mirror of
https://github.com/paperless-ngx/paperless-ngx.git
synced 2025-08-03 18:54:40 -05:00
Compare commits
95 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1f68223752 | ||
|
|
d6b626ec50 | ||
|
|
926016f1d8 | ||
|
|
8ea1cc24a7 | ||
|
|
08adb2f540 | ||
|
|
4333ee01bc | ||
|
|
46db0edd5d | ||
|
|
10d017ebe4 | ||
|
|
76a13dadb8 | ||
|
|
72750b9243 | ||
|
|
fba58f3bdd | ||
|
|
6662ca3467 | ||
|
|
6f1ed89e26 | ||
|
|
7e99e42924 | ||
|
|
5d01410dc0 | ||
|
|
9a47dba494 | ||
|
|
6edee78145 | ||
|
|
30eac99a61 | ||
|
|
ea6d040809 | ||
|
|
8e9d5caa37 | ||
|
|
122aa2b9f1 | ||
|
|
fb1da4834c | ||
|
|
96c7222269 | ||
|
|
1737e27b34 | ||
|
|
39f198138a | ||
|
|
c74bb84c83 | ||
|
|
07d06d9aee | ||
|
|
9cef689106 | ||
|
|
11a9c756b3 | ||
|
|
11accaff7f | ||
|
|
77aee832e4 | ||
|
|
4bde14368c | ||
|
|
151d85f2be | ||
|
|
e7c23cfb92 | ||
|
|
3f9ea7b971 | ||
|
|
998c3ef51b | ||
|
|
c85b6b425d | ||
|
|
273916973c | ||
|
|
5009bd022f | ||
|
|
73163d893f | ||
|
|
506af7c9c2 | ||
|
|
c90ed2da1d | ||
|
|
cebb8b9fa2 | ||
|
|
46aca10a72 | ||
|
|
6384c698ad | ||
|
|
abf01be889 | ||
|
|
1e4928d2a0 | ||
|
|
503be90932 | ||
|
|
b5d6a82cc3 | ||
|
|
c073ba5272 | ||
|
|
d1e317ce21 | ||
|
|
d4abeafb34 | ||
|
|
4d96551619 | ||
|
|
178361b247 | ||
|
|
40f8ba23a4 | ||
|
|
bef2d94374 | ||
|
|
f39c7654a0 | ||
|
|
e9fff764cb | ||
|
|
87e466c47c | ||
|
|
bd0b593c4a | ||
|
|
7a8142df2b | ||
|
|
bbe3084eda | ||
|
|
89d42bd078 | ||
|
|
93efaf7a38 | ||
|
|
398575c70c | ||
|
|
4e21fa4830 | ||
|
|
d2d2d9edaf | ||
|
|
771c8bbbe4 | ||
|
|
20eeda19b8 | ||
|
|
96c517d65c | ||
|
|
e70ad3d493 | ||
|
|
516bc48a33 | ||
|
|
7f97716ae9 | ||
|
|
5e40227bc3 | ||
|
|
5479942fc0 | ||
|
|
ce98019b49 | ||
|
|
9470154df2 | ||
|
|
5c59120c57 | ||
|
|
88736ff867 | ||
|
|
fd5b831979 | ||
|
|
3fcd1e2d7e | ||
|
|
2c81648d59 | ||
|
|
cd92c005e3 | ||
|
|
31c8cf020e | ||
|
|
e900a38983 | ||
|
|
7343a07ddd | ||
|
|
e20b4fb905 | ||
|
|
cbbc4d37d0 | ||
|
|
b140935843 | ||
|
|
7e49d047b0 | ||
|
|
68cdeb7b3d | ||
|
|
76293084a4 | ||
|
|
e1cf2117f5 | ||
|
|
7d81de4edf | ||
|
|
37af5992c7 |
@@ -1,5 +1,9 @@
|
||||
language: python
|
||||
|
||||
before_install:
|
||||
- sudo apt-get update -qq
|
||||
- sudo apt-get install -qq libpoppler-cpp-dev unpaper tesseract-ocr tesseract-ocr-eng
|
||||
|
||||
sudo: false
|
||||
|
||||
matrix:
|
||||
|
||||
74
Dockerfile
74
Dockerfile
@@ -1,50 +1,46 @@
|
||||
FROM python:3.5
|
||||
MAINTAINER Pit Kleyersburg <pitkley@googlemail.com>
|
||||
FROM alpine:3.7
|
||||
|
||||
# Install dependencies
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
sudo \
|
||||
tesseract-ocr tesseract-ocr-eng imagemagick ghostscript unpaper \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install python dependencies
|
||||
RUN mkdir -p /usr/src/paperless
|
||||
WORKDIR /usr/src/paperless
|
||||
COPY requirements.txt /usr/src/paperless/
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
LABEL maintainer="The Paperless Project https://github.com/danielquinn/paperless" \
|
||||
contributors="Guy Addadi <addadi@gmail.com>, Pit Kleyersburg <pitkley@googlemail.com>, \
|
||||
Sven Fischer <git-dev@linux4tw.de>"
|
||||
|
||||
# Copy application
|
||||
RUN mkdir -p /usr/src/paperless/src
|
||||
RUN mkdir -p /usr/src/paperless/data
|
||||
RUN mkdir -p /usr/src/paperless/media
|
||||
COPY requirements.txt /usr/src/paperless/
|
||||
COPY src/ /usr/src/paperless/src/
|
||||
COPY data/ /usr/src/paperless/data/
|
||||
COPY media/ /usr/src/paperless/media/
|
||||
|
||||
# Set consumption directory
|
||||
ENV PAPERLESS_CONSUMPTION_DIR /consume
|
||||
RUN mkdir -p $PAPERLESS_CONSUMPTION_DIR
|
||||
|
||||
# Migrate database
|
||||
WORKDIR /usr/src/paperless/src
|
||||
RUN ./manage.py migrate
|
||||
|
||||
# Create user
|
||||
RUN groupadd -g 1000 paperless \
|
||||
&& useradd -u 1000 -g 1000 -d /usr/src/paperless paperless \
|
||||
&& chown -Rh paperless:paperless /usr/src/paperless
|
||||
|
||||
# Set export directory
|
||||
ENV PAPERLESS_EXPORT_DIR /export
|
||||
RUN mkdir -p $PAPERLESS_EXPORT_DIR
|
||||
|
||||
# Setup entrypoint
|
||||
COPY scripts/docker-entrypoint.sh /sbin/docker-entrypoint.sh
|
||||
RUN chmod 755 /sbin/docker-entrypoint.sh
|
||||
|
||||
# Mount volumes
|
||||
# Set export and consumption directories
|
||||
ENV PAPERLESS_EXPORT_DIR=/export \
|
||||
PAPERLESS_CONSUMPTION_DIR=/consume
|
||||
|
||||
# Install dependencies
|
||||
RUN apk --no-cache --update add \
|
||||
python3 gnupg libmagic bash shadow \
|
||||
sudo poppler tesseract-ocr imagemagick ghostscript unpaper && \
|
||||
apk --no-cache add --virtual .build-dependencies \
|
||||
python3-dev poppler-dev gcc g++ musl-dev zlib-dev jpeg-dev && \
|
||||
# Install python dependencies
|
||||
python3 -m ensurepip && \
|
||||
rm -r /usr/lib/python*/ensurepip && \
|
||||
cd /usr/src/paperless && \
|
||||
pip3 install --no-cache-dir -r requirements.txt && \
|
||||
# Remove build dependencies
|
||||
apk del .build-dependencies && \
|
||||
# Create the consumption directory
|
||||
mkdir -p $PAPERLESS_CONSUMPTION_DIR && \
|
||||
# Create user
|
||||
addgroup -g 1000 paperless && \
|
||||
adduser -D -u 1000 -G paperless -h /usr/src/paperless paperless && \
|
||||
chown -Rh paperless:paperless /usr/src/paperless && \
|
||||
mkdir -p $PAPERLESS_EXPORT_DIR && \
|
||||
# Setup entrypoint
|
||||
chmod 755 /sbin/docker-entrypoint.sh
|
||||
|
||||
WORKDIR /usr/src/paperless/src
|
||||
# Mount volumes and set Entrypoint
|
||||
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume", "/export"]
|
||||
|
||||
ENTRYPOINT ["/sbin/docker-entrypoint.sh"]
|
||||
CMD ["--help"]
|
||||
|
||||
|
||||
70
README.md
Normal file
70
README.md
Normal file
@@ -0,0 +1,70 @@
|
||||
# Paperless
|
||||
|
||||
  
|
||||
|
||||
Index and archive all of your scanned paper documents
|
||||
|
||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||
|
||||
* There's no search feature
|
||||
* It takes up physical space
|
||||
* Backups mean more paper
|
||||
|
||||
In the past few months I've been bitten more than a few times by the problem of not having the right document around. Sometimes I recycled a document I needed (who keeps water bills for two years?) and other times I just lost it... because paper. I wrote this to make my life easier.
|
||||
|
||||
|
||||
## How it Works
|
||||
|
||||
Paperless does not control your scanner, it only helps you deal with what your scanner produces
|
||||
|
||||
1. Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the [scanner recommendations](https://paperless.readthedocs.io/en/latest/scanners.html) page.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push scanned images to a server without you having to do anything. Of course if your scanner doesn't know how to automatically upload the file somewhere, you can always do that manually. Paperless doesn't care how the documents get into its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the file and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
5. Download the PDF you need/want via the web interface and do whatever you like with it. You can even print it and send it as if it's the original. In most cases, no one will care or notice.
|
||||
|
||||
Here's what you get:
|
||||
|
||||
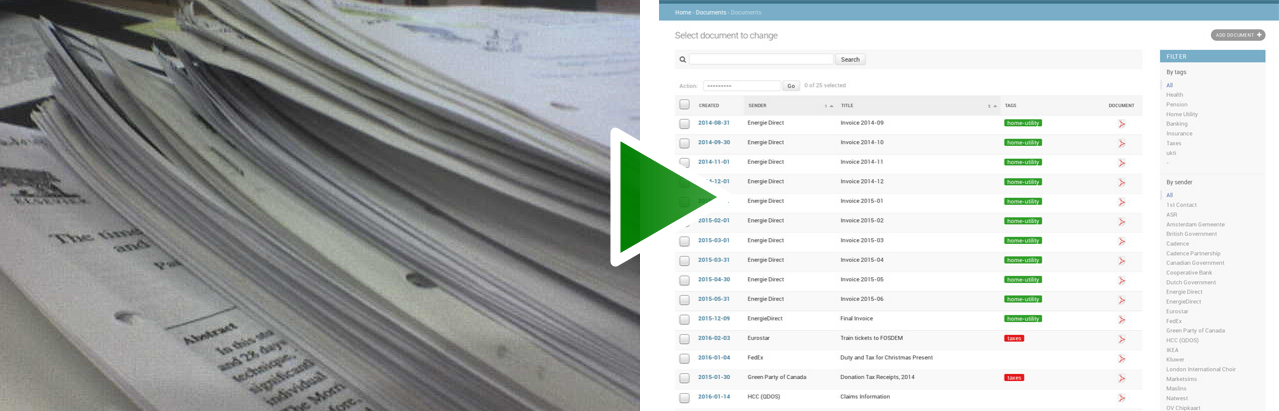
|
||||
|
||||
|
||||
## Documentation
|
||||
|
||||
It's all available on [ReadTheDocs](https://paperless.readthedocs.org/).
