Quick-start development settings - unsuitable for production
|
||||
# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
|
||||
|
||||
# The secret key has a default that should be fine so long as you're hosting
|
||||
# Paperless on a closed network. However, if you're putting this anywhere
|
||||
# public, you should change the key to something unique and verbose.
|
||||
SECRET_KEY = os.getenv(
|
||||
"PAPERLESS_SECRET_KEY",
|
||||
"e11fl1oa-*ytql8p)(06fbj4ukrlo+n7k&q5+$1md7i+mge=ee"
|
||||
)
|
||||
|
||||
|
||||
# SECURITY WARNING: don't run with debug turned on in production!
|
||||
DEBUG = True
|
||||
|
||||
LOGIN_URL = '/admin/login'
|
||||
|
||||
ALLOWED_HOSTS = ["*"]
|
||||
|
||||
_allowed_hosts = os.getenv("PAPERLESS_ALLOWED_HOSTS")
|
||||
if _allowed_hosts:
|
||||
ALLOWED_HOSTS = _allowed_hosts.split(",")
|
||||
|
||||
FORCE_SCRIPT_NAME = os.getenv("PAPERLESS_FORCE_SCRIPT_NAME")
|
||||
|
||||
# Application definition
|
||||
|
||||
INSTALLED_APPS = [
|
||||
|
||||
'django.contrib.admin',
|
||||
'django.contrib.auth',
|
||||
'django.contrib.contenttypes',
|
||||
'django.contrib.sessions',
|
||||
'django.contrib.messages',
|
||||
'django.contrib.staticfiles',
|
||||
"django.contrib.auth",
|
||||
"django.contrib.contenttypes",
|
||||
"django.contrib.sessions",
|
||||
"django.contrib.messages",
|
||||
"django.contrib.staticfiles",
|
||||
|
||||
"django_extensions",
|
||||
|
||||
"documents.apps.DocumentsConfig",
|
||||
"reminders.apps.RemindersConfig",
|
||||
"paperless_tesseract.apps.PaperlessTesseractConfig",
|
||||
|
||||
"flat_responsive",
|
||||
"django.contrib.admin",
|
||||
|
||||
"rest_framework",
|
||||
"crispy_forms",
|
||||
"django_filters"
|
||||
|
||||
]
|
||||
|
||||
if os.getenv("PAPERLESS_INSTALLED_APPS"):
|
||||
INSTALLED_APPS += os.getenv("PAPERLESS_INSTALLED_APPS").split(",")
|
||||
|
||||
MIDDLEWARE_CLASSES = [
|
||||
'django.middleware.security.SecurityMiddleware',
|
||||
'django.contrib.sessions.middleware.SessionMiddleware',
|
||||
@@ -89,7 +110,7 @@ WSGI_APPLICATION = 'paperless.wsgi.application'
|
||||
|
||||
|
||||
# Database
|
||||
# https://docs.djangoproject.com/en/1.9/ref/settings/#databases
|
||||
# https://docs.djangoproject.com/en/1.10/ref/settings/#databases
|
||||
|
||||
DATABASES = {
|
||||
"default": {
|
||||
@@ -114,7 +135,7 @@ if os.getenv("PAPERLESS_DBUSER") and os.getenv("PAPERLESS_DBPASS"):
|
||||
|
||||
|
||||
# Password validation
|
||||
# https://docs.djangoproject.com/en/1.9/ref/settings/#auth-password-validators
|
||||
# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
|
||||
|
||||
AUTH_PASSWORD_VALIDATORS = [
|
||||
{
|
||||
@@ -133,11 +154,11 @@ AUTH_PASSWORD_VALIDATORS = [
|
||||
|
||||
|
||||
# Internationalization
|
||||
# https://docs.djangoproject.com/en/1.9/topics/i18n/
|
||||
# https://docs.djangoproject.com/en/1.10/topics/i18n/
|
||||
|
||||
LANGUAGE_CODE = 'en-us'
|
||||
|
||||
TIME_ZONE = 'UTC'
|
||||
TIME_ZONE = os.getenv("PAPERLESS_TIME_ZONE", "UTC")
|
||||
|
||||
USE_I18N = True
|
||||
|
||||
@@ -147,9 +168,10 @@ USE_TZ = True
|
||||
|
||||
|
||||
# Static files (CSS, JavaScript, Images)
|
||||
# https://docs.djangoproject.com/en/1.9/howto/static-files/
|
||||
# https://docs.djangoproject.com/en/1.10/howto/static-files/
|
||||
|
||||
STATIC_ROOT = os.path.join(BASE_DIR, "..", "static")
|
||||
STATIC_ROOT = os.getenv(
|
||||
"PAPERLESS_STATICDIR", os.path.join(BASE_DIR, "..", "static"))
|
||||
MEDIA_ROOT = os.getenv(
|
||||
"PAPERLESS_MEDIADIR", os.path.join(BASE_DIR, "..", "media"))
