mirror of
https://github.com/paperless-ngx/paperless-ngx.git
synced 2025-07-30 18:27:45 -05:00
Compare commits
532 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2ef2bf873e | ||
|
|
0bb7d27269 | ||
|
|
ce5e8b2658 | ||
|
|
3f572afb8b | ||
|
|
5c3cb1e4ab | ||
|
|
c7f4bfe4f3 | ||
|
|
65d6599964 | ||
|
|
5d32e89c44 | ||
|
|
750ab5bf85 | ||
|
|
2a3f766b93 | ||
|
|
14bb52b6a4 | ||
|
|
b5176d207e | ||
|
|
e4044d0df9 | ||
|
|
bacdd51fd7 | ||
|
|
8010d72f18 | ||
|
|
9dd76f1b87 | ||
|
|
a511d34d69 | ||
|
|
35c5b8e263 | ||
|
|
8726b0316c | ||
|
|
acf6caca2f | ||
|
|
b20d7eca03 | ||
|
|
d17497fd5b | ||
|
|
090565d84c | ||
|
|
79e1e60238 | ||
|
|
ff111f1bde | ||
|
|
6db788a550 | ||
|
|
f4a09013d7 | ||
|
|
4130dd3465 | ||
|
|
117d7dad04 | ||
|
|
b420281be0 | ||
|
|
17f8953a49 | ||
|
|
9682a6f6fc | ||
|
|
425bbe34ef | ||
|
|
60ee08adec | ||
|
|
b4b4d8f25e | ||
|
|
cce6b43062 | ||
|
|
fb6f2e07c9 | ||
|
|
2edf65dd1e | ||
|
|
9a739bdbab | ||
|
|
66db06590d | ||
|
|
7cef108785 | ||
|
|
a86a20ef0f | ||
|
|
f94347abc0 | ||
|
|
46cbd10ba0 | ||
|
|
2a96c648e8 | ||
|
|
75648cc74b | ||
|
|
0472fe4e9e | ||
|
|
c99f5923d5 | ||
|
|
ef302abed7 | ||
|
|
2dc35cc856 | ||
|
|
f4c399f0dd | ||
|
|
5342db6ada | ||
|
|
5c39fff51b | ||
|
|
ed0e40d3e6 | ||
|
|
652ead2f5c | ||
|
|
be9757894a | ||
|
|
22378789e2 | ||
|
|
72c828170e | ||
|
|
cac63494f0 | ||
|
|
939a67bd4b | ||
|
|
fbc6a58f5a | ||
|
|
01a358d2b0 | ||
|
|
6b447628ed | ||
|
|
2308d5a613 | ||
|
|
23bf79274c | ||
|
|
4849249d86 | ||
|
|
ee20af71e8 | ||
|
|
3c8aa3ba42 | ||
|
|
778ffa488d | ||
|
|
0868390d63 | ||
|
|
d5180fe5e1 | ||
|
|
08174a6b52 | ||
|
|
f5e725c691 | ||
|
|
2400245b96 | ||
|
|
729f005600 | ||
|
|
39afe41f08 | ||
|
|
2d4008371b | ||
|
|
218809ce15 | ||
|
|
7db4410c1b | ||
|
|
f1e1bb4deb | ||
|
|
cccc9e1a24 | ||
|
|
39ef81d398 | ||
|
|
d6fedbec52 | ||
|
|
ec862ed526 | ||
|
|
efb0157337 | ||
|
|
efc57852d1 | ||
|
|
0b9c4f9963 | ||
|
|
633d2b376f | ||
|
|
91cecd47af | ||
|
|
b05fd4870e | ||
|
|
40e79a731f | ||
|
|
6cd06f6c8a | ||
|
|
b6a870c0e5 | ||
|
|
160c256327 | ||
|
|
fcd36c8415 | ||
|
|
70608f7e31 | ||
|
|
4e5ee24618 | ||
|
|
1bb80548d2 | ||
|
|
96268655d2 | ||
|
|
be2cbebaf7 | ||
|
|
c79583dedb | ||
|
|
24d3e7f9d3 | ||
|
|
088a631f6a | ||
|
|
a9bb78c4ae | ||
|
|
3f4ac1f2f1 | ||
|
|
6c3afd21b9 | ||
|
|
e7daf7dae4 | ||
|
|
ba1f437e0b | ||
|
|
826db170d3 | ||
|
|
04816f556f | ||
|
|
f99db14a21 | ||
|
|
c75a1e9eca | ||
|
|
2894d105cb | ||
|
|
f31d535da8 | ||
|
|
619878b2f6 | ||
|
|
5db49a3710 | ||
|
|
f3654310bd | ||
|
|
10054f978a | ||
|
|
5308f2166d | ||
|
|
03ec9f5a06 | ||
|
|
454bf7595e | ||
|
|
b916fe13e1 | ||
|
|
484cbc1bf2 | ||
|
|
1d61c9cd79 | ||
|
|
3b72d38440 | ||
|
|
631d316985 | ||
|
|
742b01d1f5 | ||
|
|
d37aabfb06 | ||
|
|
b3624f6375 | ||
|
|
d6d8537b69 | ||
|
|
90cd9f3eb7 | ||
|
|
a0240cace3 | ||
|
|
988adf963a | ||
|
|
3d188ec623 | ||
|
|
c9f35a7da2 | ||
|
|
d5876cc97d | ||
|
|
6235edf845 | ||
|
|
9b00a98de3 | ||
|
|
07e18e773a | ||
|
|
fc560b8c04 | ||
|
|
c94f4dcc75 | ||
|
|
9173bca3c7 | ||
|
|
f2cf3a6a0f | ||
|
|
d6346706db | ||
|
|
48738dab9f | ||
|
|
11db87fa11 | ||
|
|
1f7990d742 | ||
|
|
52b32fddc9 | ||
|
|
81a8cb45d7 | ||
|
|
9c583fe9f3 | ||
|
|
a1cb67c4ce | ||
|
|
c37f642cff | ||
|
|
9df06fbb12 | ||
|
|
0abf637c67 | ||
|
|
27a936f9bf | ||
|
|
6e1f2b3f03 | ||
|
|
5643d89270 | ||
|
|
52b0249d71 | ||
|
|
2ab2c37f5a | ||
|
|
f72fa43e86 | ||
|
|
c0ad6cd58a | ||
|
|
b79caa64d0 | ||
|
|
e5b7e93eff | ||
|
|
d8740ee5ca | ||
|
|
cdc07cf153 | ||
|
|
da6dc2ad5b | ||
|
|
885dbf67d5 | ||
|
|
02b40a54e0 | ||
|
|
3b6a3219f5 | ||
|
|
8783c2af88 | ||
|
|
6cedbb3307 | ||
|
|
4585308e7f | ||
|
|
4386b09eb1 | ||
|
|
f96e7f7895 | ||
|
|
8218b1aa51 | ||
|
|
0559204be4 | ||
|
|
bccac5017c | ||
|
|
3e8038577d | ||
|
|
05b7bcd199 | ||
|
|
3a2a180607 | ||
|
|
9690a00761 | ||
|
|
3532745579 | ||
|
|
24bdc07e14 | ||
|
|
528b572855 | ||
|
|
91ddfaa065 | ||
|
|
ac0cda861e | ||
|
|
a752a4a91a | ||
|
|
7e1d59377a | ||
|
|
7357471b9e | ||
|
|
bd75a65866 | ||
|
|
e65e27d11f | ||
|
|
12488c9634 | ||
|
|
61cd050e24 | ||
|
|
f018e8e54f | ||
|
|
a56a3eb86d | ||
|
|
2fe7df8ca0 | ||
|
|
873c98dddb | ||
|
|
ea287e0db2 | ||
|
|
4babfa1a5b | ||
|
|
aa2fc84d7f | ||
|
|
8d5ae64aff | ||
|
|
82f9dde055 | ||
|
|
c983e73d0f | ||
|
|
6fd9995aa1 | ||
|
|
20a4a66a57 | ||
|
|
4ed1fff518 | ||
|
|
7223ea3c3f | ||
|
|
676c8f9fa7 | ||
|
|
00fd2268c5 | ||
|
|
3aafabba26 | ||
|
|
b733b32c1d | ||
|
|
4ba9514007 | ||
|
|
4505711e4f | ||
|
|
63c394fa31 | ||
|
|
27c72a7bc6 | ||
|
|
72af13e4e4 | ||
|
|
6c8ef8f044 | ||
|
|
9d4bebd569 | ||
|
|
101b7bb9bf | ||
|
|
52d6cf085d | ||
|
|
39ead59e45 | ||
|
|
015c49030b | ||
|
|
985b9428fe | ||
|
|
ea90bd3f84 | ||
|
|
fccc95254b | ||
|
|
e266e114a9 | ||
|
|
19faed3634 | ||
|
|
fcdcf62c2c | ||
|
|
68251b8be6 | ||
|
|
8e63388833 | ||
|
|
1f2079f65a | ||
|
|
f61fa06993 | ||
|
|
da1d3820ec | ||
|
|
f778d3a6e3 | ||
|
|
96a94c4ee9 | ||
|
|
b126c6b0ff | ||
|
|
1d162dc769 | ||
|
|
a1f257369d | ||
|
|
45e18d7094 | ||
|
|
d6fe17f4c6 | ||
|
|
93bed91937 | ||
|
|
10d22abd8f | ||
|
|
fdb50d0446 | ||
|
|
79bdd829ea | ||
|
|
1c4226d27c | ||
|
|
b437803321 | ||
|
|
b6a266a4f7 | ||
|
|
b7f1561217 | ||
|
|
abbd4d772c | ||
|
|
75ac8d2796 | ||
|
|
41f816a29b | ||
|
|
4a25e9655c | ||
|
|
d0252e8e44 | ||
|
|
73e62600c2 | ||
|
|
5c43041610 | ||
|
|
f56dafe7d9 | ||
|
|
7a1754fffd | ||
|
|
f8c6c07bb7 | ||
|
|
8fefafb844 | ||
|
|
d1a57b5d68 | ||
|
|
3adccc0bdb | ||
|
|
6058630360 | ||
|
|
81d92fb4ad | ||
|
|
40cb0190fc | ||
|
|
e5ebd84eca | ||
|
|
673b4cf911 | ||
|
|
ea1260c2ce | ||
|
|
7040d13f76 | ||
|
|
ed36070e92 | ||
|
|
c88a7646e5 | ||
|
|
d174390624 | ||
|
|
5bb90cb63d | ||
|
|
c4bbb71a3b | ||
|
|
7d6cae96f3 | ||
|
|
b1e616055e | ||
|
|
eec8f09d6f | ||
|
|
c68a6d78eb | ||
|
|
acd3cc5062 | ||
|
|
a55a915439 | ||
|
|
1f68223752 | ||
|
|
d6b626ec50 | ||
|
|
926016f1d8 | ||
|
|
8ea1cc24a7 | ||
|
|
08adb2f540 | ||
|
|
4333ee01bc | ||
|
|
46db0edd5d | ||
|
|
10d017ebe4 | ||
|
|
76a13dadb8 | ||
|
|
72750b9243 | ||
|
|
fba58f3bdd | ||
|
|
6662ca3467 | ||
|
|
6f1ed89e26 | ||
|
|
7e99e42924 | ||
|
|
5d01410dc0 | ||
|
|
9a47dba494 | ||
|
|
6edee78145 | ||
|
|
30eac99a61 | ||
|
|
ea6d040809 | ||
|
|
8e9d5caa37 | ||
|
|
122aa2b9f1 | ||
|
|
fb1da4834c | ||
|
|
96c7222269 | ||
|
|
1737e27b34 | ||
|
|
39f198138a | ||
|
|
c74bb84c83 | ||
|
|
07d06d9aee | ||
|
|
9cef689106 | ||
|
|
11a9c756b3 | ||
|
|
11accaff7f | ||
|
|
77aee832e4 | ||
|
|
4bde14368c | ||
|
|
151d85f2be | ||
|
|
e7c23cfb92 | ||
|
|
3f9ea7b971 | ||
|
|
998c3ef51b | ||
|
|
c85b6b425d | ||
|
|
273916973c | ||
|
|
5009bd022f | ||
|
|
73163d893f | ||
|
|
506af7c9c2 | ||
|
|
c90ed2da1d | ||
|
|
cebb8b9fa2 | ||
|
|
46aca10a72 | ||
|
|
6384c698ad | ||
|
|
abf01be889 | ||
|
|
1e4928d2a0 | ||
|
|
503be90932 | ||
|
|
b5d6a82cc3 | ||
|
|
c073ba5272 | ||
|
|
d1e317ce21 | ||
|
|
d4abeafb34 | ||
|
|
4d96551619 | ||
|
|
178361b247 | ||
|
|
40f8ba23a4 | ||
|
|
bef2d94374 | ||
|
|
f39c7654a0 | ||
|
|
e9fff764cb | ||
|
|
87e466c47c | ||
|
|
bd0b593c4a | ||
|
|
7a8142df2b | ||
|
|
bbe3084eda | ||
|
|
89d42bd078 | ||
|
|
93efaf7a38 | ||
|
|
398575c70c | ||
|
|
4e21fa4830 | ||
|
|
d2d2d9edaf | ||
|
|
771c8bbbe4 | ||
|
|
20eeda19b8 | ||
|
|
96c517d65c | ||
|
|
e70ad3d493 | ||
|
|
516bc48a33 | ||
|
|
7f97716ae9 | ||
|
|
5e40227bc3 | ||
|
|
5479942fc0 | ||
|
|
ce98019b49 | ||
|
|
9470154df2 | ||
|
|
5c59120c57 | ||
|
|
88736ff867 | ||
|
|
fd5b831979 | ||
|
|
3fcd1e2d7e | ||
|
|
2c81648d59 | ||
|
|
cd92c005e3 | ||
|
|
31c8cf020e | ||
|
|
e900a38983 | ||
|
|
7343a07ddd | ||
|
|
e20b4fb905 | ||
|
|
cbbc4d37d0 | ||
|
|
b140935843 | ||
|
|
9faf0a102e | ||
|
|
b747dd58c3 | ||
|
|
09e1b505e1 | ||
|
|
a6babffed8 | ||
|
|
0256e2dfbb | ||
|
|
7afa90b769 | ||
|
|
5796956235 | ||
|
|
3ca215e4dc | ||
|
|
16c4183333 | ||
|
|
6fe37678f2 | ||
|
|
b58188f805 | ||
|
|
f2a42ab6fe | ||
|
|
e236b7bf7b | ||
|
|
35004f434b | ||
|
|
75251ad694 | ||
|
|
870357968a | ||
|
|
a593798b4b | ||
|
|
4f070ba162 | ||
|
|
9517d27f40 | ||
|
|
35bb3dbcc2 | ||
|
|
06117929bb | ||
|
|
d1c8241947 | ||
|
|
4c38b28469 | ||
|
|
ad0f0a0b5d | ||
|
|
83746a9aeb | ||
|
|
6a36a4ec97 | ||
|
|
7e49d047b0 | ||
|
|
68cdeb7b3d | ||
|
|
76293084a4 | ||
|
|
e1cf2117f5 | ||
|
|
7d81de4edf | ||
|
|
37af5992c7 | ||
|
|
af4623e605 | ||
|
|
db8e116681 | ||
|
|
a8616ebfe2 | ||
|
|
a38d3bf7f8 | ||
|
|
1cb5bbd07d | ||
|
|
6edb5b912f | ||
|
|
ec20c7577e | ||
|
|
d6df9b3656 | ||
|
|
80a849fef7 | ||
|
|
bd67b53d50 | ||
|
|
e32ed09da3 | ||
|
|
c5632e5c04 | ||
|
|
4d2b71454d | ||
|
|
5cbb33b02b | ||
|
|
2c55aad6c0 | ||
|
|
1e039dcb32 | ||
|
|
6ca8da4858 | ||
|
|
67b492bcb7 | ||
|
|
360d1e2802 | ||
|
|
1cd76634a3 | ||
|
|
c65c5009e4 | ||
|
|
24fb6cefb9 | ||
|
|
d80e272b75 | ||
|
|
82f05e27c3 | ||
|
|
7a627e4ad8 | ||
|
|
73af9552ec | ||
|
|
e4854f2144 | ||
|
|
6f5c1ac4e1 | ||
|
|
22acc51284 | ||
|
|
a05644fc31 | ||
|
|
d1aa54caa9 | ||
|
|
e293f70a91 | ||
|
|
347986a2b3 | ||
|
|
ede274386b | ||
|
|
3e083354cc | ||
|
|
b2b4f6516a | ||
|
|
2ae702c7bb | ||
|
|
b748420a94 | ||
|
|
8a4546ce0d | ||
|
|
167412a003 | ||
|
|
e8d90b42a1 | ||
|
|
d8c7e9de5f | ||
|
|
2ac1b78a2c | ||
|
|
e8e38befb7 | ||
|
|
b30629dd60 | ||
|
|
f66d7e1c2d | ||
|
|
8417ac7eeb | ||
|
|
6342225b22 | ||
|
|
4460fb7004 | ||
|
|
6f635c74fc | ||
|
|
c82d45689c | ||
|
|
02e0543a02 | ||
|
|
fde0276d65 | ||
|
|
3d6289e4e1 | ||
|
|
5e55b971a8 | ||
|
|
0a43b84a96 | ||
|
|
dc74cc2db5 | ||
|
|
fc00a09318 | ||
|
|
19cf9d0b9a | ||
|
|
f81780cf88 | ||
|
|
c3a55c91dc | ||
|
|
482f02fbaa | ||
|
|
6bf7429ef6 | ||
|
|
4198de604f | ||
|
|
8c06dc2dd1 | ||
|
|
13b4610c1d | ||
|
|
0090128249 | ||
|
|
3153bbd6a8 | ||
|
|
7b1812a9be | ||
|
|
c647daace2 | ||
|
|
70dceb3b37 | ||
|
|
72b1ce5fe6 | ||
|
|
731942d855 | ||
|
|
058dad7ba7 | ||
|
|
fe43e5a717 | ||
|
|
34bab04310 | ||
|
|
18f7c4f31f | ||
|
|
3477b96d87 | ||
|
|
ac850b64aa | ||
|
|
279e421ad5 | ||
|
|
22c8049bed | ||
|
|
3f1392769d | ||
|
|
da71eab0ae | ||
|
|
2e0e6bb8d2 | ||
|
|
1f145c6cba | ||
|
|
c4d48181ee | ||
|
|
0c4ecad4a7 | ||
|
|
d25de5592a | ||
|
|
88fc35d8ea | ||
|
|
02730be871 | ||
|
|
c7876dbbe8 | ||
|
|
85fcb5fedf | ||
|
|
58cbfeb72a | ||
|
|
b2b6cbe9c8 | ||
|
|
4c05a511c2 | ||
|
|
b5bef13b46 | ||
|
|
bb47dc5e06 | ||
|
|
511f154e16 | ||
|
|
10ae2207df | ||
|
|
71df99ffb6 | ||
|
|
5eb26102d4 | ||
|
|
a7fa82a83f | ||
|
|
6ce27d225d | ||
|
|
819a0e1f57 | ||
|
|
702a60b7e7 | ||
|
|
057d5f149f | ||
|
|
d047dafd23 | ||
|
|
b449a7f6e2 | ||
|
|
f302874ae8 | ||
|
|
6af58203dd | ||
|
|
fa4924d5ba | ||
|
|
5b88ebf0e7 | ||
|
|
a0edc7d54d | ||
|
|
b876a0d0df | ||
|
|
27db4f7e51 | ||
|
|
426919fa9f | ||
|
|
e47c152b81 | ||
|
|
b7cb708053 | ||
|
|
7611c2b3d5 | ||
|
|
5f964830aa | ||
|
|
7ec4f906af | ||
|
|
b5f6c06b8b | ||
|
|
55e81ca4bb | ||
|
|
0f7bfc547a | ||
|
|
9525725c28 | ||
|
|
2a2196fa4d | ||
|
|
237efbcaa0 | ||
|
|
351cd06ef7 | ||
|
|
8b37160953 | ||
|
|
db64478d9f | ||
|
|
8bc2dfe4c6 | ||
|
|
3a427c9130 |
1
.gitattributes
vendored
Normal file
1
.gitattributes
vendored
Normal file
@@ -0,0 +1 @@
|
||||
THANKS.md merge=union
|
||||
10
.gitignore
vendored
10
.gitignore
vendored
@@ -42,6 +42,7 @@ htmlcov/
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*,cover
|
||||
.pytest_cache
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
@@ -58,8 +59,10 @@ target/
|
||||
|
||||
# Stored PDFs
|
||||
media/documents/*.gpg
|
||||
media/documents/thumbnails/*.gpg
|
||||
media/documents/originals/*.gpg
|
||||
media/documents/thumbnails/*
|
||||
media/documents/originals/*
|
||||
media/overrides.css
|
||||
media/overrides.js
|
||||
|
||||
# Sqlite database
|
||||
db.sqlite3
|
||||
@@ -68,6 +71,7 @@ db.sqlite3
|
||||
.idea
|
||||
|
||||
# Other stuff that doesn't belong
|
||||
.virtualenv
|
||||
virtualenv
|
||||
.vagrant
|
||||
docker-compose.yml
|
||||
@@ -77,3 +81,5 @@ docker-compose.env
|
||||
scripts/import-for-development
|
||||
scripts/nuke
|
||||
|
||||
# Static files collected by the collectstatic command
|
||||
static/
|
||||
|
||||
19
.travis.yml
19
.travis.yml
@@ -1,18 +1,25 @@
|
||||
language: python
|
||||
|
||||
before_install:
|
||||
- sudo apt-get update -qq
|
||||
- sudo apt-get install -qq libpoppler-cpp-dev unpaper tesseract-ocr tesseract-ocr-eng tesseract-ocr-cat
|
||||
|
||||
sudo: false
|
||||
|
||||
matrix:
|
||||
include:
|
||||
- python: 3.4
|
||||
env: TOXENV=py34
|
||||
- python: 3.5
|
||||
env: TOXENV=py35
|
||||
- python: 3.5
|
||||
env: TOXENV=pep8
|
||||
- python: 3.6
|
||||
|
||||
install:
|
||||
- pip install --requirement requirements.txt
|
||||
- pip install tox
|
||||
- pip install sphinx
|
||||
script:
|
||||
- cd src/
|
||||
- pytest --cov
|
||||
- pycodestyle
|
||||
- sphinx-build -b html ../docs ../docs/_build -W
|
||||
|
||||
script: tox -c src/tox.ini
|
||||
after_success:
|
||||
- coveralls
|
||||
|
||||
46
CODE_OF_CONDUCT.md
Normal file
46
CODE_OF_CONDUCT.md
Normal file
@@ -0,0 +1,46 @@
|
||||
# Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, gender identity and expression, level of experience, nationality, personal appearance, race, religion, or sexual identity and orientation.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to creating a positive environment include:
|
||||
|
||||
* Using welcoming and inclusive language
|
||||
* Being respectful of differing viewpoints and experiences
|
||||
* Gracefully accepting constructive criticism
|
||||
* Focusing on what is best for the community
|
||||
* Showing empathy towards other community members
|
||||
|
||||
Examples of unacceptable behavior by participants include:
|
||||
|
||||
* Unwelcome sexual attention or advances
|
||||
* Trolling, insulting/derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or electronic address, without explicit permission
|
||||
* Other conduct which could reasonably be considered inappropriate in a professional setting
|
||||
|
||||
## Our Responsibilities
|
||||
|
||||
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
|
||||
|
||||
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at code@danielquinn.org. The project team will review and investigate all complaints, and will respond in a way that it deems appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
|
||||
|
||||
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4 to remove puritanical language. The original is available at [http://contributor-covenant.org/version/1/4][version]
|
||||
|
||||
[homepage]: http://contributor-covenant.org
|
||||
[version]: http://contributor-covenant.org/version/1/4/
|
||||
75
Dockerfile
75
Dockerfile
@@ -1,46 +1,47 @@
|
||||
FROM python:3.5
|
||||
MAINTAINER Pit Kleyersburg <pitkley@googlemail.com>
|
||||
FROM alpine:3.8
|
||||
|
||||
# Install dependencies
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
sudo \
|
||||
tesseract-ocr tesseract-ocr-eng imagemagick ghostscript unpaper \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
LABEL maintainer="The Paperless Project https://github.com/danielquinn/paperless" \
|
||||
contributors="Guy Addadi <addadi@gmail.com>, Pit Kleyersburg <pitkley@googlemail.com>, \
|
||||
Sven Fischer <git-dev@linux4tw.de>"
|
||||
|
||||
# Install python dependencies
|
||||
RUN mkdir -p /usr/src/paperless
|
||||
WORKDIR /usr/src/paperless
|
||||
# Copy requirements file and init script
|
||||
COPY requirements.txt /usr/src/paperless/
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
COPY scripts/docker-entrypoint.sh /sbin/docker-entrypoint.sh
|
||||
|
||||
# Set export and consumption directories
|
||||
ENV PAPERLESS_EXPORT_DIR=/export \
|
||||
PAPERLESS_CONSUMPTION_DIR=/consume
|
||||
|
||||
|
||||
RUN apk update --no-cache && apk add python3 gnupg libmagic bash shadow curl \
|
||||
sudo poppler tesseract-ocr imagemagick ghostscript unpaper optipng && \
|
||||
apk add --virtual .build-dependencies \
|
||||
python3-dev poppler-dev gcc g++ musl-dev zlib-dev jpeg-dev && \
|
||||
# Install python dependencies
|
||||
python3 -m ensurepip && \
|
||||
rm -r /usr/lib/python*/ensurepip && \
|
||||
cd /usr/src/paperless && \
|
||||
pip3 install --no-cache-dir -r requirements.txt && \
|
||||
# Remove build dependencies
|
||||
apk del .build-dependencies && \
|
||||
# Create the consumption directory
|
||||
mkdir -p $PAPERLESS_CONSUMPTION_DIR && \
|
||||
# Create user
|
||||
addgroup -g 1000 paperless && \
|
||||
adduser -D -u 1000 -G paperless -h /usr/src/paperless paperless && \
|
||||
chown -Rh paperless:paperless /usr/src/paperless && \
|
||||
mkdir -p $PAPERLESS_EXPORT_DIR && \
|
||||
# Setup entrypoint
|
||||
chmod 755 /sbin/docker-entrypoint.sh
|
||||
|
||||
WORKDIR /usr/src/paperless/src
|
||||
# Mount volumes and set Entrypoint
|
||||
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume", "/export"]
|
||||
ENTRYPOINT ["/sbin/docker-entrypoint.sh"]
|
||||
CMD ["--help"]
|
||||
|
||||
# Copy application
|
||||
RUN mkdir -p /usr/src/paperless/src
|
||||
RUN mkdir -p /usr/src/paperless/data
|
||||
RUN mkdir -p /usr/src/paperless/media
|
||||
COPY src/ /usr/src/paperless/src/
|
||||
COPY data/ /usr/src/paperless/data/
|
||||
COPY media/ /usr/src/paperless/media/
|
||||
|
||||
# Set consumption directory
|
||||
ENV PAPERLESS_CONSUMPTION_DIR /consume
|
||||
RUN mkdir -p $PAPERLESS_CONSUMPTION_DIR
|
||||
|
||||
# Migrate database
|
||||
WORKDIR /usr/src/paperless/src
|
||||
RUN ./manage.py migrate
|
||||
|
||||
# Create user
|
||||
RUN groupadd -g 1000 paperless \
|
||||
&& useradd -u 1000 -g 1000 -d /usr/src/paperless paperless \
|
||||
&& chown -Rh paperless:paperless /usr/src/paperless
|
||||
|
||||
# Setup entrypoint
|
||||
COPY scripts/docker-entrypoint.sh /sbin/docker-entrypoint.sh
|
||||
RUN chmod 755 /sbin/docker-entrypoint.sh
|
||||
|
||||
# Mount volumes
|
||||
VOLUME ["/usr/src/paperless/data", "/usr/src/paperless/media", "/consume"]
|
||||
|
||||
ENTRYPOINT ["/sbin/docker-entrypoint.sh"]
|
||||
CMD ["--help"]
|
||||
|
||||
40
Pipfile
Normal file
40
Pipfile
Normal file
@@ -0,0 +1,40 @@
|
||||
[[source]]
|
||||
url = "https://pypi.python.org/simple"
|
||||
verify_ssl = true
|
||||
name = "pypi"
|
||||
|
||||
[packages]
|
||||
django = "<2.1,>=2.0"
|
||||
pillow = "*"
|
||||
coveralls = "*"
|
||||
dateparser = "*"
|
||||
django-cors-headers = "*"
|
||||
django-crispy-forms = "*"
|
||||
django-extensions = "*"
|
||||
django-filter = "*"
|
||||
djangorestframework = "*"
|
||||
factory-boy = "*"
|
||||
filemagic = "*"
|
||||
fuzzywuzzy = {extras = ["speedup"], version = "==0.15.0"}
|
||||
gunicorn = "*"
|
||||
inotify-simple = "*"
|
||||
langdetect = "*"
|
||||
pdftotext = "*"
|
||||
pyocr = "*"
|
||||
python-dateutil = "*"
|
||||
python-dotenv = "*"
|
||||
python-gnupg = "*"
|
||||
pytz = "*"
|
||||
pycodestyle = "*"
|
||||
pytest = "*"
|
||||
pytest-cov = "*"
|
||||
pytest-django = "*"
|
||||
pytest-sugar = "*"
|
||||
pytest-env = "*"
|
||||
pytest-xdist = "*"
|
||||
|
||||
[dev-packages]
|
||||
ipython = "*"
|
||||
sphinx = "*"
|
||||
tox = "*"
|
||||
|
||||
731
Pipfile.lock
generated
Normal file
731
Pipfile.lock
generated
Normal file
@@ -0,0 +1,731 @@
|
||||
{
|
||||
"_meta": {
|
||||
"hash": {
|
||||
"sha256": "6d8bad24aa5d0c102b13b5ae27acba04836cd5a07a4003cb2763de1e0a3406b7"
|
||||
},
|
||||
"pipfile-spec": 6,
|
||||
"requires": {},
|
||||
"sources": [
|
||||
{
|
||||
"name": "pypi",
|
||||
"url": "https://pypi.python.org/simple",
|
||||
"verify_ssl": true
|
||||
}
|
||||
]
|
||||
},
|
||||
"default": {
|
||||
"apipkg": {
|
||||
"hashes": [
|
||||
"sha256:37228cda29411948b422fae072f57e31d3396d2ee1c9783775980ee9c9990af6",
|
||||
"sha256:58587dd4dc3daefad0487f6d9ae32b4542b185e1c36db6993290e7c41ca2b47c"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.5"
|
||||
},
|
||||
"atomicwrites": {
|
||||
"hashes": [
|
||||
"sha256:0312ad34fcad8fac3704d441f7b317e50af620823353ec657a53e981f92920c0",
|
||||
"sha256:ec9ae8adaae229e4f8446952d204a3e4b5fdd2d099f9be3aaf556120135fb3ee"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.2.1"
|
||||
},
|
||||
"attrs": {
|
||||
"hashes": [
|
||||
"sha256:10cbf6e27dbce8c30807caf056c8eb50917e0eaafe86347671b57254006c3e69",
|
||||
"sha256:ca4be454458f9dec299268d472aaa5a11f67a4ff70093396e1ceae9c76cf4bbb"
|
||||
],
|
||||
"version": "==18.2.0"
|
||||
},
|
||||
"certifi": {
|
||||
"hashes": [
|
||||
"sha256:376690d6f16d32f9d1fe8932551d80b23e9d393a8578c5633a2ed39a64861638",
|
||||
"sha256:456048c7e371c089d0a77a5212fb37a2c2dce1e24146e3b7e0261736aaeaa22a"
|
||||
],
|
||||
"version": "==2018.8.24"
|
||||
},
|
||||
"chardet": {
|
||||
"hashes": [
|
||||
"sha256:84ab92ed1c4d4f16916e05906b6b75a6c0fb5db821cc65e70cbd64a3e2a5eaae",
|
||||
"sha256:fc323ffcaeaed0e0a02bf4d117757b98aed530d9ed4531e3e15460124c106691"
|
||||
],
|
||||
"version": "==3.0.4"
|
||||
},
|
||||
"coverage": {
|
||||
"hashes": [
|
||||
"sha256:03481e81d558d30d230bc12999e3edffe392d244349a90f4ef9b88425fac74ba",
|
||||
"sha256:0b136648de27201056c1869a6c0d4e23f464750fd9a9ba9750b8336a244429ed",
|
||||
"sha256:10a46017fef60e16694a30627319f38a2b9b52e90182dddb6e37dcdab0f4bf95",
|
||||
"sha256:198626739a79b09fa0a2f06e083ffd12eb55449b5f8bfdbeed1df4910b2ca640",
|
||||
"sha256:23d341cdd4a0371820eb2b0bd6b88f5003a7438bbedb33688cd33b8eae59affd",
|
||||
"sha256:28b2191e7283f4f3568962e373b47ef7f0392993bb6660d079c62bd50fe9d162",
|
||||
"sha256:2a5b73210bad5279ddb558d9a2bfedc7f4bf6ad7f3c988641d83c40293deaec1",
|
||||
"sha256:2eb564bbf7816a9d68dd3369a510be3327f1c618d2357fa6b1216994c2e3d508",