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
This is all really a quite simple, shiny, user-friendly wrapper around some very powerful tools.
|
||||
|
||||
* [ImageMagick](http://imagemagick.org/) converts the images between colour and greyscale.
|
||||
* [Tesseract](https://github.com/tesseract-ocr) does the character recognition.
|
||||
* [Unpaper](https://www.flameeyes.eu/projects/unpaper) despeckles and deskews the scanned image.
|
||||
* [GNU Privacy Guard](https://gnupg.org/) is used as the encryption backend.
|
||||
* [Python 3](https://python.org/) is the language of the project.
|
||||
* [Pillow](https://pypi.python.org/pypi/pillowfight/) loads the image data as a python object to be used with PyOCR.
|
||||
* [PyOCR](https://github.com/jflesch/pyocr) is a slick programmatic wrapper around tesseract.
|
||||
* [Django](https://www.djangoproject.com/) is the framework this project is written against.
|
||||
* [Python-GNUPG](http://pythonhosted.org/python-gnupg/) decrypts the PDFs on-the-fly to allow you to download unencrypted files, leaving the encrypted ones on-disk.
|
||||
|
||||
|
||||
## Stability
|
||||
|
||||
This project has been around since 2015, and there's lots of people using it, however it's still under active development (just look at the git commit history) so don't expect it to be 100% stable. You can backup the sqlite3 database, media directory and your configuration file to be on the safe side.
|
||||
|
||||
|
||||
## Similar Projects
|
||||
|
||||
There's another project out there called [Mayan EDMS](https://mayan.readthedocs.org/en/latest/) that has a surprising amount of technical overlap with Paperless. Also based on Django and using a consumer model with Tesseract and Unpaper, Mayan EDMS is *much* more featureful and comes with a slick UI as well, but still in Python 2. It may be that Paperless consumes fewer resources, but to be honest, this is just a guess as I haven't tested this myself. One thing's for certain though, *Paperless* is a **way** better name.
|
||||
|
||||
|
||||
## Important Note
|
||||
|
||||
Document scanners are typically used to scan sensitive documents. Things like your social insurance number, tax records, invoices, etc. While Paperless encrypts the original files via the consumption script, the OCR'd text is *not* encrypted and is therefore stored in the clear (it needs to be searchable, so if someone has ideas on how to do that on encrypted data, I'm all ears). This means that Paperless should never be run on an untrusted host. Instead, I recommend that if you do want to use it, run it locally on a server in your own home.
|
||||
|
||||
|
||||
## Donations
|
||||
|
||||
As with all Free software, the power is less in the finances and more in the collective efforts. I really appreciate every pull request and bug report offered up by Paperless' users, so please keep that stuff coming. If however, you're not one for coding/design/documentation, and would like to contribute financially, I won't say no ;-)
|
||||
|
||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to the [United Nations High Commissioner for Refugees](https://donate.unhcr.org/int-en/general). They're doing important work and they need the money a lot more than I do.
|
||||
144
README.rst
144
README.rst
@@ -1,144 +0,0 @@
|
||||
Paperless
|
||||
#########
|
||||
|
||||
|Documentation|
|
||||
|Chat|
|
||||
|Travis|
|
||||
|Dependencies|
|
||||
|
||||
Index and archive all of your scanned paper documents
|
||||
|
||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||
|
||||
* There's no search feature
|
||||
* It takes up physical space
|
||||
* Backups mean more paper
|
||||
|
||||
In the past few months I've been bitten more than a few times by the problem
|
||||
of not having the right document around. Sometimes I recycled a document I
|
||||
needed (who keeps water bills for two years?) and other times I just lost
|
||||
it... because paper. I wrote this to make my life easier.
|
||||
|
||||
|
||||
How it Works
|
||||
============
|
||||
|
||||
Paperless does not control your scanner, it only helps you deal with what your
|
||||
scanner produces
|
||||
|
||||
1. Buy a document scanner that can write to a place on your network. If you
|
||||
need some inspiration, have a look at the `scanner recommendations`_ page.
|
||||
recommended by another user.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push
|
||||
scanned images to a server without you having to do anything. If your
|
||||
scanner doesn't know how to automatically upload the file somewhere, you can
|
||||
always do that manually. Paperless doesn't care how the documents get into
|
||||
its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the file
|
||||
and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
5. Download the PDF you need/want via the web interface and do whatever you
|
||||
like with it. You can even print it and send it as if it's the original.
|
||||
In most cases, no one will care or notice.
|
||||
|
||||
Here's what you get:
|
||||
|
||||
.. image:: docs/_static/screenshot.png
|
||||
:alt: The before and after
|
||||
:target: docs/_static/screenshot.png
|
||||
|
||||
|
||||
Stability
|
||||
=========
|
||||
|
||||
Paperless is still under active development (just look at the git commit
|
||||
history) so don't expect it to be 100% stable. You can backup the sqlite3
|
||||
database, media directory and your configuration file to be on the safe side.
|
||||
|
||||
|
||||
Requirements
|
||||
============
|
||||
|
||||
This is all really a quite simple, shiny, user-friendly wrapper around some
|
||||
very powerful tools.
|
||||
|
||||
* `ImageMagick`_ converts the images between colour and greyscale.
|
||||
* `Tesseract`_ does the character recognition.
|
||||
* `Unpaper`_ despeckles and deskews the scanned image.
|
||||
* `GNU Privacy Guard`_ is used as the encryption backend.
|
||||
* `Python 3`_ is the language of the project.
|
||||
|
||||
* `Pillow`_ loads the image data as a python object to be used with PyOCR.
|
||||
* `PyOCR`_ is a slick programmatic wrapper around tesseract.
|
||||
* `Django`_ is the framework this project is written against.
|
||||
* `Python-GNUPG`_ decrypts the PDFs on-the-fly to allow you to download
|
||||
unencrypted files, leaving the encrypted ones on-disk.
|
||||
|
||||
|
||||
Documentation
|
||||
=============
|
||||
|
||||
It's all available on `ReadTheDocs`_.
|
||||
|
||||
|
||||
Similar Projects
|
||||
================
|
||||
|
||||
There's another project out there called `Mayan EDMS`_ that has a surprising
|
||||
amount of technical overlap with Paperless. Also based on Django and using
|
||||
a consumer model with Tesseract and Unpaper, Mayan EDMS is *much* more
|
||||
featureful and comes with a slick UI as well, but still in Python 2. It may be
|
||||
that Paperless consumes fewer resources, but to be honest, this is just a guess
|
||||
as I haven't tested this myself. One thing's for certain though, *Paperless*
|
||||
is a **much** better name.
|
||||
|
||||
|
||||
Important Note
|
||||
==============
|
||||
|
||||
Document scanners are typically used to scan sensitive documents. Things like
|
||||
your social insurance number, tax records, invoices, etc. While Paperless
|
||||
encrypts the original files via the consumption script, the OCR'd text is *not*
|
||||
encrypted and is therefore stored in the clear (it needs to be searchable, so
|
||||
if someone has ideas on how to do that on encrypted data, I'm all ears). This
|
||||
means that Paperless should never be run on an untrusted host. Instead, I
|
||||
recommend that if you do want to use it, run it locally on a server in your own
|
||||
home.
|
||||
|
||||
|
||||
Donations
|
||||
=========
|
||||
|
||||
As with all Free software, the power is less in the finances and more in the
|
||||
collective efforts. I really appreciate every pull request and bug report
|
||||
offered up by Paperless' users, so please keep that stuff coming. If however,
|
||||
you're not one for coding/design/documentation, and would like to contribute
|
||||
financially, I won't say no ;-)
|
||||
|
||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to
|
||||
the `United Nations High Commissioner for Refugees`_. They're doing important
|
||||
work and they need the money a lot more than I do.
|
||||
|
||||
.. _scanner recommendations: https://paperless.readthedocs.io/en/latest/scanners.html
|
||||
.. _ImageMagick: http://imagemagick.org/
|
||||
.. _Tesseract: https://github.com/tesseract-ocr
|
||||
.. _Unpaper: https://www.flameeyes.eu/projects/unpaper
|
||||
.. _GNU Privacy Guard: https://gnupg.org/
|
||||
.. _Python 3: https://python.org/
|
||||
.. _Pillow: https://pypi.python.org/pypi/pillowfight/
|
||||
.. _PyOCR: https://github.com/jflesch/pyocr
|
||||
.. _Django: https://www.djangoproject.com/
|
||||
.. _Python-GNUPG: http://pythonhosted.org/python-gnupg/
|
||||
.. _ReadTheDocs: https://paperless.readthedocs.org/
|
||||
.. _Mayan EDMS: https://mayan.readthedocs.org/en/latest/
|
||||
.. _United Nations High Commissioner for Refugees: https://donate.unhcr.org/int-en/general
|
||||
.. |Documentation| image:: https://readthedocs.org/projects/paperless/badge/?version=latest
|
||||
:alt: Read the documentation at https://paperless.readthedocs.org/
|
||||
:target: https://paperless.readthedocs.org/
|
||||
.. |Chat| image:: https://badges.gitter.im/danielquinn/paperless.svg
|
||||
:alt: Join the chat at https://gitter.im/danielquinn/paperless
|
||||
:target: https://gitter.im/danielquinn/paperless?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge
|
||||
.. |Travis| image:: https://travis-ci.org/danielquinn/paperless.svg?branch=master
|
||||
:target: https://travis-ci.org/danielquinn/paperless
|
||||
.. |Dependencies| image:: https://www.versioneye.com/user/projects/57b33b81d9f1b00016faa500/badge.svg
|
||||
:target: https://www.versioneye.com/user/projects/57b33b81d9f1b00016faa500
|
||||
@@ -1,12 +1,19 @@
|
||||
version: '2'
|
||||
version: '2.1'
|
||||
|
||||
services:
|
||||
webserver:
|
||||
image: pitkley/paperless
|
||||
build: ./
|
||||
# uncomment the following line to start automatically on system boot
|
||||
# restart: always
|
||||
ports:
|
||||
# You can adapt the port you want Paperless to listen on by
|
||||
# modifying the part before the `:`.
|
||||
- "8000:8000"
|
||||
healthcheck:
|
||||
test: ["CMD", "curl" , "-f", "http://localhost:8000"]
|
||||
interval: 30s
|
||||
timeout: 10s
|
||||
retries: 5
|
||||
volumes:
|
||||
- data:/usr/src/paperless/data
|
||||
- media:/usr/src/paperless/media
|
||||
@@ -20,7 +27,12 @@ services:
|
||||
command: ["runserver", "--insecure", "0.0.0.0:8000"]
|
||||
|
||||
consumer:
|
||||
image: pitkley/paperless
|
||||
build: ./
|
||||
# uncomment the following line to start automatically on system boot
|
||||
# restart: always
|
||||
depends_on:
|
||||
webserver:
|
||||
condition: service_healthy
|
||||
volumes:
|
||||
- data:/usr/src/paperless/data
|
||||
- media:/usr/src/paperless/media
|
||||
|
||||
@@ -1,243 +1,325 @@
|
||||
Changelog
|
||||
#########
|
||||
|
||||
* 1.1.0
|
||||
* Fix for `#283`_, a redirect bug which broke interactions with
|
||||
paperless-desktop. Thanks to `chris-aeviator`_ for reporting it.
|
||||
* Addition of an optional new financial year filter, courtesy of
|
||||
`David Martin`_ `#256`_
|
||||
* Fixed a typo in how thumbnails were named in exports `#285`_, courtesy of
|
||||
`Dan Panzarella`_
|
||||
1.3.0 (Unreleased)
|
||||
==================
|
||||
|
||||
* 1.0.0
|
||||
* Upgrade to Django 1.11. **You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update**.
|
||||
* Replace the templatetag-based hack we had for document listing in favour of
|
||||
a slightly less ugly solution in the form of another template tag with less
|
||||
copypasta.
|
||||
* Support for multi-word-matches for auto-tagging thanks to an excellent
|
||||
patch from `ishirav`_ `#277`_.
|
||||
* Fixed a CSS bug reported by `Stefan Hagen`_ that caused an overlapping of
|
||||
the text and checkboxes under some resolutions `#272`_.
|
||||
* Patched the Docker config to force the serving of static files. Credit for
|
||||
this one goes to `dev-rke`_ via `#248`_.
|
||||
* Fix file permissions during Docker start up thanks to `Pit`_ on `#268`_.