|
||||
|
||||
@@ -183,11 +205,14 @@ LOGGING = {
|
||||
|
||||
# The default language that tesseract will attempt to use when parsing
|
||||
# documents. It should be a 3-letter language code consistent with ISO 639.
|
||||
OCR_LANGUAGE = "eng"
|
||||
OCR_LANGUAGE = os.getenv("PAPERLESS_OCR_LANGUAGE", "eng")
|
||||
|
||||
# The amount of threads to use for OCR
|
||||
OCR_THREADS = os.getenv("PAPERLESS_OCR_THREADS")
|
||||
|
||||
# OCR all documents?
|
||||
OCR_ALWAYS = bool(os.getenv("PAPERLESS_OCR_ALWAYS", "NO").lower() in ("yes", "y", "1", "t", "true"))
|
||||
|
||||
# If this is true, any failed attempts to OCR a PDF will result in the PDF
|
||||
# being indexed anyway, with whatever we could get. If it's False, the file
|
||||
# will simply be left in the CONSUMPTION_DIR.
|
||||
@@ -197,7 +222,7 @@ FORGIVING_OCR = bool(os.getenv("PAPERLESS_FORGIVING_OCR", "YES").lower() in ("ye
|
||||
GNUPG_HOME = os.getenv("HOME", "/tmp")
|
||||
|
||||
# Convert is part of the ImageMagick package
|
||||
CONVERT_BINARY = os.getenv("PAPERLESS_CONVERT_BINARY")
|
||||
CONVERT_BINARY = os.getenv("PAPERLESS_CONVERT_BINARY", "convert")
|
||||
CONVERT_TMPDIR = os.getenv("PAPERLESS_CONVERT_TMPDIR")
|
||||
CONVERT_MEMORY_LIMIT = os.getenv("PAPERLESS_CONVERT_MEMORY_LIMIT")
|
||||
CONVERT_DENSITY = os.getenv("PAPERLESS_CONVERT_DENSITY")
|
||||
@@ -216,18 +241,6 @@ CONSUMPTION_DIR = os.getenv("PAPERLESS_CONSUMPTION_DIR")
|
||||
# slowly, you may want to use a higher value than the default.
|
||||
CONSUMER_LOOP_TIME = int(os.getenv("PAPERLESS_CONSUMER_LOOP_TIME", 10))
|
||||
|
||||
# If you want to use IMAP mail consumption, populate this with useful values.
|
||||
# If you leave HOST set to None, we assume you're not going to use this
|
||||
# feature.
|
||||
MAIL_CONSUMPTION = {
|
||||
"HOST": os.getenv("PAPERLESS_CONSUME_MAIL_HOST"),
|
||||
"PORT": os.getenv("PAPERLESS_CONSUME_MAIL_PORT"),
|
||||
"USERNAME": os.getenv("PAPERLESS_CONSUME_MAIL_USER"),
|
||||
"PASSWORD": os.getenv("PAPERLESS_CONSUME_MAIL_PASS"),
|
||||
"USE_SSL": os.getenv("PAPERLESS_CONSUME_MAIL_USE_SSL", "y").lower() == "y", # If True, use SSL/TLS to connect
|
||||
"INBOX": "INBOX" # The name of the inbox on the server
|
||||
}
|
||||
|
||||
# This is used to encrypt the original documents and decrypt them later when
|
||||
# you want to download them. Set it and change the permissions on this file to
|
||||
# 0600, or set it to `None` and you'll be prompted for the passphrase at
|
||||
@@ -237,11 +250,17 @@ MAIL_CONSUMPTION = {
|
||||
# files.
|
||||
PASSPHRASE = os.getenv("PAPERLESS_PASSPHRASE")
|
||||
|
||||
# If you intend to use the "API" to push files into the consumer, you'll need
|
||||
# to provide a shared secret here. Leaving this as the default will disable
|
||||
# the API.
|
||||
SHARED_SECRET = os.getenv("PAPERLESS_SHARED_SECRET", "")
|
||||
|
||||
# Trigger a script after every successful document consumption?
|
||||
PRE_CONSUME_SCRIPT = os.getenv("PAPERLESS_PRE_CONSUME_SCRIPT")
|
||||
POST_CONSUME_SCRIPT = os.getenv("PAPERLESS_POST_CONSUME_SCRIPT")