|
||||
"sha256:337ded681dd2ef9ca04ef5d93cfc87e52e09db2594c296b4a0a3662cb1b41249",
|
||||
"sha256:3a2184c6d797a125dca8367878d3b9a178b6fdd05fdc2d35d758c3006a1cd694",
|
||||
"sha256:3c79a6f7b95751cdebcd9037e4d06f8d5a9b60e4ed0cd231342aa8ad7124882a",
|
||||
"sha256:3d72c20bd105022d29b14a7d628462ebdc61de2f303322c0212a054352f3b287",
|
||||
"sha256:3eb42bf89a6be7deb64116dd1cc4b08171734d721e7a7e57ad64cc4ef29ed2f1",
|
||||
"sha256:4635a184d0bbe537aa185a34193898eee409332a8ccb27eea36f262566585000",
|
||||
"sha256:56e448f051a201c5ebbaa86a5efd0ca90d327204d8b059ab25ad0f35fbfd79f1",
|
||||
"sha256:5a13ea7911ff5e1796b6d5e4fbbf6952381a611209b736d48e675c2756f3f74e",
|
||||
"sha256:69bf008a06b76619d3c3f3b1983f5145c75a305a0fea513aca094cae5c40a8f5",
|
||||
"sha256:6bc583dc18d5979dc0f6cec26a8603129de0304d5ae1f17e57a12834e7235062",
|
||||
"sha256:701cd6093d63e6b8ad7009d8a92425428bc4d6e7ab8d75efbb665c806c1d79ba",
|
||||
"sha256:7608a3dd5d73cb06c531b8925e0ef8d3de31fed2544a7de6c63960a1e73ea4bc",
|
||||
"sha256:76ecd006d1d8f739430ec50cc872889af1f9c1b6b8f48e29941814b09b0fd3cc",
|
||||
"sha256:7aa36d2b844a3e4a4b356708d79fd2c260281a7390d678a10b91ca595ddc9e99",
|
||||
"sha256:7d3f553904b0c5c016d1dad058a7554c7ac4c91a789fca496e7d8347ad040653",
|
||||
"sha256:7e1fe19bd6dce69d9fd159d8e4a80a8f52101380d5d3a4d374b6d3eae0e5de9c",
|
||||
"sha256:8c3cb8c35ec4d9506979b4cf90ee9918bc2e49f84189d9bf5c36c0c1119c6558",
|
||||
"sha256:9d6dd10d49e01571bf6e147d3b505141ffc093a06756c60b053a859cb2128b1f",
|
||||
"sha256:be6cfcd8053d13f5f5eeb284aa8a814220c3da1b0078fa859011c7fffd86dab9",
|
||||
"sha256:c1bb572fab8208c400adaf06a8133ac0712179a334c09224fb11393e920abcdd",
|
||||
"sha256:de4418dadaa1c01d497e539210cb6baa015965526ff5afc078c57ca69160108d",
|
||||
"sha256:e05cb4d9aad6233d67e0541caa7e511fa4047ed7750ec2510d466e806e0255d6",
|
||||
"sha256:f3f501f345f24383c0000395b26b726e46758b71393267aeae0bd36f8b3ade80"
|
||||
],
|
||||
"markers": "python_version >= '2.6' and python_version != '3.2.*' and python_version != '3.0.*' and python_version != '3.1.*' and python_version < '4'",
|
||||
"version": "==4.5.1"
|
||||
},
|
||||
"coveralls": {
|
||||
"hashes": [
|
||||
"sha256:9dee67e78ec17b36c52b778247762851c8e19a893c9a14e921a2fc37f05fac22",
|
||||
"sha256:aec5a1f5e34224b9089664a1b62217732381c7de361b6ed1b3c394d7187b352a"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.5.0"
|
||||
},
|
||||
"dateparser": {
|
||||
"hashes": [
|
||||
"sha256:940828183c937bcec530753211b70f673c0a9aab831e43273489b310538dff86",
|
||||
"sha256:b452ef8b36cd78ae86a50721794bc674aa3994e19b570f7ba92810f4e0a2ae03"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.7.0"
|
||||
},
|
||||
"django": {
|
||||
"hashes": [
|
||||
"sha256:0c5b65847d00845ee404bbc0b4a85686f15eb3001ffddda3db4e9baa265bf136",
|
||||
"sha256:68aeea369a8130259354b6ba1fa9babe0c5ee6bced505dea4afcd00f765ae38b"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.0.8"
|
||||
},
|
||||
"django-cors-headers": {
|
||||
"hashes": [
|
||||
"sha256:5545009c9b233ea7e70da7dbab7cb1c12afa01279895086f98ec243d7eab46fa",
|
||||
"sha256:c4c2ee97139d18541a1be7d96fe337d1694623816d83f53cb7c00da9b94acae1"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.4.0"
|
||||
},
|
||||
"django-crispy-forms": {
|
||||
"hashes": [
|
||||
"sha256:5952bab971110d0b86c278132dae0aa095beee8f723e625c3d3fa28888f1675f",
|
||||
"sha256:705ededc554ad8736157c666681165fe22ead2dec0d5446d65fc9dd976a5a876"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.7.2"
|
||||
},
|
||||
"django-extensions": {
|
||||
"hashes": [
|
||||
"sha256:1f626353a11479014bfe0d77e76d8f866ebca1bb5d595cb57b776230b9e0eb92",
|
||||
"sha256:f21b898598a1628cb73017fb9672e2c5e624133be9764f0eb138e0abf8a62b62"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.1.2"
|
||||
},
|
||||
"django-filter": {
|
||||
"hashes": [
|
||||
"sha256:6f4e4bc1a11151178520567b50320e5c32f8edb552139d93ea3e30613b886f56",
|
||||
"sha256:86c3925020c27d072cdae7b828aaa5d165c2032a629abbe3c3a1be1edae61c58"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.0.0"
|
||||
},
|
||||
"djangorestframework": {
|
||||
"hashes": [
|
||||
"sha256:b6714c3e4b0f8d524f193c91ecf5f5450092c2145439ac2769711f7eba89a9d9",
|
||||
"sha256:c375e4f95a3a64fccac412e36fb42ba36881e52313ec021ef410b40f67cddca4"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==3.8.2"
|
||||
},
|
||||
"docopt": {
|
||||
"hashes": [
|
||||
"sha256:49b3a825280bd66b3aa83585ef59c4a8c82f2c8a522dbe754a8bc8d08c85c491"
|
||||
],
|
||||
"version": "==0.6.2"
|
||||
},
|
||||
"execnet": {
|
||||
"hashes": [
|
||||
"sha256:a7a84d5fa07a089186a329528f127c9d73b9de57f1a1131b82bb5320ee651f6a",
|
||||
"sha256:fc155a6b553c66c838d1a22dba1dc9f5f505c43285a878c6f74a79c024750b83"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.5.0"
|
||||
},
|
||||
"factory-boy": {
|
||||
"hashes": [
|
||||
"sha256:6f25cc4761ac109efd503f096e2ad99421b1159f01a29dbb917359dcd68e08ca",
|
||||
"sha256:d552cb872b310ae78bd7429bf318e42e1e903b1a109e899a523293dfa762ea4f"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.11.1"
|
||||
},
|
||||
"faker": {
|
||||
"hashes": [
|
||||
"sha256:ea7cfd3aeb1544732d08bd9cfba40c5b78e3a91e17b1a0698ab81bfc5554c628",
|
||||
"sha256:f6d67f04abfb2b4bea7afc7fa6c18cf4c523a67956e455668be9ae42bccc21ad"
|
||||
],
|
||||
"markers": "python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.2.*' and python_version >= '2.7'",
|
||||
"version": "==0.9.0"
|
||||
},
|
||||
"filemagic": {
|
||||
"hashes": [
|
||||
"sha256:e684359ef40820fe406f0ebc5bf8a78f89717bdb7fed688af68082d991d6dbf3"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.6"
|
||||
},
|
||||
"fuzzywuzzy": {
|
||||
"hashes": [
|
||||
"sha256:3759bc6859daa0eecef8c82b45404bdac20c23f23136cf4c18b46b426bbc418f",
|
||||
"sha256:5b36957ccf836e700f4468324fa80ba208990385392e217be077d5cd738ae602"
|
||||
],
|
||||
"index": "pypi",
|
||||
"markers": null,
|
||||
"version": "==0.15.0"
|
||||
},
|
||||
"gunicorn": {
|
||||
"hashes": [
|
||||
"sha256:aa8e0b40b4157b36a5df5e599f45c9c76d6af43845ba3b3b0efe2c70473c2471",
|
||||
"sha256:fa2662097c66f920f53f70621c6c58ca4a3c4d3434205e608e121b5b3b71f4f3"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==19.9.0"
|
||||
},
|
||||
"idna": {
|
||||
"hashes": [
|
||||
"sha256:156a6814fb5ac1fc6850fb002e0852d56c0c8d2531923a51032d1b70760e186e",
|
||||
"sha256:684a38a6f903c1d71d6d5fac066b58d7768af4de2b832e426ec79c30daa94a16"
|
||||
],
|
||||
"version": "==2.7"
|
||||
},
|
||||
"inotify-simple": {
|
||||
"hashes": [
|
||||
"sha256:fc2c10dd73278a1027d0663f2db51240af5946390f363a154361406ebdddd8dd"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.1.8"
|
||||
},
|
||||
"langdetect": {
|
||||
"hashes": [
|
||||
"sha256:91a170d5f0ade380db809b3ba67f08e95fe6c6c8641f96d67a51ff7e98a9bf30"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.0.7"
|
||||
},
|
||||
"more-itertools": {
|
||||
"hashes": [
|
||||
"sha256:c187a73da93e7a8acc0001572aebc7e3c69daf7bf6881a2cea10650bd4420092",
|
||||
"sha256:c476b5d3a34e12d40130bc2f935028b5f636df8f372dc2c1c01dc19681b2039e",
|
||||
"sha256:fcbfeaea0be121980e15bc97b3817b5202ca73d0eae185b4550cbfce2a3ebb3d"
|
||||
],
|
||||
"version": "==4.3.0"
|
||||
},
|
||||
"pdftotext": {
|
||||
"hashes": [
|
||||
"sha256:b7312302007e19fc784263a321b41682f01a582af84e14200cef53b3f4e69a50"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.1.0"
|
||||
},
|
||||
"pillow": {
|
||||
"hashes": [
|
||||
"sha256:00def5b638994f888d1058e4d17c86dec8e1113c3741a0a8a659039aec59a83a",
|
||||
"sha256:026449b64e559226cdb8e6d8c931b5965d8fc90ec18ebbb0baa04c5b36503c72",
|
||||
"sha256:03dbb224ee196ef30ed2156d41b579143e1efeb422974719a5392fc035e4f574",
|
||||
"sha256:03eb0e04f929c102ae24bc436bf1c0c60a4e63b07ebd388e84d8b219df3e6acd",
|
||||
"sha256:1be66b9a89e367e7d20d6cae419794997921fe105090fafd86ef39e20a3baab2",
|
||||
"sha256:1e977a3ed998a599bda5021fb2c2889060617627d3ae228297a529a082a3cd5c",
|
||||
"sha256:22cf3406d135cfcc13ec6228ade774c8461e125c940e80455f500638429be273",
|
||||
"sha256:24adccf1e834f82718c7fc8e3ec1093738da95144b8b1e44c99d5fc7d3e9c554",
|
||||
"sha256:2a3e362c97a5e6a259ee9cd66553292a1f8928a5bdfa3622fdb1501570834612",
|
||||
"sha256:3832e26ecbc9d8a500821e3a1d3765bda99d04ae29ffbb2efba49f5f788dc934",
|
||||
"sha256:4fd1f0c2dc02aaec729d91c92cd85a2df0289d88e9f68d1e8faba750bb9c4786",
|
||||
"sha256:4fda62030f2c515b6e2e673c57caa55cb04026a81968f3128aae10fc28e5cc27",
|
||||
"sha256:5044d75a68b49ce36a813c82d8201384207112d5d81643937fc758c05302f05b",
|
||||
"sha256:522184556921512ec484cb93bd84e0bab915d0ac5a372d49571c241a7f73db62",
|
||||
"sha256:5914cff11f3e920626da48e564be6818831713a3087586302444b9c70e8552d9",
|
||||
"sha256:6661a7908d68c4a133e03dac8178287aa20a99f841ea90beeb98a233ae3fd710",
|
||||
"sha256:79258a8df3e309a54c7ef2ef4a59bb8e28f7e4a8992a3ad17c24b1889ced44f3",
|
||||
"sha256:7d74c20b8f1c3e99d3f781d3b8ff5abfefdd7363d61e23bdeba9992ff32cc4b4",
|
||||
"sha256:81918afeafc16ba5d9d0d4e9445905f21aac969a4ebb6f2bff4b9886da100f4b",
|
||||
"sha256:8194d913ca1f459377c8a4ed8f9b7ad750068b8e0e3f3f9c6963fcc87a84515f",
|
||||
"sha256:84d5d31200b11b3c76fab853b89ac898bf2d05c8b3da07c1fcc23feb06359d6e",
|
||||
"sha256:989981db57abffb52026b114c9a1f114c7142860a6d30a352d28f8cbf186500b",
|
||||
"sha256:a3d7511d3fad1618a82299aab71a5fceee5c015653a77ffea75ced9ef917e71a",
|
||||
"sha256:b3ef168d4d6fd4fa6685aef7c91400f59f7ab1c0da734541f7031699741fb23f",
|
||||
"sha256:c1c5792b6e74bbf2af0f8e892272c2a6c48efa895903211f11b8342e03129fea",
|
||||
"sha256:c5dcb5a56aebb8a8f2585042b2f5c496d7624f0bcfe248f0cc33ceb2fd8d39e7",
|
||||
"sha256:e2bed4a04e2ca1050bb5f00865cf2f83c0b92fd62454d9244f690fcd842e27a4",
|
||||
"sha256:e87a527c06319428007e8c30511e1f0ce035cb7f14bb4793b003ed532c3b9333",
|
||||
"sha256:f63e420180cbe22ff6e32558b612e75f50616fc111c5e095a4631946c782e109",
|
||||
"sha256:f8b3d413c5a8f84b12cd4c5df1d8e211777c9852c6be3ee9c094b626644d3eab"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==5.2.0"
|
||||
},
|
||||
"pluggy": {
|
||||
"hashes": [
|
||||
"sha256:6e3836e39f4d36ae72840833db137f7b7d35105079aee6ec4a62d9f80d594dd1",
|
||||
"sha256:95eb8364a4708392bae89035f45341871286a333f749c3141c20573d2b3876e1"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==0.7.1"
|
||||
},
|
||||
"py": {
|
||||
"hashes": [
|
||||
"sha256:06a30435d058473046be836d3fc4f27167fd84c45b99704f2fb5509ef61f9af1",
|
||||
"sha256:50402e9d1c9005d759426988a492e0edaadb7f4e68bcddfea586bc7432d009c6"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.6.0"
|
||||
},
|
||||
"pycodestyle": {
|
||||
"hashes": [
|
||||
"sha256:cbc619d09254895b0d12c2c691e237b2e91e9b2ecf5e84c26b35400f93dcfb83",
|
||||
"sha256:cbfca99bd594a10f674d0cd97a3d802a1fdef635d4361e1a2658de47ed261e3a"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.4.0"
|
||||
},
|
||||
"pyocr": {
|
||||
"hashes": [
|
||||
"sha256:b6ba6263fd92da56627dff6d263d991a2246aacd117d1788f11b93f419ca395f"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.5.3"
|
||||
},
|
||||
"pytest": {
|
||||
"hashes": [
|
||||
"sha256:453cbbbe5ce6db38717d282b758b917de84802af4288910c12442984bde7b823",
|
||||
"sha256:a8a07f84e680482eb51e244370aaf2caa6301ef265f37c2bdefb3dd3b663f99d"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==3.8.0"
|
||||
},
|
||||
"pytest-cov": {
|
||||
"hashes": [
|
||||
"sha256:513c425e931a0344944f84ea47f3956be0e416d95acbd897a44970c8d926d5d7",
|
||||
"sha256:e360f048b7dae3f2f2a9a4d067b2dd6b6a015d384d1577c994a43f3f7cbad762"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.6.0"
|
||||
},
|
||||
"pytest-django": {
|
||||
"hashes": [
|
||||
"sha256:2d2e0a618d91c280d463e90bcbea9b4e417609157f611a79685b1c561c4c0836",
|
||||
"sha256:59683def396923b78d7e191a7086a48193f8d5db869ace79acb38f906522bc7b"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==3.4.2"
|
||||
},
|
||||
"pytest-env": {
|
||||
"hashes": [
|
||||
"sha256:7e94956aef7f2764f3c147d216ce066bf6c42948bb9e293169b1b1c880a580c2"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.6.2"
|
||||
},
|
||||
"pytest-forked": {
|
||||
"hashes": [
|
||||
"sha256:e4500cd0509ec4a26535f7d4112a8cc0f17d3a41c29ffd4eab479d2a55b30805",
|
||||
"sha256:f275cb48a73fc61a6710726348e1da6d68a978f0ec0c54ece5a5fae5977e5a08"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==0.2"
|
||||
},
|
||||
"pytest-sugar": {
|
||||
"hashes": [
|
||||
"sha256:ab8cc42faf121344a4e9b13f39a51257f26f410e416c52ea11078cdd00d98a2c"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.9.1"
|
||||
},
|
||||
"pytest-xdist": {
|
||||
"hashes": [
|
||||
"sha256:0875deac20f6d96597036bdf63970887a6f36d28289c2f6682faf652dfea687b",
|
||||
"sha256:28e25e79698b2662b648319d3971c0f9ae0e6500f88258ccb9b153c31110ba9b"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.23.0"
|
||||
},
|
||||
"python-dateutil": {
|
||||
"hashes": [
|
||||
"sha256:1adb80e7a782c12e52ef9a8182bebeb73f1d7e24e374397af06fb4956c8dc5c0",
|
||||
"sha256:e27001de32f627c22380a688bcc43ce83504a7bc5da472209b4c70f02829f0b8"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.7.3"
|
||||
},
|
||||
"python-dotenv": {
|
||||
"hashes": [
|
||||
"sha256:122290a38ece9fe4f162dc7c95cae3357b983505830a154d3c98ef7f6c6cea77",
|
||||
"sha256:4a205787bc829233de2a823aa328e44fd9996fedb954989a21f1fc67c13d7a77"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.9.1"
|
||||
},
|
||||
"python-gnupg": {
|
||||
"hashes": [
|
||||
"sha256:2d158dfc6b54927752b945ebe57e6a0c45da27747fa3b9ae66eccc0d2147ac0d",
|
||||
"sha256:faa69bab58ed0936f0ccf96c99b92369b7a1819305d37dfe5c927d21a437a09d"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==0.4.3"
|
||||
},
|
||||
"python-levenshtein": {
|
||||
"hashes": [
|
||||
"sha256:033a11de5e3d19ea25c9302d11224e1a1898fe5abd23c61c7c360c25195e3eb1"
|
||||
],
|
||||
"version": "==0.12.0"
|
||||
},
|
||||
"pytz": {
|
||||
"hashes": [
|
||||
"sha256:a061aa0a9e06881eb8b3b2b43f05b9439d6583c206d0a6c340ff72a7b6669053",
|
||||
"sha256:ffb9ef1de172603304d9d2819af6f5ece76f2e85ec10692a524dd876e72bf277"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2018.5"
|
||||
},
|
||||
"regex": {
|
||||
"hashes": [
|
||||
"sha256:22d7ef8c2df344328a8a3c61edade2ee714e5de9360911d22a9213931c769faa",
|
||||
"sha256:3a699780c6b712c67dc23207b129ccc6a7e1270233f7aadead3ea3f83c893702",
|
||||
"sha256:42f460d349baebd5faec02a0c920988fb0300b24baf898d9c139886565b66b6c",
|
||||
"sha256:43bf3d79940cbdf19adda838d8b26b28b47bec793cda46590b5b25703742f440",
|
||||
"sha256:47d6c7f0588ef33464e00023067c4e7cce68e0d6a686a73c7ee15abfdad503d4",
|
||||
"sha256:5b879f59f25ed9b91bc8693a9a994014b431f224f492519ad0255ce6b54b83e5",
|
||||
"sha256:8ba0093c412900f636b0f826c597a0c3ea0e395344bc99894ddefe88b76c9c7e",
|
||||
"sha256:a4789254a1a0bd7a637036cce0b7ed72d8cc864e93f2e9cfd10ac00ae27bb7b0",
|
||||
"sha256:b73cea07117dca888b0c3671770b501bef19aac9c45c8ffdb5bea2cca2377b0a",
|
||||
"sha256:d3eb59fa3e5b5438438ec97acd9dc86f077428e020b015b43987e35bea68ef4c",
|
||||
"sha256:d51d232b4e2f106deaf286001f563947fee255bc5bd209a696f027e15cf0a1e7",
|
||||
"sha256:d59b03131a8e35061b47a8f186324a95eaf30d5f6ee9cc0637e7b87d29c7c9b5",
|
||||
"sha256:dd705df1b47470388fc4630e4df3cbbe7677e2ab80092a1c660cae630a307b2d",
|
||||
"sha256:e87fffa437a4b00afb17af785da9b01618425d6cd984c677639deb937037d8f2",
|
||||
"sha256:ed40e0474ab5ab228a8d133759d451b31d3ccdebaff698646e54aff82c3de4f8"
|
||||
],
|
||||
"version": "==2018.8.29"
|
||||
},
|
||||
"requests": {
|
||||
"hashes": [
|
||||
"sha256:63b52e3c866428a224f97cab011de738c36aec0185aa91cfacd418b5d58911d1",
|
||||
"sha256:ec22d826a36ed72a7358ff3fe56cbd4ba69dd7a6718ffd450ff0e9df7a47ce6a"
|
||||
],
|
||||
"version": "==2.19.1"
|
||||
},
|
||||
"six": {
|
||||
"hashes": [
|
||||
"sha256:70e8a77beed4562e7f14fe23a786b54f6296e34344c23bc42f07b15018ff98e9",
|
||||
"sha256:832dc0e10feb1aa2c68dcc57dbb658f1c7e65b9b61af69048abc87a2db00a0eb"
|
||||
],
|
||||
"version": "==1.11.0"
|
||||
},
|
||||
"termcolor": {
|
||||
"hashes": [
|
||||
"sha256:1d6d69ce66211143803fbc56652b41d73b4a400a2891d7bf7a1cdf4c02de613b"
|
||||
],
|
||||
"version": "==1.1.0"
|
||||
},
|
||||
"text-unidecode": {
|
||||
"hashes": [
|
||||
"sha256:5a1375bb2ba7968740508ae38d92e1f889a0832913cb1c447d5e2046061a396d",
|
||||
"sha256:801e38bd550b943563660a91de8d4b6fa5df60a542be9093f7abf819f86050cc"
|
||||
],
|
||||
"version": "==1.2"
|
||||
},
|
||||
"tzlocal": {
|
||||
"hashes": [
|
||||
"sha256:4ebeb848845ac898da6519b9b31879cf13b6626f7184c496037b818e238f2c4e"
|
||||
],
|
||||
"version": "==1.5.1"
|
||||
},
|
||||
"urllib3": {
|
||||
"hashes": [
|
||||
"sha256:a68ac5e15e76e7e5dd2b8f94007233e01effe3e50e8daddf69acfd81cb686baf",
|
||||
"sha256:b5725a0bd4ba422ab0e66e89e030c806576753ea3ee08554382c14e685d117b5"
|
||||
],
|
||||
"markers": "python_version >= '2.6' and python_version != '3.2.*' and python_version != '3.0.*' and python_version != '3.1.*' and python_version < '4' and python_version != '3.3.*'",
|
||||
"version": "==1.23"
|
||||
}
|
||||
},
|
||||
"develop": {
|
||||
"alabaster": {
|
||||
"hashes": [
|
||||
"sha256:674bb3bab080f598371f4443c5008cbfeb1a5e622dd312395d2d82af2c54c456",
|
||||
"sha256:b63b1f4dc77c074d386752ec4a8a7517600f6c0db8cd42980cae17ab7b3275d7"
|
||||
],
|
||||
"version": "==0.7.11"
|
||||
},
|
||||
"babel": {
|
||||
"hashes": [
|
||||
"sha256:6778d85147d5d85345c14a26aada5e478ab04e39b078b0745ee6870c2b5cf669",
|
||||
"sha256:8cba50f48c529ca3fa18cf81fa9403be176d374ac4d60738b839122dfaaa3d23"
|
||||
],
|
||||
"version": "==2.6.0"
|
||||
},
|
||||
"backcall": {
|
||||
"hashes": [
|
||||
"sha256:38ecd85be2c1e78f77fd91700c76e14667dc21e2713b63876c0eb901196e01e4",
|
||||
"sha256:bbbf4b1e5cd2bdb08f915895b51081c041bac22394fdfcfdfbe9f14b77c08bf2"
|
||||
],
|
||||
"version": "==0.1.0"
|
||||
},
|
||||
"certifi": {
|
||||
"hashes": [
|
||||
"sha256:376690d6f16d32f9d1fe8932551d80b23e9d393a8578c5633a2ed39a64861638",
|
||||
"sha256:456048c7e371c089d0a77a5212fb37a2c2dce1e24146e3b7e0261736aaeaa22a"
|
||||
],
|
||||
"version": "==2018.8.24"
|
||||
},
|
||||
"chardet": {
|
||||
"hashes": [
|
||||
"sha256:84ab92ed1c4d4f16916e05906b6b75a6c0fb5db821cc65e70cbd64a3e2a5eaae",
|
||||
"sha256:fc323ffcaeaed0e0a02bf4d117757b98aed530d9ed4531e3e15460124c106691"
|
||||
],
|
||||
"version": "==3.0.4"
|
||||
},
|
||||
"decorator": {
|
||||
"hashes": [
|
||||
"sha256:2c51dff8ef3c447388fe5e4453d24a2bf128d3a4c32af3fabef1f01c6851ab82",
|
||||
"sha256:c39efa13fbdeb4506c476c9b3babf6a718da943dab7811c206005a4a956c080c"
|
||||
],
|
||||
"version": "==4.3.0"
|
||||
},
|
||||
"docutils": {
|
||||
"hashes": [
|
||||
"sha256:02aec4bd92ab067f6ff27a38a38a41173bf01bed8f89157768c1573f53e474a6",
|
||||
"sha256:51e64ef2ebfb29cae1faa133b3710143496eca21c530f3f71424d77687764274",
|
||||
"sha256:7a4bd47eaf6596e1295ecb11361139febe29b084a87bf005bf899f9a42edc3c6"
|
||||
],
|
||||
"version": "==0.14"
|
||||
},
|
||||
"idna": {
|
||||
"hashes": [
|
||||
"sha256:156a6814fb5ac1fc6850fb002e0852d56c0c8d2531923a51032d1b70760e186e",
|
||||
"sha256:684a38a6f903c1d71d6d5fac066b58d7768af4de2b832e426ec79c30daa94a16"
|
||||
],
|
||||
"version": "==2.7"
|
||||
},
|
||||
"imagesize": {
|
||||
"hashes": [
|
||||
"sha256:3f349de3eb99145973fefb7dbe38554414e5c30abd0c8e4b970a7c9d09f3a1d8",
|
||||
"sha256:f3832918bc3c66617f92e35f5d70729187676313caa60c187eb0f28b8fe5e3b5"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.1.0"
|
||||
},
|
||||
"ipython": {
|
||||
"hashes": [
|
||||
"sha256:007dcd929c14631f83daff35df0147ea51d1af420da303fd078343878bd5fb62",
|
||||
"sha256:b0f2ef9eada4a68ef63ee10b6dde4f35c840035c50fd24265f8052c98947d5a4"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==6.5.0"
|
||||
},
|
||||
"ipython-genutils": {
|
||||
"hashes": [
|
||||
"sha256:72dd37233799e619666c9f639a9da83c34013a73e8bbc79a7a6348d93c61fab8",
|
||||
"sha256:eb2e116e75ecef9d4d228fdc66af54269afa26ab4463042e33785b887c628ba8"
|
||||
],
|
||||
"version": "==0.2.0"
|
||||
},
|
||||
"jedi": {
|
||||
"hashes": [
|
||||
"sha256:b409ed0f6913a701ed474a614a3bb46e6953639033e31f769ca7581da5bd1ec1",
|
||||
"sha256:c254b135fb39ad76e78d4d8f92765ebc9bf92cbc76f49e97ade1d5f5121e1f6f"
|
||||
],
|
||||
"version": "==0.12.1"
|
||||
},
|
||||
"jinja2": {
|
||||
"hashes": [
|
||||
"sha256:74c935a1b8bb9a3947c50a54766a969d4846290e1e788ea44c1392163723c3bd",
|
||||
"sha256:f84be1bb0040caca4cea721fcbbbbd61f9be9464ca236387158b0feea01914a4"
|
||||
],
|
||||
"version": "==2.10"
|
||||
},
|
||||
"markupsafe": {
|
||||
"hashes": [
|
||||
"sha256:a6be69091dac236ea9c6bc7d012beab42010fa914c459791d627dad4910eb665"
|
||||
],
|
||||
"version": "==1.0"
|
||||
},
|
||||
"packaging": {
|
||||
"hashes": [
|
||||
"sha256:e9215d2d2535d3ae866c3d6efc77d5b24a0192cce0ff20e42896cc0664f889c0",
|
||||
"sha256:f019b770dd64e585a99714f1fd5e01c7a8f11b45635aa953fd41c689a657375b"
|
||||
],
|
||||
"version": "==17.1"
|
||||
},
|
||||
"parso": {
|
||||
"hashes": [
|
||||
"sha256:35704a43a3c113cce4de228ddb39aab374b8004f4f2407d070b6a2ca784ce8a2",
|
||||
"sha256:895c63e93b94ac1e1690f5fdd40b65f07c8171e3e53cbd7793b5b96c0e0a7f24"
|
||||
],
|
||||
"version": "==0.3.1"
|
||||
},
|
||||
"pexpect": {
|
||||
"hashes": [
|
||||
"sha256:2a8e88259839571d1251d278476f3eec5db26deb73a70be5ed5dc5435e418aba",
|
||||
"sha256:3fbd41d4caf27fa4a377bfd16fef87271099463e6fa73e92a52f92dfee5d425b"
|
||||
],
|
||||
"markers": "sys_platform != 'win32'",
|
||||
"version": "==4.6.0"
|
||||
},
|
||||
"pickleshare": {
|
||||
"hashes": [
|
||||