|
||||
* Date fields in the admin are now expressed as HTML5 date fields thanks to
|
||||
`Lukas Winkler`_'s issue `#278`_
|
||||
* You can now run Paperless without a login, though you'll still have to create
|
||||
at least one user. This is thanks to a pull-request from `matthewmoto`_:
|
||||
`#295`_. Note that logins are still required by default, and that you need
|
||||
to disable them by setting ``PAPERLESS_DISABLE_LOGIN="true"`` in your
|
||||
environment or in ``/etc/paperless.conf``.
|
||||
* Fix for `#303`_ where sketchily-formatted documents could cause the consumer
|
||||
to break and insert half-records into the database breaking all sorts of
|
||||
things. We now capture the return codes of both ``convert`` and ``unpaper``
|
||||
and fail-out nicely.
|
||||
* Fix for additional date types thanks to input from `Isaac`_ and code from
|
||||
`BastianPoe`_ (`#301`_).
|
||||
* Fix for running migrations in the Docker container (`#299`_). Thanks to
|
||||
`Georgi Todorov`_ for the fix (`#300`_) and to `Pit`_ for the review.
|
||||
* Fix for Docker cases where the issuing user is not UID 1000. This was a
|
||||
collaborative fix between `Jeffrey Portman`_ and `Pit`_ in `#311`_ and
|
||||
`#312`_ to fix `#306`_.
|
||||
* Patch the historical migrations to support MySQL's um, *interesting* way of
|
||||
handing indexes (`#308`_). Thanks to `Simon Taddiken`_ for reporting the
|
||||
problem and helping me find where to fix it.
|
||||
|
||||
* 0.8.0
|
||||
* Paperless can now run in a subdirectory on a host (``/paperless``), rather
|
||||
than always running in the root (``/``) thanks to `maphy-psd`_'s work on
|
||||
`#255`_.
|
||||
1.2.0
|
||||
=====
|
||||
|
||||
* 0.7.0
|
||||
* **Potentially breaking change**: As per `#235`_, Paperless will no longer
|
||||
automatically delete documents attached to correspondents when those
|
||||
correspondents are themselves deleted. This was Django's default
|
||||
behaviour, but didn't make much sense in Paperless' case. Thanks to
|
||||
`Thomas Brueggemann`_ and `David Martin`_ for their input on this one.
|
||||
* Fix for `#232`_ wherein Paperless wasn't recognising ``.tif`` files
|
||||
properly. Thanks to `ayounggun`_ for reporting this one and to
|
||||
`Kusti Skytén`_ for posting the correct solution in the Github issue.
|
||||
* New Docker image, now based on Alpine, thanks to the efforts of `addadi`_
|
||||
and `Pit`_. This new image is dramatically smaller than the Debian-based
|
||||
one, and it also has `a new home on Docker Hub`_. A proper thank-you to
|
||||
`Pit`_ for hosting the image on his Docker account all this time, but after
|
||||
some discussion, we decided the image needed a more *official-looking* home.
|
||||
* `BastianPoe`_ has added the long-awaited feature to automatically skip the
|
||||
OCR step when the PDF already contains text. This can be overridden by
|
||||
setting ``PAPERLESS_OCR_ALWAYS=YES`` either in your ``paperless.conf`` or
|
||||
in the environment. Note that this also means that Paperless now requires
|
||||
``libpoppler-cpp-dev`` to be installed. **Important**: You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update.
|
||||
* `BastianPoe`_ has also contributed a monumental amount of work (`#291`_) to
|
||||
solving `#158`_: setting the document creation date based on finding a date
|
||||
in the document text.
|
||||
|
||||
* 0.6.0
|
||||
* Abandon the shared-secret trick we were using for the POST API in favour
|
||||
of BasicAuth or Django session.
|
||||
* Fix the POST API so it actually works. `#236`_
|
||||
* **Breaking change**: We've dropped the use of ``PAPERLESS_SHARED_SECRET``
|
||||
as it was being used both for the API (now replaced with a normal auth)
|
||||
and form email polling. Now that we're only using it for email, this
|
||||
variable has been renamed to ``PAPERLESS_EMAIL_SECRET``. The old value
|
||||
will still work for a while, but you should change your config if you've
|
||||
been using the email polling feature. Thanks to `Joshua Gilman`_ for all
|
||||
the help with this feature.
|
||||
* 0.5.0
|
||||
* Support for fuzzy matching in the auto-tagger & auto-correspondent systems
|
||||
thanks to `Jake Gysland`_'s patch `#220`_.
|
||||
* Modified the Dockerfile to prepare an export directory (`#212`_). Thanks
|
||||
to combined efforts from `Pit`_ and `Strubbl`_ in working out the kinks on
|
||||
this one.
|
||||
* Updated the import/export scripts to include support for thumbnails. Big
|
||||
thanks to `CkuT`_ for finding this shortcoming and doing the work to get
|
||||
it fixed in `#224`_.
|
||||
* All of the following changes are thanks to `David Martin`_:
|
||||
* Bumped the dependency on pyocr to 0.4.7 so new users can make use of
|
||||
Tesseract 4 if they so prefer (`#226`_).
|
||||
* Fixed a number of issues with the automated mail handler (`#227`_, `#228`_)
|
||||
* Amended the documentation for better handling of systemd service files (`#229`_)
|
||||
* Amended the Django Admin configuration to have nice headers (`#230`_)
|
||||
1.1.0
|
||||
=====
|
||||
|
||||
* 0.4.1
|
||||
* Fix for `#206`_ wherein the pluggable parser didn't recognise files with
|
||||
all-caps suffixes like ``.PDF``
|
||||
* Fix for `#283`_, a redirect bug which broke interactions with
|
||||
paperless-desktop. Thanks to `chris-aeviator`_ for reporting it.
|
||||
* Addition of an optional new financial year filter, courtesy of
|
||||
`David Martin`_ `#256`_
|
||||
* Fixed a typo in how thumbnails were named in exports `#285`_, courtesy of
|
||||
`Dan Panzarella`_
|
||||
|
||||
* 0.4.0
|
||||
* Introducing reminders. See `#199`_ for more information, but the short
|
||||
explanation is that you can now attach simple notes & times to documents
|
||||
which are made available via the API. Currently, the default API
|
||||
(basically just the Django admin) doesn't really make use of this, but
|
||||
`Thomas Brueggemann`_ over at `Paperless Desktop`_ has said that he would
|
||||
like to make use of this feature in his project.
|
||||
1.0.0
|
||||
=====
|
||||
|
||||
* 0.3.6
|
||||
* Fix for `#200`_ (!!) where the API wasn't configured to allow updating the
|
||||
correspondent or the tags for a document.
|
||||
* The ``content`` field is now optional, to allow for the edge case of a
|
||||
purely graphical document.
|
||||
* You can no longer add documents via the admin. This never worked in the
|
||||
first place, so all I've done here is remove the link to the broken form.
|
||||
* The consumer code has been heavily refactored to support a pluggable
|
||||
interface. Install a paperless consumer via pip and tell paperless about
|
||||
it with an environment variable, and you're good to go. Proper
|
||||
documentation is on its way.
|
||||
* Upgrade to Django 1.11. **You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update**.
|
||||
* Replace the templatetag-based hack we had for document listing in favour of
|
||||
a slightly less ugly solution in the form of another template tag with less
|
||||
copypasta.
|
||||
* Support for multi-word-matches for auto-tagging thanks to an excellent
|
||||
patch from `ishirav`_ `#277`_.
|
||||
* Fixed a CSS bug reported by `Stefan Hagen`_ that caused an overlapping of
|
||||
the text and checkboxes under some resolutions `#272`_.
|
||||
* Patched the Docker config to force the serving of static files. Credit for
|
||||
this one goes to `dev-rke`_ via `#248`_.
|
||||
* Fix file permissions during Docker start up thanks to `Pit`_ on `#268`_.
|
||||
* Date fields in the admin are now expressed as HTML5 date fields thanks to
|
||||
`Lukas Winkler`_'s issue `#278`_
|
||||
|
||||
* 0.3.5
|
||||
* A serious facelift for the documents listing page wherein we drop the
|
||||
tabular layout in favour of a tiled interface.
|
||||
* Users can now configure the number of items per page.
|
||||
* Fix for `#171`_: Allow users to specify their own ``SECRET_KEY`` value.
|
||||
* Moved the dotenv loading to the top of settings.py
|
||||
* Fix for `#112`_: Added checks for binaries required for document
|
||||
consumption.
|
||||
0.8.0
|
||||
=====
|
||||
|
||||
* 0.3.4
|
||||
* Removal of django-suit due to a licensing conflict I bumped into in 0.3.3.
|
||||
Note that you *can* use Django Suit with Paperless, but only in a
|
||||
non-profit situation as their free license prohibits for-profit use. As a
|
||||
result, I can't bundle Suit with Paperless without conflicting with the
|
||||
GPL. Further development will be done against the stock Django admin.
|
||||
* I shrunk the thumbnails a little 'cause they were too big for me, even on
|
||||
my high-DPI monitor.
|
||||
* BasicAuth support for document and thumbnail downloads, as well as the Push
|
||||
API thanks to @thomasbrueggemann. See `#179`_.
|
||||
* Paperless can now run in a subdirectory on a host (``/paperless``), rather
|
||||
than always running in the root (``/``) thanks to `maphy-psd`_'s work on
|
||||
`#255`_.
|
||||
|
||||
* 0.3.3
|
||||
* Thumbnails in the UI and a Django-suit -based face-lift courtesy of @ekw!
|
||||
* Timezone, items per page, and default language are now all configurable,
|
||||
also thanks to @ekw.
|
||||
0.7.0
|
||||
=====
|
||||
|
||||
* 0.3.2
|
||||
* Fix for `#172`_: defaulting ALLOWED_HOSTS to ``["*"]`` and allowing the
|
||||
user to set her own value via ``PAPERLESS_ALLOWED_HOSTS`` should the need
|
||||
arise.
|
||||
* **Potentially breaking change**: As per `#235`_, Paperless will no longer
|
||||
automatically delete documents attached to correspondents when those
|
||||
correspondents are themselves deleted. This was Django's default
|
||||
behaviour, but didn't make much sense in Paperless' case. Thanks to
|
||||
`Thomas Brueggemann`_ and `David Martin`_ for their input on this one.
|
||||
* Fix for `#232`_ wherein Paperless wasn't recognising ``.tif`` files
|
||||
properly. Thanks to `ayounggun`_ for reporting this one and to
|
||||
`Kusti Skytén`_ for posting the correct solution in the Github issue.
|
||||
|
||||
* 0.3.1
|
||||
* Added a default value for ``CONVERT_BINARY``
|
||||
0.6.0
|
||||
=====
|
||||
|
||||
* 0.3.0
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
* Consumer loop time is now configurable for systems with slow writes. Just
|
||||
set ``PAPERLESS_CONSUMER_LOOP_TIME`` to a number of seconds. The default
|
||||
is 10.
|
||||
* As per `#44`_, we've removed support for ``PAPERLESS_CONVERT``,
|
||||
``PAPERLESS_CONSUME``, and ``PAPERLESS_SECRET``. Please use
|
||||
``PAPERLESS_CONVERT_BINARY``, ``PAPERLESS_CONSUMPTION_DIR``, and
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
* Abandon the shared-secret trick we were using for the POST API in favour
|
||||
of BasicAuth or Django session.
|
||||
* Fix the POST API so it actually works. `#236`_
|
||||
* **Breaking change**: We've dropped the use of ``PAPERLESS_SHARED_SECRET``
|
||||
as it was being used both for the API (now replaced with a normal auth)
|
||||
and form email polling. Now that we're only using it for email, this
|
||||
variable has been renamed to ``PAPERLESS_EMAIL_SECRET``. The old value
|
||||
will still work for a while, but you should change your config if you've
|
||||
been using the email polling feature. Thanks to `Joshua Gilman`_ for all
|
||||
the help with this feature.
|
||||
|
||||
* 0.2.0
|
||||
0.5.0
|
||||
=====
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#148`_: The database location (sqlite) is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#146`_: Fixed a bug that allowed unauthorised access to the ``/fetch``
|
||||
URL.