|
||||
|
||||
# The number of items on each page in the web UI. This value must be a
|
||||
# positive integer, but if you don't define one in paperless.conf, a default of
|
||||
# 100 will be used.
|
||||
PAPERLESS_LIST_PER_PAGE = int(os.getenv("PAPERLESS_LIST_PER_PAGE", 100))
|
||||
|
||||
FY_START = os.getenv("PAPERLESS_FINANCIAL_YEAR_START")
|
||||
FY_END = os.getenv("PAPERLESS_FINANCIAL_YEAR_END")
|
||||
|
||||
# Specify the default date order (for autodetected dates)
|
||||
DATE_ORDER = os.getenv("PAPERLESS_DATE_ORDER", "DMY")
|
||||
|
||||
@@ -1,35 +1,26 @@
|
||||
"""paperless URL Configuration
|
||||
|
||||
The `urlpatterns` list routes URLs to views. For more information please see:
|
||||
https://docs.djangoproject.com/en/1.9/topics/http/urls/
|
||||
Examples:
|
||||
Function views
|
||||
1. Add an import: from my_app import views
|
||||
2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')
|
||||
Class-based views
|
||||
1. Add an import: from other_app.views import Home
|
||||
2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')
|
||||
Including another URLconf
|
||||
1. Add an import: from blog import urls as blog_urls
|
||||
2. Import the include() function: from django.conf.urls import url, include
|
||||
3. Add a URL to urlpatterns: url(r'^blog/', include(blog_urls))
|
||||
"""
|
||||
from django.conf import settings
|
||||
from django.conf.urls import url, static, include
|
||||
from django.conf.urls import include, static, url
|
||||
from django.contrib import admin
|
||||
|
||||
from django.views.decorators.csrf import csrf_exempt
|
||||
from django.views.generic import RedirectView
|
||||
from rest_framework.routers import DefaultRouter
|
||||
|
||||
from documents.views import (
|
||||
IndexView, FetchView, PushView,
|
||||
CorrespondentViewSet, TagViewSet, DocumentViewSet, LogViewSet
|
||||
CorrespondentViewSet,
|
||||
DocumentViewSet,
|
||||
FetchView,
|
||||
LogViewSet,
|
||||
PushView,
|
||||
TagViewSet
|
||||
)
|
||||
from reminders.views import ReminderViewSet
|
||||
|
||||
router = DefaultRouter()
|
||||
router.register(r'correspondents', CorrespondentViewSet)
|
||||
router.register(r'tags', TagViewSet)
|
||||
router.register(r'documents', DocumentViewSet)
|
||||
router.register(r'logs', LogViewSet)
|
||||
router.register(r"correspondents", CorrespondentViewSet)
|
||||
router.register(r"documents", DocumentViewSet)
|
||||
router.register(r"logs", LogViewSet)
|
||||
router.register(r"reminders", ReminderViewSet)
|
||||
router.register(r"tags", TagViewSet)
|
||||
|
||||
urlpatterns = [
|
||||
|
||||
@@ -40,9 +31,6 @@ urlpatterns = [
|
||||
),
|
||||
url(r"^api/", include(router.urls, namespace="drf")),
|
||||
|
||||
# Normal pages (coming soon)
|
||||
# url(r"^$", IndexView.as_view(), name="index"),
|
||||
|
||||
# File downloads
|
||||
url(
|
||||
r"^fetch/(?P<kind>doc|thumb)/(?P<pk>\d+)$",
|
||||
@@ -50,11 +38,20 @@ urlpatterns = [
|
||||
name="fetch"
|
||||
),
|
||||
|
||||
# File uploads
|
||||
url(r"^push$", csrf_exempt(PushView.as_view()), name="push"),
|
||||
|
||||
# The Django admin
|
||||
url(r"admin/", admin.site.urls),
|
||||
url(r"", admin.site.urls), # This is going away
|
||||
|
||||
# Redirect / to /admin
|
||||
url(r"^$", RedirectView.as_view(permanent=True, url="/admin/")),
|
||||
|
||||
] + static.static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
|
||||
|
||||
if settings.SHARED_SECRET:
|
||||
urlpatterns.insert(0, url(r"^push$", PushView.as_view(), name="push"))
|
||||
# Text in each page's <h1> (and above login form).
|
||||
admin.site.site_header = 'Paperless'
|
||||
# Text at the end of each page's <title>.
|
||||
admin.site.site_title = 'Paperless'
|
||||
# Text at the top of the admin index page.
|
||||
admin.site.index_title = 'Paperless administration'
|
||||
|
||||
@@ -1 +1 @@
|
||||
__version__ = (0, 3, 0)
|
||||
__version__ = (1, 2, 0)
|
||||
|
||||
7
src/paperless/views.py
Normal file
@@ -0,0 +1,7 @@
|
||||
from rest_framework.pagination import PageNumberPagination
|
||||
|
||||
|
||||
class StandardPagination(PageNumberPagination):
|
||||
page_size = 25
|
||||
page_size_query_param = "page-size"
|
||||
max_page_size = 100000
|
||||
@@ -4,7 +4,7 @@ WSGI config for paperless project.
|
||||
It exposes the WSGI callable as a module-level variable named ``application``.