"sha256:84a9257227dfdd6fe1b4be1319096c20eb85ff1e82c7932f36efccfe1b09737b",
|
||||
"sha256:c9a2541f25aeabc070f12f452e1f2a8eae2abd51e1cd19e8430402bdf4c1d8b5"
|
||||
],
|
||||
"version": "==0.7.4"
|
||||
},
|
||||
"pluggy": {
|
||||
"hashes": [
|
||||
"sha256:6e3836e39f4d36ae72840833db137f7b7d35105079aee6ec4a62d9f80d594dd1",
|
||||
"sha256:95eb8364a4708392bae89035f45341871286a333f749c3141c20573d2b3876e1"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==0.7.1"
|
||||
},
|
||||
"prompt-toolkit": {
|
||||
"hashes": [
|
||||
"sha256:1df952620eccb399c53ebb359cc7d9a8d3a9538cb34c5a1344bdbeb29fbcc381",
|
||||
"sha256:3f473ae040ddaa52b52f97f6b4a493cfa9f5920c255a12dc56a7d34397a398a4",
|
||||
"sha256:858588f1983ca497f1cf4ffde01d978a3ea02b01c8a26a8bbc5cd2e66d816917"
|
||||
],
|
||||
"version": "==1.0.15"
|
||||
},
|
||||
"ptyprocess": {
|
||||
"hashes": [
|
||||
"sha256:923f299cc5ad920c68f2bc0bc98b75b9f838b93b599941a6b63ddbc2476394c0",
|
||||
"sha256:d7cc528d76e76342423ca640335bd3633420dc1366f258cb31d05e865ef5ca1f"
|
||||
],
|
||||
"version": "==0.6.0"
|
||||
},
|
||||
"py": {
|
||||
"hashes": [
|
||||
"sha256:06a30435d058473046be836d3fc4f27167fd84c45b99704f2fb5509ef61f9af1",
|
||||
"sha256:50402e9d1c9005d759426988a492e0edaadb7f4e68bcddfea586bc7432d009c6"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.6.0"
|
||||
},
|
||||
"pygments": {
|
||||
"hashes": [
|
||||
"sha256:78f3f434bcc5d6ee09020f92ba487f95ba50f1e3ef83ae96b9d5ffa1bab25c5d",
|
||||
"sha256:dbae1046def0efb574852fab9e90209b23f556367b5a320c0bcb871c77c3e8cc"
|
||||
],
|
||||
"version": "==2.2.0"
|
||||
},
|
||||
"pyparsing": {
|
||||
"hashes": [
|
||||
"sha256:0832bcf47acd283788593e7a0f542407bd9550a55a8a8435214a1960e04bcb04",
|
||||
"sha256:fee43f17a9c4087e7ed1605bd6df994c6173c1e977d7ade7b651292fab2bd010"
|
||||
],
|
||||
"version": "==2.2.0"
|
||||
},
|
||||
"pytz": {
|
||||
"hashes": [
|
||||
"sha256:a061aa0a9e06881eb8b3b2b43f05b9439d6583c206d0a6c340ff72a7b6669053",
|
||||
"sha256:ffb9ef1de172603304d9d2819af6f5ece76f2e85ec10692a524dd876e72bf277"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2018.5"
|
||||
},
|
||||
"requests": {
|
||||
"hashes": [
|
||||
"sha256:63b52e3c866428a224f97cab011de738c36aec0185aa91cfacd418b5d58911d1",
|
||||
"sha256:ec22d826a36ed72a7358ff3fe56cbd4ba69dd7a6718ffd450ff0e9df7a47ce6a"
|
||||
],
|
||||
"version": "==2.19.1"
|
||||
},
|
||||
"simplegeneric": {
|
||||
"hashes": [
|
||||
"sha256:dc972e06094b9af5b855b3df4a646395e43d1c9d0d39ed345b7393560d0b9173"
|
||||
],
|
||||
"version": "==0.8.1"
|
||||
},
|
||||
"six": {
|
||||
"hashes": [
|
||||
"sha256:70e8a77beed4562e7f14fe23a786b54f6296e34344c23bc42f07b15018ff98e9",
|
||||
"sha256:832dc0e10feb1aa2c68dcc57dbb658f1c7e65b9b61af69048abc87a2db00a0eb"
|
||||
],
|
||||
"version": "==1.11.0"
|
||||
},
|
||||
"snowballstemmer": {
|
||||
"hashes": [
|
||||
"sha256:919f26a68b2c17a7634da993d91339e288964f93c274f1343e3bbbe2096e1128",
|
||||
"sha256:9f3bcd3c401c3e862ec0ebe6d2c069ebc012ce142cce209c098ccb5b09136e89"
|
||||
],
|
||||
"version": "==1.2.1"
|
||||
},
|
||||
"sphinx": {
|
||||
"hashes": [
|
||||
"sha256:217a7705adcb573da5bbe1e0f5cab4fa0bd89fd9342c9159121746f593c2d5a4",
|
||||
"sha256:a602513f385f1d5785ff1ca420d9c7eb1a1b63381733b2f0ea8188a391314a86"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==1.7.9"
|
||||
},
|
||||
"sphinxcontrib-websupport": {
|
||||
"hashes": [
|
||||
"sha256:68ca7ff70785cbe1e7bccc71a48b5b6d965d79ca50629606c7861a21b206d9dd",
|
||||
"sha256:9de47f375baf1ea07cdb3436ff39d7a9c76042c10a769c52353ec46e4e8fc3b9"
|
||||
],
|
||||
"markers": "python_version != '3.2.*' and python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.1.*' and python_version != '3.3.*'",
|
||||
"version": "==1.1.0"
|
||||
},
|
||||
"tox": {
|
||||
"hashes": [
|
||||
"sha256:37cf240781b662fb790710c6998527e65ca6851eace84d1595ee71f7af4e85f7",
|
||||
"sha256:eb61aa5bcce65325538686f09848f04ef679b5cd9b83cc491272099b28739600"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==3.2.1"
|
||||
},
|
||||
"traitlets": {
|
||||
"hashes": [
|
||||
"sha256:9c4bd2d267b7153df9152698efb1050a5d84982d3384a37b2c1f7723ba3e7835",
|
||||
"sha256:c6cb5e6f57c5a9bdaa40fa71ce7b4af30298fbab9ece9815b5d995ab6217c7d9"
|
||||
],
|
||||
"version": "==4.3.2"
|
||||
},
|
||||
"urllib3": {
|
||||
"hashes": [
|
||||
"sha256:a68ac5e15e76e7e5dd2b8f94007233e01effe3e50e8daddf69acfd81cb686baf",
|
||||
"sha256:b5725a0bd4ba422ab0e66e89e030c806576753ea3ee08554382c14e685d117b5"
|
||||
],
|
||||
"markers": "python_version >= '2.6' and python_version != '3.2.*' and python_version != '3.0.*' and python_version != '3.1.*' and python_version < '4' and python_version != '3.3.*'",
|
||||
"version": "==1.23"
|
||||
},
|
||||
"virtualenv": {
|
||||
"hashes": [
|
||||
"sha256:2ce32cd126117ce2c539f0134eb89de91a8413a29baac49cbab3eb50e2026669",
|
||||
"sha256:ca07b4c0b54e14a91af9f34d0919790b016923d157afda5efdde55c96718f752"
|
||||
],
|
||||
"markers": "python_version >= '2.7' and python_version != '3.0.*' and python_version != '3.2.*' and python_version != '3.1.*'",
|
||||
"version": "==16.0.0"
|
||||
},
|
||||
"wcwidth": {
|
||||
"hashes": [
|
||||
"sha256:3df37372226d6e63e1b1e1eda15c594bca98a22d33a23832a90998faa96bc65e",
|
||||
"sha256:f4ebe71925af7b40a864553f761ed559b43544f8f71746c2d756c7fe788ade7c"
|
||||
],
|
||||
"version": "==0.1.7"
|
||||
}
|
||||
}
|
||||
}
|
||||
84
README-de.md
Normal file
84
README-de.md
Normal file
@@ -0,0 +1,84 @@
|
||||
*[English](README.md)*<br/>
|
||||
*[Greek](README-el.md)*
|
||||
|
||||
# Paperless
|
||||
|
||||
[](https://paperless.readthedocs.org/) [](https://gitter.im/danielquinn/paperless) [](https://travis-ci.org/danielquinn/paperless) [](https://coveralls.io/github/danielquinn/paperless?branch=master) [](https://github.com/danielquinn/paperless/blob/master/THANKS.md)
|
||||
|
||||
Indexiere und archiviere alle deine eingescannten Papierdokumente
|
||||
|
||||
Ich hasse Papier. Abgesehen von Umweltproblemen, ist es der Albtraum einer technisch-interessierten Person:
|
||||
|
||||
* Es gibt keine Suchfunktion
|
||||
* Es braucht physischen Platz
|
||||
* Sicherungen bedeuten mehr Papier
|
||||
|
||||
In den vergangenen Monaten hatte ich mehrmals das Problem, das richtige Dokument nicht zur Hand zu haben. Manchmal warf ich Dokumente weg, die ich noch gebraucht hätte (wer behält schon Wasserrechnungen für zwei Jahre?), andere verlor ich einfach... weil PAPIER. Ich schrieb dies, um mein Leben einfacher zu machen.
|
||||
|
||||
|
||||
|
||||
## Wie es funktioniert
|
||||
|
||||
Paperless steuert nicht deinen Scanner, es hilft nur damit umzugehen, was der Scanner herausspuckt
|
||||
|
||||
1. Kaufe einen Dokumentenscanner, der an einen Ort in deinem Netzwerk schreiben kann. Wenn du Inspirationen brauchst, schau in die [Scannerempfehlungen](https://paperless.readthedocs.io/en/latest/scanners.html).
|
||||
2. Stelle "Scanne zu FTP" oder ähnliches ein. Es sollte möglich sein, eingescannte Bilder ohne etwas tun zu müssen an einen Server hochzuladen. Natürlich kannst du auch die einscannte Datei händisch hochladen, wenn der Scanner automatisches Hochladen nicht unterstützt. Paperless ist es egal, wie die Dokumente in seinen lokalen Konsumordner gelangen.
|
||||
3. Besitze einen Zielserver, lasse das Papierless-Konsumskript laufen, um die Datei mit OCR zu versehen und sie in einer lokalen Datenbank zu indexieren.
|
||||
4. Benutze die Weboberfläche, um die Datenbank zu durchforsten und zu finden, was du suchst.
|
||||
5. Lade die PDF-Datei, die du brauchst/möchtest über die Weboberfläche herunter und mach was auch immer du willst damit. Du kannst es auch drucken und versenden, so als wäre es das Original. In den meisten Fällen, wird das niemanden interessieren oder bemerken.
|
||||
|
||||
Hier das, was du bekommt:
|
||||
|
||||
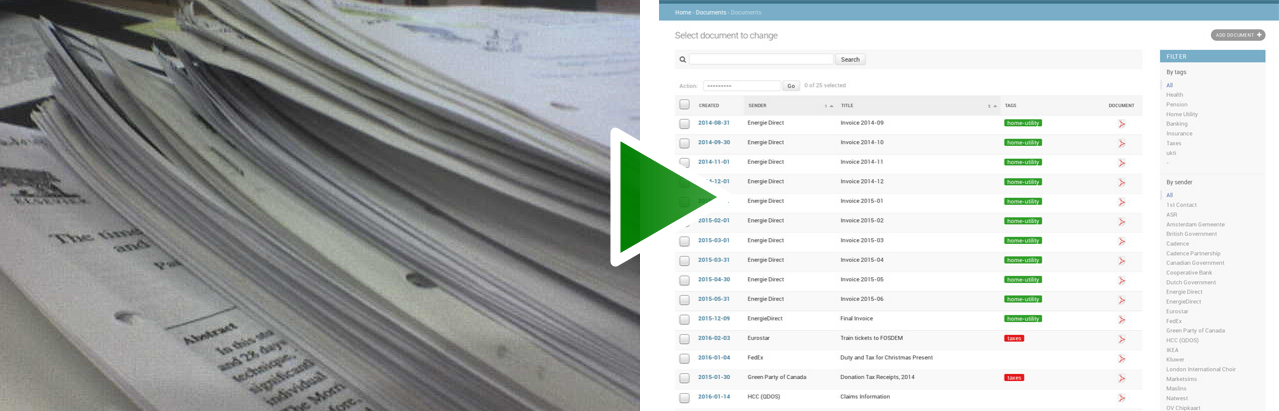
|
||||
|
||||
|
||||
## Dokumentation
|
||||
|
||||
Diese ist komplett verfügbar auf [ReadTheDocs](https://paperless.readthedocs.org/).
|
||||
|
||||
|
||||
## Anforderungen
|
||||
|
||||
Dies alles ist eine wirklich ziemlich einfache, glänzende und benutzerfreundliche Hülle rund um einige sehr mächtige Werkzeuge.
|
||||
|
||||
* [ImageMagick](http://imagemagick.org/) wandelt Bilder zwischen Farbe und Graustufen um.
|
||||
* [Tesseract](https://github.com/tesseract-ocr) erledigt die Buchstabenerkennung.
|
||||
* [Unpaper](https://www.flameeyes.eu/projects/unpaper) bereinigt und begradigt das eingescannte Bild.
|
||||
* [GNU Privacy Guard](https://gnupg.org/) wird als Verschlüsselungsbackend genutzt.
|
||||
* [Python 3](https://python.org/) ist die Sprache des Projekts.
|
||||
* [Pillow](https://pypi.python.org/pypi/pillowfight/) lädt die Bilddaten als Python-Objekt, um sie mit PyOCR zu verwenden.
|
||||
* [PyOCR](https://github.com/jflesch/pyocr) ist ein glatter, programmatischer Wrapper um Tesseract.
|
||||
* [Django](https://www.djangoproject.com/) ist das Framework, auf das dieses Projekt aufbaut.
|
||||
* [Python-GNUPG](http://pythonhosted.org/python-gnupg/) entschlüsselt die PDFs auf Abruf, um das Herunterladen unverschlüsselter Dateien zu ermöglichen, während die verschlüsselten Dateien auf der Festplatte bleiben.
|
||||
|
||||
|
||||
## Status des Projekts
|
||||
|
||||
Dieses Projekt wurde um 2015 gestartet und es gibt viele Leute, die es verwenden. Warum auch immer ist es ziemlich beliebt in Deutschland -- vielleicht kann jemand dort drüben mich über das Warum aufklären.
|
||||
|
||||
Ich entwickle keine neuen Funktionen mehr für Paperless, weil es genau das tut, was ich brauche und meine Aufmerksamkeit meinem neuesten Projekt [Aletheia](https://github.com/danielquinn/aletheia) gewidmet ist. Ich verlasse jedoch nicht das Projekt. Ich bin glücklich damit, Pull Requests zu begutachten und Fragen im Issue-Bereich zu beantworten. Wenn du ein Entwickler bist und eine neue Funktion willst, reihe sie in den Issues ein und/oder sende einen PR! Ich bin glücklich damit, neue Sachen hinzuzufügen, habe aber einfach nicht die Zeit, sie selbst zu erarbeiten.
|
||||
|
||||
|
||||
## Verknüpfte Prjekte
|
||||
|
||||
Paperless gibt es bereits seit einer Weile und Leute haben damit angefangen, Sachen rund um Paperless zu entwickeln. Wenn du einer dieser Menschen bist, kannst du dein Projekt zu dieser Liste hinzufügen:
|
||||
|
||||
* [Paperless Desktop](https://github.com/thomasbrueggemann/paperless-desktop): Eine Desktop-Oberfläche für deine Paperless-Installation. Läuft auf Mac, Linux und Windows.
|
||||
* [ansible-role-paperless](https://github.com/ovv/ansible-role-paperless): Eine einfache Möglichkeit, Paperless via Ansible laufen zu lassen.
|
||||
|
||||
|
||||
## Ähnliche Projekte
|
||||
|
||||
Es gibt da draußen auch das Projekt [Mayan EDMS](https://mayan.readthedocs.org/en/latest/), welches überraschenderweise sehr große überschneidende Techniken hat wie Paperless. Mayan EDMS ist *viel* funktionsreicher und kommt ebenso mit einer glatten UI, aber kommt noch mit Python2; basiert jedoch auch auf Django und verwendet ein Konsummodell mit Tesseract und Unpaper. Es kann sein, dass Paperless weniger Ressourcen verbraucht, aber um ehrlich zu sein, hab ich das noch nicht selbst getestet. Eine Sache jedoch ist klar, *Paperless* ist ein **viel** besserer Name.
|
||||
|
||||
|
||||
## Wichtiger Hinweis
|
||||
|
||||
Dokumentenscanner werden typerweise verwendet, um sensible Dokumente zu scannen. Dinge wie die Sozialversicherungsnummer, Steueraufzeichnungen, Rechnungen, etc. Während Paperless die Originaldateien über das Konsumskript verschlüsselt, sind die OCR-Texte *nicht* verschlüsselt und demnach in Klartext gespeichert (es muss durchsuchbar sein, also wenn jemand eine Idee hat, wie man das mit verschlüsselten Daten tun kann: Ich bin ganz Ohr). Das bedeutet, dass Paperless niemals auf einem nicht vertrauten Host laufen sollte. Stattdessen empfehle ich, wenn du es verwenden willst, es lokal auf einem Server in deinem Zuhause laufen zu lassen.
|
||||
|
||||
|
||||
## Spenden
|
||||
|
||||
Wie mit aller Freier Software, liegt die Macht weniger in den Finanzen als mehr in den gemeinsamen Bemühungen. Ich schätze wirklich jeden Pull Request und Bugreport, der von Benutzern von Paperless getätigt wird, also bitte macht damit weiter. Wenn du jedoch nicht einer für Programmieren/Design/Dokumentation bist und mich wirklich finanziell unterstützen willst, sage ich nicht nein dazu ;-)
|
||||
|
||||
Das Ding ist, mir geht es finanziell OK, also würde ich dich darum bitten, an den [Hochkommissar der Vereinten Nationen für Flüchtlinge](https://donate.unhcr.org/int-en/general) zu spenden. Diese machen wichtige Arbeit und brauchen das Geld viel dringender als ich.
|
||||
81
README-el.md
Normal file
81
README-el.md
Normal file
@@ -0,0 +1,81 @@
|
||||
*[English](README.md)*<br/>
|
||||
*[German](README-de.md)*
|
||||
|
||||
# Paperless
|
||||
|
||||
[](https://paperless.readthedocs.org/) [](https://gitter.im/danielquinn/paperless) [](https://travis-ci.org/danielquinn/paperless) [](https://coveralls.io/github/danielquinn/paperless?branch=master) [](https://github.com/danielquinn/paperless/blob/master/THANKS.md)
|
||||
|
||||
Ευρετήριο και αρχείο για όλα σας τα σκαναρισμένα έγγραφα
|
||||
|
||||
Μισώ το χαρτί. Πέρα από τα περιβαλλοντικά ζητήματα, είναι ο εφιάλτης ενός τεχνικού.
|
||||
|
||||
* Δεν υπάρχει η δυνατότητα της αναζήτησης
|
||||
* Πιάνουν πολύ χώρο
|
||||
* Τα αντίγραφα ασφαλείας σημάινουν περισσότερο χαρτί
|
||||
|
||||
Τους τελευταίους μήνες μου έχει τύχει αρκετές φορές να μην μπορώ να βρω το σωστό έγγραφο. Κάποιες φορές ανακύκλωνα το έγγραφο που χρειαζόμουν (ποιος κρατάει τους λογαριασμούς του νερού για 2 χρόνια;;;) και κάποιες φορές απλά το έχανα ... επειδή έτσι είναι τα χαρτιά. Το έκανα αυτό για να κάνω την ζωή μου πιο εύκολη
|
||||
|
||||
|
||||
## Πως δουλεύει
|
||||
|
||||
Η εφαρμογή Paperless δεν ελέγχει το scanner σας, αλλά σας βοηθάει με τα αποτελέσματα του scanner σας.
|
||||
|
||||
1. Αγοράστε ένα scanner με πρόσβαση στο δίκτυο σας. Αν χρειάζεστε έμπνευση, δείτε την σελίδα με τα [προτεινόμενα scanner](https://paperless.readthedocs.io/en/latest/scanners.html).
|
||||
2. Κάντε την ρύθμιση "scan to FTP" ή κάτι παρόμοιο. Θα μπορεί να αποθηκεύει τις σκαναρισμένες εικόνες σε έναν server χωρίς να χρειάζεται να κάνετε κάτι. Φυσικά άμα το scanner σας δεν μπορεί να αποθηκεύσει κάπου τις εικόνες σας αυτόματα μπορείτε να το κάνετε χειροκίνητα. Το Paperless δεν ενδιαφέρεται πως καταλήγουν κάπου τα αρχεία.
|
||||
3. Να έχετε τον server που τρέχει το OCR script του Paperless να έχει ευρετήριο στην τοπική βάση δεδομένων.
|
||||
4. Χρησιμοποιήστε το web frontend για να επιλέξετε βάση δεδομένων και να βρείτε αυτό που θέλετε.
|
||||
5. Κατεβάστε το PDF που θέλετε/χρειάζεστε μέσω του web interface και κάντε ότι θέλετε με αυτό. Μπορείτε ακόμη να το εκτυπώσετε και να το στείλετε, σαν να ήταν το αρχικό. Στις περισσότερες περιπτώσεις κανείς δεν θα το προσέξει ή θα νοιαστεί.
|
||||
|
||||
Αυτό είναι που θα πάρετε:
|
||||
|
||||

|
||||
|
||||
|
||||
## Documentation
|
||||
|
||||
Είναι όλα διαθέσιμα εδώ [ReadTheDocs](https://paperless.readthedocs.org/).
|
||||
|
||||
|
||||
## Απαιτήσεις
|
||||
|
||||
Όλα αυτά είναι πολύ απλά, και φιλικά προς τον χρήστη, μια συλλογή με πολύτιμα εργαλεία.
|
||||
|
||||
* [ImageMagick](http://imagemagick.org/) μετατρέπει τις εικόνες σε έγχρωμες και ασπρόμαυρες.
|
||||
* [Tesseract](https://github.com/tesseract-ocr) κάνει την αναγνώρηση των χαρακτήρων.
|
||||
* [Unpaper](https://www.flameeyes.eu/projects/unpaper) despeckles and deskews the scanned image.
|
||||
* [GNU Privacy Guard](https://gnupg.org/) χρησιμοποιείται για κρυπτογράφηση στο backend.
|
||||
* [Python 3](https://python.org/) είναι η γλώσσα του project.
|
||||
* [Pillow](https://pypi.python.org/pypi/pillowfight/) Φορτώνει την εικόνα σαν αντικείμενο στην python και μπορεί να χρησιμοποιηθεί με PyOCR
|
||||
* [PyOCR](https://github.com/jflesch/pyocr) is a slick programmatic wrapper around tesseract.
|
||||
* [Django](https://www.djangoproject.com/) το framework με το οποίο έγινε το project.
|
||||
* [Python-GNUPG](http://pythonhosted.org/python-gnupg/) Αποκρυπτογραφεί τα PDF αρχεία στη στιγμή ώστε να κατεβάζετε αποκρυπτογραφημένα αρχεία, αφήνοντας τα κρυπτογραφημένα στον δίσκο.
|
||||
|
||||
|
||||
## Σταθερότητα
|
||||
|
||||
Αυτό το project υπάρχει από το 2015 και υπάρχουν αρκετοί άνθρωποι που το χρησιμοποιούν, παρόλα αυτά βρίσκεται σε διαρκή ανάπτυξη (απλά δείτε πότε commit έχουν γίνει στο git history) οπότε μην περιμένετε να είναι 100% σταθερό. Μπορείτε να κάνετε backup την βάση δεδομένων sqlite3, τον φάκελο media και το configuration αρχείο σας ώστε να είστε ασφαλείς.
|
||||
|
||||
|
||||
## Affiliated Projects
|
||||
|
||||
Το Paperless υπάρχει εδώ και κάποιο καιρό και άνθρωποι έχουν αρχίσει να φτιάχνουν πράγματα γύρω από αυτό. Αν είσαι ένας από αυτούς τους ανθρώπους, μπορούμε να βάλουμε το project σου σε αυτήν την λίστα:
|
||||
|
||||
* [Paperless Desktop](https://github.com/thomasbrueggemann/paperless-desktop): Μια desktop εφαρμογή για εγκατάσταση του Paperless. Τρέχει σε Mac, Linux, και Windows.
|
||||
* [ansible-role-paperless](https://github.com/ovv/ansible-role-paperless): Ένας εύκολο τρόπος για να τρέχει το Paperless μέσω Ansible.
|
||||
|
||||
|
||||
## Παρόμοια Projects
|
||||
|
||||
Υπάρχει ένα άλλο ṕroject που λέγεται [Mayan EDMS](https://mayan.readthedocs.org/en/latest/) το οποίο έχει παρόμοια τεχνικά χαρακτηριστικά με το Paperless σε εντυπωσιακό βαθμό. Επίσης βασισμένο στο Django και χρησιμοποιώντας το consumer model με Tesseract και Unpaper, Mayan EDMS έχει *πολλά* περισσότερα χαρακτηριστικά και έρχεται με ένα επιδέξιο UI, αλλά είναι ακόμα σε Python 2. Μπορεί να είναι ότι το Paperless καταναλώνει λιγότερους πόρους, αλλά για να είμαι ειλικρινής, αυτό είναι μια εικασία την οποία δεν έχω επιβεβαιώσει μόνος μου. Ένα πράγμα είναι σίγουρο, το *Paperless* έχει **πολύ** καλύτερο όνομα.
|
||||
|
||||
|
||||
## Σημαντική Σημείωση
|
||||
|
||||
Τα scanner για αρχεία συνήθως χρησιμοποιούνται για ευαίσθητα αρχεία. Πράγματα όπως το ΑΜΚΑ, φορολογικά αρχεία, τιμολόγια κτλπ. Παρόλο που το Paperless κρυπτογραφεί τα αρχικά αρχεία μέσω του consumption script, το κείμενο OCR *δεν είναι* κρυπτογραφημένο και για αυτό αποθηκεύεται (πρέπει να είναι αναζητήσιμο, οπότε αν κάποιος ξέρει να το κάνει αυτό με κρυπτογραφημένα δεδομένα είμαι όλος αυτιά). Αυτό σημάνει ότι το Paperless δεν πρέπει ποτέ να τρέχει σε μη αξιόπιστο πάροχο. Για αυτό συστήνω αν θέλετε να το τρέξετε να το τρέξετε σε έναν τοπικό server σπίτι σας.
|
||||
|
||||
|
||||
## Δωρεές
|
||||
|
||||
Όπως με όλα τα δωρεάν λογισμικά, η δύναμη δεν βρίσκεται στα οικονομικά αλλά στην συλλογική προσπάθεια. Αλήθεια εκτιμώ κάθε pull request και bug report που προσφέρεται από τους χρήστες του Paperless, οπότε σας παρακαλώ συνεχίστε. Αν παρόλα αυτά, δεν μπορείτε να γράψετε κώδικα/να κάνέτε design/να γράψετε documentation, και θέλετε να συνεισφέρετε οικονομικά, δεν θα πω όχι ;-)
|
||||
|
||||
Το θέμα είναι ότι είμαι οικονομικά εντάξει, οπότε θα σας ζητήσω να δωρίσετε τα χρήματα σας εδώ [United Nations High Commissioner for Refugees](https://donate.unhcr.org/int-en/general). Κάνουν σημαντική δουλειά και χρειάζονται τα χρήματα πολύ περισσότερο από ότι εγώ.
|
||||
83
README.md
Normal file
83
README.md
Normal file
@@ -0,0 +1,83 @@
|
||||
*[German](README-de.md)*<br/>
|
||||
*[Greek](README-el.md)*
|
||||
|
||||
# Paperless
|
||||
|
||||
[](https://paperless.readthedocs.org/) [](https://gitter.im/danielquinn/paperless) [](https://travis-ci.org/danielquinn/paperless) [](https://coveralls.io/github/danielquinn/paperless?branch=master) [](https://github.com/danielquinn/paperless/blob/master/THANKS.md)
|
||||
|
||||
Index and archive all of your scanned paper documents
|
||||
|
||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||
|
||||
* There's no search feature
|
||||
* It takes up physical space
|
||||
* Backups mean more paper
|
||||
|
||||
In the past few months I've been bitten more than a few times by the problem of not having the right document around. Sometimes I recycled a document I needed (who keeps water bills for two years?) and other times I just lost it... because paper. I wrote this to make my life easier.
|
||||
|
||||
|
||||
## How it Works
|
||||
|
||||
Paperless does not control your scanner, it only helps you deal with what your scanner produces
|
||||
|
||||
1. Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the [scanner recommendations](https://paperless.readthedocs.io/en/latest/scanners.html) page.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push scanned images to a server without you having to do anything. Of course if your scanner doesn't know how to automatically upload the file somewhere, you can always do that manually. Paperless doesn't care how the documents get into its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the file and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
5. Download the PDF you need/want via the web interface and do whatever you like with it. You can even print it and send it as if it's the original. In most cases, no one will care or notice.
|
||||
|
||||
Here's what you get:
|
||||
|
||||

|
||||
|
||||
|
||||
## Documentation
|
||||
|
||||
It's all available on [ReadTheDocs](https://paperless.readthedocs.org/).