|
||||
* `#131`_: Document files are now automatically removed from disk when
|
||||
they're deleted in Paperless.
|
||||
* `#121`_: Fixed a bug where Paperless wasn't setting document creation time
|
||||
based on the file naming scheme.
|
||||
* `#81`_: Added a hook to run an arbitrary script after every document is
|
||||
consumed.
|
||||
* `#98`_: Added optional environment variables for ImageMagick so that it
|
||||
doesn't explode when handling Very Large Documents or when it's just
|
||||
running on a low-memory system. Thanks to `Florian Harr`_ for his help on
|
||||
this one.
|
||||
* `#89`_ Ported the auto-tagging code to correspondents as well. Thanks to
|
||||
`Justin Snyman`_ for the pointers in the issue queue.
|
||||
* Added support for guessing the date from the file name along with the
|
||||
correspondent, title, and tags. Thanks to `Tikitu de Jager`_ for his pull
|
||||
request that I took forever to merge and to `Pit`_ for his efforts on the
|
||||
regex front.
|
||||
* `#94`_: Restored support for changing the created date in the UI. Thanks
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
* Support for fuzzy matching in the auto-tagger & auto-correspondent systems
|
||||
thanks to `Jake Gysland`_'s patch `#220`_.
|
||||
* Modified the Dockerfile to prepare an export directory (`#212`_). Thanks
|
||||
to combined efforts from `Pit`_ and `Strubbl`_ in working out the kinks on
|
||||
this one.
|
||||
* Updated the import/export scripts to include support for thumbnails. Big
|
||||
thanks to `CkuT`_ for finding this shortcoming and doing the work to get
|
||||
it fixed in `#224`_.
|
||||
* All of the following changes are thanks to `David Martin`_:
|
||||
* Bumped the dependency on pyocr to 0.4.7 so new users can make use of
|
||||
Tesseract 4 if they so prefer (`#226`_).
|
||||
* Fixed a number of issues with the automated mail handler (`#227`_, `#228`_)
|
||||
* Amended the documentation for better handling of systemd service files (`#229`_)
|
||||
* Amended the Django Admin configuration to have nice headers (`#230`_)
|
||||
|
||||
* 0.1.1
|
||||
0.4.1
|
||||
=====
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
property (one could quite reasonably scan a document before sending it to
|
||||
someone.)
|
||||
* `#67`_: Rewrote the document exporter and added a new importer that allows
|
||||
for full metadata retention without depending on the file name and
|
||||
modification time. A big thanks to `Tikitu de Jager`_, `Pit`_,
|
||||
`Florian Jung`_, and `Christopher Luu`_ for their code snippets and
|
||||
contributing conversation that lead to this change.
|
||||
* `#20`_: Added *unpaper* support to help in cleaning up the scanned image
|
||||
before it's OCR'd. Thanks to `Pit`_ for this one.
|
||||
* `#71`_ Added (encrypted) thumbnails in anticipation of a proper UI.
|
||||
* `#68`_: Added support for using a proper config file at
|
||||
``/etc/paperless.conf`` and modified the systemd unit files to use it.
|
||||
* Refactored the Vagrant installation process to use environment variables
|
||||
rather than asking the user to modify ``settings.py``.
|
||||
* `#44`_: Harmonise environment variable names with constant names.
|
||||
* `#60`_: Setup logging to actually use the Python native logging framework.
|
||||
* `#53`_: Fixed an annoying bug that caused ``.jpeg`` and ``.JPG`` images
|
||||
to be imported but made unavailable.
|
||||
* Fix for `#206`_ wherein the pluggable parser didn't recognise files with
|
||||
all-caps suffixes like ``.PDF``
|
||||
|
||||
* 0.1.0
|
||||
0.4.0
|
||||
=====
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
who spearheadded this effort.
|
||||
* A simple REST API is in place, but it should be considered unstable.
|
||||
* Cleaned up the consumer to use temporary directories instead of a single
|
||||
scratch space. (Thanks `Pit`_)
|
||||
* Improved the efficiency of the consumer by parsing pages more intelligently
|
||||
and introducing a threaded OCR process (thanks again `Pit`_).
|
||||
* `#45`_: Cleaned up the logic for tag matching. Reported by `darkmatter`_.
|
||||
* `#47`_: Auto-rotate landscape documents. Reported by `Paul`_ and fixed by
|
||||
`Pit`_.
|
||||
* `#48`_: Matching algorithms should do so on a word boundary (`darkmatter`_)
|
||||
* `#54`_: Documented the re-tagger (`zedster`_)
|
||||
* `#57`_: Make sure file is preserved on import failure (`darkmatter`_)
|
||||
* Added tox with pep8 checking
|
||||
* Introducing reminders. See `#199`_ for more information, but the short
|
||||
explanation is that you can now attach simple notes & times to documents
|
||||
which are made available via the API. Currently, the default API
|
||||
(basically just the Django admin) doesn't really make use of this, but
|
||||
`Thomas Brueggemann`_ over at `Paperless Desktop`_ has said that he would
|
||||
like to make use of this feature in his project.
|
||||
|
||||
* 0.0.6
|
||||
0.3.6
|
||||
=====
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
* Fix for `#200`_ (!!) where the API wasn't configured to allow updating the
|
||||
correspondent or the tags for a document.
|
||||
* The ``content`` field is now optional, to allow for the edge case of a
|
||||
purely graphical document.
|
||||
* You can no longer add documents via the admin. This never worked in the
|
||||
first place, so all I've done here is remove the link to the broken form.
|
||||
* The consumer code has been heavily refactored to support a pluggable
|
||||
interface. Install a paperless consumer via pip and tell paperless about
|
||||
it with an environment variable, and you're good to go. Proper
|
||||
documentation is on its way.
|
||||
|
||||
* 0.0.5
|
||||
0.3.5
|
||||
=====
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
* Added IMAP mail support
|
||||
* Added a re-tagging utility
|
||||
* Documentation for the above as well as data migration
|
||||
* A serious facelift for the documents listing page wherein we drop the
|
||||
tabular layout in favour of a tiled interface.
|
||||
* Users can now configure the number of items per page.
|
||||
* Fix for `#171`_: Allow users to specify their own ``SECRET_KEY`` value.
|
||||
* Moved the dotenv loading to the top of settings.py
|
||||
* Fix for `#112`_: Added checks for binaries required for document
|
||||
consumption.
|
||||
|
||||
* 0.0.4
|
||||
0.3.4
|
||||
=====
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
* Removed ``User`` and ``Group`` from the admin
|
||||
* Added ``pytz`` to the list of requirements
|
||||
* Removal of django-suit due to a licensing conflict I bumped into in 0.3.3.
|
||||
Note that you *can* use Django Suit with Paperless, but only in a
|
||||
non-profit situation as their free license prohibits for-profit use. As a
|
||||
result, I can't bundle Suit with Paperless without conflicting with the
|
||||
GPL. Further development will be done against the stock Django admin.
|
||||
* I shrunk the thumbnails a little 'cause they were too big for me, even on
|
||||
my high-DPI monitor.
|
||||
* BasicAuth support for document and thumbnail downloads, as well as the Push
|
||||
API thanks to @thomasbrueggemann. See `#179`_.
|
||||
|
||||
* 0.0.3
|
||||
0.3.3
|
||||
=====
|
||||
|
||||
* Added basic tagging
|
||||
* Thumbnails in the UI and a Django-suit -based face-lift courtesy of @ekw!
|
||||
* Timezone, items per page, and default language are now all configurable,
|
||||
also thanks to @ekw.
|
||||
|
||||
* 0.0.2
|
||||
0.3.2
|
||||
=====
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
* Fix for `#172`_: defaulting ALLOWED_HOSTS to ``["*"]`` and allowing the
|
||||
user to set her own value via ``PAPERLESS_ALLOWED_HOSTS`` should the need
|
||||
arise.
|
||||
|
||||
* 0.0.1
|
||||
0.3.1
|
||||
=====
|
||||
|
||||
* Initial release
|
||||
* Added a default value for ``CONVERT_BINARY``
|
||||
|
||||
0.3.0
|
||||
=====
|
||||
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
* Consumer loop time is now configurable for systems with slow writes. Just
|
||||
set ``PAPERLESS_CONSUMER_LOOP_TIME`` to a number of seconds. The default
|
||||
is 10.
|
||||
* As per `#44`_, we've removed support for ``PAPERLESS_CONVERT``,
|
||||
``PAPERLESS_CONSUME``, and ``PAPERLESS_SECRET``. Please use
|
||||
``PAPERLESS_CONVERT_BINARY``, ``PAPERLESS_CONSUMPTION_DIR``, and
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
|
||||
0.2.0
|
||||
=====
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#148`_: The database location (sqlite) is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#146`_: Fixed a bug that allowed unauthorised access to the ``/fetch``
|
||||
URL.
|
||||
* `#131`_: Document files are now automatically removed from disk when
|
||||
they're deleted in Paperless.
|
||||
* `#121`_: Fixed a bug where Paperless wasn't setting document creation time
|
||||
based on the file naming scheme.
|
||||
* `#81`_: Added a hook to run an arbitrary script after every document is
|
||||
consumed.
|
||||
* `#98`_: Added optional environment variables for ImageMagick so that it
|
||||
doesn't explode when handling Very Large Documents or when it's just
|
||||
running on a low-memory system. Thanks to `Florian Harr`_ for his help on
|
||||
this one.
|
||||
* `#89`_ Ported the auto-tagging code to correspondents as well. Thanks to
|
||||
`Justin Snyman`_ for the pointers in the issue queue.
|
||||
* Added support for guessing the date from the file name along with the
|
||||
correspondent, title, and tags. Thanks to `Tikitu de Jager`_ for his pull
|
||||
request that I took forever to merge and to `Pit`_ for his efforts on the
|
||||
regex front.
|
||||
* `#94`_: Restored support for changing the created date in the UI. Thanks
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
|
||||
0.1.1
|
||||
=====
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
property (one could quite reasonably scan a document before sending it to
|
||||
someone.)
|
||||
* `#67`_: Rewrote the document exporter and added a new importer that allows
|
||||
for full metadata retention without depending on the file name and
|
||||
modification time. A big thanks to `Tikitu de Jager`_, `Pit`_,
|
||||
`Florian Jung`_, and `Christopher Luu`_ for their code snippets and
|
||||
contributing conversation that lead to this change.
|
||||
* `#20`_: Added *unpaper* support to help in cleaning up the scanned image
|
||||
before it's OCR'd. Thanks to `Pit`_ for this one.
|
||||
* `#71`_ Added (encrypted) thumbnails in anticipation of a proper UI.
|
||||
* `#68`_: Added support for using a proper config file at
|
||||
``/etc/paperless.conf`` and modified the systemd unit files to use it.
|
||||
* Refactored the Vagrant installation process to use environment variables
|
||||
rather than asking the user to modify ``settings.py``.
|
||||
* `#44`_: Harmonise environment variable names with constant names.
|
||||
* `#60`_: Setup logging to actually use the Python native logging framework.
|
||||
* `#53`_: Fixed an annoying bug that caused ``.jpeg`` and ``.JPG`` images
|
||||
to be imported but made unavailable.
|
||||
|
||||
0.1.0
|
||||
=====
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
who spearheadded this effort.
|
||||
* A simple REST API is in place, but it should be considered unstable.
|
||||
* Cleaned up the consumer to use temporary directories instead of a single
|
||||
scratch space. (Thanks `Pit`_)
|
||||
* Improved the efficiency of the consumer by parsing pages more intelligently
|
||||
and introducing a threaded OCR process (thanks again `Pit`_).
|
||||
* `#45`_: Cleaned up the logic for tag matching. Reported by `darkmatter`_.
|
||||
* `#47`_: Auto-rotate landscape documents. Reported by `Paul`_ and fixed by
|
||||
`Pit`_.