|
||||
|
||||
For more information on this file, see
|
||||
https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/
|
||||
https://docs.djangoproject.com/en/1.10/howto/deployment/wsgi/
|
||||
"""
|
||||
|
||||
import os
|
||||
|
||||
0
src/paperless_tesseract/__init__.py
Normal file
16
src/paperless_tesseract/apps.py
Normal file
@@ -0,0 +1,16 @@
|
||||
from django.apps import AppConfig
|
||||
|
||||
|
||||
class PaperlessTesseractConfig(AppConfig):
|
||||
|
||||
name = "paperless_tesseract"
|
||||
|
||||
def ready(self):
|
||||
|
||||
from documents.signals import document_consumer_declaration
|
||||
|
||||
from .signals import ConsumerDeclaration
|
||||
|
||||
document_consumer_declaration.connect(ConsumerDeclaration.handle)
|
||||
|
||||
AppConfig.ready(self)
|
||||
271
src/paperless_tesseract/parsers.py
Normal file
@@ -0,0 +1,271 @@
|
||||
import itertools
|
||||
import os
|
||||
import re
|
||||
import subprocess
|
||||
from multiprocessing.pool import Pool
|
||||
import dateparser
|
||||
import pdftotext
|
||||
|
||||
import langdetect
|
||||
import pyocr
|
||||
from django.conf import settings
|
||||
from documents.parsers import DocumentParser, ParseError
|
||||
from PIL import Image
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
from pyocr.tesseract import TesseractError
|
||||
|
||||
from .languages import ISO639
|
||||
|
||||
|
||||
class OCRError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class RasterisedDocumentParser(DocumentParser):
|
||||
"""
|
||||
This parser uses Tesseract to try and get some text out of a rasterised
|
||||
image, whether it's a PDF, or other graphical format (JPEG, TIFF, etc.)
|
||||
"""
|
||||
|
||||
CONVERT = settings.CONVERT_BINARY
|
||||
DENSITY = settings.CONVERT_DENSITY if settings.CONVERT_DENSITY else 300
|
||||
THREADS = int(settings.OCR_THREADS) if settings.OCR_THREADS else None
|
||||
UNPAPER = settings.UNPAPER_BINARY
|
||||
DATE_ORDER = settings.DATE_ORDER
|
||||
DEFAULT_OCR_LANGUAGE = settings.OCR_LANGUAGE
|
||||
OCR_ALWAYS = settings.OCR_ALWAYS
|
||||
TEXT_CACHE = None
|
||||
|
||||
def get_thumbnail(self):
|
||||
"""
|
||||
The thumbnail of a PDF is just a 500px wide image of the first page.
|
||||
"""
|
||||
|
||||
run_convert(
|
||||
self.CONVERT,
|
||||
"-scale", "500x5000",
|
||||
"-alpha", "remove",
|
||||
self.document_path, os.path.join(self.tempdir, "convert-%04d.png")
|
||||
)
|
||||
|
||||
return os.path.join(self.tempdir, "convert-0000.png")
|
||||
|
||||
def _is_ocred(self):
|
||||
# Extract text from PDF using pdftotext
|
||||
text = get_text_from_pdf(self.document_path)
|
||||
|
||||
# We assume, that a PDF with at least 50 characters contains text
|
||||
# (so no OCR required)
|
||||
if len(text) > 50:
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def get_text(self):
|
||||
if self.TEXT_CACHE is not None:
|
||||
return self.TEXT_CACHE
|
||||
|
||||
if not self.OCR_ALWAYS and self._is_ocred():
|
||||
self.log("info", "Skipping OCR, using Text from PDF")
|
||||
self.TEXT_CACHE = get_text_from_pdf(self.document_path)
|
||||
return self.TEXT_CACHE
|
||||
|
||||
images = self._get_greyscale()
|
||||
|
||||
try:
|
||||
|
||||
self.TEXT_CACHE = self._get_ocr(images)
|
||||
return self.TEXT_CACHE
|
||||
except OCRError as e:
|
||||
raise ParseError(e)
|
||||
|
||||
def _get_greyscale(self):
|
||||
"""
|
||||
Greyscale images are easier for Tesseract to OCR
|
||||
"""
|
||||
|
||||
# Convert PDF to multiple PNMs
|
||||
pnm = os.path.join(self.tempdir, "convert-%04d.pnm")
|
||||
run_convert(
|
||||
self.CONVERT,
|
||||
"-density", str(self.DENSITY),
|
||||
"-depth", "8",
|
||||
"-type", "grayscale",
|
||||
self.document_path, pnm,
|
||||
)
|
||||
|
||||
# Get a list of converted images
|
||||
pnms = []
|
||||
for f in os.listdir(self.tempdir):
|
||||
if f.endswith(".pnm"):
|
||||
pnms.append(os.path.join(self.tempdir, f))
|
||||
|
||||
# Run unpaper in parallel on converted images
|
||||
with Pool(processes=self.THREADS) as pool:
|
||||
pool.map(run_unpaper, itertools.product([self.UNPAPER], pnms))
|
||||
|
||||
# Return list of converted images, processed with unpaper
|
||||
pnms = []
|
||||
for f in os.listdir(self.tempdir):
|
||||
if f.endswith(".unpaper.pnm"):
|
||||
pnms.append(os.path.join(self.tempdir, f))
|
||||
|
||||
return sorted(filter(lambda __: os.path.isfile(__), pnms))
|
||||
|
||||
def _guess_language(self, text):
|
||||
try:
|
||||
guess = langdetect.detect(text)
|
||||
self.log("debug", "Language detected: {}".format(guess))
|
||||
return guess
|
||||
except Exception as e:
|
||||
self.log("warning", "Language detection error: {}".format(e))
|
||||
|
||||
def _get_ocr(self, imgs):
|
||||
"""
|
||||
Attempts to do the best job possible OCR'ing the document based on
|
||||
simple language detection trial & error.