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
This is all really a quite simple, shiny, user-friendly wrapper around some very powerful tools.
|
||||
|
||||
* [ImageMagick](http://imagemagick.org/) converts the images between colour and greyscale.
|
||||
* [Tesseract](https://github.com/tesseract-ocr) does the character recognition.
|
||||
* [Unpaper](https://www.flameeyes.eu/projects/unpaper) despeckles and deskews the scanned image.
|
||||
* [GNU Privacy Guard](https://gnupg.org/) is used as the encryption backend.
|
||||
* [Python 3](https://python.org/) is the language of the project.
|
||||
* [Pillow](https://pypi.python.org/pypi/pillowfight/) loads the image data as a python object to be used with PyOCR.
|
||||
* [PyOCR](https://github.com/jflesch/pyocr) is a slick programmatic wrapper around tesseract.
|
||||
* [Django](https://www.djangoproject.com/) is the framework this project is written against.
|
||||
* [Python-GNUPG](http://pythonhosted.org/python-gnupg/) decrypts the PDFs on-the-fly to allow you to download unencrypted files, leaving the encrypted ones on-disk.
|
||||
|
||||
|
||||
## Project Status
|
||||
|
||||
This project has been around since 2015, and there's lots of people using it. For some reason, it's really popular in Germany -- maybe someone over there can clue me in as to why?
|
||||
|
||||
I am no longer doing new development on Paperless as it does exactly what I need it to and have since turned my attention to my latest project, [Aletheia](https://github.com/danielquinn/aletheia). However, I'm not abandoning this project. I am happy to field pull requests and answer questions in the issue queue. If you're a developer yourself and want a new feature, float it in the issue queue and/or send me a pull request! I'm happy to add new stuff, but I just don't have the time to do that work myself.
|
||||
|
||||
|
||||
## Affiliated Projects
|
||||
|
||||
Paperless has been around a while now, and people are starting to build stuff on top of it. If you're one of those people, we can add your project to this list:
|
||||
|
||||
* [Paperless Desktop](https://github.com/thomasbrueggemann/paperless-desktop): A desktop UI for your Paperless installation. Runs on Mac, Linux, and Windows.
|
||||
* [ansible-role-paperless](https://github.com/ovv/ansible-role-paperless): An easy way to get Paperless running via Ansible.
|
||||
|
||||
|
||||
## Similar Projects
|
||||
|
||||
There's another project out there called [Mayan EDMS](https://mayan.readthedocs.org/en/latest/) that has a surprising amount of technical overlap with Paperless. Also based on Django and using a consumer model with Tesseract and Unpaper, Mayan EDMS is *much* more featureful and comes with a slick UI as well, but still in Python 2. It may be that Paperless consumes fewer resources, but to be honest, this is just a guess as I haven't tested this myself. One thing's for certain though, *Paperless* is a **way** better name.
|
||||
|
||||
|
||||
## Important Note
|
||||
|
||||
Document scanners are typically used to scan sensitive documents. Things like your social insurance number, tax records, invoices, etc. While Paperless encrypts the original files via the consumption script, the OCR'd text is *not* encrypted and is therefore stored in the clear (it needs to be searchable, so if someone has ideas on how to do that on encrypted data, I'm all ears). This means that Paperless should never be run on an untrusted host. Instead, I recommend that if you do want to use it, run it locally on a server in your own home.
|
||||
|
||||
|
||||
## Donations
|
||||
|
||||
As with all Free software, the power is less in the finances and more in the collective efforts. I really appreciate every pull request and bug report offered up by Paperless' users, so please keep that stuff coming. If however, you're not one for coding/design/documentation, and would like to contribute financially, I won't say no ;-)
|
||||
|
||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to the [United Nations High Commissioner for Refugees](https://donate.unhcr.org/int-en/general). They're doing important work and they need the money a lot more than I do.
|
||||
140
README.rst
140
README.rst
@@ -1,140 +0,0 @@
|
||||
Paperless
|
||||
#########
|
||||
|
||||
|Documentation|
|
||||
|Chat|
|
||||
|Travis|
|
||||
|Dependencies|
|
||||
|
||||
Scan, index, and archive all of your paper documents
|
||||
|
||||
I hate paper. Environmental issues aside, it's a tech person's nightmare:
|
||||
|
||||
* There's no search feature
|
||||
* It takes up physical space
|
||||
* Backups mean more paper
|
||||
|
||||
In the past few months I've been bitten more than a few times by the problem
|
||||
of not having the right document around. Sometimes I recycled a document I
|
||||
needed (who keeps water bills for two years?) and other times I just lost
|
||||
it... because paper. I wrote this to make my life easier.
|
||||
|
||||
|
||||
How it Works
|
||||
============
|
||||
|
||||
1. Buy a document scanner like `this one`_.
|
||||
2. Set it up to "scan to FTP" or something similar. It should be able to push
|
||||
scanned images to a server without you having to do anything. If your
|
||||
scanner doesn't know how to automatically upload the file somewhere, you can
|
||||
always do that manually. Paperless doesn't care how the documents get into
|
||||
its local consumption directory.
|
||||
3. Have the target server run the Paperless consumption script to OCR the PDF
|
||||
and index it into a local database.
|
||||
4. Use the web frontend to sift through the database and find what you want.
|
||||
5. Download the PDF you need/want via the web interface and do whatever you
|
||||
like with it. You can even print it and send it as if it's the original.
|
||||
In most cases, no one will care or notice.
|
||||
|
||||
Here's what you get:
|
||||
|
||||
.. image:: docs/_static/screenshot.png
|
||||
:alt: The before and after
|
||||
:target: docs/_static/screenshot.png
|
||||
|
||||
|
||||
Stability
|
||||
=========
|
||||
|
||||
Paperless is still under active development (just look at the git commit
|
||||
history) so don't expect it to be 100% stable. I'm using it for my own
|
||||
documents, but I'm crazy like that. If you use this and it breaks something,
|
||||
you get to keep all the shiny pieces.
|
||||
|
||||
|
||||
Requirements
|
||||
============
|
||||
|
||||
This is all really a quite simple, shiny, user-friendly wrapper around some very
|
||||
powerful tools.
|
||||
|
||||
* `ImageMagick`_ converts the images between colour and greyscale.
|
||||
* `Tesseract`_ does the character recognition.
|
||||
* `Unpaper`_ despeckles and deskews the scanned image.
|
||||
* `GNU Privacy Guard`_ is used as the encryption backend.
|
||||
* `Python 3`_ is the language of the project.
|
||||
|
||||
* `Pillow`_ loads the image data as a python object to be used with PyOCR.
|
||||
* `PyOCR`_ is a slick programmatic wrapper around tesseract.
|
||||
* `Django`_ is the framework this project is written against.
|
||||
* `Python-GNUPG`_ decrypts the PDFs on-the-fly to allow you to download
|
||||
unencrypted files, leaving the encrypted ones on-disk.
|
||||
|
||||
|
||||
Documentation
|
||||
=============
|
||||
|
||||
It's all available on `ReadTheDocs`_.
|
||||
|
||||
|
||||
Similar Projects
|
||||
================
|
||||
|
||||
There's another project out there called `Mayan EDMS`_ that has a surprising
|
||||
amount of technical overlap with Paperless. Also based on Django and using
|
||||
a consumer model with Tesseract and unpaper, Mayan EDMS is *much* more
|
||||
featureful and comes with a slick UI as well. It may be that Paperless is
|
||||
better suited for low-resource environments (like a Rasberry Pi), but to be
|
||||
honest, this is just a guess as I haven't tested this myself. One thing's
|
||||
for certain though, *Paperless* is a **much** better name.
|
||||
|
||||
|
||||
Important Note
|
||||
==============
|
||||
|
||||
Document scanners are typically used to scan sensitive documents. Things like
|
||||
your social insurance number, tax records, invoices, etc. While paperless
|
||||
encrypts the original PDFs via the consumption script, the OCR'd text is *not*
|
||||
encrypted and is therefore stored in the clear (it needs to be searchable, so
|
||||
if someone has ideas on how to do that on encrypted data, I'm all ears). This
|
||||
means that paperless should never be run on an untrusted host. Instead, I
|
||||
recommend that if you do want to use it, run it locally on a server in your own
|
||||
home.
|
||||
|
||||
|
||||
Donations
|
||||
=========
|
||||
|
||||
As with all Free software, the power is less in the finances and more in the
|
||||
collective efforts. I really appreciate every pull request and bug report
|
||||
offered up by Paperless' users, so please keep that stuff coming. If however,
|
||||
you're not one for coding/design/documentation, and would like to contribute
|
||||
financially, I won't say no ;-)
|
||||
|
||||
The thing is, I'm doing ok for money, so I would instead ask you to donate to
|
||||
the `United Nations High Commissioner for Refugees`_. They're doing important
|
||||
work and they need the money a lot more than I do.
|
||||
|
||||
.. _this one: http://www.brother.ca/en-CA/Scanners/11/ProductDetail/ADS1500W?ProductDetail=productdetail
|
||||
.. _ImageMagick: http://imagemagick.org/
|
||||
.. _Tesseract: https://github.com/tesseract-ocr
|
||||
.. _Unpaper: https://www.flameeyes.eu/projects/unpaper
|
||||
.. _GNU Privacy Guard: https://gnupg.org/
|
||||
.. _Python 3: https://python.org/
|
||||
.. _Pillow: https://pypi.python.org/pypi/pillowfight/
|
||||
.. _PyOCR: https://github.com/jflesch/pyocr
|
||||
.. _Django: https://www.djangoproject.com/
|
||||
.. _Python-GNUPG: http://pythonhosted.org/python-gnupg/
|
||||
.. _ReadTheDocs: https://paperless.readthedocs.org/
|
||||
.. _Mayan EDMS: https://mayan.readthedocs.org/en/latest/
|
||||
.. _United Nations High Commissioner for Refugees: https://donate.unhcr.org/int-en/general
|
||||
.. |Documentation| image:: https://readthedocs.org/projects/paperless/badge/?version=latest
|
||||
:alt: Read the documentation at https://paperless.readthedocs.org/
|
||||
:target: https://paperless.readthedocs.org/
|
||||
.. |Chat| image:: https://badges.gitter.im/danielquinn/paperless.svg
|
||||
:alt: Join the chat at https://gitter.im/danielquinn/paperless
|
||||
:target: https://gitter.im/danielquinn/paperless?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge
|
||||
.. |Travis| image:: https://travis-ci.org/danielquinn/paperless.svg?branch=master
|
||||
:target: https://travis-ci.org/danielquinn/paperless
|
||||
.. |Dependencies| image:: https://www.versioneye.com/user/projects/57b33b81d9f1b00016faa500/badge.svg?style=flat-square
|
||||
:target: https://www.versioneye.com/user/projects/57b33b81d9f1b00016faa500
|
||||
19
THANKS.md
Normal file
19
THANKS.md
Normal file
@@ -0,0 +1,19 @@
|
||||
# Thanks for using Paperless!
|
||||
|
||||
Working on this project has been exhausting, but rewarding at the same time.
|
||||
It's just wonderful that so many people are using this thing, and in so many
|
||||
crazy ways.
|
||||
|
||||
This file is here for everyone to post their own stories about how you use this
|
||||
code. It helps me to understand who's using it and why, and maybe to give
|
||||
others an idea of how it might be used. It's based on a Twitter exchange
|
||||
between [John Glanville](https://twitter.com/hexapodium) and
|
||||
[Julia Evans](https://github.com/jvns) and later better defined [here](https://github.com/paulmolluzzo/thanks-md).
|
||||
|
||||
To contribute, simply issue a pull request that appends to this file something
|
||||
like this:
|
||||
|
||||
```
|
||||
### Your Name
|
||||
Some friendly message
|
||||
```
|
||||
5
Vagrantfile
vendored
5
Vagrantfile
vendored
@@ -12,4 +12,9 @@ Vagrant.configure(VAGRANT_API_VERSION) do |config|
|
||||
|
||||
# Networking details
|
||||
config.vm.network "private_network", ip: "172.28.128.4"
|
||||
|
||||
config.vm.provider "virtualbox" do |vb|
|
||||
# Customize the amount of memory on the VM:
|
||||
vb.memory = "1024"
|
||||
end
|
||||
end
|
||||
|
||||
@@ -1,13 +1,20 @@
|
||||
# Environment variables to set for Paperless
|
||||
# Commented out variables will be replaced by a default within Paperless.
|
||||
# Commented out variables will be replaced with a default within Paperless.
|
||||
#
|
||||
# In addition to what you see here, you can also define any values you find in
|
||||
# paperless.conf.example here. Values like:
|
||||
#
|
||||
# * PAPERLESS_PASSPHRASE
|
||||
# * PAPERLESS_CONSUMPTION_DIR
|
||||
# * PAPERLESS_CONSUME_MAIL_HOST
|
||||
#
|
||||
# ...are all explained in that file but can be defined here, since the Docker
|
||||
# installation doesn't make use of paperless.conf.
|
||||
|
||||
# Passphrase Paperless uses to encrypt and decrypt your documents
|
||||
PAPERLESS_PASSPHRASE=CHANGE_ME
|
||||
|
||||
# The amount of threads to use for text recognition
|
||||
# PAPERLESS_OCR_THREADS=4
|
||||
|
||||
# Additional languages to install for text recognition
|
||||
# Additional languages to install for text recognition. Note that this is
|
||||
# different from PAPERLESS_OCR_LANGUAGE (default=eng), which defines the
|
||||
# default language used when guessing the language from the OCR output.
|
||||
# PAPERLESS_OCR_LANGUAGES=deu ita
|
||||
|
||||
# You can change the default user and group id to a custom one
|
||||
|
||||
@@ -1,12 +1,19 @@
|
||||
version: '2'
|
||||
version: '2.1'
|
||||
|
||||
services:
|
||||
webserver:
|
||||
image: pitkley/paperless
|
||||
build: ./
|
||||
# uncomment the following line to start automatically on system boot
|
||||
# restart: always
|
||||
ports:
|
||||
# You can adapt the port you want Paperless to listen on by
|
||||
# modifying the part before the `:`.
|
||||
- "8000:8000"
|
||||
healthcheck:
|
||||
test: ["CMD", "curl" , "-f", "http://localhost:8000"]
|
||||
interval: 30s
|
||||
timeout: 10s
|
||||
retries: 5
|
||||
volumes:
|
||||
- data:/usr/src/paperless/data
|
||||
- media:/usr/src/paperless/media
|
||||
@@ -17,16 +24,21 @@ services:
|
||||
# value with nothing.
|
||||
environment:
|
||||
- PAPERLESS_OCR_LANGUAGES=
|
||||
command: ["runserver", "0.0.0.0:8000"]
|
||||
command: ["runserver", "--insecure", "--noreload", "0.0.0.0:8000"]
|
||||
|
||||
consumer:
|
||||
image: pitkley/paperless
|
||||
build: ./
|
||||
# uncomment the following line to start automatically on system boot
|
||||
# restart: always
|
||||
depends_on:
|
||||
webserver:
|
||||
condition: service_healthy
|
||||
volumes:
|
||||
- data:/usr/src/paperless/data
|
||||
- media:/usr/src/paperless/media
|
||||
# You have to adapt the local path you want the consumption
|
||||
# directory to mount to by modifying the part before the ':'.
|
||||
- /path/to/arbitrary/place:/consume
|
||||
- ./consume:/consume
|
||||
# Likewise, you can add a local path to mount a directory for
|
||||
# exporting. This is not strictly needed for paperless to
|
||||
# function, only if you're exporting your files: uncomment
|
||||
|
||||
@@ -1,152 +1,517 @@
|
||||
Changelog
|
||||
#########
|
||||
|
||||
* 0.3.5
|
||||
* A serious facelift for the documents listing page wherein we drop the
|
||||
tabular layout in favour of a tiled interface.
|
||||
* Users can now configure the number of items per page.
|
||||
* Fix for `#171`_: Allow users to specify their own ``SECRET_KEY`` value.
|
||||
* Moved the dotenv loading to the top of settings.py
|
||||
* Fix for `#112`_: Added checks for binaries required for document
|
||||
consumption.
|
||||
2.5.0
|
||||
=====
|
||||
|
||||
* 0.3.4
|
||||
* Removal of django-suit due to a licensing conflict I bumped into in 0.3.3.
|
||||
Note that you *can* use Django Suit with Paperless, but only in a
|
||||
non-profit situation as their free license prohibits for-profit use. As a
|
||||
result, I can't bundle Suit with Paperless without conflicting with the
|
||||
GPL. Further development will be done against the stock Django admin.
|
||||
* I shrunk the thumbnails a little 'cause they were too big for me, even on
|
||||
my high-DPI monitor.
|
||||
* BasicAuth support for document and thumbnail downloads, as well as the Push
|
||||
API thanks to @thomasbrueggemann. See `#179`_.
|
||||
* **New dependency**: Paperless now optimises thumbnail generation with
|
||||
`optipng`_, so you'll need to install that somewhere in your PATH or declare
|
||||
its location in ``PAPERLESS_OPTIPNG_BINARY``. The Docker image has already
|
||||
been updated on the Docker Hub, so you just need to pull the latest one from
|
||||
there if you're a Docker user.
|
||||
|
||||
* 0.3.3
|
||||
* Thumbnails in the UI and a Django-suit -based face-lift courtesy of @ekw!
|
||||
* Timezone, items per page, and default language are now all configurable,
|
||||
also thanks to @ekw.
|
||||
* "Login free" instances of Paperless were breaking whenever you tried to edit
|
||||
objects in the admin: adding/deleting tags or correspondents, or even fixing
|
||||
spelling. This was due to the "user hack" we were applying to sessions that
|
||||
weren't using a login, as that hack user didn't have a valid id. The fix was
|
||||
to attribute the first user id in the system to this hack user. `#394`_
|
||||
|
||||
* 0.3.2
|
||||
* Fix for `#172`_: defaulting ALLOWED_HOSTS to ``["*"]`` and allowing the
|
||||
user to set her own value via ``PAPERLESS_ALLOWED_HOSTS`` should the need
|
||||
arise.
|
||||
* A problem in how we handle slug values on Tags and Correspondents required a
|
||||
few changes to how we handle this field `#393`_:
|
||||
|
||||
* 0.3.1
|
||||
* Added a default value for ``CONVERT_BINARY``
|
||||
1. Slugs are no longer editable. They're derived from the name of the tag or
|
||||
correspondent at save time, so if you wanna change the slug, you have to
|
||||
change the name, and even then you're restricted to the rules of the
|
||||
``slugify()`` function. The slug value is still visible in the admin
|
||||
though.
|
||||
2. I've added a migration to go over all existing tags & correspondents and
|
||||
rewrite the ``.slug`` values to ones conforming to the ``slugify()``
|
||||
rules.
|
||||
3. The consumption process now uses the same rules as ``.save()`` in
|
||||
determining a slug and using that to check for an existing
|
||||
tag/correspondent.
|
||||
|
||||
* 0.3.0
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
* Consumer loop time is now configurable for systems with slow writes. Just
|
||||
set ``PAPERLESS_CONSUMER_LOOP_TIME`` to a number of seconds. The default
|
||||
is 10.
|
||||
* As per `#44`_, we've removed support for ``PAPERLESS_CONVERT``,
|
||||
``PAPERLESS_CONSUME``, and ``PAPERLESS_SECRET``. Please use
|
||||
``PAPERLESS_CONVERT_BINARY``, ``PAPERLESS_CONSUMPTION_DIR``, and
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
* An annoying bug in the date capture code was causing some bogus dates to be
|
||||
attached to documents, which in turn busted the UI. Thanks to `Andrew Peng`_
|
||||
for reporting this. `#414`_.
|
||||
|
||||
* 0.2.0
|
||||
* A bug in the Dockerfile meant that Tesseract language files weren't being
|
||||
installed correctly. `euri10`_ was quick to provide a fix: `#406`_, `#413`_.
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#148`_: The database location (sqlite) is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#146`_: Fixed a bug that allowed unauthorised access to the ``/fetch``
|
||||
URL.
|
||||
* `#131`_: Document files are now automatically removed from disk when
|
||||
they're deleted in Paperless.
|
||||
* `#121`_: Fixed a bug where Paperless wasn't setting document creation time
|
||||
based on the file naming scheme.
|
||||
* `#81`_: Added a hook to run an arbitrary script after every document is
|
||||
consumed.
|
||||
* `#98`_: Added optional environment variables for ImageMagick so that it
|
||||
doesn't explode when handling Very Large Documents or when it's just
|
||||
running on a low-memory system. Thanks to `Florian Harr`_ for his help on
|
||||
this one.
|
||||
* `#89`_ Ported the auto-tagging code to correspondents as well. Thanks to
|
||||
`Justin Snyman`_ for the pointers in the issue queue.
|
||||
* Added support for guessing the date from the file name along with the
|
||||
correspondent, title, and tags. Thanks to `Tikitu de Jager`_ for his pull
|
||||
request that I took forever to merge and to `Pit`_ for his efforts on the
|
||||
regex front.
|
||||
* `#94`_: Restored support for changing the created date in the UI. Thanks
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
* Document consumption is now wrapped in a transaction as per an old ticket
|
||||
`#262`_.
|
||||
|
||||
* 0.1.1
|
||||
* The ``get_date()`` functionality of the parsers has been consolidated onto
|
||||
the ``DocumentParser`` class since much of that code was redundant anyway.
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
property (one could quite reasonably scan a document before sending it to
|
||||
someone.)
|
||||
* `#67`_: Rewrote the document exporter and added a new importer that allows
|
||||
for full metadata retention without depending on the file name and
|
||||
modification time. A big thanks to `Tikitu de Jager`_, `Pit`_,
|
||||
`Florian Jung`_, and `Christopher Luu`_ for their code snippets and
|
||||
contributing conversation that lead to this change.
|
||||
* `#20`_: Added *unpaper* support to help in cleaning up the scanned image
|
||||
before it's OCR'd. Thanks to `Pit`_ for this one.
|
||||
* `#71`_ Added (encrypted) thumbnails in anticipation of a proper UI.
|
||||
* `#68`_: Added support for using a proper config file at
|
||||
``/etc/paperless.conf`` and modified the systemd unit files to use it.
|
||||
* Refactored the Vagrant installation process to use environment variables
|
||||
rather than asking the user to modify ``settings.py``.
|
||||
* `#44`_: Harmonise environment variable names with constant names.
|
||||
* `#60`_: Setup logging to actually use the Python native logging framework.
|
||||
* `#53`_: Fixed an annoying bug that caused ``.jpeg`` and ``.JPG`` images
|
||||
to be imported but made unavailable.
|
||||
2.4.0
|
||||
=====
|
||||
|
||||
* 0.1.0
|
||||
* A new set of actions are now available thanks to `jonaswinkler`_'s very first
|
||||
pull request! You can now do nifty things like tag documents in bulk, or set
|
||||
correspondents in bulk. `#405`_
|
||||
* The import/export system is now a little smarter. By default, documents are
|
||||
tagged as ``unencrypted``, since exports are by their nature unencrypted.
|
||||
It's now in the import step that we decide the storage type. This allows you
|
||||
to export from an encrypted system and import into an unencrypted one, or
|
||||
vice-versa.
|
||||
* The migration history has been slightly modified to accomodate PostgreSQL
|
||||
users. Additionally, you can now tell paperless to use PostgreSQL simply by
|
||||
declaring ``PAPERLESS_DBUSER`` in your environment. This will attempt to
|
||||
connect to your Postgres database without a password unless you also set
|
||||
``PAPERLESS_DBPASS``.
|
||||
* A bug was found in the REST API filter system that was the result of an
|
||||
update of django-filter some time ago. This has now been patched `#412`_.
|
||||
Thanks to `thepill`_ for spotting it!
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
who spearheadded this effort.
|
||||
* A simple REST API is in place, but it should be considered unstable.
|
||||
* Cleaned up the consumer to use temporary directories instead of a single
|
||||
scratch space. (Thanks `Pit`_)
|
||||
* Improved the efficiency of the consumer by parsing pages more intelligently
|
||||
and introducing a threaded OCR process (thanks again `Pit`_).
|
||||
* `#45`_: Cleaned up the logic for tag matching. Reported by `darkmatter`_.
|
||||
* `#47`_: Auto-rotate landscape documents. Reported by `Paul`_ and fixed by
|
||||
`Pit`_.
|
||||
* `#48`_: Matching algorithms should do so on a word boundary (`darkmatter`_)
|
||||
* `#54`_: Documented the re-tagger (`zedster`_)
|
||||
* `#57`_: Make sure file is preserved on import failure (`darkmatter`_)
|
||||
* Added tox with pep8 checking
|
||||
|
||||
* 0.0.6
|
||||
2.3.0
|
||||
=====
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
* Support for consuming plain text & markdown documents was added by
|
||||
`Joshua Taillon`_! This was a long-requested feature, and it's addition is
|
||||
likely to be greatly appreciated by the community: `#395`_ Thanks also to
|
||||
`David Martin`_ for his assistance on the issue.
|
||||
* `dubit0`_ found & fixed a bug that prevented management commands from running
|
||||
before we had an operational database: `#396`_
|
||||
* Joshua also added a simple update to the thumbnail generation process to
|
||||
improve performance: `#399`_
|
||||
* As his last bit of effort on this release, Joshua also added some code to
|
||||
allow you to view the documents inline rather than download them as an
|
||||
attachment. `#400`_
|
||||
* Finally, `ahyear`_ found a slip in the Docker documentation and patched it.
|
||||
`#401`_
|
||||
|
||||
* 0.0.5
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
* Added IMAP mail support
|
||||
* Added a re-tagging utility
|
||||
* Documentation for the above as well as data migration
|
||||
2.2.1
|
||||
=====
|
||||
|
||||
* 0.0.4
|
||||
* `Kyle Lucy`_ reported a bug quickly after the release of 2.2.0 where we broke
|
||||
the ``DISABLE_LOGIN`` feature: `#392`_.
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
* Removed ``User`` and ``Group`` from the admin
|
||||
* Added ``pytz`` to the list of requirements
|
||||
|
||||
* 0.0.3
|
||||
2.2.0
|
||||
=====
|
||||
|
||||
* Added basic tagging
|
||||
* Thanks to `dadosch`_, `Wolfgang Mader`_, and `Tim Brooks`_ this is the first
|
||||
version of Paperless that supports Django 2.0! As a result of their hard
|
||||
work, you can now also run Paperless on Python 3.7 as well: `#386`_ &
|
||||
`#390`_.
|
||||
* `Stéphane Brunner`_ added a few lines of code that made tagging interface a
|
||||
lot easier on those of us with lots of different tags: `#391`_.
|
||||
* `Kilian Koeltzsch`_ noticed a bug in how we capture & automatically create
|
||||
tags, so that's fixed now too: `#384`_.
|
||||
* `erikarvstedt`_ tweaked the behaviour of the test suite to be better behaved
|
||||
for packaging environments: `#383`_.
|
||||
* `Lukasz Soluch`_ added CORS support to make building a new Javascript-based
|
||||
front-end cleaner & easier: `#387`_.
|
||||
|
||||
* 0.0.2
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
2.1.0
|
||||
=====
|
||||
|
||||
* 0.0.1
|
||||
* `Enno Lohmeier`_ added three simple features that make Paperless a lot more
|
||||
user (and developer) friendly:
|
||||
|
||||
* Initial release
|
||||
1. There's a new search box on the front page: `#374`_.
|
||||
2. The correspondents & tags pages now have a column showing the number of
|
||||
relevant documents: `#375`_.
|
||||
3. The Dockerfile has been tweaked to build faster for those of us who are
|
||||
doing active development on Paperless using the Docker environment:
|
||||
`#376`_.
|
||||
|
||||
* You now also have the ability to customise the interface to your heart's
|
||||
content by creating a file called ``overrides.css`` and/or ``overrides.js``
|
||||
in the root of your media directory. Thanks to `Mark McFate`_ for this
|
||||
idea: `#371`_
|
||||
|
||||
|
||||
2.0.0
|
||||
=====
|
||||
|
||||
This is a big release as we've changed a core-functionality of Paperless: we no
|
||||
longer encrypt files with GPG by default.
|
||||
|
||||
The reasons for this are many, but it boils down to that the encryption wasn't
|
||||
really all that useful, as files on-disk were still accessible so long as you
|
||||
had the key, and the key was most typically stored in the config file. In
|
||||
other words, your files are only as safe as the ``paperless`` user is. In
|
||||
addition to that, *the contents of the documents were never encrypted*, so
|
||||
important numbers etc. were always accessible simply by querying the database.
|
||||
Still, it was better than nothing, but the consensus from users appears to be
|
||||
that it was more an annoyance than anything else, so this feature is now turned
|
||||
off unless you explicitly set a passphrase in your config file.
|
||||
|
||||
Migrating from 1.x
|
||||
------------------
|
||||
|
||||
Encryption isn't gone, it's just off for new users. So long as you have
|
||||
``PAPERLESS_PASSPHRASE`` set in your config or your environment, Paperless
|
||||
should continue to operate as it always has. If however, you want to drop
|
||||
encryption too, you only need to do two things:
|
||||
|
||||
1. Run ``./manage.py migrate && ./manage.py change_storage_type gpg unencrypted``.
|
||||
This will go through your entire database and Decrypt All The Things.
|
||||
2. Remove ``PAPERLESS_PASSPHRASE`` from your ``paperless.conf`` file, or simply
|
||||
stop declaring it in your environment.
|
||||
|
||||
Special thanks to `erikarvstedt`_, `matthewmoto`_, and `mcronce`_ who did the
|
||||
bulk of the work on this big change.
|
||||
|
||||
1.4.0
|
||||
=====
|
||||
|
||||
* `Quentin Dawans`_ has refactored the document consumer to allow for some
|
||||
command-line options. Notably, you can now direct it to consume from a
|
||||
particular ``--directory``, limit the ``--loop-time``, set the time between
|
||||
mail server checks with ``--mail-delta`` or just run it as a one-off with
|
||||
``--one-shot``. See `#305`_ & `#313`_ for more information.
|
||||
* Refactor the use of travis/tox/pytest/coverage into two files:
|
||||
``.travis.yml`` and ``setup.cfg``.
|
||||
* Start generating requirements.txt from a Pipfile. I'll probably switch over
|
||||
to just using pipenv in the future.
|
||||
* All for a alternative FreeBSD-friendly location for ``paperless.conf``.
|
||||
Thanks to `Martin Arendtsen`_ who provided this (`#322`_).
|
||||
* Document consumption events are now logged in the Django admin events log.
|
||||
Thanks to `CkuT`_ for doing the legwork on this one and to `Quentin Dawans`_
|
||||
& `David Martin`_ for helping to coordinate & work out how the feature would
|
||||
be developed.
|
||||
* `erikarvstedt`_ contributed a pull request (`#328`_) to add ``--noreload``
|
||||
to the default server start process. This helps reduce the load imposed
|
||||
by the running webservice.
|
||||
* Through some discussion on `#253`_ and `#323`_, we've removed a few of the
|
||||
hardcoded URL values to make it easier for people to host Paperless on a
|
||||
subdirectory. Thanks to `Quentin Dawans`_ and `Kyle Lucy`_ for helping to
|
||||
work this out.
|
||||
* The clickable area for documents on the listing page has been increased to a
|
||||
more predictable space thanks to a glorious hack from `erikarvstedt`_ in
|
||||
`#344`_.
|
||||
* `Strubbl`_ noticed an annoying bug in the bash script wrapping the Docker
|
||||
entrypoint and fixed it with some very creating Bash skills: `#352`_.
|
||||
* You can now use the search field to find documents by tag thanks to
|
||||
`thinkjk`_'s *first ever issue*: `#354`_.