|
||||
* `#48`_: Matching algorithms should do so on a word boundary (`darkmatter`_)
|
||||
* `#54`_: Documented the re-tagger (`zedster`_)
|
||||
* `#57`_: Make sure file is preserved on import failure (`darkmatter`_)
|
||||
* Added tox with pep8 checking
|
||||
|
||||
0.0.6
|
||||
=====
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
|
||||
0.0.5
|
||||
=====
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
* Added IMAP mail support
|
||||
* Added a re-tagging utility
|
||||
* Documentation for the above as well as data migration
|
||||
|
||||
0.0.4
|
||||
=====
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
* Removed ``User`` and ``Group`` from the admin
|
||||
* Added ``pytz`` to the list of requirements
|
||||
|
||||
0.0.3
|
||||
=====
|
||||
|
||||
* Added basic tagging
|
||||
|
||||
0.0.2
|
||||
=====
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
|
||||
0.0.1
|
||||
=====
|
||||
|
||||
* Initial release
|
||||
|
||||
.. _Brian Conn: https://github.com/TheConnMan
|
||||
.. _Christopher Luu: https://github.com/nuudles
|
||||
@@ -268,6 +350,13 @@ Changelog
|
||||
.. _Lukas Winkler: https://github.com/Findus23
|
||||
.. _chris-aeviator: https://github.com/chris-aeviator
|
||||
.. _Dan Panzarella: https://github.com/pzl
|
||||
.. _addadi: https://github.com/addadi
|
||||
.. _BastianPoe: https://github.com/BastianPoe
|
||||
.. _matthewmoto: https://github.com/BastianPoe
|
||||
.. _Isaac: https://github.com/isaacsando
|
||||
.. _Georgi Todorov: https://github.com/TeraHz
|
||||
.. _Jeffrey Portman: https://github.com/ChromoX
|
||||
.. _Simon Taddiken: https://github.com/skuzzle
|
||||
|
||||
.. _#20: https://github.com/danielquinn/paperless/issues/20
|
||||
.. _#44: https://github.com/danielquinn/paperless/issues/44
|
||||
@@ -291,6 +380,7 @@ Changelog
|
||||
.. _#146: https://github.com/danielquinn/paperless/issues/146
|
||||
.. _#148: https://github.com/danielquinn/paperless/pull/148
|
||||
.. _#150: https://github.com/danielquinn/paperless/pull/150
|
||||
.. _#158: https://github.com/danielquinn/paperless/issues/158
|
||||
.. _#171: https://github.com/danielquinn/paperless/issues/171
|
||||
.. _#172: https://github.com/danielquinn/paperless/issues/172
|
||||
.. _#179: https://github.com/danielquinn/paperless/pull/179
|
||||
@@ -317,3 +407,16 @@ Changelog
|
||||
.. _#283: https://github.com/danielquinn/paperless/issues/283
|
||||
.. _#256: https://github.com/danielquinn/paperless/pull/256
|
||||
.. _#285: https://github.com/danielquinn/paperless/pull/285
|
||||
.. _#291: https://github.com/danielquinn/paperless/pull/291
|
||||
.. _#295: https://github.com/danielquinn/paperless/pull/295
|
||||
.. _#299: https://github.com/danielquinn/paperless/issues/299
|
||||
.. _#300: https://github.com/danielquinn/paperless/pull/300
|
||||
.. _#301: https://github.com/danielquinn/paperless/issues/301
|
||||
.. _#303: https://github.com/danielquinn/paperless/issues/303
|
||||
.. _#306: https://github.com/danielquinn/paperless/issues/306
|
||||
.. _#308: https://github.com/danielquinn/paperless/issues/308
|
||||
.. _#311: https://github.com/danielquinn/paperless/pull/311
|
||||
.. _#312: https://github.com/danielquinn/paperless/pull/312
|
||||
|
||||
.. _pipenv: https://docs.pipenv.org/
|
||||
.. _a new home on Docker Hub: https://hub.docker.com/r/danielquinn/paperless/
|
||||
|
||||
112
docs/extending.rst
Normal file
112
docs/extending.rst
Normal file
@@ -0,0 +1,112 @@
|
||||
.. _extending:
|
||||
|
||||
Extending Paperless
|
||||
===================
|
||||
|
||||
For the most part, Paperless is monolithic, so extending it is often best
|
||||
managed by way of modifying the code directly and issuing a pull request on
|
||||
`GitHub`_. However, over time the project has been evolving to be a little
|
||||
more "pluggable" so that users can write their own stuff that talks to it.
|
||||
|
||||
.. _GitHub: https://github.com/danielquinn/paperless
|
||||
|
||||
|
||||
.. _extending-parsers:
|
||||
|
||||
Parsers
|
||||
-------
|
||||
|
||||
You can leverage Paperless' consumption model to have it consume files *other*
|
||||
than ones handled by default like ``.pdf``, ``.jpg``, and ``.tiff``. To do so,
|
||||
you simply follow Django's convention of creating a new app, with a few key
|
||||
requirements.
|
||||
|
||||
|
||||
.. _extending-parsers-parserspy:
|
||||
|
||||
parsers.py
|
||||
..........
|
||||
|
||||
In this file, you create a class that extends
|
||||
``documents.parsers.DocumentParser`` and go about implementing the three
|
||||
required methods:
|
||||
|
||||
* ``get_thumbnail()``: Returns the path to a file we can use as a thumbnail for
|
||||
this document.
|
||||
* ``get_text()``: Returns the text from the document and only the text.
|
||||
* ``get_date()``: If possible, this returns the date of the document, otherwise
|
||||
it should return ``None``.
|
||||
|
||||
|
||||
.. _extending-parsers-signalspy:
|
||||
|
||||
signals.py
|
||||
..........
|
||||
|
||||
At consumption time, Paperless emits a ``document_consumer_declaration``
|
||||
signal which your module has to react to in order to let the consumer know
|
||||
whether or not it's capable of handling a particular file. Think of it like
|
||||
this:
|
||||
|
||||
1. Consumer finds a file in the consumption directory.
|
||||
2. It asks all the available parsers: *"Hey, can you handle this file?"*
|
||||
3. Each parser responds with either ``None`` meaning they can't handle the
|
||||
file, or a dictionary in the following format:
|
||||
|
||||
.. code:: python
|
||||
|
||||
{
|
||||
"parser": <the class name>,
|
||||
"weight": <an integer>
|
||||
}
|
||||
|
||||
The consumer compares the ``weight`` values from all respondents and uses the
|
||||
class with the highest value to consume the document. The default parser,
|
||||
``RasterisedDocumentParser`` has a weight of ``0``.
|
||||
|
||||
|
||||
.. _extending-parsers-appspy:
|
||||
|
||||
apps.py
|
||||
.......
|
||||
|
||||
This is a standard Django file, but you'll need to add some code to it to
|
||||
connect your parser to the ``document_consumer_declaration`` signal.
|
||||
|
||||
|
||||
.. _extending-parsers-finally:
|
||||
|
||||
Finally
|
||||
.......
|
||||
|
||||
The last step is to update ``settings.py`` to include your new module.
|
||||
Eventually, this will be dynamic, but at the moment, you have to edit the
|
||||
``INSTALLED_APPS`` section manually. Simply add the path to your AppConfig to
|
||||
the list like this:
|
||||
|
||||
.. code:: python
|
||||
|
||||
INSTALLED_APPS = [
|
||||
...
|
||||
"my_module.apps.MyModuleConfig",
|
||||
...
|
||||
]
|
||||
|
||||
Order doesn't matter, but generally it's a good idea to place your module lower
|
||||
in the list so that you don't end up accidentally overriding project defaults
|
||||
somewhere.
|
||||
|
||||
|
||||
.. _extending-parsers-example:
|
||||
|
||||
An Example
|
||||
..........
|
||||
|
||||
The core Paperless functionality is based on this design, so if you want to see
|
||||
what a parser module should look like, have a look at `parsers.py`_,
|
||||
`signals.py`_, and `apps.py`_ in the `paperless_tesseract`_ module.
|
||||
|
||||
.. _parsers.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/parsers.py
|
||||
.. _signals.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/signals.py
|
||||
.. _apps.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/apps.py
|
||||
.. _paperless_tesseract: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/
|
||||
@@ -5,9 +5,9 @@ Paperless
|
||||
|
||||
Paperless is a simple Django application running in two parts:
|
||||
a :ref:`consumer <utilities-consumer>` (the thing that does the indexing) and
|
||||
the :ref:`webserver <utilities-webserver>` (the part that lets you search & download
|
||||
already-indexed documents). If you want to learn more about its functions keep on
|
||||
reading after the installation section.
|
||||
the :ref:`webserver <utilities-webserver>` (the part that lets you search &
|
||||
download already-indexed documents). If you want to learn more about its
|
||||
functions keep on reading after the installation section.
|
||||
|
||||
|
||||
.. _index-why-this-exists:
|
||||
@@ -16,12 +16,13 @@ Why This Exists
|
||||
===============
|
||||
|
||||
Paper is a nightmare. Environmental issues aside, there's no excuse for it in
|
||||
the 21st century. It takes up space, collects dust, doesn't support any form of
|
||||
a search feature, indexing is tedious, it's heavy and prone to damage & loss.
|
||||
the 21st century. It takes up space, collects dust, doesn't support any form
|
||||
of a search feature, indexing is tedious, it's heavy and prone to damage &
|
||||
loss.
|
||||
|
||||
I wrote this to make "going paperless" easier. I do not have to worry about
|
||||
finding stuff again. I feed documents right from the post box into the scanner and
|
||||
then shred them. Perhaps you might find it useful too.
|
||||
finding stuff again. I feed documents right from the post box into the scanner
|
||||
and then shred them. Perhaps you might find it useful too.
|
||||
|
||||
|
||||
|
||||
@@ -39,6 +40,7 @@ Contents
|
||||
utilities
|
||||
guesswork
|
||||
migrating
|
||||
extending
|
||||
troubleshooting
|
||||
scanners
|
||||
changelog
|
||||
|
||||
@@ -94,7 +94,7 @@ You may want to take a look at the ``paperless.conf.example`` file to see if
|
||||
there's anything new in there compared to what you've got int ``/etc``.
|
||||
|
||||
If you are :ref:`using Docker <setup-installation-docker>` the update process
|
||||
requires only one additional step:
|
||||
is similar:
|
||||
|
||||
.. code-block:: shell-session
|
||||
|
||||
@@ -102,7 +102,6 @@ requires only one additional step:
|
||||
$ git pull
|
||||
$ docker build -t paperless .
|
||||
$ docker-compose up -d
|
||||
$ docker-compose run --rm webserver migrate
|
||||
|
||||
If ``git pull`` doesn't report any changes, there is no need to continue with
|
||||
the remaining steps.
|
||||
|
||||
@@ -11,24 +11,27 @@ should work) that has the following software installed:
|
||||
* `Tesseract`_, plus its language files matching your document base.
|
||||
* `Imagemagick`_ version 6.7.5 or higher
|
||||
* `unpaper`_
|
||||
* `libpoppler-cpp-dev`_ PDF rendering library
|
||||
|
||||
.. _Python3: https://python.org/
|
||||
.. _GNU Privacy Guard: https://gnupg.org
|
||||
.. _Tesseract: https://github.com/tesseract-ocr
|
||||
.. _Imagemagick: http://imagemagick.org/
|
||||
.. _unpaper: https://www.flameeyes.eu/projects/unpaper
|
||||
.. _libpoppler-cpp-dev: https://poppler.freedesktop.org/
|
||||
|
||||
Notably, you should confirm how you access your Python3 installation. Many
|
||||
Linux distributions will install Python3 in parallel to Python2, using the names
|
||||
``python3`` and ``python`` respectively. The same goes for ``pip3`` and
|
||||
``pip``. Running Paperless with Python2 will likely break things, so make sure that
|
||||
you're using the right version.
|
||||
Linux distributions will install Python3 in parallel to Python2, using the
|
||||
names ``python3`` and ``python`` respectively. The same goes for ``pip3`` and
|
||||
``pip``. Running Paperless with Python2 will likely break things, so make sure
|
||||
that you're using the right version.