|
||||
"""
|
||||
|
||||
if not imgs:
|
||||
raise OCRError("No images found")
|
||||
|
||||
self.log("info", "OCRing the document")
|
||||
|
||||
# Since the division gets rounded down by int, this calculation works
|
||||
# for every edge-case, i.e. 1
|
||||
middle = int(len(imgs) / 2)
|
||||
raw_text = self._ocr([imgs[middle]], self.DEFAULT_OCR_LANGUAGE)
|
||||
|
||||
guessed_language = self._guess_language(raw_text)
|
||||
|
||||
if not guessed_language or guessed_language not in ISO639:
|
||||
self.log("warning", "Language detection failed!")
|
||||
if settings.FORGIVING_OCR:
|
||||
self.log(
|
||||
"warning",
|
||||
"As FORGIVING_OCR is enabled, we're going to make the "
|
||||
"best with what we have."
|
||||
)
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
raise OCRError("Language detection failed")
|
||||
|
||||
if ISO639[guessed_language] == self.DEFAULT_OCR_LANGUAGE:
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
|
||||
try:
|
||||
return self._ocr(imgs, ISO639[guessed_language])
|
||||
except pyocr.pyocr.tesseract.TesseractError:
|
||||
if settings.FORGIVING_OCR:
|
||||
self.log(
|
||||
"warning",
|
||||
"OCR for {} failed, but we're going to stick with what "
|
||||
"we've got since FORGIVING_OCR is enabled.".format(
|
||||
guessed_language
|
||||
)
|
||||
)
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
raise OCRError(
|
||||
"The guessed language is not available in this instance of "
|
||||
"Tesseract."
|
||||
)
|
||||
|
||||
def _ocr(self, imgs, lang):
|
||||
"""
|
||||
Performs a single OCR attempt.
|
||||
"""
|
||||
|
||||
if not imgs:
|
||||
return ""
|
||||
|
||||
self.log("info", "Parsing for {}".format(lang))
|
||||
|
||||
with Pool(processes=self.THREADS) as pool:
|
||||
r = pool.map(image_to_string, itertools.product(imgs, [lang]))
|
||||
r = " ".join(r)
|
||||
|
||||
# Strip out excess white space to allow matching to go smoother
|
||||
return strip_excess_whitespace(r)
|
||||
|
||||
def _assemble_ocr_sections(self, imgs, middle, text):
|
||||
"""
|
||||
Given a `middle` value and the text that middle page represents, we OCR
|
||||
the remainder of the document and return the whole thing.
|
||||
"""
|
||||
text = self._ocr(imgs[:middle], self.DEFAULT_OCR_LANGUAGE) + text
|
||||
text += self._ocr(imgs[middle + 1:], self.DEFAULT_OCR_LANGUAGE)
|
||||
return text
|
||||
|
||||
def get_date(self):
|
||||
text = self.get_text()
|
||||
|
||||
# This regular expression will try to find dates in the document at
|
||||
# hand and will match the following formats:
|
||||
# - XX.YY.ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX/YY/ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX-YY-ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX. MONTH ZZZZ with XX being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - MONTH ZZZZ
|
||||
m = re.search(
|
||||
r'\b([0-9]{1,2})[\.\/-]([0-9]{1,2})[\.\/-]([0-9]{4}|[0-9]{2})\b|' +
|
||||
r'\b([0-9]{1,2}\. [^ ]{3,9} ([0-9]{4}|[0-9]{2}))\b|' +
|
||||
r'\b([^ ]{3,9} [0-9]{4})\b', text)
|
||||
|
||||
if m is None:
|
||||
return None
|
||||
|
||||
return dateparser.parse(m.group(0),
|
||||
settings={'DATE_ORDER': self.DATE_ORDER,
|
||||
'PREFER_DAY_OF_MONTH': 'first',
|
||||
'RETURN_AS_TIMEZONE_AWARE': True})
|
||||
|
||||
|
||||
def run_convert(*args):
|
||||
|
||||
environment = os.environ.copy()
|
||||
if settings.CONVERT_MEMORY_LIMIT:
|
||||
environment["MAGICK_MEMORY_LIMIT"] = settings.CONVERT_MEMORY_LIMIT
|
||||
if settings.CONVERT_TMPDIR:
|
||||
environment["MAGICK_TMPDIR"] = settings.CONVERT_TMPDIR
|
||||
|
||||
subprocess.Popen(args, env=environment).wait()
|
||||
|
||||
|
||||
def run_unpaper(args):
|
||||
unpaper, pnm = args
|
||||
subprocess.Popen(
|
||||
(unpaper, pnm, pnm.replace(".pnm", ".unpaper.pnm"))).wait()
|
||||
|
||||
|
||||
def strip_excess_whitespace(text):
|
||||
collapsed_spaces = re.sub(r"([^\S\r\n]+)", " ", text)
|
||||
no_leading_whitespace = re.sub(
|
||||
"([\n\r]+)([^\S\n\r]+)", '\\1', collapsed_spaces)
|
||||
no_trailing_whitespace = re.sub("([^\S\n\r]+)$", '', no_leading_whitespace)
|
||||
return no_trailing_whitespace
|
||||
|
||||
|
||||
def image_to_string(args):
|
||||
img, lang = args
|
||||
ocr = pyocr.get_available_tools()[0]
|
||||
with Image.open(os.path.join(RasterisedDocumentParser.SCRATCH, img)) as f:
|
||||
if ocr.can_detect_orientation():
|
||||
try:
|
||||
orientation = ocr.detect_orientation(f, lang=lang)