|
||||
* Inotify is now being used to detect additions to the consume directory thanks
|
||||
to some excellent work from `erikarvstedt`_ on `#351`_
|
||||
|
||||
1.3.0
|
||||
=====
|
||||
|
||||
* You can now run Paperless without a login, though you'll still have to create
|
||||
at least one user. This is thanks to a pull-request from `matthewmoto`_:
|
||||
`#295`_. Note that logins are still required by default, and that you need
|
||||
to disable them by setting ``PAPERLESS_DISABLE_LOGIN="true"`` in your
|
||||
environment or in ``/etc/paperless.conf``.
|
||||
* Fix for `#303`_ where sketchily-formatted documents could cause the consumer
|
||||
to break and insert half-records into the database breaking all sorts of
|
||||
things. We now capture the return codes of both ``convert`` and ``unpaper``
|
||||
and fail-out nicely.
|
||||
* Fix for additional date types thanks to input from `Isaac`_ and code from
|
||||
`BastianPoe`_ (`#301`_).
|
||||
* Fix for running migrations in the Docker container (`#299`_). Thanks to
|
||||
`Georgi Todorov`_ for the fix (`#300`_) and to `Pit`_ for the review.
|
||||
* Fix for Docker cases where the issuing user is not UID 1000. This was a
|
||||
collaborative fix between `Jeffrey Portman`_ and `Pit`_ in `#311`_ and
|
||||
`#312`_ to fix `#306`_.
|
||||
* Patch the historical migrations to support MySQL's um, *interesting* way of
|
||||
handing indexes (`#308`_). Thanks to `Simon Taddiken`_ for reporting the
|
||||
problem and helping me find where to fix it.
|
||||
|
||||
1.2.0
|
||||
=====
|
||||
|
||||
* New Docker image, now based on Alpine, thanks to the efforts of `addadi`_
|
||||
and `Pit`_. This new image is dramatically smaller than the Debian-based
|
||||
one, and it also has `a new home on Docker Hub`_. A proper thank-you to
|
||||
`Pit`_ for hosting the image on his Docker account all this time, but after
|
||||
some discussion, we decided the image needed a more *official-looking* home.
|
||||
* `BastianPoe`_ has added the long-awaited feature to automatically skip the
|
||||
OCR step when the PDF already contains text. This can be overridden by
|
||||
setting ``PAPERLESS_OCR_ALWAYS=YES`` either in your ``paperless.conf`` or
|
||||
in the environment. Note that this also means that Paperless now requires
|
||||
``libpoppler-cpp-dev`` to be installed. **Important**: You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update.
|
||||
* `BastianPoe`_ has also contributed a monumental amount of work (`#291`_) to
|
||||
solving `#158`_: setting the document creation date based on finding a date
|
||||
in the document text.
|
||||
|
||||
1.1.0
|
||||
=====
|
||||
|
||||
* Fix for `#283`_, a redirect bug which broke interactions with
|
||||
paperless-desktop. Thanks to `chris-aeviator`_ for reporting it.
|
||||
* Addition of an optional new financial year filter, courtesy of
|
||||
`David Martin`_ `#256`_
|
||||
* Fixed a typo in how thumbnails were named in exports `#285`_, courtesy of
|
||||
`Dan Panzarella`_
|
||||
|
||||
1.0.0
|
||||
=====
|
||||
|
||||
* Upgrade to Django 1.11. **You'll need to run
|
||||
``pip install -r requirements.txt`` after the usual ``git pull`` to
|
||||
properly update**.
|
||||
* Replace the templatetag-based hack we had for document listing in favour of
|
||||
a slightly less ugly solution in the form of another template tag with less
|
||||
copypasta.
|
||||
* Support for multi-word-matches for auto-tagging thanks to an excellent
|
||||
patch from `ishirav`_ `#277`_.
|
||||
* Fixed a CSS bug reported by `Stefan Hagen`_ that caused an overlapping of
|
||||
the text and checkboxes under some resolutions `#272`_.
|
||||
* Patched the Docker config to force the serving of static files. Credit for
|
||||
this one goes to `dev-rke`_ via `#248`_.
|
||||
* Fix file permissions during Docker start up thanks to `Pit`_ on `#268`_.
|
||||
* Date fields in the admin are now expressed as HTML5 date fields thanks to
|
||||
`Lukas Winkler`_'s issue `#278`_
|
||||
|
||||
0.8.0
|
||||
=====
|
||||
|
||||
* Paperless can now run in a subdirectory on a host (``/paperless``), rather
|
||||
than always running in the root (``/``) thanks to `maphy-psd`_'s work on
|
||||
`#255`_.
|
||||
|
||||
0.7.0
|
||||
=====
|
||||
|
||||
* **Potentially breaking change**: As per `#235`_, Paperless will no longer
|
||||
automatically delete documents attached to correspondents when those
|
||||
correspondents are themselves deleted. This was Django's default
|
||||
behaviour, but didn't make much sense in Paperless' case. Thanks to
|
||||
`Thomas Brueggemann`_ and `David Martin`_ for their input on this one.
|
||||
* Fix for `#232`_ wherein Paperless wasn't recognising ``.tif`` files
|
||||
properly. Thanks to `ayounggun`_ for reporting this one and to
|
||||
`Kusti Skytén`_ for posting the correct solution in the Github issue.
|
||||
|
||||
0.6.0
|
||||
=====
|
||||
|
||||
* Abandon the shared-secret trick we were using for the POST API in favour
|
||||
of BasicAuth or Django session.
|
||||
* Fix the POST API so it actually works. `#236`_
|
||||
* **Breaking change**: We've dropped the use of ``PAPERLESS_SHARED_SECRET``
|
||||
as it was being used both for the API (now replaced with a normal auth)
|
||||
and form email polling. Now that we're only using it for email, this
|
||||
variable has been renamed to ``PAPERLESS_EMAIL_SECRET``. The old value
|
||||
will still work for a while, but you should change your config if you've
|
||||
been using the email polling feature. Thanks to `Joshua Gilman`_ for all
|
||||
the help with this feature.
|
||||
|
||||
0.5.0
|
||||
=====
|
||||
|
||||
* Support for fuzzy matching in the auto-tagger & auto-correspondent systems
|
||||
thanks to `Jake Gysland`_'s patch `#220`_.
|
||||
* Modified the Dockerfile to prepare an export directory (`#212`_). Thanks
|
||||
to combined efforts from `Pit`_ and `Strubbl`_ in working out the kinks on
|
||||
this one.
|
||||
* Updated the import/export scripts to include support for thumbnails. Big
|
||||
thanks to `CkuT`_ for finding this shortcoming and doing the work to get
|
||||
it fixed in `#224`_.
|
||||
* All of the following changes are thanks to `David Martin`_:
|
||||
* Bumped the dependency on pyocr to 0.4.7 so new users can make use of
|
||||
Tesseract 4 if they so prefer (`#226`_).
|
||||
* Fixed a number of issues with the automated mail handler (`#227`_, `#228`_)
|
||||
* Amended the documentation for better handling of systemd service files (`#229`_)
|
||||
* Amended the Django Admin configuration to have nice headers (`#230`_)
|
||||
|
||||
0.4.1
|
||||
=====
|
||||
|
||||
* Fix for `#206`_ wherein the pluggable parser didn't recognise files with
|
||||
all-caps suffixes like ``.PDF``
|
||||
|
||||
0.4.0
|
||||
=====
|
||||
|
||||
* Introducing reminders. See `#199`_ for more information, but the short
|
||||
explanation is that you can now attach simple notes & times to documents
|
||||
which are made available via the API. Currently, the default API
|
||||
(basically just the Django admin) doesn't really make use of this, but
|
||||
`Thomas Brueggemann`_ over at `Paperless Desktop`_ has said that he would
|
||||
like to make use of this feature in his project.
|
||||
|
||||
0.3.6
|
||||
=====
|
||||
|
||||
* Fix for `#200`_ (!!) where the API wasn't configured to allow updating the
|
||||
correspondent or the tags for a document.
|
||||
* The ``content`` field is now optional, to allow for the edge case of a
|
||||
purely graphical document.
|
||||
* You can no longer add documents via the admin. This never worked in the
|
||||
first place, so all I've done here is remove the link to the broken form.
|
||||
* The consumer code has been heavily refactored to support a pluggable
|
||||
interface. Install a paperless consumer via pip and tell paperless about
|
||||
it with an environment variable, and you're good to go. Proper
|
||||
documentation is on its way.
|
||||
|
||||
0.3.5
|
||||
=====
|
||||
|
||||
* A serious facelift for the documents listing page wherein we drop the
|
||||
tabular layout in favour of a tiled interface.
|
||||
* Users can now configure the number of items per page.
|
||||
* Fix for `#171`_: Allow users to specify their own ``SECRET_KEY`` value.
|
||||
* Moved the dotenv loading to the top of settings.py
|
||||
* Fix for `#112`_: Added checks for binaries required for document
|
||||
consumption.
|
||||
|
||||
0.3.4
|
||||
=====
|
||||
|
||||
* Removal of django-suit due to a licensing conflict I bumped into in 0.3.3.
|
||||
Note that you *can* use Django Suit with Paperless, but only in a
|
||||
non-profit situation as their free license prohibits for-profit use. As a
|
||||
result, I can't bundle Suit with Paperless without conflicting with the
|
||||
GPL. Further development will be done against the stock Django admin.
|
||||
* I shrunk the thumbnails a little 'cause they were too big for me, even on
|
||||
my high-DPI monitor.
|
||||
* BasicAuth support for document and thumbnail downloads, as well as the Push
|
||||
API thanks to @thomasbrueggemann. See `#179`_.
|
||||
|
||||
0.3.3
|
||||
=====
|
||||
|
||||
* Thumbnails in the UI and a Django-suit -based face-lift courtesy of @ekw!
|
||||
* Timezone, items per page, and default language are now all configurable,
|
||||
also thanks to @ekw.
|
||||
|
||||
0.3.2
|
||||
=====
|
||||
|
||||
* Fix for `#172`_: defaulting ALLOWED_HOSTS to ``["*"]`` and allowing the
|
||||
user to set her own value via ``PAPERLESS_ALLOWED_HOSTS`` should the need
|
||||
arise.
|
||||
|
||||
0.3.1
|
||||
=====
|
||||
|
||||
* Added a default value for ``CONVERT_BINARY``
|
||||
|
||||
0.3.0
|
||||
=====
|
||||
|
||||
* Updated to using django-filter 1.x
|
||||
* Added some system checks so new users aren't confused by misconfigurations.
|
||||
* Consumer loop time is now configurable for systems with slow writes. Just
|
||||
set ``PAPERLESS_CONSUMER_LOOP_TIME`` to a number of seconds. The default
|
||||
is 10.
|
||||
* As per `#44`_, we've removed support for ``PAPERLESS_CONVERT``,
|
||||
``PAPERLESS_CONSUME``, and ``PAPERLESS_SECRET``. Please use
|
||||
``PAPERLESS_CONVERT_BINARY``, ``PAPERLESS_CONSUMPTION_DIR``, and
|
||||
``PAPERLESS_SHARED_SECRET`` respectively instead.
|
||||
|
||||
0.2.0
|
||||
=====
|
||||
|
||||
* `#150`_: The media root is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#148`_: The database location (sqlite) is now a variable you can set in
|
||||
``paperless.conf``.
|
||||
* `#146`_: Fixed a bug that allowed unauthorised access to the ``/fetch``
|
||||
URL.
|
||||
* `#131`_: Document files are now automatically removed from disk when
|
||||
they're deleted in Paperless.
|
||||
* `#121`_: Fixed a bug where Paperless wasn't setting document creation time
|
||||
based on the file naming scheme.
|
||||
* `#81`_: Added a hook to run an arbitrary script after every document is
|
||||
consumed.
|
||||
* `#98`_: Added optional environment variables for ImageMagick so that it
|
||||
doesn't explode when handling Very Large Documents or when it's just
|
||||
running on a low-memory system. Thanks to `Florian Harr`_ for his help on
|
||||
this one.
|
||||
* `#89`_ Ported the auto-tagging code to correspondents as well. Thanks to
|
||||
`Justin Snyman`_ for the pointers in the issue queue.
|
||||
* Added support for guessing the date from the file name along with the
|
||||
correspondent, title, and tags. Thanks to `Tikitu de Jager`_ for his pull
|
||||
request that I took forever to merge and to `Pit`_ for his efforts on the
|
||||
regex front.
|
||||
* `#94`_: Restored support for changing the created date in the UI. Thanks
|
||||
to `Martin Honermeyer`_ and `Tim White`_ for working with me on this.
|
||||
|
||||
0.1.1
|
||||
=====
|
||||
|
||||
* Potentially **Breaking Change**: All references to "sender" in the code
|
||||
have been renamed to "correspondent" to better reflect the nature of the
|
||||
property (one could quite reasonably scan a document before sending it to
|
||||
someone.)
|
||||
* `#67`_: Rewrote the document exporter and added a new importer that allows
|
||||
for full metadata retention without depending on the file name and
|
||||
modification time. A big thanks to `Tikitu de Jager`_, `Pit`_,
|
||||
`Florian Jung`_, and `Christopher Luu`_ for their code snippets and
|
||||
contributing conversation that lead to this change.
|
||||
* `#20`_: Added *unpaper* support to help in cleaning up the scanned image
|
||||
before it's OCR'd. Thanks to `Pit`_ for this one.
|
||||
* `#71`_ Added (encrypted) thumbnails in anticipation of a proper UI.
|
||||
* `#68`_: Added support for using a proper config file at
|
||||
``/etc/paperless.conf`` and modified the systemd unit files to use it.
|
||||
* Refactored the Vagrant installation process to use environment variables
|
||||
rather than asking the user to modify ``settings.py``.
|
||||
* `#44`_: Harmonise environment variable names with constant names.
|
||||
* `#60`_: Setup logging to actually use the Python native logging framework.
|
||||
* `#53`_: Fixed an annoying bug that caused ``.jpeg`` and ``.JPG`` images
|
||||
to be imported but made unavailable.
|
||||
|
||||
0.1.0
|
||||
=====
|
||||
|
||||
* Docker support! Big thanks to `Wayne Werner`_, `Brian Conn`_, and
|
||||
`Tikitu de Jager`_ for this one, and especially to `Pit`_
|
||||
who spearheadded this effort.
|
||||
* A simple REST API is in place, but it should be considered unstable.
|
||||
* Cleaned up the consumer to use temporary directories instead of a single
|
||||
scratch space. (Thanks `Pit`_)
|
||||
* Improved the efficiency of the consumer by parsing pages more intelligently
|
||||
and introducing a threaded OCR process (thanks again `Pit`_).
|
||||
* `#45`_: Cleaned up the logic for tag matching. Reported by `darkmatter`_.
|
||||
* `#47`_: Auto-rotate landscape documents. Reported by `Paul`_ and fixed by
|
||||
`Pit`_.
|
||||
* `#48`_: Matching algorithms should do so on a word boundary (`darkmatter`_)
|
||||
* `#54`_: Documented the re-tagger (`zedster`_)
|
||||
* `#57`_: Make sure file is preserved on import failure (`darkmatter`_)
|
||||
* Added tox with pep8 checking
|
||||
|
||||
0.0.6
|
||||
=====
|
||||
|
||||
* Added support for parallel OCR (significant work from `Pit`_)
|
||||
* Sped up the language detection (significant work from `Pit`_)
|
||||
* Added simple logging
|
||||
|
||||
0.0.5
|
||||
=====
|
||||
|
||||
* Added support for image files as documents (png, jpg, gif, tiff)
|
||||
* Added a crude means of HTTP POST for document imports
|
||||
* Added IMAP mail support
|
||||
* Added a re-tagging utility
|
||||
* Documentation for the above as well as data migration
|
||||
|
||||
0.0.4
|
||||
=====
|
||||
|
||||
* Added automated tagging basted on keyword matching
|
||||
* Cleaned up the document listing page
|
||||
* Removed ``User`` and ``Group`` from the admin
|
||||
* Added ``pytz`` to the list of requirements
|
||||
|
||||
0.0.3
|
||||
=====
|
||||
|
||||
* Added basic tagging
|
||||
|
||||
0.0.2
|
||||
=====
|
||||
|
||||
* Added language detection
|
||||
* Added datestamps to ``document_exporter``.
|
||||
* Changed ``settings.TESSERACT_LANGUAGE`` to ``settings.OCR_LANGUAGE``.
|
||||
|
||||
0.0.1
|
||||
=====
|
||||
|
||||
* Initial release
|
||||
|
||||
.. _Brian Conn: https://github.com/TheConnMan
|
||||
.. _Christopher Luu: https://github.com/nuudles
|
||||
@@ -161,6 +526,50 @@ Changelog
|
||||
.. _Tim White: https://github.com/timwhite
|
||||
.. _Florian Harr: https://github.com/evils
|
||||
.. _Justin Snyman: https://github.com/stringlytyped
|
||||
.. _Thomas Brueggemann: https://github.com/thomasbrueggemann
|
||||
.. _Jake Gysland: https://github.com/jgysland
|
||||
.. _Strubbl: https://github.com/strubbl
|
||||
.. _CkuT: https://github.com/CkuT
|
||||
.. _David Martin: https://github.com/ddddavidmartin
|
||||
.. _Paperless Desktop: https://github.com/thomasbrueggemann/paperless-desktop
|
||||
.. _Joshua Gilman: https://github.com/jmgilman
|
||||
.. _ayounggun: https://github.com/ayounggun
|
||||
.. _Kusti Skytén: https://github.com/kskyten
|
||||
.. _maphy-psd: https://github.com/maphy-psd
|
||||
.. _ishirav: https://github.com/ishirav
|
||||
.. _Stefan Hagen: https://github.com/xkpd3
|
||||
.. _dev-rke: https://github.com/dev-rke
|
||||
.. _Lukas Winkler: https://github.com/Findus23
|
||||
.. _chris-aeviator: https://github.com/chris-aeviator
|
||||
.. _Dan Panzarella: https://github.com/pzl
|
||||
.. _addadi: https://github.com/addadi
|
||||
.. _BastianPoe: https://github.com/BastianPoe
|
||||
.. _matthewmoto: https://github.com/matthewmoto
|
||||
.. _Isaac: https://github.com/isaacsando
|
||||
.. _Georgi Todorov: https://github.com/TeraHz
|
||||
.. _Jeffrey Portman: https://github.com/ChromoX
|
||||
.. _Simon Taddiken: https://github.com/skuzzle
|
||||
.. _Quentin Dawans: https://github.com/ovv
|
||||
.. _Martin Arendtsen: https://github.com/Arendtsen
|
||||
.. _erikarvstedt: https://github.com/erikarvstedt
|
||||
.. _Kyle Lucy: https://github.com/kmlucy
|
||||
.. _thinkjk: https://github.com/thinkjk
|
||||
.. _mcronce: https://github.com/mcronce
|
||||
.. _Enno Lohmeier: https://github.com/elohmeier
|
||||
.. _Mark McFate: https://github.com/SummittDweller
|
||||
.. _dadosch: https://github.com/dadosch
|
||||
.. _Wolfgang Mader: https://github.com/wmader
|
||||
.. _Tim Brooks: https://github.com/brookst
|
||||
.. _Stéphane Brunner: https://github.com/sbrunner
|
||||
.. _Kilian Koeltzsch: https://github.com/kiliankoe
|
||||
.. _Lukasz Soluch: https://github.com/LukaszSolo
|
||||
.. _Joshua Taillon: https://github.com/jat255
|
||||
.. _dubit0: https://github.com/dubit0
|
||||
.. _ahyear: https://github.com/ahyear
|
||||
.. _jonaswinkler: https://github.com/jonaswinkler
|
||||
.. _thepill: https://github.com/thepill
|
||||
.. _Andrew Peng: https://github.com/pengc99
|
||||
.. _euri10: https://github.com/euri10
|
||||
|
||||
.. _#20: https://github.com/danielquinn/paperless/issues/20
|
||||
.. _#44: https://github.com/danielquinn/paperless/issues/44
|
||||
@@ -184,6 +593,78 @@ Changelog
|
||||
.. _#146: https://github.com/danielquinn/paperless/issues/146
|
||||
.. _#148: https://github.com/danielquinn/paperless/pull/148
|
||||
.. _#150: https://github.com/danielquinn/paperless/pull/150
|
||||
.. _#158: https://github.com/danielquinn/paperless/issues/158
|
||||
.. _#171: https://github.com/danielquinn/paperless/issues/171
|
||||
.. _#172: https://github.com/danielquinn/paperless/issues/172
|
||||
.. _#179: https://github.com/danielquinn/paperless/pull/179
|
||||
.. _#199: https://github.com/danielquinn/paperless/issues/199
|
||||
.. _#200: https://github.com/danielquinn/paperless/issues/200
|
||||
.. _#206: https://github.com/danielquinn/paperless/issues/206
|
||||
.. _#212: https://github.com/danielquinn/paperless/pull/212
|
||||
.. _#220: https://github.com/danielquinn/paperless/pull/220
|
||||
.. _#224: https://github.com/danielquinn/paperless/pull/224
|
||||
.. _#226: https://github.com/danielquinn/paperless/pull/226
|
||||
.. _#227: https://github.com/danielquinn/paperless/pull/227
|
||||
.. _#228: https://github.com/danielquinn/paperless/pull/228
|
||||
.. _#229: https://github.com/danielquinn/paperless/pull/229
|
||||
.. _#230: https://github.com/danielquinn/paperless/pull/230
|
||||
.. _#232: https://github.com/danielquinn/paperless/issues/232
|
||||
.. _#235: https://github.com/danielquinn/paperless/issues/235
|
||||
.. _#236: https://github.com/danielquinn/paperless/issues/236
|
||||
.. _#255: https://github.com/danielquinn/paperless/pull/255
|
||||
.. _#268: https://github.com/danielquinn/paperless/pull/268
|
||||
.. _#277: https://github.com/danielquinn/paperless/pull/277
|
||||
.. _#272: https://github.com/danielquinn/paperless/issues/272
|
||||
.. _#248: https://github.com/danielquinn/paperless/issues/248
|
||||
.. _#278: https://github.com/danielquinn/paperless/issues/248
|
||||
.. _#283: https://github.com/danielquinn/paperless/issues/283
|
||||
.. _#256: https://github.com/danielquinn/paperless/pull/256
|
||||
.. _#285: https://github.com/danielquinn/paperless/pull/285
|
||||
.. _#291: https://github.com/danielquinn/paperless/pull/291
|
||||
.. _#295: https://github.com/danielquinn/paperless/pull/295
|
||||
.. _#299: https://github.com/danielquinn/paperless/issues/299
|
||||
.. _#300: https://github.com/danielquinn/paperless/pull/300
|
||||
.. _#301: https://github.com/danielquinn/paperless/issues/301
|
||||
.. _#303: https://github.com/danielquinn/paperless/issues/303
|
||||
.. _#305: https://github.com/danielquinn/paperless/issues/305
|
||||
.. _#306: https://github.com/danielquinn/paperless/issues/306
|
||||
.. _#308: https://github.com/danielquinn/paperless/issues/308
|
||||
.. _#311: https://github.com/danielquinn/paperless/pull/311
|
||||
.. _#312: https://github.com/danielquinn/paperless/pull/312
|
||||
.. _#313: https://github.com/danielquinn/paperless/pull/313
|
||||
.. _#322: https://github.com/danielquinn/paperless/pull/322
|
||||
.. _#328: https://github.com/danielquinn/paperless/pull/328
|
||||
.. _#253: https://github.com/danielquinn/paperless/issues/253
|
||||
.. _#262: https://github.com/danielquinn/paperless/issues/262
|
||||
.. _#323: https://github.com/danielquinn/paperless/issues/323
|
||||
.. _#344: https://github.com/danielquinn/paperless/pull/344
|
||||
.. _#351: https://github.com/danielquinn/paperless/pull/351
|
||||
.. _#352: https://github.com/danielquinn/paperless/pull/352
|
||||
.. _#354: https://github.com/danielquinn/paperless/issues/354
|
||||
.. _#371: https://github.com/danielquinn/paperless/issues/371
|
||||
.. _#374: https://github.com/danielquinn/paperless/pull/374
|
||||
.. _#375: https://github.com/danielquinn/paperless/pull/375
|
||||
.. _#376: https://github.com/danielquinn/paperless/pull/376
|
||||
.. _#383: https://github.com/danielquinn/paperless/pull/383
|
||||
.. _#384: https://github.com/danielquinn/paperless/issues/384
|
||||
.. _#386: https://github.com/danielquinn/paperless/issues/386
|
||||
.. _#387: https://github.com/danielquinn/paperless/pull/387
|
||||
.. _#391: https://github.com/danielquinn/paperless/pull/391
|
||||
.. _#390: https://github.com/danielquinn/paperless/pull/390
|
||||
.. _#392: https://github.com/danielquinn/paperless/issues/392
|
||||
.. _#393: https://github.com/danielquinn/paperless/issues/393
|
||||
.. _#395: https://github.com/danielquinn/paperless/pull/395
|
||||
.. _#394: https://github.com/danielquinn/paperless/issues/394
|
||||
.. _#396: https://github.com/danielquinn/paperless/pull/396
|
||||
.. _#399: https://github.com/danielquinn/paperless/pull/399
|
||||
.. _#400: https://github.com/danielquinn/paperless/pull/400
|
||||
.. _#401: https://github.com/danielquinn/paperless/pull/401
|
||||
.. _#405: https://github.com/danielquinn/paperless/pull/405
|
||||
.. _#406: https://github.com/danielquinn/paperless/issues/406
|
||||
.. _#412: https://github.com/danielquinn/paperless/issues/412
|
||||
.. _#413: https://github.com/danielquinn/paperless/pull/413
|
||||
.. _#414: https://github.com/danielquinn/paperless/issues/414
|
||||
|
||||
.. _pipenv: https://docs.pipenv.org/
|
||||
.. _a new home on Docker Hub: https://hub.docker.com/r/danielquinn/paperless/
|
||||
.. _optipng: http://optipng.sourceforge.net/
|
||||
|
||||
@@ -40,7 +40,7 @@ extensions = [
|
||||
'sphinx.ext.autodoc',
|
||||
'sphinx.ext.intersphinx',
|
||||
'sphinx.ext.todo',
|
||||
'sphinx.ext.pngmath',
|
||||
'sphinx.ext.imgmath',
|
||||
'sphinx.ext.viewcode',
|
||||
]
|
||||
|
||||
|
||||
@@ -17,7 +17,8 @@ The primary method of getting documents into your database is by putting them in
|
||||
the consumption directory. The ``document_consumer`` script runs in an infinite
|
||||
loop looking for new additions to this directory and when it finds them, it goes
|
||||
about the process of parsing them with the OCR, indexing what it finds, and
|
||||
encrypting the PDF, storing it in the media directory.
|
||||
encrypting the PDF (if ``PAPERLESS_PASSPHRASE`` is set), storing it in the
|
||||
media directory.
|
||||
|
||||
Getting stuff into this directory is up to you. If you're running Paperless
|
||||
on your local computer, you might just want to drag and drop files there, but if
|
||||
@@ -75,6 +76,31 @@ Pre-consumption script
|
||||
|
||||
* Document file name
|
||||
|
||||
A simple but common example for this would be creating a simple script like
|
||||
this:
|
||||
|
||||
``/usr/local/bin/ocr-pdf``
|
||||
|
||||
.. code:: bash
|
||||
|
||||
#!/usr/bin/env bash
|
||||
pdf2pdfocr.py -i ${1}
|
||||
|
||||
``/etc/paperless.conf``
|
||||
|
||||
.. code:: bash
|
||||
|
||||
...
|
||||
PAPERLESS_PRE_CONSUME_SCRIPT="/usr/local/bin/ocr-pdf"
|
||||
...
|
||||
|
||||
This will pass the path to the document about to be consumed to ``/usr/local/bin/ocr-pdf``,
|
||||
which will in turn call `pdf2pdfocr.py`_ on your document, which will then
|
||||
overwrite the file with an OCR'd version of the file and exit. At which point,
|
||||
the consumption process will begin with the newly modified file.
|
||||
|
||||
.. _pdf2pdfocr.py: https://github.com/LeoFCardoso/pdf2pdfocr
|
||||
|
||||
|
||||
.. _consumption-director-hook-variables-post:
|
||||
|
||||
@@ -121,18 +147,21 @@ So, with all that in mind, here's what you do to get it running:
|
||||
|
||||
1. Setup a new email account somewhere, or if you're feeling daring, create a
|
||||
folder in an existing email box and note the path to that folder.
|
||||
2. In ``settings.py`` set all of the appropriate values in ``MAIL_CONSUMPTION``.
|
||||
2. In ``/etc/paperless.conf`` set all of the appropriate values in
|
||||
``PATHS AND FOLDERS`` and ``SECURITY``.
|
||||
If you decided to use a subfolder of an existing account, then make sure you
|
||||
set ``INBOX`` accordingly here. You also have to set the
|
||||
``UPLOAD_SHARED_SECRET`` to something you can remember 'cause you'll have to
|
||||
include that in every email you send.
|
||||
set ``PAPERLESS_CONSUME_MAIL_INBOX`` accordingly here. You also have to set
|
||||
the ``PAPERLESS_EMAIL_SECRET`` to something you can remember 'cause you'll
|
||||
have to include that in every email you send.
|
||||
3. Restart the :ref:`consumer <utilities-consumer>`. The consumer will check
|
||||
the configured email account every 10 minutes for something new and pull down
|
||||
whatever it finds.
|
||||
the configured email account at startup and from then on every 10 minutes
|
||||
for something new and pulls down whatever it finds.
|
||||
4. Send yourself an email! Note that the subject is treated as the file name,
|
||||
so if you set the subject to ``Correspondent - Title - tag,tag,tag``, you'll
|
||||
get what you expect. Also, you must include the aforementioned secret
|
||||
string in every email so the fetcher knows that it's safe to import.
|
||||
Note that Paperless only allows the email title to consist of safe characters
|
||||
to be imported. These consist of alpha-numeric characters and ``-_ ,.'``.
|
||||
5. After a few minutes, the consumer will poll your mailbox, pull down the
|
||||
message, and place the attachment in the consumption directory with the
|
||||
appropriate name. A few minutes later, the consumer will import it like any
|
||||
@@ -144,46 +173,83 @@ So, with all that in mind, here's what you do to get it running:
|
||||
HTTP POST
|
||||
=========
|
||||
|
||||
You can also submit a document via HTTP POST. It doesn't do tags yet, and the
|
||||
URL schema isn't concrete, but it's a start.
|
||||
|
||||
To push your document to Paperless, send an HTTP POST to the server with the
|
||||
following name/value pairs:
|
||||
You can also submit a document via HTTP POST, so long as you do so after
|
||||
authenticating. To push your document to Paperless, send an HTTP POST to the
|
||||
server with the following name/value pairs:
|
||||
|
||||
* ``correspondent``: The name of the document's correspondent. Note that there
|
||||
are restrictions on what characters you can use here. Specifically,
|
||||
alphanumeric characters, `-`, `,`, `.`, and `'` are ok, everything else it
|
||||
alphanumeric characters, `-`, `,`, `.`, and `'` are ok, everything else is
|
||||
out. You also can't use the sequence ` - ` (space, dash, space).
|
||||
* ``title``: The title of the document. The rules for characters is the same
|
||||
here as the correspondent.
|
||||
* ``signature``: For security reasons, we have the correspondent send a
|
||||
signature using a "shared secret" method to make sure that random strangers
|
||||
don't start uploading stuff to your server. The means of generating this
|
||||
signature is defined below.