|
||||
|
||||
For the purposes of simplicity, ``python`` and ``pip`` is used everywhere to
|
||||
refer to their Python3 versions.
|
||||
|
||||
In addition to the above, there are a number of Python requirements, all of
|
||||
which are listed in a file called ``requirements.txt`` in the project root directory.
|
||||
which are listed in a file called ``requirements.txt`` in the project root
|
||||
directory.
|
||||
|
||||
If you're not working on a virtual environment (like Vagrant or Docker), you
|
||||
should probably be using a virtualenv, but that's your call. The reasons why
|
||||
@@ -39,12 +42,13 @@ probably figure that out before continuing.
|
||||
|
||||
.. _requirements-apple:
|
||||
|
||||
Apple-tastic Complications
|
||||
--------------------------
|
||||
Problems with Imagemagick & PDFs
|
||||
--------------------------------
|
||||
|
||||
Some users have `run into problems`_ with installing ImageMagick on Apple
|
||||
systems using HomeBrew. The solution appears to be to install ghostscript as
|
||||
well as ImageMagick:
|
||||
Some users have `run into problems`_ with getting ImageMagick to do its thing
|
||||
with PDFs. Often this is the case with Apple systems using HomeBrew, but other
|
||||
Linuxes have been a problem as well. The solution appears to be to install
|
||||
ghostscript as well as ImageMagick:
|
||||
|
||||
.. _run into problems: https://github.com/danielquinn/paperless/issues/25
|
||||
|
||||
|
||||
102
docs/setup.rst
102
docs/setup.rst
@@ -95,48 +95,6 @@ Standard (Bare Metal)
|
||||
.. _Paperless webserver: http://127.0.0.1:8000
|
||||
|
||||
|
||||
.. _setup-installation-vagrant:
|
||||
|
||||
Vagrant Method
|
||||
..............
|
||||
|
||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||
provisioned...
|
||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||
``/etc/paperless.conf`` and set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document.
|
||||
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
||||
documents from mail or via the API. If you don't use either, leaving it
|
||||
blank is just fine.
|
||||
|
||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||
updates the environment to make use of the changes you made to the config
|
||||
file.
|
||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||
create your user.
|
||||
7. Start the webserver with
|
||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||
You can login with the user/pass you created in #6.
|
||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||
your vagrant instance, you should start the consumer script with
|
||||
``/opt/paperless/src/manage.py document_consumer``.
|
||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
10. Wait a few minutes
|
||||
11. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. _Vagrant: https://vagrantup.com/
|
||||
.. _Paperless server: http://172.28.128.4:8000
|
||||
|
||||
|
||||
.. _setup-installation-docker:
|
||||
|
||||
Docker Method
|
||||
@@ -175,7 +133,8 @@ Docker Method
|
||||
modified versions of the configuration files.
|
||||
4. Modify ``docker-compose.yml`` to your preferences, following the
|
||||
instructions in comments in the file. The only change that is a hard
|
||||
requirement is to specify where the consumption directory should mount.
|
||||
requirement is to specify where the consumption directory should
|
||||
mount.[#dockercomposeyml]_
|
||||
5. Modify ``docker-compose.env`` and adapt the following environment variables:
|
||||
|
||||
``PAPERLESS_PASSPHRASE``
|
||||
@@ -192,7 +151,7 @@ Docker Method
|
||||
default English, set this parameter to a space separated list of
|
||||
three-letter language-codes after `ISO 639-2/T`_. For a list of available
|
||||
languages -- including their three letter codes -- see the
|
||||
`Debian packagelist`_.
|
||||
`Alpine packagelist`_.
|
||||
|
||||
``USERMAP_UID`` and ``USERMAP_GID``
|
||||
If you want to mount the consumption volume (directory ``/consume`` within
|
||||
@@ -282,12 +241,60 @@ Docker Method
|
||||
.. _Docker: https://www.docker.com/
|
||||
.. _docker-compose: https://docs.docker.com/compose/install/
|
||||
.. _ISO 639-2/T: https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes
|
||||
.. _Debian packagelist: https://packages.debian.org/search?suite=jessie&searchon=names&keywords=tesseract-ocr-
|
||||
.. _Alpine packagelist: https://pkgs.alpinelinux.org/packages?name=tesseract-ocr-data*&arch=x86_64
|
||||
|
||||
.. [#compose] You of course don't have to use docker-compose, but it
|
||||
simplifies deployment immensely. If you know your way around Docker, feel
|
||||
free to tinker around without using compose!
|
||||
|
||||
.. [#dockercomposeyml] If you're upgrading your docker-compose images from
|
||||
version 1.1.0 or earlier, you might need to change in the
|
||||
``docker-compose.yml`` file the ``image: pitkley/paperless`` directive in
|
||||
both the ``webserver`` and ``consumer`` sections to ``build: ./`` as per the
|
||||
newer ``docker-compose.yml.example`` file
|
||||
|
||||
|
||||
.. _setup-installation-vagrant:
|
||||
|
||||
Vagrant Method
|
||||
..............
|
||||
|
||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||
provisioned...
|
||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||
``/etc/paperless.conf`` and set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document.
|
||||
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
||||
documents from mail or via the API. If you don't use either, leaving it
|
||||
blank is just fine.
|
||||
|
||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||
updates the environment to make use of the changes you made to the config
|
||||
file.
|
||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||
create your user.
|
||||
7. Start the webserver with
|
||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||
You can login with the user/pass you created in #6.
|
||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||
your vagrant instance, you should start the consumer script with
|
||||
``/opt/paperless/src/manage.py document_consumer``.
|
||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
10. Wait a few minutes
|
||||
11. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. _Vagrant: https://vagrantup.com/
|
||||
.. _Paperless server: http://172.28.128.4:8000
|
||||
|
||||
|
||||
.. _setup-permanent:
|
||||
|
||||
@@ -563,7 +570,8 @@ your gunicorn instance. This should do the trick:
|
||||
Vagrant
|
||||
.......
|
||||
|
||||
You may use the Ubuntu explanation above. Replace ``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||
You may use the Ubuntu explanation above. Replace
|
||||
``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||
|
||||
.. _setup-permanent-docker:
|
||||
|
||||
@@ -577,7 +585,7 @@ Docker daemon.
|
||||
.. _restart-policy: https://docs.docker.com/engine/reference/commandline/run/#restart-policies-restart
|
||||
|
||||
|
||||
.. _setup-subdirectory
|
||||
.. _setup-subdirectory:
|
||||
|
||||
Hosting Paperless in a Subdirectory
|
||||
-----------------------------------
|
||||
|
||||
@@ -86,6 +86,11 @@ PAPERLESS_PASSPHRASE="secret"
|
||||
# https://docs.djangoproject.com/en/1.11/ref/settings/#force-script-name
|
||||
#PAPERLESS_FORCE_SCRIPT_NAME=""
|
||||
|
||||
# If you are using alternative authentication means or are just using paperless
|
||||
# as a single user on a small private network, this option allows you to disable
|
||||
# user authentication if you set it to "true"
|
||||
#PAPERLESS_DISABLE_LOGIN="false"
|
||||
|
||||
###############################################################################
|
||||
#### Software Tweaks ####
|
||||
###############################################################################
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
Django>=1.11,<2.0
|
||||
Pillow>=3.1.1
|
||||
dateparser>=0.6.0
|
||||
django-crispy-forms>=1.6.1
|
||||
django-extensions>=1.7.6
|
||||
django-filter>=1.0
|
||||
@@ -7,20 +8,21 @@ django-flat-responsive>=1.2.0
|
||||
djangorestframework>=3.5.3
|
||||
filemagic>=1.6
|
||||
fuzzywuzzy[speedup]==0.15.0
|
||||
gunicorn>=19.7.1
|
||||
langdetect>=1.0.7
|
||||
pdftotext>=2.0.1
|
||||
pyocr>=0.4.7
|
||||
python-dateutil>=2.6.0
|
||||
python-dotenv>=0.6.2
|
||||
python-gnupg>=0.3.9
|
||||
pytz>=2016.10
|
||||
gunicorn==19.7.1
|
||||
|
||||
# For the tests
|
||||
factory-boy
|
||||
pytest
|
||||
flake8
|
||||
pytest==3.3.2 # Newer versions break with pytest-sugar
|
||||
pytest-django
|
||||
pytest-sugar
|
||||
pytest-env
|
||||
pycodestyle
|
||||
flake8
|
||||
tox
|
||||
|
||||
@@ -4,13 +4,13 @@ set -e
|
||||
# Source: https://github.com/sameersbn/docker-gitlab/
|
||||
map_uidgid() {
|
||||
USERMAP_ORIG_UID=$(id -u paperless)
|
||||
USERMAP_ORIG_UID=$(id -g paperless)
|
||||
USERMAP_GID=${USERMAP_GID:-${USERMAP_UID:-$USERMAP_ORIG_GID}}
|
||||
USERMAP_UID=${USERMAP_UID:-$USERMAP_ORIG_UID}
|
||||
if [[ ${USERMAP_UID} != "${USERMAP_ORIG_UID}" || ${USERMAP_GID} != "${USERMAP_ORIG_GID}" ]]; then
|
||||
echo "Mapping UID and GID for paperless:paperless to $USERMAP_UID:$USERMAP_GID"
|
||||
groupmod -g "${USERMAP_GID}" paperless
|
||||
sed -i -e "s|:${USERMAP_ORIG_UID}:${USERMAP_GID}:|:${USERMAP_UID}:${USERMAP_GID}:|" /etc/passwd
|
||||
USERMAP_ORIG_GID=$(id -g paperless)
|
||||
USERMAP_NEW_UID=${USERMAP_UID:-$USERMAP_ORIG_UID}
|
||||
USERMAP_NEW_GID=${USERMAP_GID:-${USERMAP_ORIG_GID:-$USERMAP_NEW_UID}}
|
||||
if [[ ${USERMAP_NEW_UID} != "${USERMAP_ORIG_UID}" || ${USERMAP_NEW_GID} != "${USERMAP_ORIG_GID}" ]]; then
|
||||
echo "Mapping UID and GID for paperless:paperless to $USERMAP_NEW_UID:$USERMAP_NEW_GID"
|
||||
usermod -u "${USERMAP_NEW_UID}" paperless
|
||||
groupmod -g "${USERMAP_NEW_GID}" paperless
|
||||
fi
|
||||
}
|
||||
|
||||
@@ -42,9 +42,24 @@ set_permissions() {
|
||||
chown -Rh paperless:paperless /usr/src/paperless
|
||||
}
|
||||
|
||||
migrations() {
|
||||
# A simple lock file in case other containers use this startup
|
||||
LOCKFILE="/usr/src/paperless/data/db.sqlite3.migration"
|
||||
|
||||
set -o noclobber
|
||||
# check for and create lock file in one command
|
||||
(> ${LOCKFILE}) &> /dev/null
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
sudo -HEu paperless "/usr/src/paperless/src/manage.py" "migrate"
|
||||
rm ${LOCKFILE}
|
||||
fi
|
||||
}
|
||||
|
||||
initialize() {
|
||||
map_uidgid
|
||||
set_permissions
|
||||
migrations
|
||||
}
|
||||
|
||||
install_languages() {
|
||||
@@ -56,25 +71,24 @@ install_languages() {
|
||||
return
|
||||
fi
|
||||
|
||||
# Update apt-lists
|
||||
apt-get update
|
||||
|
||||
# Loop over languages to be installed
|
||||
for lang in "${langs[@]}"; do
|
||||
pkg="tesseract-ocr-$lang"
|
||||
if dpkg -s "$pkg" > /dev/null 2>&1; then
|
||||
pkg="tesseract-ocr-data-$lang"
|
||||
|
||||
# English is installed by default
|
||||
if [ "$lang" == "eng" ]; then
|
||||
continue
|
||||
fi
|
||||
|
||||
if ! apt-cache show "$pkg" > /dev/null 2>&1; then
|
||||
if apk info -e "$pkg" > /dev/null 2>&1; then
|
||||
continue
|
||||
fi
|
||||
if ! apk info "$pkg" > /dev/null 2>&1; then
|
||||
continue
|
||||
fi
|
||||
|
||||
apt-get install "$pkg"
|
||||
apk --no-cache --update add "$pkg"
|
||||
done
|
||||
|
||||
# Remove apt lists
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
}
|
||||
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ class ConsumerError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class Consumer(object):
|
||||
class Consumer:
|
||||
"""
|
||||
Loop over every file found in CONSUMPTION_DIR and:
|
||||
1. Convert it to a greyscale pnm
|
||||
@@ -117,13 +117,15 @@ class Consumer(object):
|
||||
)
|
||||
|
||||
parsed_document = parser_class(doc)
|
||||
thumbnail = parsed_document.get_thumbnail()
|
||||
|
||||
try:
|
||||
thumbnail = parsed_document.get_thumbnail()
|
||||
date = parsed_document.get_date()
|
||||
document = self._store(
|
||||
parsed_document.get_text(),
|
||||
doc,
|
||||
thumbnail
|
||||
thumbnail,
|
||||
date
|
||||
)
|
||||
except ParseError as e:
|
||||
|
||||
@@ -174,7 +176,7 @@ class Consumer(object):
|
||||
return sorted(
|
||||
options, key=lambda _: _["weight"], reverse=True)[0]["parser"]
|
||||
|
||||
def _store(self, text, doc, thumbnail):
|
||||
def _store(self, text, doc, thumbnail, date):
|
||||
|
||||
file_info = FileInfo.from_path(doc)
|
||||
|
||||
@@ -182,7 +184,7 @@ class Consumer(object):
|
||||
|
||||
self.log("debug", "Saving record to database")
|
||||
|
||||
created = file_info.created or timezone.make_aware(
|
||||
created = file_info.created or date or timezone.make_aware(
|
||||
datetime.datetime.fromtimestamp(stats.st_mtime))
|
||||
|
||||
with open(doc, "rb") as f:
|
||||
|
||||
82
src/documents/management/commands/document_correspondents.py
Normal file
82
src/documents/management/commands/document_correspondents.py
Normal file
@@ -0,0 +1,82 @@
|
||||
import sys
|
||||
|
||||
from django.core.management.base import BaseCommand
|
||||
|
||||
from documents.models import Correspondent, Document
|
||||
|
||||
from ...mixins import Renderable
|
||||
|
||||
|
||||
class Command(Renderable, BaseCommand):
|
||||
|
||||
help = """
|
||||
Using the current set of correspondent rules, apply said rules to all
|
||||
documents in the database, effectively allowing you to back-tag all
|
||||
previously indexed documents with correspondent created (or modified)
|
||||
after their initial import.