|
||||
f = f.rotate(orientation["angle"], expand=1)
|
||||
except (TesseractError, OtherTesseractError):
|
||||
pass
|
||||
return ocr.image_to_string(f, lang=lang)
|
||||
|
||||
|
||||
def get_text_from_pdf(pdf_file):
|
||||
with open(pdf_file, "rb") as f:
|
||||
try:
|
||||
pdf = pdftotext.PDF(f)
|
||||
except pdftotext.Error:
|
||||
return ""
|
||||
|
||||
return "\n".join(pdf)
|
||||
23
src/paperless_tesseract/signals.py
Normal file
@@ -0,0 +1,23 @@
|
||||
import re
|
||||
|
||||
from .parsers import RasterisedDocumentParser
|
||||
|
||||
|
||||
class ConsumerDeclaration:
|
||||
|
||||
MATCHING_FILES = re.compile("^.*\.(pdf|jpe?g|gif|png|tiff?|pnm|bmp)$")
|
||||
|
||||
@classmethod
|
||||
def handle(cls, sender, **kwargs):
|
||||
return cls.test
|
||||
|
||||
@classmethod
|
||||
def test(cls, doc):
|
||||
|
||||
if cls.MATCHING_FILES.match(doc.lower()):
|
||||
return {
|
||||
"parser": RasterisedDocumentParser,
|
||||
"weight": 0
|
||||
}
|
||||
|
||||
return None
|
||||
0
src/paperless_tesseract/tests/__init__.py
Normal file
{kind=link}
|
Before Width: | Height: | Size: 32 KiB After Width: | Height: | Size: 32 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_1.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_2.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 135 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_3.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 138 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_4.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 138 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_5.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_6.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_7.pdf
Normal file
215
src/paperless_tesseract/tests/test_date.py
Normal file
@@ -0,0 +1,215 @@
|
||||
import datetime
|
||||
import os
|
||||
import shutil
|
||||
from unittest import mock
|
||||
from uuid import uuid4
|
||||
|
||||
from dateutil import tz
|
||||
from django.test import TestCase
|
||||
|
||||
from ..parsers import RasterisedDocumentParser
|
||||
|
||||
|
||||
class TestDate(TestCase):
|
||||
|
||||
SAMPLE_FILES = os.path.join(os.path.dirname(__file__), "samples")
|
||||
SCRATCH = "/tmp/paperless-tests-{}".format(str(uuid4())[:8])
|
||||
|
||||
def setUp(self):
|
||||
os.makedirs(self.SCRATCH, exist_ok=True)
|
||||
|
||||
def tearDown(self):
|
||||
shutil.rmtree(self.SCRATCH)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_1_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_1.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 4, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_1_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_1.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 4, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_2_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_2.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2013, 2, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_2_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_2.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2013, 2, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_3_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_3.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_3_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_3.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_4_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_4.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_4_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_4.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_5_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_5.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_5_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_5.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_pdf_us(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
document.DATE_ORDER = "MDY"
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_png_us(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
document.DATE_ORDER = "MDY"
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_pdf_eu(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_png_eu(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_7_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_7.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2018, 4, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