|
||||
* ``document``: The file you're uploading
|
||||
|
||||
Specify ``enctype="multipart/form-data"``, and then POST your file with::
|
||||
|
||||
Content-Disposition: form-data; name="document"; filename="whatever.pdf"
|
||||
|
||||
An example of this in HTML is a typical form:
|
||||
|
||||
.. _consumption-http-signature:
|
||||
.. code:: html
|
||||
|
||||
Generating the Signature
|
||||
------------------------
|
||||
<form method="post" enctype="multipart/form-data">
|
||||
<input type="text" name="correspondent" value="My Correspondent" />
|
||||
<input type="text" name="title" value="My Title" />
|
||||
<input type="file" name="document" />
|
||||
<input type="submit" name="go" value="Do the thing" />
|
||||
</form>
|
||||
|
||||
Generating a signature based a shared secret is pretty simple: define a secret,
|
||||
and store it on the server and the client. Then use that secret, along with
|
||||
the text you want to verify to generate a string that you can use for
|
||||
verification.
|
||||
|
||||
In the case of Paperless, you configure the server with the secret by setting
|
||||
``UPLOAD_SHARED_SECRET``. Then on your client, you generate your signature by
|
||||
concatenating the correspondent, title, and the secret, and then using sha256
|
||||
to generate a hexdigest.
|
||||
|
||||
If you're using Python, this is what that looks like:
|
||||
But a potentially more useful way to do this would be in Python. Here we use
|
||||
the requests library to handle basic authentication and to send the POST data
|
||||
to the URL.
|
||||
|
||||
.. code:: python
|
||||
|
||||
import os
|
||||
|
||||
from hashlib import sha256
|
||||
signature = sha256(correspondent + title + secret).hexdigest()
|
||||
|
||||
import requests
|
||||
from requests.auth import HTTPBasicAuth
|
||||
|
||||
# You authenticate via BasicAuth or with a session id.
|
||||
# We use BasicAuth here
|
||||
username = "my-username"
|
||||
password = "my-super-secret-password"
|
||||
|
||||
# Where you have Paperless installed and listening
|
||||
url = "http://localhost:8000/push"
|
||||
|
||||
# Document metadata
|
||||
correspondent = "Test Correspondent"
|
||||
title = "Test Title"
|
||||
|
||||
# The local file you want to push
|
||||
path = "/path/to/some/directory/my-document.pdf"
|
||||
|
||||
|
||||
with open(path, "rb") as f:
|
||||
|
||||
response = requests.post(
|
||||
url=url,
|
||||
data={"title": title, "correspondent": correspondent},
|
||||
files={"document": (os.path.basename(path), f, "application/pdf")},
|
||||
auth=HTTPBasicAuth(username, password),
|
||||
allow_redirects=False
|
||||
)
|
||||
|
||||
if response.status_code == 202:
|
||||
|
||||
# Everything worked out ok
|
||||
print("Upload successful")
|
||||
|
||||
else:
|
||||
|
||||
# If you don't get a 202, it's probably because your credentials
|
||||
# are wrong or something. This will give you a rough idea of what
|
||||
# happened.
|
||||
|
||||
print("We got HTTP status code: {}".format(response.status_code))
|
||||
for k, v in response.headers.items():
|
||||
print("{}: {}".format(k, v))
|
||||
|
||||
141
docs/contributing.rst
Normal file
141
docs/contributing.rst
Normal file
@@ -0,0 +1,141 @@
|
||||
.. _contributing:
|
||||
|
||||
Contributing to Paperless
|
||||
#########################
|
||||
|
||||
Maybe you've been using Paperless for a while and want to add a feature or two,
|
||||
or maybe you've come across a bug that you have some ideas how to solve. The
|
||||
beauty of Free software is that you can see what's wrong and help to get it
|
||||
fixed for everyone!
|
||||
|
||||
|
||||
How to Get Your Changes Rolled Into Paperless
|
||||
=============================================
|
||||
|
||||
If you've found a bug, but don't know how to fix it, you can always post an
|
||||
issue on `GitHub`_ in the hopes that someone will have the time to fix it for
|
||||
you. If however you're the one with the time, pull requests are always
|
||||
welcome, you just have to make sure that your code conforms to a few standards:
|
||||
|
||||
Pep8
|
||||
----
|
||||
|
||||
It's the standard for all Python development, so it's `very well documented`_.
|
||||
The short version is:
|
||||
|
||||
* Lines should wrap at 79 characters
|
||||
* Use ``snake_case`` for variables, ``CamelCase`` for classes, and ``ALL_CAPS``
|
||||
for constants.
|
||||
* Space out your operators: ``stuff + 7`` instead of ``stuff+7``
|
||||
* Two empty lines between classes, and functions, but 1 empty line between
|
||||
class methods.
|
||||
|
||||
There's more to it than that, but if you follow those, you'll probably be
|
||||
alright. When you submit your pull request, there's a pep8 checker that'll
|
||||
look at your code to see if anything is off. If it finds anything, it'll
|
||||
complain at you until you fix it.
|
||||
|
||||
|
||||
Additional Style Guides
|
||||
-----------------------
|
||||
|
||||
Where pep8 is ambiguous, I've tried to be a little more specific. These rules
|
||||
aren't hard-and-fast, but if you can conform to them, I'll appreciate it and
|
||||
spend less time trying to conform your PR before merging:
|
||||
|
||||
|
||||
Function calls
|
||||
..............
|
||||
|
||||
If you're calling a function and that necessitates more than one line of code,
|
||||
please format it like this:
|
||||
|
||||
.. code:: python
|
||||
|
||||
my_function(
|
||||
argument1,
|
||||
kwarg1="x",
|
||||
kwarg2="y"
|
||||
another_really_long_kwarg="some big value"
|
||||
a_kwarg_calling_another_long_function=another_function(
|
||||
another_arg,
|
||||
another_kwarg="kwarg!"
|
||||
)
|
||||
)
|
||||
|
||||
This is all in the interest of code uniformity rather than anything else. If
|
||||
we stick to a style, everything is understandable in the same way.
|
||||
|
||||
|
||||
Quoting Strings
|
||||
...............
|
||||
|
||||
pep8 is a little too open-minded on this for my liking. Python strings should
|
||||
be quoted with double quotes (``"``) except in cases where the resulting string
|
||||
would require too much escaping of a double quote, in which case, a single
|
||||
quoted, or triple-quoted string will do:
|
||||
|
||||
.. code:: python
|
||||
|
||||
my_string = "This is my string"
|
||||
problematic_string = 'This is a "string" with "quotes" in it'
|
||||
|
||||
In HTML templates, please use double-quotes for tag attributes, and single
|
||||
quotes for arguments passed to Django tempalte tags:
|
||||
|
||||
.. code:: html
|
||||
|
||||
<div class="stuff">
|
||||
<a href="{% url 'some-url-name' pk='w00t' %}">link this</a>
|
||||
</div>
|
||||
|
||||
This is to keep linters happy they look at an HTML file and see an attribute
|
||||
closing the ``"`` before it should have been.
|
||||
|
||||
--
|
||||
|
||||
That's all there is in terms of guidelines, so I hope it's not too daunting.
|
||||
|
||||
|
||||
Indentation & Spacing
|
||||
.....................
|
||||
|
||||
When it comes to indentation:
|
||||
|
||||
* For Python, the rule is: follow pep8 and use 4 spaces.
|
||||
* For Javascript, CSS, and HTML, please use 1 tab.
|
||||
|
||||
Additionally, Django templates making use of block elements like ``{% if %}``,
|
||||
``{% for %}``, and ``{% block %}`` etc. should be indented:
|
||||
|
||||
Good:
|
||||
|
||||
.. code:: html
|
||||
|
||||
{% block stuff %}
|
||||
<h1>This is the stuff</h1>
|
||||
{% endblock %}
|
||||
|
||||
Bad:
|
||||
|
||||
.. code:: html
|
||||
|
||||
{% block stuff %}
|
||||
<h1>This is the stuff</h1>
|
||||
{% endblock %}
|
||||
|
||||
|
||||
The Code of Conduct
|
||||
===================
|
||||
|
||||
Paperless has a `code of conduct`_. It's a lot like the other ones you see out
|
||||
there, with a few small changes, but basically it boils down to:
|
||||
|
||||
> Don't be an ass, or you might get banned.
|
||||
|
||||
I'm proud to say that the CoC has never had to be enforced because everyone has
|
||||
been awesome, friendly, and professional.
|
||||
|
||||
.. _GitHub: https://github.com/danielquinn/paperless/issues
|
||||
.. _very well documented: https://www.python.org/dev/peps/pep-0008/
|
||||
.. _code of conduct: https://github.com/danielquinn/paperless/blob/master/CODE_OF_CONDUCT.md
|
||||
42
docs/customising.rst
Normal file
42
docs/customising.rst
Normal file
@@ -0,0 +1,42 @@
|
||||
.. _customising:
|
||||
|
||||
Customising Paperless
|
||||
#####################
|
||||
|
||||
Currently, the Paperless' interface is just the default Django admin, which
|
||||
while powerful, is rather boring. If you'd like to give the site a bit of a
|
||||
face-lift, or if you simply want to adjust the colours, contrast, or font size
|
||||
to make things easier to read, you can do that by adding your own CSS or
|
||||
Javascript quite easily.
|
||||
|
||||
|
||||
.. _customising-overrides:
|
||||
|
||||
Overrides
|
||||
=========
|
||||
|
||||
On every page load, Paperless looks for two files in your media root directory
|
||||
(the directory defined by your ``PAPERLESS_MEDIADIR`` configuration variable or
|
||||
the default, ``<project root>/media/``) for two files:
|
||||
|
||||
* ``overrides.css``
|
||||
* ``overrides.js``
|
||||
|
||||
If it finds either or both of those files, they'll be loaded into the page: the
|
||||
CSS in the ``<head>``, and the Javascript stuffed into the last line of the
|
||||
``<body>``.
|
||||
|
||||
|
||||
.. _customising-overrides-note:
|
||||
|
||||
An important note about customisation
|
||||
-------------------------------------
|
||||
|
||||
Any changes you make to the site with your CSS or Javascript are likely to
|
||||
depend on the structure of the current HTML and/or the existing CSS rules. For
|
||||
the most part it's safe to assume that these bits won't change, but *sometimes
|
||||
they do* as features are added or bugs are fixed.
|
||||
|
||||
If you make a change that you think others would appreciate though, submit it
|
||||
as a pull request and maybe we can find a way to work it into the project by
|
||||
default!
|
||||
112
docs/extending.rst
Normal file
112
docs/extending.rst
Normal file
@@ -0,0 +1,112 @@
|
||||
.. _extending:
|
||||
|
||||
Extending Paperless
|
||||
===================
|
||||
|
||||
For the most part, Paperless is monolithic, so extending it is often best
|
||||
managed by way of modifying the code directly and issuing a pull request on
|
||||
`GitHub`_. However, over time the project has been evolving to be a little
|
||||
more "pluggable" so that users can write their own stuff that talks to it.
|
||||
|
||||
.. _GitHub: https://github.com/danielquinn/paperless
|
||||
|
||||
|
||||
.. _extending-parsers:
|
||||
|
||||
Parsers
|
||||
-------
|
||||
|
||||
You can leverage Paperless' consumption model to have it consume files *other*
|
||||
than ones handled by default like ``.pdf``, ``.jpg``, and ``.tiff``. To do so,
|
||||
you simply follow Django's convention of creating a new app, with a few key
|
||||
requirements.
|
||||
|
||||
|
||||
.. _extending-parsers-parserspy:
|
||||
|
||||
parsers.py
|
||||
..........
|
||||
|
||||
In this file, you create a class that extends
|
||||
``documents.parsers.DocumentParser`` and go about implementing the three
|
||||
required methods:
|
||||
|
||||
* ``get_thumbnail()``: Returns the path to a file we can use as a thumbnail for
|
||||
this document.
|
||||
* ``get_text()``: Returns the text from the document and only the text.
|
||||
* ``get_date()``: If possible, this returns the date of the document, otherwise
|
||||
it should return ``None``.
|
||||
|
||||
|
||||
.. _extending-parsers-signalspy:
|
||||
|
||||
signals.py
|
||||
..........
|
||||
|
||||
At consumption time, Paperless emits a ``document_consumer_declaration``
|
||||
signal which your module has to react to in order to let the consumer know
|
||||
whether or not it's capable of handling a particular file. Think of it like
|
||||
this:
|
||||
|
||||
1. Consumer finds a file in the consumption directory.
|
||||
2. It asks all the available parsers: *"Hey, can you handle this file?"*
|
||||
3. Each parser responds with either ``None`` meaning they can't handle the
|
||||
file, or a dictionary in the following format:
|
||||
|
||||
.. code:: python
|
||||
|
||||
{
|
||||
"parser": <the class name>,
|
||||
"weight": <an integer>
|
||||
}
|
||||
|
||||
The consumer compares the ``weight`` values from all respondents and uses the
|
||||
class with the highest value to consume the document. The default parser,
|
||||
``RasterisedDocumentParser`` has a weight of ``0``.
|
||||
|
||||
|
||||
.. _extending-parsers-appspy:
|
||||
|
||||
apps.py
|
||||
.......
|
||||
|
||||
This is a standard Django file, but you'll need to add some code to it to
|
||||
connect your parser to the ``document_consumer_declaration`` signal.
|
||||
|
||||
|
||||
.. _extending-parsers-finally:
|
||||
|
||||
Finally
|
||||
.......
|
||||
|
||||
The last step is to update ``settings.py`` to include your new module.
|
||||
Eventually, this will be dynamic, but at the moment, you have to edit the
|
||||
``INSTALLED_APPS`` section manually. Simply add the path to your AppConfig to
|
||||
the list like this:
|
||||
|
||||
.. code:: python
|
||||
|
||||
INSTALLED_APPS = [
|
||||
...
|
||||
"my_module.apps.MyModuleConfig",
|
||||
...
|
||||
]
|
||||
|
||||
Order doesn't matter, but generally it's a good idea to place your module lower
|
||||
in the list so that you don't end up accidentally overriding project defaults
|
||||
somewhere.
|
||||
|
||||
|
||||
.. _extending-parsers-example:
|
||||
|
||||
An Example
|
||||
..........
|
||||
|
||||
The core Paperless functionality is based on this design, so if you want to see
|
||||
what a parser module should look like, have a look at `parsers.py`_,
|
||||
`signals.py`_, and `apps.py`_ in the `paperless_tesseract`_ module.
|
||||
|
||||
.. _parsers.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/parsers.py
|
||||
.. _signals.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/signals.py
|
||||
.. _apps.py: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/apps.py
|
||||
.. _paperless_tesseract: https://github.com/danielquinn/paperless/blob/master/src/paperless_tesseract/
|
||||
@@ -20,6 +20,8 @@ for you. This is is the logic the consumer follows:
|
||||
the pattern: ``Date - Correspondent - Title - tag,tag,tag.pdf``. Note that
|
||||
the format of the date is **rigidly defined** as ``YYYYMMDDHHMMSSZ`` or
|
||||
``YYYYMMDDZ``. The ``Z`` refers "Zulu time" AKA "UTC".
|
||||
The tags are optional, so the format ``Date - Correspondent - Title.pdf``
|
||||
works as well.
|
||||
2. If that doesn't work, we skip the date and try this pattern:
|
||||
``Correspondent - Title - tag,tag,tag.pdf``.
|
||||
3. If that doesn't work, we try to find the correspondent and title in the file
|
||||
@@ -80,6 +82,12 @@ text and matching algorithm. From the help info there:
|
||||
uses a regex to match the PDF. If you don't know what a regex is, you
|
||||
probably don't want this option.
|
||||
|
||||
When using the "any" or "all" matching algorithms, you can search for terms that
|
||||
consist of multiple words by enclosing them in double quotes. For example, defining
|
||||
a match text of ``"Bank of America" BofA`` using the "any" algorithm, will match
|
||||
documents that contain either "Bank of America" or "BofA", but will not match
|
||||
documents containing "Bank of South America".
|
||||
|
||||
Then just save your tag/correspondent and run another document through the
|
||||
consumer. Once complete, you should see the newly-created document,
|
||||
automatically tagged with the appropriate data.
|
||||
|
||||
@@ -3,7 +3,11 @@
|
||||
Paperless
|
||||
=========
|
||||
|
||||
Scan, index, and archive all of your paper documents. Say goodbye to paper.
|
||||
Paperless is a simple Django application running in two parts:
|
||||
a :ref:`consumer <utilities-consumer>` (the thing that does the indexing) and
|
||||
the :ref:`webserver <utilities-webserver>` (the part that lets you search &
|
||||
download already-indexed documents). If you want to learn more about its
|
||||
functions keep on reading after the installation section.
|
||||
|
||||
|
||||
.. _index-why-this-exists:
|
||||
@@ -12,13 +16,15 @@ Why This Exists
|
||||
===============
|
||||
|
||||
Paper is a nightmare. Environmental issues aside, there's no excuse for it in
|
||||
the 21st century. It takes up space, collects dust, doesn't support any form of
|
||||
a search feature, indexing is tedious, it's heavy and prone to damage & loss.
|
||||
the 21st century. It takes up space, collects dust, doesn't support any form
|
||||
of a search feature, indexing is tedious, it's heavy and prone to damage &
|
||||
loss.
|
||||
|
||||
I wrote this to make "going paperless" easier. I do not have to worry about
|
||||
finding stuff again. I feed documents right from the post box into the scanner
|
||||
and then shred them. Perhaps you might find it useful too.
|
||||
|
||||
|
||||
I wrote this to make "going paperless" easier. I wanted to be able to feed
|
||||
documents right from the post box into the scanner and then shred them so I
|
||||
never have to worry about finding stuff again. Perhaps you might find it useful
|
||||
too.
|
||||
|
||||
|
||||
Contents
|
||||
@@ -34,5 +40,9 @@ Contents
|
||||
utilities
|
||||
guesswork
|
||||
migrating
|
||||
customising
|
||||
extending
|
||||
troubleshooting
|
||||
contributing
|
||||
scanners
|
||||
changelog
|
||||
|
||||
@@ -16,7 +16,7 @@ Backing Up
|
||||
----------
|
||||
|
||||
So you're bored of this whole project, or you want to make a remote backup of
|
||||
the unencrypted files for whatever reason. This is easy to do, simply use the
|
||||
your files for whatever reason. This is easy to do, simply use the
|
||||
:ref:`exporter <utilities-exporter>` to dump your documents and database out
|
||||
into an arbitrary directory.
|
||||
|
||||
@@ -94,15 +94,15 @@ You may want to take a look at the ``paperless.conf.example`` file to see if
|
||||
there's anything new in there compared to what you've got int ``/etc``.
|
||||
|
||||
If you are :ref:`using Docker <setup-installation-docker>` the update process
|
||||
requires only one additional step:
|
||||
is similar:
|
||||
|
||||
.. code-block:: shell-session
|
||||
|
||||
$ cd /path/to/project
|
||||
$ git pull
|
||||
$ docker build -t paperless .
|
||||
$ docker-compose run --rm comsumer migrate
|
||||
$ docker-compose up -d
|
||||
$ docker-compose run --rm webserver migrate
|
||||
|
||||
If ``git pull`` doesn't report any changes, there is no need to continue with
|
||||
the remaining steps.
|
||||
|
||||
@@ -4,31 +4,34 @@ Requirements
|
||||
============
|
||||
|
||||
You need a Linux machine or Unix-like setup (theoretically an Apple machine
|
||||
should work) that has the following software installed on it:
|
||||
should work) that has the following software installed:
|
||||
|
||||
* `Python3`_ (with development libraries, pip and virtualenv)
|
||||
* `GNU Privacy Guard`_
|
||||
* `Tesseract`_, plus its language files matching your document base.
|
||||
* `Imagemagick`_ version 6.7.5 or higher
|
||||
* `unpaper`_
|
||||
* `libpoppler-cpp-dev`_ PDF rendering library
|
||||
|
||||
.. _Python3: https://python.org/
|
||||
.. _GNU Privacy Guard: https://gnupg.org
|
||||
.. _Tesseract: https://github.com/tesseract-ocr
|
||||
.. _Imagemagick: http://imagemagick.org/
|
||||
.. _unpaper: https://www.flameeyes.eu/projects/unpaper
|
||||
.. _libpoppler-cpp-dev: https://poppler.freedesktop.org/
|
||||
|
||||
Notably, you should confirm how you access your Python3 installation. Many
|
||||
Linux distributions will install Python3 in parallel to Python2, using the names
|
||||
``python3`` and ``python`` respectively. The same goes for ``pip3`` and
|
||||
``pip``. Using Python2 will likely break things, so make sure that you're using
|
||||
the right version.
|
||||
Linux distributions will install Python3 in parallel to Python2, using the
|
||||
names ``python3`` and ``python`` respectively. The same goes for ``pip3`` and
|
||||
``pip``. Running Paperless with Python2 will likely break things, so make sure
|
||||
that you're using the right version.
|
||||
|
||||
For the purposes of simplicity, ``python`` and ``pip`` is used everywhere to
|
||||
refer to their Python 3 versions.
|
||||
refer to their Python3 versions.
|
||||
|
||||
In addition to the above, there are a number of Python requirements, all of
|
||||
which are listed in a file called ``requirements.txt`` in the project root.
|
||||
which are listed in a file called ``requirements.txt`` in the project root
|
||||
directory.
|
||||
|
||||
If you're not working on a virtual environment (like Vagrant or Docker), you
|
||||
should probably be using a virtualenv, but that's your call. The reasons why
|
||||
@@ -39,12 +42,13 @@ probably figure that out before continuing.
|
||||
|
||||
.. _requirements-apple:
|
||||
|
||||
Apple-tastic Complications
|
||||
--------------------------
|
||||
Problems with Imagemagick & PDFs
|
||||
--------------------------------
|
||||
|
||||
Some users have `run into problems`_ with installing ImageMagick on Apple
|
||||
systems using HomeBrew. The solution appears to be to install ghostscript as
|
||||
well as ImageMagick:
|
||||
Some users have `run into problems`_ with getting ImageMagick to do its thing
|
||||
with PDFs. Often this is the case with Apple systems using HomeBrew, but other
|
||||
Linuxes have been a problem as well. The solution appears to be to install
|
||||
ghostscript as well as ImageMagick:
|
||||
|
||||
.. _run into problems: https://github.com/danielquinn/paperless/issues/25
|
||||
|
||||
@@ -67,7 +71,7 @@ dependencies is easy:
|
||||
|
||||
$ pip install --user --requirement /path/to/paperless/requirements.txt
|
||||
|
||||
This should download and install all of the requirements into
|
||||
This will download and install all of the requirements into
|
||||
``${HOME}/.local``. Remember that your distribution may be using ``pip3`` as
|
||||
mentioned above.
|
||||
|
||||
@@ -86,8 +90,8 @@ enter it, and install the requirements using the ``requirements.txt`` file:
|
||||
$ . /path/to/arbitrary/directory/bin/activate
|
||||
$ pip install --requirement /path/to/paperless/requirements.txt
|
||||
|
||||
Now you're ready to go. Just remember to enter your virtualenv whenever you
|
||||
want to use Paperless.
|
||||
Now you're ready to go. Just remember to enter (activate) your virtualenv
|
||||
whenever you want to use Paperless.
|
||||
|
||||
|
||||
.. _requirements-documentation:
|
||||
@@ -95,7 +99,7 @@ want to use Paperless.
|
||||
Documentation
|
||||
-------------
|
||||
|
||||
As generation of the documentation is not required for use of Paperless,
|
||||
As generation of the documentation is not required for the use of Paperless,
|
||||
dependencies for this process are not included in ``requirements.txt``. If
|
||||
you'd like to generate your own docs locally, you'll need to:
|
||||
|
||||
|
||||
0
docs/requirements.txt
Normal file
0
docs/requirements.txt
Normal file
29
docs/scanners.rst
Normal file
29
docs/scanners.rst
Normal file
@@ -0,0 +1,29 @@
|
||||
.. _scanners:
|
||||
|
||||
Scanner Recommendations
|
||||
=======================
|
||||
|
||||
As Paperless operates by watching a folder for new files, doesn't care what
|
||||
scanner you use, but sometimes finding a scanner that will write to an FTP,
|
||||
NFS, or SMB server can be difficult. This page is here to help you find one
|
||||
that works right for you based on recommentations from other Paperless users.
|
||||
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Brand | Model | Supports | Recommended By |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| | | FTP | NFS | SMB | |
|
||||
+=========+================+=====+=====+=====+================+
|
||||
| Brother | `ADS-1500W`_ | yes | no | yes | `danielquinn`_ |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Brother | `MFC-J6930DW`_ | yes | | | `ayounggun`_ |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
| Fujitsu | `ix500`_ | yes | | yes | `eonist`_ |
|
||||
+---------+----------------+-----+-----+-----+----------------+
|
||||
|
||||
.. _ADS-1500W: https://www.brother.ca/en/p/ads1500w
|
||||
.. _MFC-J6930DW: https://www.brother.ca/en/p/MFCJ6930DW
|
||||
.. _ix500: http://www.fujitsu.com/us/products/computing/peripheral/scanners/scansnap/ix500/
|
||||
|
||||
.. _danielquinn: https://github.com/danielquinn
|
||||
.. _ayounggun: https://github.com/ayounggun
|
||||
.. _eonist: https://github.com/eonist
|
||||
494
docs/setup.rst
494
docs/setup.rst
@@ -4,7 +4,7 @@ Setup
|
||||
=====
|
||||
|
||||
Paperless isn't a very complicated app, but there are a few components, so some
|
||||
basic documentation is in order. If you go follow along in this document and
|
||||
basic documentation is in order. If you follow along in this document and
|
||||
still have trouble, please open an `issue on GitHub`_ so I can fill in the
|
||||
gaps.
|
||||
|
||||
@@ -28,6 +28,7 @@ or just download the tarball and go that route:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
$ cd to the directory where you want to run Paperless
|
||||
$ wget https://github.com/danielquinn/paperless/archive/master.zip
|
||||
$ unzip master.zip
|
||||
$ cd paperless-master
|
||||
@@ -38,103 +39,78 @@ or just download the tarball and go that route:
|
||||
Installation & Configuration
|
||||
----------------------------
|
||||
|
||||
You can go multiple routes with setting up and running Paperless. The `Vagrant
|
||||
route`_ is quick & easy, but means you're running a VM which comes with memory
|
||||
consumption etc. We also `support Docker`_, which you can use natively under
|
||||
Linux and in a VM with `Docker Machine`_ (this guide was written for native
|
||||
Docker usage under Linux, you might have to adapt it for Docker Machine.)
|
||||
Alternatively the standard, `bare metal`_ approach is a little more
|
||||
complicated, but worth it because it makes it easier should you want to
|
||||
contribute some code back.
|
||||
You can go multiple routes with setting up and running Paperless:
|
||||
|
||||
* The `bare metal route`_
|
||||
* The `vagrant route`_
|
||||
* The `docker route`_
|
||||
|
||||
|
||||
The `Vagrant route`_ is quick & easy, but means you're running a VM which comes
|
||||
with memory consumption, cpu overhead etc. The `docker route`_ offers the same
|
||||
simplicity as Vagrant with lower resource consumption.
|
||||
|
||||
The `bare metal route`_ is a bit more complicated to setup but makes it easier
|
||||
should you want to contribute some code back.
|
||||
|
||||
.. _Vagrant route: setup-installation-vagrant_
|
||||
.. _support Docker: setup-installation-docker_
|
||||
.. _bare metal: setup-installation-standard_
|
||||
.. _docker route: setup-installation-docker_
|
||||
.. _bare metal route: setup-installation-bare-metal_
|
||||
.. _Docker Machine: https://docs.docker.com/machine/
|
||||
|
||||
|
||||
.. _setup-installation-standard:
|
||||
.. _setup-installation-bare-metal:
|
||||
|
||||
Standard (Bare Metal)
|
||||
.....................
|
||||
+++++++++++++++++++++
|
||||
|
||||
1. Install the requirements as per the :ref:`requirements <requirements>` page.
|
||||
2. Change to the ``src`` directory in this repo.
|
||||
3. Copy ``paperless.conf.example`` to ``/etc/paperless.conf`` and open it in
|
||||
your favourite editor. Set the values for:
|
||||
2. Within the extract of master.zip go to the ``src`` directory.
|
||||
3. Copy ``../paperless.conf.example`` to ``/etc/paperless.conf`` and open it in
|
||||
your favourite editor. As this file contains passwords. It should only be
|
||||
readable by user root and paperless! Set the values for:
|
||||
|
||||
Set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document.
|
||||
* ``PAPERLESS_OCR_THREADS``: this is the number of threads the OCR process
|
||||
will spawn to process document pages in parallel.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is only required if you want to use GPG to
|
||||
encrypt your document files. This is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original documents. Don't worry about defining this
|
||||
if you don't want to use encryption (the default).
|
||||
|
||||
4. Initialise the database with ``./manage.py migrate``.
|
||||
4. Initialise the SQLite database with ``./manage.py migrate``.
|
||||
5. Create a user for your Paperless instance with
|
||||
``./manage.py createsuperuser``. Follow the prompts to create your user.
|
||||
6. Start the webserver with ``./manage.py runserver <IP>:<PORT>``.
|
||||
If no specifc IP or port are given, the default is ``127.0.0.1:8000``.
|
||||
You should now be able to visit your (empty) `Paperless webserver`_ at
|
||||
``127.0.0.1:8000`` (or whatever you chose). You can login with the
|
||||
If no specifc IP or port are given, the default is ``127.0.0.1:8000``
|
||||
also known as http://localhost:8000/.
|
||||
You should now be able to visit your (empty) installation at
|
||||
`Paperless webserver`_ or whatever you chose before. You can login with the
|
||||
user/pass you created in #5.
|
||||
|
||||
7. In a separate window, change to the ``src`` directory in this repo again,
|
||||
but this time, you should start the consumer script with
|
||||
``./manage.py document_consumer``.
|
||||
8. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
8. Scan something or put a file into the ``CONSUMPTION_DIR``.
|
||||
9. Wait a few minutes
|
||||
10. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. caution::
|
||||
|
||||
This installation is not secure. Once everything is working head over to
|
||||
`Making things more permanent`_
|
||||
|
||||
.. _Paperless webserver: http://127.0.0.1:8000
|
||||
|
||||
|
||||
.. _setup-installation-vagrant:
|
||||
|
||||
Vagrant Method
|
||||
..............
|
||||
|
||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||
provisioned...
|
||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||
``/etc/paperless.conf`` and set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: this is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: this is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document.
|
||||
* ``PAPERLESS_SHARED_SECRET``: this is the "magic word" used when consuming
|
||||
documents from mail or via the API. If you don't use either, leaving it
|
||||
blank is just fine.
|
||||
|
||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||
updates the environment to make use of the changes you made to the config
|
||||
file.
|
||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||
create your user.
|
||||
7. Start the webserver with
|
||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||
You can login with the user/pass you created in #6.
|
||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||
your vagrant instance, you should start the consumer script with
|
||||
``/opt/paperless/src/manage.py document_consumer``.