|
||||
""".replace(" ", "")
|
||||
|
||||
TOO_MANY_CONTINUE = (
|
||||
"Detected {} potential correspondents for {}, so we've opted for {}")
|
||||
TOO_MANY_SKIP = (
|
||||
"Detected {} potential correspondents for {}, so we're skipping it")
|
||||
CHANGE_MESSAGE = (
|
||||
'Document {}: "{}" was given the correspondent id {}: "{}"')
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.verbosity = 0
|
||||
BaseCommand.__init__(self, *args, **kwargs)
|
||||
|
||||
def add_arguments(self, parser):
|
||||
parser.add_argument(
|
||||
"--use-first",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="By default this command won't try to assign a correspondent "
|
||||
"if more than one matches the document. Use this flag if "
|
||||
"you'd rather it just pick the first one it finds."
|
||||
)
|
||||
|
||||
def handle(self, *args, **options):
|
||||
|
||||
self.verbosity = options["verbosity"]
|
||||
|
||||
for document in Document.objects.filter(correspondent__isnull=True):
|
||||
|
||||
potential_correspondents = list(
|
||||
Correspondent.match_all(document.content))
|
||||
|
||||
if not potential_correspondents:
|
||||
continue
|
||||
|
||||
potential_count = len(potential_correspondents)
|
||||
correspondent = potential_correspondents[0]
|
||||
|
||||
if potential_count > 1:
|
||||
if not options["use_first"]:
|
||||
print(
|
||||
self.TOO_MANY_SKIP.format(potential_count, document),
|
||||
file=sys.stderr
|
||||
)
|
||||
continue
|
||||
print(
|
||||
self.TOO_MANY_CONTINUE.format(
|
||||
potential_count,
|
||||
document,
|
||||
correspondent
|
||||
),
|
||||
file=sys.stderr
|
||||
)
|
||||
|
||||
document.correspondent = correspondent
|
||||
document.save(update_fields=("correspondent",))
|
||||
|
||||
print(
|
||||
self.CHANGE_MESSAGE.format(
|
||||
document.pk,
|
||||
document.title,
|
||||
correspondent.pk,
|
||||
correspondent.name
|
||||
),
|
||||
file=sys.stderr
|
||||
)
|
||||
@@ -3,6 +3,7 @@
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
@@ -15,6 +16,6 @@ class Migration(migrations.Migration):
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='content',
|
||||
field=models.TextField(blank=True, db_index=True, help_text='The raw, text-only data of the document. This field is primarily used for searching.'),
|
||||
field=models.TextField(blank=True, db_index=("mysql" not in settings.DATABASES["default"]["ENGINE"]), help_text='The raw, text-only data of the document. This field is primarily used for searching.'),
|
||||
),
|
||||
]
|
||||
|
||||
@@ -135,8 +135,10 @@ class MatchingModel(models.Model):
|
||||
"""
|
||||
findterms = re.compile(r'"([^"]+)"|(\S+)').findall
|
||||
normspace = re.compile(r"\s+").sub
|
||||
return [normspace(r"\s+", (t[0] or t[1]).strip())
|
||||
for t in findterms(self.match)]
|
||||
return [
|
||||
normspace(" ", (t[0] or t[1]).strip()).replace(" ", r"\s+")
|
||||
for t in findterms(self.match)
|
||||
]
|
||||
|
||||
def save(self, *args, **kwargs):
|
||||
|
||||
|
||||
@@ -9,7 +9,7 @@ class ParseError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class DocumentParser(object):
|
||||
class DocumentParser:
|
||||
"""
|
||||
Subclass this to make your own parser. Have a look at
|
||||
`paperless_tesseract.parsers` for inspiration.
|
||||
@@ -19,7 +19,7 @@ class DocumentParser(object):
|
||||
|
||||
def __init__(self, path):
|
||||
self.document_path = path
|
||||
self.tempdir = tempfile.mkdtemp(prefix="paperless", dir=self.SCRATCH)
|
||||
self.tempdir = tempfile.mkdtemp(prefix="paperless-", dir=self.SCRATCH)
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.logging_group = None
|
||||
|
||||
@@ -35,6 +35,12 @@ class DocumentParser(object):
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def get_date(self):
|
||||
"""
|
||||
Returns the date of the document.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def log(self, level, message):
|
||||
getattr(self.logger, level)(message, extra={
|
||||
"group": self.logging_group
|
||||
|
||||
@@ -30,15 +30,8 @@ from .serialisers import (
|
||||
|
||||
|
||||
class IndexView(TemplateView):
|
||||
|
||||
template_name = "documents/index.html"
|
||||
|
||||
def get_context_data(self, **kwargs):
|
||||
print(kwargs)
|
||||
print(self.request.GET)
|
||||
print(self.request.POST)
|
||||
return TemplateView.get_context_data(self, **kwargs)
|
||||
|
||||
|
||||
class FetchView(SessionOrBasicAuthMixin, DetailView):
|
||||
|
||||
|
||||
14
src/paperless/middleware.py
Normal file
14
src/paperless/middleware.py
Normal file
@@ -0,0 +1,14 @@
|
||||
from django.utils.deprecation import MiddlewareMixin
|
||||
from .models import User
|
||||
|
||||
|
||||
class Middleware (MiddlewareMixin):
|
||||
"""
|
||||
This is a dummy authentication middleware class that creates what
|
||||
is roughly an Anonymous authenticated user so we can disable login
|
||||
and not interfere with existing user ID's. It's only used if
|
||||
login is disabled in paperless.conf (default is to require login)
|
||||
"""
|
||||
|
||||
def process_request(self, request):
|
||||
request.user = User()
|
||||
26
src/paperless/models.py
Normal file
26
src/paperless/models.py
Normal file
@@ -0,0 +1,26 @@
|
||||
class User:
|
||||
"""
|
||||
This is a dummy django User used with our middleware to disable
|
||||
login authentication if that is configured in paperless.conf
|
||||
"""
|
||||
is_superuser = True
|
||||
is_active = True
|
||||
is_staff = True
|
||||
is_authenticated = True
|
||||
|
||||
# Must be -1 to avoid colliding with real user ID's (which start at 1)
|
||||
id = -1
|
||||
|
||||
@property
|
||||
def pk(self):
|
||||
return self.id
|
||||
|
||||
|
||||
"""
|
||||
NOTE: These are here as a hack instead of being in the User definition
|
||||
above due to the way pycodestyle handles lamdbdas.
|
||||
See https://github.com/PyCQA/pycodestyle/issues/379 for more.
|
||||
"""
|
||||
|
||||
User.has_module_perms = lambda *_: True
|
||||
User.has_perm = lambda *_: True
|
||||
@@ -77,6 +77,8 @@ INSTALLED_APPS = [
|
||||
if os.getenv("PAPERLESS_INSTALLED_APPS"):
|
||||
INSTALLED_APPS += os.getenv("PAPERLESS_INSTALLED_APPS").split(",")
|
||||
|
||||
|
||||
|
||||
MIDDLEWARE_CLASSES = [
|
||||
'django.middleware.security.SecurityMiddleware',
|
||||
'django.contrib.sessions.middleware.SessionMiddleware',
|
||||
@@ -88,6 +90,12 @@ MIDDLEWARE_CLASSES = [
|
||||
'django.middleware.clickjacking.XFrameOptionsMiddleware',
|
||||
]
|
||||
|
||||
#If AUTH is disabled, we just use our "bypass" authentication middleware
|
||||
if bool(os.getenv("PAPERLESS_DISABLE_LOGIN", "false").lower() in ("yes", "y", "1", "t", "true")):
|
||||
_index = MIDDLEWARE_CLASSES.index('django.contrib.auth.middleware.AuthenticationMiddleware')
|
||||
MIDDLEWARE_CLASSES[_index] = 'paperless.middleware.Middleware'
|
||||
MIDDLEWARE_CLASSES.remove('django.contrib.auth.middleware.SessionAuthenticationMiddleware')
|
||||
|
||||
ROOT_URLCONF = 'paperless.urls'
|
||||
|
||||
TEMPLATES = [
|
||||
@@ -210,6 +218,9 @@ OCR_LANGUAGE = os.getenv("PAPERLESS_OCR_LANGUAGE", "eng")
|
||||
# The amount of threads to use for OCR
|
||||
OCR_THREADS = os.getenv("PAPERLESS_OCR_THREADS")
|
||||
|
||||
# OCR all documents?
|
||||
OCR_ALWAYS = bool(os.getenv("PAPERLESS_OCR_ALWAYS", "NO").lower() in ("yes", "y", "1", "t", "true"))