80
src/paperless_tesseract/tests/test_ocr.py
Normal file
@@ -0,0 +1,80 @@
|
||||
import os
|
||||
from unittest import mock, skipIf
|
||||
|
||||
import pyocr
|
||||
from django.test import TestCase
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
|
||||
from ..parsers import image_to_string, strip_excess_whitespace
|
||||
|
||||
|
||||
class FakeTesseract(object):
|
||||
|
||||
@staticmethod
|
||||
def can_detect_orientation():
|
||||
return True
|
||||
|
||||
@staticmethod
|
||||
def detect_orientation(file_handle, lang):
|
||||
raise OtherTesseractError("arbitrary status", "message")
|
||||
|
||||
@staticmethod
|
||||
def image_to_string(file_handle, lang):
|
||||
return "This is test text"
|
||||
|
||||
|
||||
class FakePyOcr(object):
|
||||
|
||||
@staticmethod
|
||||
def get_available_tools():
|
||||
return [FakeTesseract]
|
||||
|
||||
|
||||
class TestOCR(TestCase):
|
||||
|
||||
text_cases = [
|
||||
("simple string", "simple string"),
|
||||
(
|
||||
"simple newline\n testing string",
|
||||
"simple newline\ntesting string"
|
||||
),
|
||||
(
|
||||
"utf-8 строка с пробелами в конце ",
|
||||
"utf-8 строка с пробелами в конце"
|
||||
)
|
||||
]
|
||||
|
||||
SAMPLE_FILES = os.path.join(os.path.dirname(__file__), "samples")
|
||||
TESSERACT_INSTALLED = bool(pyocr.get_available_tools())
|
||||
|
||||
def test_strip_excess_whitespace(self):
|
||||
for source, result in self.text_cases:
|
||||
actual_result = strip_excess_whitespace(source)
|
||||
self.assertEqual(
|
||||
result,
|
||||
actual_result,
|
||||
"strip_exceess_whitespace({}) != '{}', but '{}'".format(
|
||||
source,
|
||||
result,
|
||||
actual_result
|
||||
)
|
||||
)
|
||||
|
||||
@skipIf(not TESSERACT_INSTALLED, "Tesseract not installed. Skipping")
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
@mock.patch("paperless_tesseract.parsers.pyocr", FakePyOcr)
|
||||
def test_image_to_string_with_text_free_page(self):
|
||||
"""
|
||||
This test is sort of silly, since it's really just reproducing an odd
|
||||
exception thrown by pyocr when it encounters a page with no text.
|
||||
Actually running this test against an installation of Tesseract results
|
||||
in a segmentation fault rooted somewhere deep inside pyocr where I
|
||||
don't care to dig. Regardless, if you run the consumer normally,
|
||||
text-free pages are now handled correctly so long as we work around
|
||||
this weird exception.
|
||||
"""
|
||||
image_to_string(["no-text.png", "en"])
|
||||
36
src/paperless_tesseract/tests/test_signals.py
Normal file
@@ -0,0 +1,36 @@
|
||||
from django.test import TestCase
|
||||
|
||||
from ..signals import ConsumerDeclaration
|
||||
|
||||
|
||||
class SignalsTestCase(TestCase):
|
||||
|
||||
def test_test_handles_various_file_names_true(self):
|
||||
|
||||
prefixes = (
|
||||
"doc", "My Document", "Μυ Γρεεκ Δοψθμεντ", "Doc -with - tags",
|
||||
"A document with a . in it", "Doc with -- in it"
|
||||
)
|
||||
suffixes = (
|
||||
"pdf", "jpg", "jpeg", "gif", "png", "tiff", "tif", "pnm", "bmp",
|
||||
"PDF", "JPG", "JPEG", "GIF", "PNG", "TIFF", "TIF", "PNM", "BMP",
|
||||
"pDf", "jPg", "jpEg", "gIf", "pNg", "tIff", "tIf", "pNm", "bMp",
|
||||
)
|
||||
|
||||
for prefix in prefixes:
|
||||
for suffix in suffixes:
|
||||
name = "{}.{}".format(prefix, suffix)
|
||||
self.assertTrue(ConsumerDeclaration.test(name))
|
||||
|
||||
def test_test_handles_various_file_names_false(self):
|
||||
|
||||
prefixes = ("doc",)
|
||||
suffixes = ("txt", "markdown", "",)
|
||||
|
||||
for prefix in prefixes:
|
||||
for suffix in suffixes:
|
||||
name = "{}.{}".format(prefix, suffix)
|
||||
self.assertFalse(ConsumerDeclaration.test(name))
|
||||
|
||||
self.assertFalse(ConsumerDeclaration.test(""))
|
||||
self.assertFalse(ConsumerDeclaration.test("doc"))
|
||||
@@ -1,3 +1,8 @@
|
||||
[pytest]
|
||||
DJANGO_SETTINGS_MODULE=paperless.settings
|
||||
|
||||
addopts = --pythonwarnings=all
|
||||
env =
|
||||
PAPERLESS_CONSUME=/tmp
|
||||
PAPERLESS_PASSPHRASE=THISISNOTASECRET
|
||||
PAPERLESS_SECRET=paperless
|
||||
PAPERLESS_EMAIL_SECRET=paperless
|
||||
|
||||
0
src/reminders/__init__.py
Normal file
20
src/reminders/admin.py
Normal file
@@ -0,0 +1,20 @@
|
||||
from django.conf import settings
|
||||
from django.contrib import admin
|
||||
|
||||
from .models import Reminder
|
||||
|
||||
|
||||
class ReminderAdmin(admin.ModelAdmin):
|
||||
|
||||
class Media:
|
||||
css = {
|
||||
"all": ("paperless.css",)
|
||||
}
|
||||
|
||||
list_per_page = settings.PAPERLESS_LIST_PER_PAGE
|
||||
list_display = ("date", "document", "note")
|
||||
list_filter = ("date",)
|
||||
list_editable = ("note",)
|
||||
|
||||
|
||||
admin.site.register(Reminder, ReminderAdmin)
|
||||
5
src/reminders/apps.py
Normal file
@@ -0,0 +1,5 @@
|
||||
from django.apps import AppConfig
|
||||
|
||||
|
||||
class RemindersConfig(AppConfig):
|
||||
name = "reminders"
|
||||
14
src/reminders/filters.py
Normal file
@@ -0,0 +1,14 @@
|
||||
from django_filters.rest_framework import CharFilter, FilterSet
|
||||
|
||||
from .models import Reminder
|
||||
|
||||
|
||||
class ReminderFilterSet(FilterSet):
|
||||
|
||||
class Meta(object):
|
||||
model = Reminder
|
||||
fields = {
|
||||
"document": ["exact"],
|
||||
"date": ["gt", "lt", "gte", "lte", "exact"],
|
||||
"note": ["istartswith", "iendswith", "icontains"]
|
||||
}
|
||||
27
src/reminders/migrations/0001_initial.py
Normal file
@@ -0,0 +1,27 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-03-25 15:58
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
import django.db.models.deletion
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
initial = True
|
||||
|
||||
dependencies = [
|
||||
('documents', '0016_auto_20170325_1558'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.CreateModel(
|
||||
name='Reminder',
|
||||
fields=[
|
||||
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
|
||||
('date', models.DateTimeField()),
|
||||
('note', models.TextField(blank=True)),
|
||||
('document', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='documents.Document')),
|
||||
],
|
||||
),
|
||||
]
|
||||
0
src/reminders/migrations/__init__.py
Normal file
8
src/reminders/models.py
Normal file
@@ -0,0 +1,8 @@
|
||||
from django.db import models
|
||||
|
||||
|
||||
class Reminder(models.Model):
|
||||
|
||||
document = models.ForeignKey("documents.Document")
|
||||
date = models.DateTimeField()
|
||||
note = models.TextField(blank=True)
|
||||
14
src/reminders/serialisers.py
Normal file
@@ -0,0 +1,14 @@
|
||||
from documents.models import Document
|
||||
from rest_framework import serializers
|
||||
|
||||
from .models import Reminder
|
||||
|
||||
|
||||
class ReminderSerializer(serializers.HyperlinkedModelSerializer):
|
||||
|
||||
document = serializers.HyperlinkedRelatedField(
|
||||
view_name="drf:document-detail", queryset=Document.objects)
|
||||
|
||||
class Meta(object):
|
||||
model = Reminder
|
||||
fields = ("id", "document", "date", "note")
|
||||
3
src/reminders/tests.py
Normal file
@@ -0,0 +1,3 @@
|
||||
from django.test import TestCase
|
||||
|
||||
# Create your tests here.
|
||||
22
src/reminders/views.py
Normal file
@@ -0,0 +1,22 @@
|
||||
from django_filters.rest_framework import DjangoFilterBackend
|
||||
from rest_framework.filters import OrderingFilter
|
||||
from rest_framework.permissions import IsAuthenticated
|
||||
from rest_framework.viewsets import (
|
||||
ModelViewSet,
|
||||
)
|
||||
|
||||
from .filters import ReminderFilterSet
|
||||
from .models import Reminder
|
||||
from .serialisers import ReminderSerializer
|
||||
from paperless.views import StandardPagination
|
||||
|
||||
|
||||
class ReminderViewSet(ModelViewSet):
|
||||
model = Reminder
|
||||
queryset = Reminder.objects
|
||||
serializer_class = ReminderSerializer
|
||||
pagination_class = StandardPagination
|
||||
permission_classes = (IsAuthenticated,)
|
||||
filter_backends = (DjangoFilterBackend, OrderingFilter)
|
||||
filter_class = ReminderFilterSet
|
||||
ordering_fields = ("date", "document")
|
||||
21
src/tox.ini
@@ -5,19 +5,18 @@
|
||||
|
||||
[tox]
|
||||
skipsdist = True
|
||||
envlist = py34, py35, pep8
|
||||
envlist = py34, py35, py36, pycodestyle
|
||||
|
||||
[testenv]
|
||||
commands = {envpython} manage.py test
|
||||
commands = pytest
|
||||
deps = -r{toxinidir}/../requirements.txt
|
||||
setenv =
|
||||
PAPERLESS_CONSUME=/tmp
|
||||
PAPERLESS_PASSPHRASE=THISISNOTASECRET
|
||||
PAPERLESS_SECRET=paperless
|
||||
|
||||
[testenv:pep8]
|
||||
commands=pep8
|
||||
deps=pep8
|
||||
[testenv:pycodestyle]
|
||||
commands=pycodestyle
|
||||
deps=pycodestyle
|
||||
|
||||
[pep8]
|
||||
exclude=.tox,migrations,paperless/settings.py
|
||||
[pycodestyle]
|
||||
exclude=
|
||||
.tox,
|
||||
migrations,
|
||||
paperless/settings.py
|
||||
|
||||