|
||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
10. Wait a few minutes
|
||||
11. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. _Vagrant: https://vagrantup.com/
|
||||
.. _Paperless server: http://172.28.128.4:8000
|
||||
|
||||
.. _Making things more permanent: setup-permanent_
|
||||
|
||||
.. _setup-installation-docker:
|
||||
|
||||
Docker Method
|
||||
.............
|
||||
+++++++++++++
|
||||
|
||||
1. Install `Docker`_.
|
||||
|
||||
@@ -169,12 +145,14 @@ Docker Method
|
||||
modified versions of the configuration files.
|
||||
4. Modify ``docker-compose.yml`` to your preferences, following the
|
||||
instructions in comments in the file. The only change that is a hard
|
||||
requirement is to specify where the consumption directory should mount.
|
||||
requirement is to specify where the consumption directory should
|
||||
mount.[#dockercomposeyml]_
|
||||
5. Modify ``docker-compose.env`` and adapt the following environment variables:
|
||||
|
||||
``PAPERLESS_PASSPHRASE``
|
||||
This is the passphrase Paperless uses to encrypt/decrypt the original
|
||||
document.
|
||||
document. If you aren't planning on using GPG encryption, you can just
|
||||
leave this undefined.
|
||||
|
||||
``PAPERLESS_OCR_THREADS``
|
||||
This is the number of threads the OCR process will spawn to process
|
||||
@@ -186,7 +164,7 @@ Docker Method
|
||||
default English, set this parameter to a space separated list of
|
||||
three-letter language-codes after `ISO 639-2/T`_. For a list of available
|
||||
languages -- including their three letter codes -- see the
|
||||
`Debian packagelist`_.
|
||||
`Alpine packagelist`_.
|
||||
|
||||
``USERMAP_UID`` and ``USERMAP_GID``
|
||||
If you want to mount the consumption volume (directory ``/consume`` within
|
||||
@@ -276,121 +254,105 @@ Docker Method
|
||||
.. _Docker: https://www.docker.com/
|
||||
.. _docker-compose: https://docs.docker.com/compose/install/
|
||||
.. _ISO 639-2/T: https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes
|
||||
.. _Debian packagelist: https://packages.debian.org/search?suite=jessie&searchon=names&keywords=tesseract-ocr-
|
||||
.. _Alpine packagelist: https://pkgs.alpinelinux.org/packages?name=tesseract-ocr-data*&arch=x86_64
|
||||
|
||||
.. [#compose] You of course don't have to use docker-compose, but it
|
||||
simplifies deployment immensely. If you know your way around Docker, feel
|
||||
free to tinker around without using compose!
|
||||
|
||||
.. [#dockercomposeyml] If you're upgrading your docker-compose images from
|
||||
version 1.1.0 or earlier, you might need to change in the
|
||||
``docker-compose.yml`` file the ``image: pitkley/paperless`` directive in
|
||||
both the ``webserver`` and ``consumer`` sections to ``build: ./`` as per the
|
||||
newer ``docker-compose.yml.example`` file
|
||||
|
||||
|
||||
.. _setup-installation-vagrant:
|
||||
|
||||
Vagrant Method
|
||||
++++++++++++++
|
||||
|
||||
1. Install `Vagrant`_. How you do that is really between you and your OS.
|
||||
2. Run ``vagrant up``. An instance will start up for you. When it's ready and
|
||||
provisioned...
|
||||
3. Run ``vagrant ssh`` and once inside your new vagrant box, edit
|
||||
``/etc/paperless.conf`` and set the values for:
|
||||
|
||||
* ``PAPERLESS_CONSUMPTION_DIR``: This is where your documents will be
|
||||
dumped to be consumed by Paperless.
|
||||
* ``PAPERLESS_PASSPHRASE``: This is the passphrase Paperless uses to
|
||||
encrypt/decrypt the original document. It's only required if you want
|
||||
your original files to be encrypted, otherwise, just leave it unset.
|
||||
* ``PAPERLESS_EMAIL_SECRET``: this is the "magic word" used when consuming
|
||||
documents from mail or via the API. If you don't use either, leaving it
|
||||
blank is just fine.
|
||||
|
||||
4. Exit the vagrant box and re-enter it with ``vagrant ssh`` again. This
|
||||
updates the environment to make use of the changes you made to the config
|
||||
file.
|
||||
5. Initialise the database with ``/opt/paperless/src/manage.py migrate``.
|
||||
6. Still inside your vagrant box, create a user for your Paperless instance
|
||||
with ``/opt/paperless/src/manage.py createsuperuser``. Follow the prompts to
|
||||
create your user.
|
||||
7. Start the webserver with
|
||||
``/opt/paperless/src/manage.py runserver 0.0.0.0:8000``. You should now be
|
||||
able to visit your (empty) `Paperless webserver`_ at ``172.28.128.4:8000``.
|
||||
You can login with the user/pass you created in #6.
|
||||
8. In a separate window, run ``vagrant ssh`` again, but this time once inside
|
||||
your vagrant instance, you should start the consumer script with
|
||||
``/opt/paperless/src/manage.py document_consumer``.
|
||||
9. Scan something. Put it in the ``CONSUMPTION_DIR``.
|
||||
10. Wait a few minutes
|
||||
11. Visit the document list on your webserver, and it should be there, indexed
|
||||
and downloadable.
|
||||
|
||||
.. caution::
|
||||
|
||||
This installation is not secure. Once everything is working head up to
|
||||
`Making things more permanent`_
|
||||
|
||||
.. _Vagrant: https://vagrantup.com/
|
||||
.. _Paperless server: http://172.28.128.4:8000
|
||||
|
||||
|
||||
.. _setup-permanent:
|
||||
|
||||
Making Things a Little more Permanent
|
||||
-------------------------------------
|
||||
|
||||
Once you've tested things and are happy with the work flow, you can automate
|
||||
the process of starting the webserver and consumer automatically.
|
||||
Once you've tested things and are happy with the work flow, you should secure
|
||||
the installation and automate the process of starting the webserver and
|
||||
consumer.
|
||||
|
||||
|
||||
.. _setup-permanent-standard-systemd:
|
||||
|
||||
Standard (Bare Metal, Systemd)
|
||||
..............................
|
||||
|
||||
If you're running on a bare metal system that's using Systemd, you can use the
|
||||
service unit files in the ``scripts`` directory to set this up. You'll need to
|
||||
create a user called ``paperless`` and setup Paperless to be in a place that
|
||||
this new user can read and write to. Be sure to edit the service scripts to point
|
||||
to the proper location of your paperless install, referencing the appropriate Python
|
||||
binary. For example: ``ExecStart=/path/to/python3 /path/to/paperless/src/manage.py document_consumer``.
|
||||
If you don't want to make a new user, you can change the ``Group`` and ``User`` variables
|
||||
accordingly.
|
||||
|
||||
Then, you can just tell Systemd as ``root`` (or using ``sudo``) to enable the two ``.service`` files::
|
||||
|
||||
# systemctl enable /path/to/paperless/scripts/paperless-consumer.service
|
||||
# systemctl enable /path/to/paperless/scripts/paperless-webserver.service
|
||||
# systemctl start paperless-consumer
|
||||
# systemctl start paperless-webserver
|
||||
|
||||
|
||||
.. _setup-permanent-standard-ubuntu14:
|
||||
|
||||
Ubuntu 14.04 (Bare Metal, Upstart)
|
||||
..................................
|
||||
|
||||
Ubuntu 14.04 and earlier use the `Upstart`_ init system to start services
|
||||
during the boot process. To configure Upstart to run Paperless automatically
|
||||
after restarting your system:
|
||||
|
||||
1. Change to the directory where Upstart's configuration files are kept:
|
||||
``cd /etc/init``
|
||||
2. Create a new file: ``sudo nano paperless-server.conf``
|
||||
3. In the newly-created file enter::
|
||||
|
||||
start on (local-filesystems and net-device-up IFACE=eth0)
|
||||
stop on shutdown
|
||||
|
||||
respawn
|
||||
respawn limit 10 5
|
||||
|
||||
script
|
||||
exec /srv/paperless/src/manage.py runserver 0.0.0.0:80
|
||||
end script
|
||||
|
||||
Note that you'll need to replace ``/srv/paperless/src/manage.py`` with the
|
||||
path to the ``manage.py`` script in your installation directory.
|
||||
|
||||
If you are using a network interface other than ``eth0``, you will have to
|
||||
change ``IFACE=eth0``. For example, if you are connected via WiFi, you will
|
||||
likely need to replace ``eth0`` above with ``wlan0``. To see all interfaces,
|
||||
run ``ifconfig``.
|
||||
|
||||
Save the file.
|
||||
|
||||
4. Create a new file: ``sudo nano paperless-consumer.conf``
|
||||
|
||||
5. In the newly-created file enter::
|
||||
|
||||
start on (local-filesystems and net-device-up IFACE=eth0)
|
||||
stop on shutdown
|
||||
|
||||
respawn
|
||||
respawn limit 10 5
|
||||
|
||||
script
|
||||
exec /srv/paperless/src/manage.py document_consumer
|
||||
end script
|
||||
|
||||
Replace ``/srv/paperless/src/manage.py`` with the same values as in step 3
|
||||
above and replace ``eth0`` with the appropriate value, if necessary. Save the
|
||||
file.
|
||||
|
||||
These two configuration files together will start both the Paperless webserver
|
||||
and document consumer processes when the file system and network interface
|
||||
specified is available after boot. Furthermore, if either process ever exits
|
||||
unexpectedly, Upstart will try to restart it a maximum of 10 times within a 5
|
||||
second period.
|
||||
|
||||
.. _Upstart: http://upstart.ubuntu.com/
|
||||
|
||||
|
||||
.. _setup-permanent-vagrant:
|
||||
|
||||
.. _setup-permanent-webserver:
|
||||
|
||||
Using a Real Webserver
|
||||
......................
|
||||
++++++++++++++++++++++
|
||||
|
||||
The default is to use Django's development server, as that's easy and does the
|
||||
job well enough on a home network. However, if you want to do things right,
|
||||
it's probably a good idea to use a webserver capable of handling more than one
|
||||
thread.
|
||||
job well enough on a home network. However it is heavily discouraged to use
|
||||
it for more than that.
|
||||
|
||||
If you want to do things right you should use a real webserver capable of
|
||||
handling more than one thread. You will also have to let the webserver serve
|
||||
the static files (CSS, JavaScript) from the directory configured in
|
||||
``PAPERLESS_STATICDIR``. The default static files directory is ``../static``.
|
||||
|
||||
For that you need to activate your virtual environment and collect the static
|
||||
files with the command:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
$ cd <paperless directory>/src
|
||||
$ ./manage.py collectstatic
|
||||
|
||||
|
||||
Apache
|
||||
~~~~~~
|
||||
|
||||
This is a configuration supplied by `steckerhalter`_ on GitHub. It uses Apache
|
||||
and mod_wsgi, with a Paperless installation in /home/paperless/:
|
||||
and mod_wsgi, with a Paperless installation in ``/home/paperless/``:
|
||||
|
||||
.. code:: apache
|
||||
|
||||
@@ -421,141 +383,147 @@ Nginx + Gunicorn
|
||||
|
||||
If you're using Nginx, the most common setup is to combine it with a
|
||||
Python-based server like Gunicorn so that Nginx is acting as a proxy. Below is
|
||||
a copy of a simple Nginx configuration fragment making use of SSL and IPv6 to
|
||||
refer to a gunicorn instance listening on a local Unix socket:
|
||||
a copy of a simple Nginx configuration fragment making use of a gunicorn
|
||||
instance listening on localhost port 8000.
|
||||
|
||||
.. code:: nginx
|
||||
|
||||
upstream transfer_server {
|
||||
server unix:/run/example.com/gunicorn.sock fail_timeout=0;
|
||||
}
|
||||
|
||||
# Redirect requests on port 80 to 443
|
||||
server {
|
||||
listen 80;
|
||||
listen [::]:80;
|
||||
server_name example.com;
|
||||
rewrite ^ https://$server_name$request_uri? permanent;
|
||||
listen 80;
|
||||
|
||||
index index.html index.htm index.php;
|
||||
access_log /var/log/nginx/paperless_access.log;
|
||||
error_log /var/log/nginx/paperless_error.log;
|
||||
|
||||
location /static {
|
||||
|
||||
autoindex on;
|
||||
alias <path-to-paperless-static-directory>
|
||||
|
||||
}
|
||||
|
||||
location / {
|
||||
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header X-Forwarded-Proto $scheme;
|
||||
|
||||
proxy_pass http://127.0.0.1:8000
|
||||
}
|
||||
}
|
||||
|
||||
server {
|
||||
|
||||
listen 443 ssl;
|
||||
listen [::]:443;
|
||||
client_max_body_size 4G;
|
||||
server_name example.com;
|
||||
keepalive_timeout 5;
|
||||
root /var/www/example.com;
|
||||
The gunicorn server can be started with the command:
|
||||
|
||||
ssl on;
|
||||
.. code-block:: shell
|
||||
|
||||
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem;
|
||||
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
|
||||
ssl_trusted_certificate /etc/letsencrypt/live/example.com/fullchain.pem;
|
||||
ssl_session_timeout 1d;
|
||||
ssl_session_cache shared:SSL:50m;
|
||||
$ <path-to-paperless-virtual-environment>/bin/gunicorn <path-to-paperless>/src/paperless.wsgi -w 2
|
||||
|
||||
# Diffie-Hellman parameter for DHE ciphersuites, recommended 2048 bits
|
||||
# Generate with:
|
||||
# openssl dhparam -out /etc/nginx/dhparam.pem 2048
|
||||
ssl_dhparam /etc/nginx/dhparam.pem;
|
||||
|
||||
# What Mozilla calls "Intermediate configuration"
|
||||
# Copied from https://mozilla.github.io/server-side-tls/ssl-config-generator/
|
||||
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
|
||||
ssl_ciphers 'ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS';
|
||||
ssl_prefer_server_ciphers on;
|
||||
.. _setup-permanent-standard-systemd:
|
||||
|
||||
add_header Strict-Transport-Security max-age=15768000;
|
||||
Standard (Bare Metal + Systemd)
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
ssl_stapling on;
|
||||
ssl_stapling_verify on;
|
||||
If you're running on a bare metal system that's using Systemd, you can use the
|
||||
service unit files in the ``scripts`` directory to set this up.
|
||||
|
||||
access_log /var/log/nginx/example.com.log main;
|
||||
error_log /var/log/nginx/example.com.err info;
|
||||
1. You'll need to create a group and user called ``paperless`` (without login)
|
||||
2. Setup Paperless to be in a place that this new user can read and write to.
|
||||
3. Ensure ``/etc/paperless`` is readable by the ``paperless`` user.
|
||||
4. Copy the service file from the ``scripts`` directory to
|
||||
``/etc/systemd/system``.
|
||||
|
||||
location / {
|
||||
try_files $uri @proxy_to_app;
|
||||
}
|
||||
.. code-block:: bash
|
||||
|
||||
location @proxy_to_app {
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header X-Forwarded-Proto https;
|
||||
proxy_set_header Host $host;
|
||||
proxy_redirect off;
|
||||
proxy_pass http://transfer_server;
|
||||
}
|
||||
$ cp /path/to/paperless/scripts/paperless-consumer.service /etc/systemd/system/
|
||||
$ cp /path/to/paperless/scripts/paperless-webserver.service /etc/systemd/system/
|
||||
|
||||
}
|
||||
5. Edit the service file to point the ``ExecStart`` line to the proper location
|
||||
of your paperless install, referencing the appropriate Python binary. For
|
||||
example:
|
||||
``ExecStart=/path/to/python3 /path/to/paperless/src/manage.py document_consumer``.
|
||||
6. Start and enable (so they start on boot) the services.
|
||||
|
||||
Once you've got Nginx configured, you'll want to have a configuration file for
|
||||
your gunicorn instance. This should do the trick:
|
||||
.. code-block:: bash
|
||||
|
||||
.. code:: python
|
||||
$ systemctl enable paperless-consumer
|
||||
$ systemctl enable paperless-webserver
|
||||
$ systemctl start paperless-consumer
|
||||
$ systemctl start paperless-webserver
|
||||
|
||||
import os
|
||||
|
||||
bind = 'unix:/run/example.com/gunicorn.sock'
|
||||
backlog = 2048
|
||||
workers = 6
|
||||
worker_class = 'sync'
|
||||
worker_connections = 1000
|
||||
timeout = 30
|
||||
keepalive = 2
|
||||
debug = False
|
||||
spew = False
|
||||
daemon = False
|
||||
pidfile = None
|
||||
umask = 0
|
||||
user = None
|
||||
group = None
|
||||
tmp_upload_dir = None
|
||||
errorlog = '/var/log/example.com/gunicorn.err'
|
||||
loglevel = 'warning'
|
||||
accesslog = '/var/log/example.com/gunicorn.log'
|
||||
proc_name = None
|
||||
.. _setup-permanent-standard-upstart:
|
||||
|
||||
def post_fork(server, worker):
|
||||
server.log.info("Worker spawned (pid: %s)", worker.pid)
|
||||
Standard (Bare Metal + Upstart)
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
def pre_fork(server, worker):
|
||||
pass
|
||||
Ubuntu 14.04 and earlier use the `Upstart`_ init system to start services
|
||||
during the boot process. To configure Upstart to run Paperless automatically
|
||||
after restarting your system:
|
||||
|
||||
def pre_exec(server):
|
||||
server.log.info("Forked child, re-executing.")
|
||||
1. Change to the directory where Upstart's configuration files are kept:
|
||||
``cd /etc/init``
|
||||
2. Create a new file: ``sudo nano paperless-server.conf``
|
||||
3. In the newly-created file enter::
|
||||
|
||||
def when_ready(server):
|
||||
server.log.info("Server is ready. Spawning workers")
|
||||
start on (local-filesystems and net-device-up IFACE=eth0)
|
||||
stop on shutdown
|
||||
|
||||
def worker_int(worker):
|
||||
worker.log.info("worker received INT or QUIT signal")
|
||||
respawn
|
||||
respawn limit 10 5
|
||||
|
||||
## get traceback info
|
||||
import threading, sys, traceback
|
||||
id2name = dict([(th.ident, th.name) for th in threading.enumerate()])
|
||||
code = []
|
||||
for threadId, stack in sys._current_frames().items():
|
||||
code.append("\n# Thread: %s(%d)" % (id2name.get(threadId,""),
|
||||
threadId))
|
||||
for filename, lineno, name, line in traceback.extract_stack(stack):
|
||||
code.append('File: "%s", line %d, in %s' % (filename,
|
||||
lineno, name))
|
||||
if line:
|
||||
code.append(" %s" % (line.strip()))
|
||||
worker.log.debug("\n".join(code))
|
||||
script
|
||||
exec <path to paperless virtual environment>/bin/gunicorn <path to parperless>/src/paperless.wsgi -w 2
|
||||
end script
|
||||
|
||||
Note that you'll need to replace ``/srv/paperless/src/manage.py`` with the
|
||||
path to the ``manage.py`` script in your installation directory.
|
||||
|
||||
If you are using a network interface other than ``eth0``, you will have to
|
||||
change ``IFACE=eth0``. For example, if you are connected via WiFi, you will
|
||||
likely need to replace ``eth0`` above with ``wlan0``. To see all interfaces,
|
||||
run ``ifconfig -a``.
|
||||
|
||||
Save the file.
|
||||
|
||||
4. Create a new file: ``sudo nano paperless-consumer.conf``
|
||||
|
||||
5. In the newly-created file enter::
|
||||
|
||||
start on (local-filesystems and net-device-up IFACE=eth0)
|
||||
stop on shutdown
|
||||
|
||||
respawn
|
||||
respawn limit 10 5
|
||||
|
||||
script
|
||||
exec <path to paperless virtual environment>/bin/python <path to parperless>/manage.py document_consumer
|
||||
end script
|
||||
|
||||
Replace the path placeholder and ``eth0`` with the appropriate value and save the file.
|
||||
|
||||
These two configuration files together will start both the Paperless webserver
|
||||
and document consumer processes when the file system and network interface
|
||||
specified is available after boot. Furthermore, if either process ever exits
|
||||
unexpectedly, Upstart will try to restart it a maximum of 10 times within a 5
|
||||
second period.
|
||||
|
||||
.. _Upstart: http://upstart.ubuntu.com/
|
||||
|
||||
def worker_abort(worker):
|
||||
worker.log.info("worker received SIGABRT signal")
|
||||
|
||||
Vagrant
|
||||
.......
|
||||
~~~~~~~
|
||||
|
||||
You may use the Ubuntu explanation above. Replace
|
||||
``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||
|
||||
You may use the Ubuntu explanation above. Replace ``(local-filesystems and net-device-up IFACE=eth0)`` with ``vagrant-mounted``.
|
||||
|
||||
.. _setup-permanent-docker:
|
||||
|
||||
Docker
|
||||
......
|
||||
~~~~~~
|
||||
|
||||
If you're using Docker, you can set a restart-policy_ in the
|
||||
``docker-compose.yml`` to have the containers automatically start with the
|
||||
|
||||
@@ -33,8 +33,11 @@ The webserver is started via the ``manage.py`` script:
|
||||
By default, the server runs on localhost, port 8000, but you can change this
|
||||
with a few arguments, run ``manage.py --help`` for more information.
|
||||
|
||||
Note that this command runs continuously, so exiting it will mean your webserver
|
||||
disappears. If you want to run this full-time (which is kind of the point)
|
||||
Add the option ``--noreload`` to reduce resource usage. Otherwise, the server
|
||||
continuously polls all source files for changes to auto-reload them.
|
||||
|
||||
Note that when exiting this command your webserver will disappear.
|
||||
If you want to run this full-time (which is kind of the point)
|
||||
you'll need to have it start in the background -- something you'll need to
|
||||
figure out for your own system. To get you started though, there are Systemd
|
||||
service files in the ``scripts`` directory.
|
||||
@@ -46,17 +49,18 @@ The Consumer
|
||||
------------
|
||||
|
||||
The consumer script runs in an infinite loop, constantly looking at a directory
|
||||
for PDF files to parse and index. The process is pretty straightforward:
|
||||
for documents to parse and index. The process is pretty straightforward:
|
||||
|
||||
1. Look in ``CONSUMPTION_DIR`` for a PDF. If one is found, go to #2. If not,
|
||||
wait 10 seconds and try again.
|
||||
2. Parse the PDF with Tesseract
|
||||
1. Look in ``CONSUMPTION_DIR`` for a document. If one is found, go to #2.
|
||||
If not, wait 10 seconds and try again. On Linux, new documents are detected
|
||||
instantly via inotify, so there's no waiting involved.
|
||||
2. Parse the document with Tesseract
|
||||
3. Create a new record in the database with the OCR'd text
|
||||
4. Attempt to automatically assign document attributes by doing some guesswork.
|
||||
Read up on the :ref:`guesswork documentation<guesswork>` for more
|
||||
information about this process.
|
||||
5. Encrypt the PDF and store it in the ``media`` directory under
|
||||
``documents/pdf``.
|
||||
5. Encrypt the document (if you have a passphrase set) and store it in the
|
||||
``media`` directory under ``documents/originals``.
|
||||
6. Go to #1.
|
||||
|
||||
|
||||
@@ -71,8 +75,8 @@ The consumer is started via the ``manage.py`` script:
|
||||
|
||||
$ /path/to/paperless/src/manage.py document_consumer
|
||||
|
||||
This starts the service that will run in a loop, consuming PDF files as they
|
||||
appear in ``CONSUMPTION_DIR``.
|
||||
This starts the service that will consume documents as they appear in
|
||||
``CONSUMPTION_DIR``.
|
||||
|
||||
Note that this command runs continuously, so exiting it will mean your webserver
|
||||
disappears. If you want to run this full-time (which is kind of the point)
|
||||
@@ -80,6 +84,13 @@ you'll need to have it start in the background -- something you'll need to
|
||||
figure out for your own system. To get you started though, there are Systemd
|
||||
service files in the ``scripts`` directory.
|
||||
|
||||
Some command line arguments are available to customize the behavior of the
|
||||
consumer. By default it will use ``/etc/paperless.conf`` values. Display the
|
||||
help with:
|
||||
|
||||
.. code-block:: shell-session
|
||||
|
||||
$ /path/to/paperless/src/manage.py document_consumer --help
|
||||
|
||||
.. _utilities-exporter:
|
||||
|
||||
@@ -87,8 +98,8 @@ The Exporter
|
||||
------------
|
||||
|
||||
Tired of fiddling with Paperless, or just want to do something stupid and are
|
||||
afraid of accidentally damaging your files? You can export all of your PDFs
|
||||
into neatly named, dated, and unencrypted.
|
||||
afraid of accidentally damaging your files? You can export all of your
|
||||
documents into neatly named, dated, and unencrypted files.
|
||||
|
||||
|
||||
.. _utilities-exporter-howto:
|
||||
@@ -102,10 +113,10 @@ This too is done via the ``manage.py`` script:
|
||||
|
||||
$ /path/to/paperless/src/manage.py document_exporter /path/to/somewhere/
|
||||
|
||||
This will dump all of your unencrypted PDFs into ``/path/to/somewhere`` for you
|
||||
to do with as you please. The files are accompanied with a special file,
|
||||
``manifest.json`` which can be used to
|
||||
:ref:`import the files <utilities-importer>` at a later date if you wish.
|
||||
This will dump all of your unencrypted documents into ``/path/to/somewhere``
|
||||
for you to do with as you please. The files are accompanied with a special
|
||||
file, ``manifest.json`` which can be used to :ref:`import the files
|
||||
<utilities-importer>` at a later date if you wish.
|
||||
|
||||
|
||||
.. _utilities-exporter-howto-docker:
|
||||
|
||||
@@ -1,11 +1,43 @@
|
||||
# Sample paperless.conf
|
||||
# Copy this file to /etc/paperless.conf and modify it to suit your needs.
|
||||
# As this file contains passwords it should only be readable by the user
|
||||
# running paperless.
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Paths & Folders ####
|
||||
###############################################################################
|
||||
|
||||
# This where your documents should go to be consumed. Make sure that it exists
|
||||
# and that the user running the paperless service can read/write its contents
|
||||
# before you start Paperless.
|
||||
PAPERLESS_CONSUMPTION_DIR=""
|
||||
|
||||
|
||||
# You can specify where you want the SQLite database to be stored instead of
|
||||
# the default location of /data/ within the install directory.
|
||||
#PAPERLESS_DBDIR=/path/to/database/file
|
||||
|
||||
|
||||
# Override the default MEDIA_ROOT here. This is where all files are stored.
|
||||
# The default location is /media/documents/ within the install folder.
|
||||
#PAPERLESS_MEDIADIR=/path/to/media
|
||||
|
||||
|
||||
# Override the default STATIC_ROOT here. This is where all static files
|
||||
# created using "collectstatic" manager command are stored.
|
||||
#PAPERLESS_STATICDIR=""
|
||||
|
||||
|
||||
# Override the MEDIA_URL here. Unless you're hosting Paperless off a subdomain
|
||||
# like /paperless/, you probably don't need to change this.
|
||||
#PAPERLESS_MEDIA_URL="/media/"
|
||||
|
||||
# Override the STATIC_URL here. Unless you're hosting Paperless off a
|
||||
# subdomain like /paperless/, you probably don't need to change this.
|
||||
#PAPERLESS_STATIC_URL="/static/"
|
||||
|
||||
|
||||
# These values are required if you want paperless to check a particular email
|
||||
# box every 10 minutes and attempt to consume documents from there. If you
|
||||
# don't define a HOST, mail checking will just be disabled.
|
||||
@@ -14,88 +46,44 @@ PAPERLESS_CONSUME_MAIL_PORT=""
|
||||
PAPERLESS_CONSUME_MAIL_USER=""
|
||||
PAPERLESS_CONSUME_MAIL_PASS=""
|
||||
|
||||
# You must have a passphrase in order for Paperless to work at all. If you set
|
||||
# this to "", GNUGPG will "encrypt" your PDF by writing it out as a zero-byte
|
||||
# file.
|
||||
#
|
||||
# The passphrase you use here will be used when storing your documents in
|
||||
# Paperless, but you can always export them in an unencrypted format by using
|
||||
# document exporter. See the documentation for more information.
|
||||
# Override the default IMAP inbox here. If not set Paperless defaults to
|
||||
# "INBOX".
|
||||
#PAPERLESS_CONSUME_MAIL_INBOX="INBOX"
|
||||
|
||||
# Any email sent to the target account that does not contain this text will be
|
||||
# ignored.
|
||||
PAPERLESS_EMAIL_SECRET=""
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Security ####
|
||||
###############################################################################
|
||||
|
||||
# Controls whether django's debug mode is enabled. Disable this on production
|
||||
# systems. Debug mode is enabled by default.
|
||||
PAPERLESS_DEBUG="false"
|
||||
|
||||
|
||||
# Paperless can be instructed to attempt to encrypt your PDF files with GPG
|
||||
# using the PAPERLESS_PASSPHRASE specified below. If however you're not
|
||||
# concerned about encrypting these files (for example if you have disk
|
||||
# encryption locally) then you don't need this and can safely leave this value
|
||||
# un-set.
|
||||
#
|
||||
# One final note about the passphrase. Once you've consumed a document with
|
||||
# one passphrase, DON'T CHANGE IT. Paperless assumes this to be a constant and
|
||||
# can't properly export documents that were encrypted with an old passphrase if
|
||||
# you've since changed it to a new one.
|
||||
PAPERLESS_PASSPHRASE="secret"
|
||||
|
||||
# If you intend to consume documents either via HTTP POST or by email, you must
|
||||
# have a shared secret here.
|
||||
PAPERLESS_SHARED_SECRET=""
|
||||
|
||||
# After a document is consumed, Paperless can trigger an arbitrary script if
|
||||
# you like. This script will be passed a number of arguments for you to work
|
||||
# with. The default is blank, which means nothing will be executed. For more
|
||||
# information, take a look at the docs: http://paperless.readthedocs.org/en/latest/consumption.html#hooking-into-the-consumption-process
|
||||
#PAPERLESS_POST_CONSUME_SCRIPT="/path/to/an/arbitrary/script.sh"
|
||||
|
||||
|
||||
#
|
||||
# The following values use sensible defaults for modern systems, but if you're
|
||||
# running Paperless on a low-resource machine (like a Raspberry Pi), modifying
|
||||
# some of these values may be necessary.
|
||||
#
|
||||
# The default is to not use encryption at all.
|
||||
#PAPERLESS_PASSPHRASE="secret"
|
||||
|
||||
|
||||
# By default, Paperless will attempt to use all available CPU cores to process
|
||||
# a document, but if you would like to limit that, you can set this value to
|
||||
# an integer:
|
||||
#PAPERLESS_OCR_THREADS=1
|
||||
# The secret key has a default that should be fine so long as you're hosting
|
||||
# Paperless on a closed network. However, if you're putting this anywhere
|
||||
# public, you should change the key to something unique and verbose.
|
||||
#PAPERLESS_SECRET_KEY="change-me"