|
||||
|
||||
# If this is true, any failed attempts to OCR a PDF will result in the PDF
|
||||
# being indexed anyway, with whatever we could get. If it's False, the file
|
||||
# will simply be left in the CONSUMPTION_DIR.
|
||||
@@ -258,3 +269,6 @@ PAPERLESS_LIST_PER_PAGE = int(os.getenv("PAPERLESS_LIST_PER_PAGE", 100))
|
||||
|
||||
FY_START = os.getenv("PAPERLESS_FINANCIAL_YEAR_START")
|
||||
FY_END = os.getenv("PAPERLESS_FINANCIAL_YEAR_END")
|
||||
|
||||
# Specify the default date order (for autodetected dates)
|
||||
DATE_ORDER = os.getenv("PAPERLESS_DATE_ORDER", "DMY")
|
||||
|
||||
@@ -1 +1 @@
|
||||
__version__ = (1, 1, 0)
|
||||
__version__ = (1, 3, 0)
|
||||
|
||||
@@ -4,15 +4,18 @@ import re
|
||||
import subprocess
|
||||
from multiprocessing.pool import Pool
|
||||
|
||||
import dateparser
|
||||
import langdetect
|
||||
import pyocr
|
||||
from django.conf import settings
|
||||
from documents.parsers import DocumentParser, ParseError
|
||||
from PIL import Image
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
from pyocr.tesseract import TesseractError
|
||||
|
||||
import pdftotext
|
||||
from documents.parsers import DocumentParser, ParseError
|
||||
|
||||
from .languages import ISO639
|
||||
|
||||
|
||||
@@ -30,7 +33,13 @@ class RasterisedDocumentParser(DocumentParser):
|
||||
DENSITY = settings.CONVERT_DENSITY if settings.CONVERT_DENSITY else 300
|
||||
THREADS = int(settings.OCR_THREADS) if settings.OCR_THREADS else None
|
||||
UNPAPER = settings.UNPAPER_BINARY
|
||||
DATE_ORDER = settings.DATE_ORDER
|
||||
DEFAULT_OCR_LANGUAGE = settings.OCR_LANGUAGE
|
||||
OCR_ALWAYS = settings.OCR_ALWAYS
|
||||
|
||||
def __init__(self, path):
|
||||
super().__init__(path)
|
||||
self._text = None
|
||||
|
||||
def get_thumbnail(self):
|
||||
"""
|
||||
@@ -46,13 +55,30 @@ class RasterisedDocumentParser(DocumentParser):
|
||||
|
||||
return os.path.join(self.tempdir, "convert-0000.png")
|
||||
|
||||
def _is_ocred(self):
|
||||
|
||||
# Extract text from PDF using pdftotext
|
||||
text = get_text_from_pdf(self.document_path)
|
||||
|
||||
# We assume, that a PDF with at least 50 characters contains text
|
||||
# (so no OCR required)
|
||||
return len(text) > 50
|
||||
|
||||
def get_text(self):
|
||||
|
||||
if self._text is not None:
|
||||
return self._text
|
||||
|
||||
if not self.OCR_ALWAYS and self._is_ocred():
|
||||
self.log("info", "Skipping OCR, using Text from PDF")
|
||||
self._text = get_text_from_pdf(self.document_path)
|
||||
return self._text
|
||||
|
||||
images = self._get_greyscale()
|
||||
|
||||
try:
|
||||
|
||||
return self._get_ocr(images)
|
||||
self._text = self._get_ocr(images)
|
||||
return self._text
|
||||
except OCRError as e:
|
||||
raise ParseError(e)
|
||||
|
||||
@@ -175,6 +201,54 @@ class RasterisedDocumentParser(DocumentParser):
|
||||
text += self._ocr(imgs[middle + 1:], self.DEFAULT_OCR_LANGUAGE)
|
||||
return text
|
||||
|
||||
def get_date(self):
|
||||
date = None
|
||||
datestring = None
|
||||
|
||||
try:
|
||||
text = self.get_text()
|
||||
except ParseError as e:
|
||||
return None
|
||||
|
||||
# This regular expression will try to find dates in the document at
|
||||
# hand and will match the following formats:
|
||||
# - XX.YY.ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX/YY/ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX-YY-ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX. MONTH ZZZZ with XX being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - MONTH ZZZZ, with ZZZZ being 4 digits
|
||||
# - MONTH XX, ZZZZ with XX being 1 or 2 and ZZZZ being 4 digits
|
||||
pattern = re.compile(
|
||||
r'\b([0-9]{1,2})[\.\/-]([0-9]{1,2})[\.\/-]([0-9]{4}|[0-9]{2})\b|' +
|
||||
r'\b([0-9]{1,2}[\. ]+[^ ]{3,9} ([0-9]{4}|[0-9]{2}))\b|' +
|
||||
r'\b([^\W\d_]{3,9} [0-9]{1,2}, ([0-9]{4}))\b|' +
|
||||
r'\b([^\W\d_]{3,9} [0-9]{4})\b')
|
||||
|
||||
# Iterate through all regex matches and try to parse the date
|
||||
for m in re.finditer(pattern, text):
|
||||
datestring = m.group(0)
|
||||
|
||||
try:
|
||||
date = dateparser.parse(
|
||||
datestring,
|
||||
settings={'DATE_ORDER': self.DATE_ORDER,
|
||||
'PREFER_DAY_OF_MONTH': 'first',
|
||||
'RETURN_AS_TIMEZONE_AWARE': True})
|
||||
except TypeError:
|
||||
# Skip all matches that do not parse to a proper date
|
||||
continue
|
||||
|
||||
if date is not None:
|
||||
break
|
||||
|
||||
if date is not None:
|
||||
self.log("info", "Detected document date " + date.strftime("%x") +
|
||||
" based on string " + datestring)
|
||||
else:
|
||||
self.log("info", "Unable to detect date for document")
|
||||
|
||||
return date
|
||||
|
||||
|
||||
def run_convert(*args):
|
||||
|
||||
@@ -184,13 +258,15 @@ def run_convert(*args):
|
||||
if settings.CONVERT_TMPDIR:
|
||||
environment["MAGICK_TMPDIR"] = settings.CONVERT_TMPDIR
|
||||
|
||||
subprocess.Popen(args, env=environment).wait()
|
||||
if not subprocess.Popen(args, env=environment).wait() == 0:
|
||||
raise ParseError("Convert failed at {}".format(args))
|
||||
|
||||
|
||||
def run_unpaper(args):
|
||||
unpaper, pnm = args
|
||||
subprocess.Popen(
|
||||
(unpaper, pnm, pnm.replace(".pnm", ".unpaper.pnm"))).wait()
|
||||
command_args = unpaper, pnm, pnm.replace(".pnm", ".unpaper.pnm")
|
||||
if not subprocess.Popen(command_args).wait() == 0:
|
||||
raise ParseError("Unpaper failed at {}".format(command_args))
|
||||
|
||||
|
||||
def strip_excess_whitespace(text):
|
||||
@@ -212,3 +288,14 @@ def image_to_string(args):
|
||||
except (TesseractError, OtherTesseractError):
|
||||
pass
|
||||
return ocr.image_to_string(f, lang=lang)
|
||||
|
||||
|
||||
def get_text_from_pdf(pdf_file):
|
||||
|
||||
with open(pdf_file, "rb") as f:
|
||||
try:
|
||||
pdf = pdftotext.PDF(f)
|
||||
except pdftotext.Error:
|
||||
return ""
|
||||
|
||||
return "\n".join(pdf)
|
||||
|
||||
@@ -3,7 +3,7 @@ import re
|
||||
from .parsers import RasterisedDocumentParser
|
||||
|
||||
|
||||
class ConsumerDeclaration(object):
|
||||
class ConsumerDeclaration:
|
||||
|
||||
MATCHING_FILES = re.compile("^.*\.(pdf|jpe?g|gif|png|tiff?|pnm|bmp)$")
|
||||
|
||||
|
||||
BIN
src/paperless_tesseract/tests/samples/tests_date_1.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_1.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_1.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_1.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_2.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_2.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_2.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_2.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 135 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_3.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_3.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_3.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_3.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 138 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_4.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_4.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_4.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_4.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 138 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_5.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_5.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_5.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_5.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_6.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_6.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_6.png
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_6.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
BIN
src/paperless_tesseract/tests/samples/tests_date_7.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_7.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_8.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_8.pdf
Normal file
Binary file not shown.
BIN
src/paperless_tesseract/tests/samples/tests_date_9.pdf
Normal file
BIN
src/paperless_tesseract/tests/samples/tests_date_9.pdf
Normal file
Binary file not shown.
386
src/paperless_tesseract/tests/test_date.py
Normal file
386
src/paperless_tesseract/tests/test_date.py
Normal file
@@ -0,0 +1,386 @@
|
||||
import datetime
|
||||
import os
|
||||
import shutil
|
||||
from unittest import mock
|
||||
from uuid import uuid4
|
||||
|
||||
from dateutil import tz
|
||||
from django.test import TestCase
|
||||
|
||||
from ..parsers import RasterisedDocumentParser
|
||||
|
||||
|
||||
class TestDate(TestCase):
|
||||
|
||||
SAMPLE_FILES = os.path.join(os.path.dirname(__file__), "samples")
|
||||
SCRATCH = "/tmp/paperless-tests-{}".format(str(uuid4())[:8])
|
||||
|
||||
def setUp(self):
|
||||
os.makedirs(self.SCRATCH, exist_ok=True)
|
||||
|
||||
def tearDown(self):
|
||||
shutil.rmtree(self.SCRATCH)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_date_format_1(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = "lorem ipsum 130218 lorem ipsum"
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_2(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = "lorem ipsum 2018 lorem ipsum"
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_3(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = "lorem ipsum 20180213 lorem ipsum"
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_4(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = "lorem ipsum 13.02.2018 lorem ipsum"
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 2, 13, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_5(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = (
|
||||
"lorem ipsum 130218, 2018, 20180213 and 13.02.2018 lorem ipsum")
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 2, 13, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_6(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = (
|
||||
"lorem ipsum\n"
|
||||
"Wohnort\n"
|
||||
"3100\n"
|
||||
"IBAN\n"
|
||||
"AT87 4534\n"
|
||||
"1234\n"
|
||||
"1234 5678\n"
|
||||
"BIC\n"
|
||||
"lorem ipsum"
|
||||
)
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_7(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = (
|
||||
"lorem ipsum\n"
|
||||
"März 2019\n"
|
||||
"lorem ipsum"
|
||||
)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2019, 3, 1, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_8(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = ("lorem ipsum\n"
|
||||
"Wohnort\n"
|
||||
"3100\n"
|
||||
"IBAN\n"
|
||||
"AT87 4534\n"
|
||||
"1234\n"
|
||||
"1234 5678\n"
|
||||
"BIC\n"
|
||||
"lorem ipsum\n"
|
||||
"März 2020")
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2020, 3, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_date_format_9(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document._text = ("lorem ipsum\n"
|
||||
"27. Nullmonth 2020\n"
|
||||
"März 2020\n"
|
||||
"lorem ipsum")
|
||||
self.assertEqual(document.get_date(),
|
||||
datetime.datetime(2020, 3, 1, 0, 0,
|
||||
tzinfo=tz.tzutc()))
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_get_text_1_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_1.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 4, 1, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_1_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_1.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 4, 1, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_2_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_2.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2013, 2, 1, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_2_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_2.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2013, 2, 1, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_3_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_3.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_3_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_3.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_4_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_4.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_4_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_4.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 10, 5, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_5_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_5.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_5_png(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_5.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_pdf_us(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
document.DATE_ORDER = "MDY"
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_png_us(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
document.DATE_ORDER = "MDY"
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 12, 17, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_pdf_eu(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_6_png_eu(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_6.png")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), False)
|
||||
self.assertEqual(document.get_date(), None)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SCRATCH
|
||||
)
|
||||
def test_get_text_7_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_7.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2018, 4, 1, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_get_text_8_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_8.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2017, 12, 31, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
|
||||
@mock.patch(
|
||||
"paperless_tesseract.parsers.RasterisedDocumentParser.SCRATCH",
|
||||
SAMPLE_FILES
|
||||
)
|
||||
def test_get_text_9_pdf(self):
|
||||
input_file = os.path.join(self.SAMPLE_FILES, "tests_date_9.pdf")
|
||||
document = RasterisedDocumentParser(input_file)
|
||||
document.get_text()
|
||||
self.assertEqual(document._is_ocred(), True)
|
||||
self.assertEqual(
|
||||
document.get_date(),
|
||||
datetime.datetime(2017, 12, 31, 0, 0, tzinfo=tz.tzutc())
|
||||
)
|
||||
Reference in New Issue
Block a user