|
||||
|
||||
# On smaller systems, or even in the case of Very Large Documents, the consumer
|
||||
# may explode, complaining about how it's "unable to extent pixel cache". In
|
||||
# such cases, try setting this to a reasonably low value, like 32000000. The
|
||||
# default is to use whatever is necessary to do everything without writing to
|
||||
# disk, and units are in megabytes.
|
||||
#
|
||||
# For more information on how to use this value, you should probably search
|
||||
# the web for "MAGICK_MEMORY_LIMIT".
|
||||
#PAPERLESS_CONVERT_MEMORY_LIMIT=0
|
||||
|
||||
# By default the conversion density setting for documents is 300DPI, in some
|
||||
# cases it has proven useful to configure a lesser value.
|
||||
# This setting has a high impact on the physical size of tmp page files,
|
||||
# the speed of document conversion, and can affect the accuracy of OCR
|
||||
# results. Individual results can vary and this setting should be tested
|
||||
# thoroughly against the documents you are importing to see if it has any
|
||||
# impacts either negative or positive. Testing on limited document sets has
|
||||
# shown a setting of 200 can cut the size of tmp files by 1/3, and speed up
|
||||
# conversion by up to 4x with little impact to OCR accuracy.
|
||||
#PAPERLESS_CONVERT_DENSITY=300
|
||||
|
||||
# Similar to the memory limit, if you've got a small system and your OS mounts
|
||||
# /tmp as tmpfs, you should set this to a path that's on a physical disk, like
|
||||
# /home/your_user/tmp or something. ImageMagick will use this as scratch space
|
||||
# when crunching through very large documents.
|
||||
#
|
||||
# For more information on how to use this value, you should probably search
|
||||
# the web for "MAGICK_TMPDIR".
|
||||
#PAPERLESS_CONVERT_TMPDIR=/var/tmp/paperless
|
||||
|
||||
# You can specify where you want the SQLite database to be stored instead of
|
||||
# the default location
|
||||
#PAPERLESS_DBDIR=/path/to/database/file
|
||||
|
||||
# Override the default MEDIA_ROOT here. This is where all files are stored.
|
||||
#PAPERLESS_MEDIADIR=/path/to/media
|
||||
|
||||
# Override the default STATIC_ROOT here. This is where all static files created
|
||||
# using "collectstatic" manager command are stored.
|
||||
#PAPERLESS_STATICDIR=""
|
||||
|
||||
# The number of seconds that Paperless will wait between checking
|
||||
# PAPERLESS_CONSUMPTION_DIR. If you tend to write documents to this directory
|
||||
# very slowly, you may want to use a higher value than the default (10).
|
||||
# PAPERLESS_CONSUMER_LOOP_TIME=10
|
||||
|
||||
# If you're planning on putting Paperless on the open internet, then you
|
||||
# really should set this value to the domain name you're using. Failing to do
|
||||
@@ -106,22 +94,142 @@ PAPERLESS_SHARED_SECRET=""
|
||||
# as is "example.com,www.example.com", but NOT " example.com" or "example.com,"
|
||||
#PAPERLESS_ALLOWED_HOSTS="example.com,www.example.com"
|
||||
|
||||
# Override the default UTC time zone here
|
||||
# If you decide to use the Paperless API in an ajax call, you need to add your
|
||||
# servers to the list of allowed hosts that can do CORS calls. By default
|
||||
# Paperless allows calls from localhost:8080, but you'd like to change that,
|
||||
# you can set this value to a comma-separated list.
|
||||
#PAPERLESS_CORS_ALLOWED_HOSTS="localhost:8080,example.com,localhost:8000"
|
||||
|
||||
# To host paperless under a subpath url like example.com/paperless you set
|
||||
# this value to /paperless. No trailing slash!
|
||||
#
|
||||
# https://docs.djangoproject.com/en/1.11/ref/settings/#force-script-name
|
||||
#PAPERLESS_FORCE_SCRIPT_NAME=""
|
||||
|
||||
# If you are using alternative authentication means or are just using paperless
|
||||
# as a single user on a small private network, this option allows you to disable
|
||||
# user authentication if you set it to "true"
|
||||
#PAPERLESS_DISABLE_LOGIN="false"
|
||||
|
||||
###############################################################################
|
||||
#### Software Tweaks ####
|
||||
###############################################################################
|
||||
|
||||
# After a document is consumed, Paperless can trigger an arbitrary script if
|
||||
# you like. This script will be passed a number of arguments for you to work
|
||||
# with. The default is blank, which means nothing will be executed. For more
|
||||
# information, take a look at the docs:
|
||||
# http://paperless.readthedocs.org/en/latest/consumption.html#hooking-into-the-consumption-process
|
||||
#PAPERLESS_POST_CONSUME_SCRIPT="/path/to/an/arbitrary/script.sh"
|
||||
|
||||
# By default, when clicking on a document within the web interface, the
|
||||
# browser will prompt the user to save the document to disk. By setting this to
|
||||
# "true", the document will instead be opened in the browser, if possible.
|
||||
#PAPERLESS_INLINE_DOC="false"
|
||||
|
||||
#
|
||||
# The following values use sensible defaults for modern systems, but if you're
|
||||
# running Paperless on a low-resource device (like a Raspberry Pi), modifying
|
||||
# some of these values may be necessary.
|
||||
#
|
||||
|
||||
|
||||
# By default, Paperless will attempt to use all available CPU cores to process
|
||||
# a document, but if you would like to limit that, you can set this value to
|
||||
# an integer:
|
||||
#PAPERLESS_OCR_THREADS=1
|
||||
|
||||
|
||||
# Customize the default language that tesseract will attempt to use when
|
||||
# parsing documents. It should be a 3-letter language code consistent with ISO
|
||||
# 639: https://www.loc.gov/standards/iso639-2/php/code_list.php
|
||||
#PAPERLESS_OCR_LANGUAGE=eng
|
||||
|
||||
|
||||
# On smaller systems, or even in the case of Very Large Documents, the consumer
|
||||
# may explode, complaining about how it's "unable to extend pixel cache". In
|
||||
# such cases, try setting this to a reasonably low value, like 32000000. The
|
||||
# default is to use whatever is necessary to do everything without writing to
|
||||
# disk, and units are in megabytes.
|
||||
#
|
||||
# For more information on how to use this value, you should probably search
|
||||
# the web for "MAGICK_MEMORY_LIMIT".
|
||||
#PAPERLESS_CONVERT_MEMORY_LIMIT=0
|
||||
|
||||
|
||||
# Similar to the memory limit, if you've got a small system and your OS mounts
|
||||
# /tmp as tmpfs, you should set this to a path that's on a physical disk, like
|
||||
# /home/your_user/tmp or something. ImageMagick will use this as scratch space
|
||||
# when crunching through very large documents.
|
||||
#
|
||||
# For more information on how to use this value, you should probably search
|
||||
# the web for "MAGICK_TMPDIR".
|
||||
#PAPERLESS_CONVERT_TMPDIR=/var/tmp/paperless
|
||||
|
||||
|
||||
# By default the conversion density setting for documents is 300DPI, in some
|
||||
# cases it has proven useful to configure a lesser value.
|
||||
# This setting has a high impact on the physical size of tmp page files,
|
||||
# the speed of document conversion, and can affect the accuracy of OCR
|
||||
# results. Individual results can vary and this setting should be tested
|
||||
# thoroughly against the documents you are importing to see if it has any
|
||||
# impacts either negative or positive.
|
||||
# Testing on limited document sets has shown a setting of 200 can cut the
|
||||
# size of tmp files by 1/3, and speed up conversion by up to 4x
|
||||
# with little impact to OCR accuracy.
|
||||
#PAPERLESS_CONVERT_DENSITY=300
|
||||
|
||||
|
||||
# (This setting is ignored on Linux where inotify is used instead of a
|
||||
# polling loop.)
|
||||
# The number of seconds that Paperless will wait between checking
|
||||
# PAPERLESS_CONSUMPTION_DIR. If you tend to write documents to this directory
|
||||
# rarely, you may want to use a higher value than the default (10).
|
||||
#PAPERLESS_CONSUMER_LOOP_TIME=10
|
||||
|
||||
|
||||
###############################################################################
|
||||
#### Interface ####
|
||||
###############################################################################
|
||||
|
||||
# Override the default UTC time zone here.
|
||||
# See https://docs.djangoproject.com/en/1.10/ref/settings/#std:setting-TIME_ZONE
|
||||
# for details on how to set it.
|
||||
#PAPERLESS_TIME_ZONE=UTC
|
||||
|
||||
# Customize number of list items to show per page
|
||||
#PAPERLESS_LIST_PER_PAGE=50
|
||||
|
||||
# Customize the default language that tesseract will attempt to use when parsing
|
||||
# documents. It should be a 3-letter language code consistent with ISO 639.
|
||||
#PAPERLESS_OCR_LANGUAGE=eng
|
||||
# If set, Paperless will show document filters per financial year.
|
||||
# The dates must be in the format "mm-dd", for example "07-15" for July 15.
|
||||
#PAPERLESS_FINANCIAL_YEAR_START="mm-dd"
|
||||
#PAPERLESS_FINANCIAL_YEAR_END="mm-dd"
|
||||
|
||||
|
||||
# The number of items on each page in the web UI. This value must be a
|
||||
# positive integer, but if you don't define one in paperless.conf, a default of
|
||||
# 100 will be used.
|
||||
#PAPERLESS_LIST_PER_PAGE=100
|
||||
|
||||
# The secret key has a default that should be fine so long as you're hosting
|
||||
# Paperless on a closed network. However, if you're putting this anywhere
|
||||
# public, you should change the key to something unique and verbose.
|
||||
#PAPERLESS_SECRET_KEY="change-me"
|
||||
|
||||
# The number of years for which a correspondent will be included in the recent
|
||||
# correspondents filter.
|
||||
#PAPERLESS_RECENT_CORRESPONDENT_YEARS=1
|
||||
|
||||
###############################################################################
|
||||
#### Third-Party Binaries ####
|
||||
###############################################################################
|
||||
|
||||
# There are a few external software packages that Paperless expects to find on
|
||||
# your system when it starts up. Unless you've done something creative with
|
||||
# their installation, you probably won't need to edit any of these. However,
|
||||
# if you've installed these programs somewhere where simply typing the name of
|
||||
# the program doesn't automatically execute it (ie. the program isn't in your
|
||||
# $PATH), then you'll need to specify the literal path for that program here.
|
||||
|
||||
# Convert (part of the ImageMagick suite)
|
||||
#PAPERLESS_CONVERT_BINARY=/usr/bin/convert
|
||||
|
||||
# Unpaper
|
||||
#PAPERLESS_UNPAPER_BINARY=/usr/bin/unpaper
|
||||
|
||||
# Optipng (for optimising thumbnail sizes)
|
||||
#PAPERLESS_OPTIPNG_BINARY=/usr/bin/optipng
|
||||
|
||||
74
requirements.txt
Normal file → Executable file
74
requirements.txt
Normal file → Executable file
@@ -1,23 +1,51 @@
|
||||
Django==1.10.5
|
||||
Pillow>=3.1.1
|
||||
django-crispy-forms>=1.6.1
|
||||
django-extensions>=1.7.6
|
||||
django-filter>=1.0
|
||||
django-flat-responsive>=1.2.0
|
||||
djangorestframework>=3.5.3
|
||||
filemagic>=1.6
|
||||
langdetect>=1.0.7
|
||||
pyocr>=0.4.6
|
||||
python-dateutil>=2.6.0
|
||||
python-dotenv>=0.6.2
|
||||
python-gnupg>=0.3.9
|
||||
pytz>=2016.10
|
||||
gunicorn==19.6.0
|
||||
|
||||
# For the tests
|
||||
pytest
|
||||
pytest-django
|
||||
pytest-sugar
|
||||
pep8
|
||||
flake8
|
||||
tox
|
||||
-i https://pypi.python.org/simple
|
||||
apipkg==1.5; python_version != '3.3.*'
|
||||
atomicwrites==1.2.1; python_version != '3.3.*'
|
||||
attrs==18.2.0
|
||||
certifi==2018.8.24
|
||||
chardet==3.0.4
|
||||
coverage==4.5.1; python_version < '4'
|
||||
coveralls==1.5.0
|
||||
dateparser==0.7.0
|
||||
django-cors-headers==2.4.0
|
||||
django-crispy-forms==1.7.2
|
||||
django-extensions==2.1.2
|
||||
django-filter==2.0.0
|
||||
django==2.0.8
|
||||
djangorestframework==3.8.2
|
||||
docopt==0.6.2
|
||||
execnet==1.5.0; python_version != '3.3.*'
|
||||
factory-boy==2.11.1
|
||||
faker==0.9.0; python_version >= '2.7'
|
||||
filemagic==1.6
|
||||
fuzzywuzzy==0.15.0
|
||||
gunicorn==19.9.0
|
||||
idna==2.7
|
||||
inotify-simple==1.1.8
|
||||
langdetect==1.0.7
|
||||
more-itertools==4.3.0
|
||||
pdftotext==2.1.0
|
||||
pillow==5.2.0
|
||||
pluggy==0.7.1; python_version != '3.3.*'
|
||||
py==1.6.0; python_version != '3.3.*'
|
||||
pycodestyle==2.4.0
|
||||
pyocr==0.5.3
|
||||
pytest-cov==2.6.0
|
||||
pytest-django==3.4.2
|
||||
pytest-env==0.6.2
|
||||
pytest-forked==0.2; python_version != '3.3.*'
|
||||
pytest-sugar==0.9.1
|
||||
pytest-xdist==1.23.0
|
||||
pytest==3.8.0
|
||||
python-dateutil==2.7.3
|
||||
python-dotenv==0.9.1
|
||||
python-gnupg==0.4.3
|
||||
python-levenshtein==0.12.0
|
||||
pytz==2018.5
|
||||
regex==2018.8.29
|
||||
requests==2.19.1
|
||||
six==1.11.0
|
||||
termcolor==1.1.0
|
||||
text-unidecode==1.2
|
||||
tzlocal==1.5.1
|
||||
urllib3==1.23; python_version != '3.3.*'
|
||||
|
||||
@@ -4,44 +4,61 @@ set -e
|
||||
# Source: https://github.com/sameersbn/docker-gitlab/
|
||||
map_uidgid() {
|
||||
USERMAP_ORIG_UID=$(id -u paperless)
|
||||
USERMAP_ORIG_UID=$(id -g paperless)
|
||||
USERMAP_GID=${USERMAP_GID:-${USERMAP_UID:-$USERMAP_ORIG_GID}}
|
||||
USERMAP_UID=${USERMAP_UID:-$USERMAP_ORIG_UID}
|
||||
if [[ ${USERMAP_UID} != ${USERMAP_ORIG_UID} || ${USERMAP_GID} != ${USERMAP_ORIG_GID} ]]; then
|
||||
echo "Mapping UID and GID for paperless:paperless to $USERMAP_UID:$USERMAP_GID"
|
||||
groupmod -g ${USERMAP_GID} paperless
|
||||
sed -i -e "s|:${USERMAP_ORIG_UID}:${USERMAP_GID}:|:${USERMAP_UID}:${USERMAP_GID}:|" /etc/passwd
|
||||
USERMAP_ORIG_GID=$(id -g paperless)
|
||||
USERMAP_NEW_UID=${USERMAP_UID:-$USERMAP_ORIG_UID}
|
||||
USERMAP_NEW_GID=${USERMAP_GID:-${USERMAP_ORIG_GID:-$USERMAP_NEW_UID}}
|
||||
if [[ ${USERMAP_NEW_UID} != "${USERMAP_ORIG_UID}" || ${USERMAP_NEW_GID} != "${USERMAP_ORIG_GID}" ]]; then
|
||||
echo "Mapping UID and GID for paperless:paperless to $USERMAP_NEW_UID:$USERMAP_NEW_GID"
|
||||
usermod -u "${USERMAP_NEW_UID}" paperless
|
||||
groupmod -g "${USERMAP_NEW_GID}" paperless
|
||||
fi
|
||||
}
|
||||
|
||||
set_permissions() {
|
||||
# Set permissions for consumption directory
|
||||
chgrp paperless "$PAPERLESS_CONSUMPTION_DIR" || {
|
||||
echo "Changing group of consumption directory:"
|
||||
echo " $PAPERLESS_CONSUMPTION_DIR"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`o+x\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
chmod g+x "$PAPERLESS_CONSUMPTION_DIR" || {
|
||||
echo "Changing group permissions of consumption directory:"
|
||||
echo " $PAPERLESS_CONSUMPTION_DIR"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`o+x\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
|
||||
# Set permissions for consumption and export directory
|
||||
for dir in PAPERLESS_CONSUMPTION_DIR PAPERLESS_EXPORT_DIR; do
|
||||
# Extract the name of the current directory from $dir for the error message
|
||||
cur_dir_name=$(echo "$dir" | awk -F'_' '{ print tolower($2); }')
|
||||
chgrp paperless "${!dir}" || {
|
||||
echo "Changing group of ${cur_dir_name} directory:"
|
||||
echo " ${!dir}"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`g+wx\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
chmod g+wx "${!dir}" || {
|
||||
echo "Changing group permissions of ${cur_dir_name} directory:"
|
||||
echo " ${!dir}"
|
||||
echo "failed."
|
||||
echo ""
|
||||
echo "Either try to set it on your host-mounted directory"
|
||||
echo "directly, or make sure that the directory has \`g+wx\`"
|
||||
echo "permissions and the files in it at least \`o+r\`."
|
||||
} >&2
|
||||
done
|
||||
# Set permissions for application directory
|
||||
chown -Rh paperless:paperless /usr/src/paperless
|
||||
}
|
||||
|
||||
migrations() {
|
||||
# A simple lock file in case other containers use this startup
|
||||
LOCKFILE="/usr/src/paperless/data/db.sqlite3.migration"
|
||||
|
||||
# check for and create lock file in one command
|
||||
if (set -o noclobber; echo "$$" > "${LOCKFILE}") 2> /dev/null
|
||||
then
|
||||
trap 'rm -f "${LOCKFILE}"; exit $?' INT TERM EXIT
|
||||
sudo -HEu paperless "/usr/src/paperless/src/manage.py" "migrate"
|
||||
rm ${LOCKFILE}
|
||||
fi
|
||||
}
|
||||
|
||||
initialize() {
|
||||
map_uidgid
|
||||
set_permissions
|
||||
migrations
|
||||
}
|
||||
|
||||
install_languages() {
|
||||
@@ -53,25 +70,24 @@ install_languages() {
|
||||
return
|
||||
fi
|
||||
|
||||
# Update apt-lists
|
||||
apt-get update
|
||||
|
||||
# Loop over languages to be installed
|
||||
for lang in "${langs[@]}"; do
|
||||
pkg="tesseract-ocr-$lang"
|
||||
if dpkg -s "$pkg" 2>&1 > /dev/null; then
|
||||
pkg="tesseract-ocr-data-$lang"
|
||||
|
||||
# English is installed by default
|
||||
if [ "$lang" == "eng" ]; then
|
||||
continue
|
||||
fi
|
||||
|
||||
if ! apt-cache show "$pkg" 2>&1 > /dev/null; then
|
||||
if apk info -e "$pkg" > /dev/null 2>&1; then
|
||||
continue
|
||||
fi
|
||||
if ! apk info "$pkg" > /dev/null 2>&1; then
|
||||
continue
|
||||
fi
|
||||
|
||||
apt-get install "$pkg"
|
||||
apk --no-cache --update add "$pkg"
|
||||
done
|
||||
|
||||
# Remove apt lists
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
}
|
||||
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@ Description=Paperless webserver
|
||||
[Service]
|
||||
User=paperless
|
||||
Group=paperless
|
||||
ExecStart=/home/paperless/project/virtualenv/bin/python /home/paperless/project/src/manage.py runserver 0.0.0.0:8000
|
||||
ExecStart=/home/paperless/project/virtualenv/bin/gunicorn /home/paperless/project/src/paperless.wsgi -w 2
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
@@ -0,0 +1 @@
|
||||
from .checks import changed_password_check
|
||||
|
||||
146
src/documents/actions.py
Normal file
146
src/documents/actions.py
Normal file
@@ -0,0 +1,146 @@
|
||||
from django.contrib import messages
|
||||
from django.contrib.admin import helpers
|
||||
from django.contrib.admin.utils import model_ngettext
|
||||
from django.core.exceptions import PermissionDenied
|
||||
from django.template.response import TemplateResponse
|
||||
|
||||
from documents.models import Correspondent, Tag
|
||||
|
||||
|
||||
def select_action(
|
||||
modeladmin, request, queryset, title, action, modelclass,
|
||||
success_message="", document_action=None, queryset_action=None):
|
||||
|
||||
opts = modeladmin.model._meta
|
||||
app_label = opts.app_label
|
||||
|
||||
if not modeladmin.has_change_permission(request):
|
||||
raise PermissionDenied
|
||||
|
||||
if request.POST.get('post'):
|
||||
n = queryset.count()
|
||||
selected_object = modelclass.objects.get(id=request.POST.get('obj_id'))
|
||||
if n:
|
||||
for document in queryset:
|
||||
if document_action:
|
||||
document_action(document, selected_object)
|
||||
document_display = str(document)
|
||||
modeladmin.log_change(request, document, document_display)
|
||||
if queryset_action:
|
||||
queryset_action(queryset, selected_object)
|
||||
|
||||
modeladmin.message_user(request, success_message % {
|
||||
"selected_object": selected_object.name,
|
||||
"count": n,
|
||||
"items": model_ngettext(modeladmin.opts, n)
|
||||
}, messages.SUCCESS)
|
||||
|
||||
# Return None to display the change list page again.
|
||||
return None
|
||||
|
||||
context = dict(
|
||||
modeladmin.admin_site.each_context(request),
|
||||
title=title,
|
||||
queryset=queryset,
|
||||
opts=opts,
|
||||
action_checkbox_name=helpers.ACTION_CHECKBOX_NAME,
|
||||
media=modeladmin.media,
|
||||
action=action,
|
||||
objects=modelclass.objects.all(),
|
||||
itemname=model_ngettext(modelclass, 1)
|
||||
)
|
||||
|
||||
request.current_app = modeladmin.admin_site.name
|
||||
|
||||
return TemplateResponse(
|
||||
request,
|
||||
"admin/{}/{}/select_object.html".format(app_label, opts.model_name),
|
||||
context
|
||||
)
|
||||
|
||||
|
||||
def simple_action(
|
||||
modeladmin, request, queryset, success_message="",
|
||||
document_action=None, queryset_action=None):
|
||||
|
||||
if not modeladmin.has_change_permission(request):
|
||||
raise PermissionDenied
|
||||
|
||||
n = queryset.count()
|
||||
if n:
|
||||
for document in queryset:
|
||||
if document_action:
|
||||
document_action(document)
|
||||
document_display = str(document)
|
||||
modeladmin.log_change(request, document, document_display)
|
||||
if queryset_action:
|
||||
queryset_action(queryset)
|
||||
modeladmin.message_user(request, success_message % {
|
||||
"count": n, "items": model_ngettext(modeladmin.opts, n)
|
||||
}, messages.SUCCESS)
|
||||
|
||||
# Return None to display the change list page again.
|
||||
return None
|
||||
|
||||
|
||||
def add_tag_to_selected(modeladmin, request, queryset):
|
||||
return select_action(
|
||||
modeladmin=modeladmin,
|
||||
request=request,
|
||||
queryset=queryset,
|
||||
title="Add tag to multiple documents",
|
||||
action="add_tag_to_selected",
|
||||
modelclass=Tag,
|
||||
success_message="Successfully added tag %(selected_object)s to "
|
||||
"%(count)d %(items)s.",
|
||||
document_action=lambda doc, tag: doc.tags.add(tag)
|
||||
)
|
||||
|
||||
|
||||
def remove_tag_from_selected(modeladmin, request, queryset):
|
||||
return select_action(
|
||||
modeladmin=modeladmin,
|
||||
request=request,
|
||||
queryset=queryset,
|
||||
title="Remove tag from multiple documents",
|
||||
action="remove_tag_from_selected",
|
||||
modelclass=Tag,
|
||||
success_message="Successfully removed tag %(selected_object)s from "
|
||||
"%(count)d %(items)s.",
|
||||
document_action=lambda doc, tag: doc.tags.remove(tag)
|
||||
)
|
||||
|
||||
|
||||
def set_correspondent_on_selected(modeladmin, request, queryset):
|
||||
|
||||
return select_action(
|
||||
modeladmin=modeladmin,
|
||||
request=request,
|
||||
queryset=queryset,
|
||||
title="Set correspondent on multiple documents",
|
||||
action="set_correspondent_on_selected",
|
||||
modelclass=Correspondent,
|
||||
success_message="Successfully set correspondent %(selected_object)s "
|
||||
"on %(count)d %(items)s.",
|
||||
queryset_action=lambda qs, corr: qs.update(correspondent=corr)
|
||||
)
|
||||
|
||||
|
||||
def remove_correspondent_from_selected(modeladmin, request, queryset):
|
||||
return simple_action(
|
||||
modeladmin=modeladmin,
|
||||
request=request,
|
||||
queryset=queryset,
|
||||
success_message="Successfully removed correspondent from %(count)d "
|
||||
"%(items)s.",
|
||||
queryset_action=lambda qs: qs.update(correspondent=None)
|
||||
)
|
||||
|
||||
|
||||
add_tag_to_selected.short_description = "Add tag to selected documents"
|
||||
remove_tag_from_selected.short_description = \
|
||||
"Remove tag from selected documents"
|
||||
set_correspondent_on_selected.short_description = \
|
||||
"Set correspondent on selected documents"
|
||||
remove_correspondent_from_selected.short_description = \
|
||||
"Remove correspondent from selected documents"
|
||||
@@ -1,35 +1,112 @@
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
from django.conf import settings
|
||||
from django.contrib import admin
|
||||
from django.contrib.auth.models import User, Group
|
||||
from django.core.urlresolvers import reverse
|
||||
from django.contrib import admin, messages
|
||||
from django.contrib.admin.templatetags.admin_urls import add_preserved_filters
|
||||
from django.contrib.auth.models import Group, User
|
||||
from django.db import models
|
||||
from django.http import HttpResponseRedirect
|
||||
from django.templatetags.static import static
|
||||
from django.urls import reverse
|
||||
from django.utils.html import format_html, format_html_join
|
||||
from django.utils.http import urlquote
|
||||
from django.utils.safestring import mark_safe
|
||||
|
||||
from .models import Correspondent, Tag, Document, Log
|
||||
from documents.actions import (
|
||||
add_tag_to_selected,
|
||||
remove_correspondent_from_selected,
|
||||
remove_tag_from_selected,
|
||||
set_correspondent_on_selected
|
||||
)
|
||||
|
||||
from .models import Correspondent, Document, Log, Tag
|
||||
|
||||
|
||||
class MonthListFilter(admin.SimpleListFilter):
|
||||
class FinancialYearFilter(admin.SimpleListFilter):
|
||||
|
||||
title = "Month"
|
||||
title = "Financial Year"
|
||||
parameter_name = "fy"
|
||||
_fy_wraps = None
|
||||
|
||||
# Parameter for the filter that will be used in the URL query.
|
||||
parameter_name = "month"
|
||||
def _fy_start(self, year):
|
||||
"""Return date of the start of financial year for the given year."""
|
||||
fy_start = "{}-{}".format(str(year), settings.FY_START)
|
||||
return datetime.strptime(fy_start, "%Y-%m-%d").date()
|
||||
|
||||
def _fy_end(self, year):
|
||||
"""Return date of the end of financial year for the given year."""
|
||||
fy_end = "{}-{}".format(str(year), settings.FY_END)
|
||||
return datetime.strptime(fy_end, "%Y-%m-%d").date()
|
||||
|
||||
def _fy_does_wrap(self):
|
||||
"""Return whether the financial year spans across two years."""
|
||||
if self._fy_wraps is None:
|
||||
start = "{}".format(settings.FY_START)
|
||||
start = datetime.strptime(start, "%m-%d").date()
|
||||
end = "{}".format(settings.FY_END)
|
||||
end = datetime.strptime(end, "%m-%d").date()
|
||||
self._fy_wraps = end < start
|
||||
|
||||
return self._fy_wraps
|
||||
|
||||
def _determine_fy(self, date):
|
||||
"""Return a (query, display) financial year tuple of the given date."""
|
||||
if self._fy_does_wrap():
|
||||
fy_start = self._fy_start(date.year)
|
||||
|
||||
if date.date() >= fy_start:
|
||||
query = "{}-{}".format(date.year, date.year + 1)
|
||||
else:
|
||||
query = "{}-{}".format(date.year - 1, date.year)
|
||||
|
||||
# To keep it simple we use the same string for both
|
||||
# query parameter and the display.
|
||||
return (query, query)
|
||||
|
||||
else:
|
||||
query = "{0}-{0}".format(date.year)
|
||||
display = "{}".format(date.year)
|
||||
return (query, display)
|
||||
|
||||
def lookups(self, request, model_admin):
|
||||
if not settings.FY_START or not settings.FY_END:
|
||||
return None
|
||||
|
||||
r = []
|
||||
for document in Document.objects.all():
|
||||
r.append((
|
||||
document.created.strftime("%Y-%m"),
|
||||
document.created.strftime("%B %Y")
|
||||
))
|
||||
r.append(self._determine_fy(document.created))
|
||||
|
||||
return sorted(set(r), key=lambda x: x[0], reverse=True)
|
||||
|
||||
def queryset(self, request, queryset):
|
||||
|
||||
if not self.value():
|
||||
if not self.value() or not settings.FY_START or not settings.FY_END:
|
||||
return None
|
||||
|
||||
year, month = self.value().split("-")
|
||||
return queryset.filter(created__year=year, created__month=month)
|
||||
start, end = self.value().split("-")
|
||||
return queryset.filter(created__gte=self._fy_start(start),
|
||||
created__lte=self._fy_end(end))
|
||||
|
||||
|
||||
class RecentCorrespondentFilter(admin.RelatedFieldListFilter):
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.title = "correspondent (recent)"
|
||||
|
||||
def field_choices(self, field, request, model_admin):
|
||||
|
||||
years = settings.PAPERLESS_RECENT_CORRESPONDENT_YEARS
|
||||
days = 365 * years
|
||||
|
||||
lookups = []
|
||||
if years and years > 0:
|
||||
correspondents = Correspondent.objects.filter(
|
||||
documents__created__gte=datetime.now() - timedelta(days=days)
|
||||
).distinct()
|
||||
for c in correspondents:
|
||||
lookups.append((c.id, c.name))
|
||||
|
||||
return lookups
|
||||
|
||||
|
||||
class CommonAdmin(admin.ModelAdmin):
|
||||
@@ -38,17 +115,53 @@ class CommonAdmin(admin.ModelAdmin):
|
||||
|
||||
class CorrespondentAdmin(CommonAdmin):
|
||||
|
||||
list_display = ("name", "match", "matching_algorithm")
|
||||
list_display = (
|
||||
"name",
|
||||
"match",
|
||||
"matching_algorithm",
|
||||
"document_count",
|
||||
"last_correspondence"
|
||||
)
|
||||
list_filter = ("matching_algorithm",)
|
||||
list_editable = ("match", "matching_algorithm")
|
||||
|
||||
readonly_fields = ("slug",)
|
||||
|
||||
def get_queryset(self, request):
|
||||
qs = super(CorrespondentAdmin, self).get_queryset(request)
|
||||
qs = qs.annotate(
|
||||
document_count=models.Count("documents"),
|
||||
last_correspondence=models.Max("documents__created")
|
||||
)
|
||||
return qs
|
||||
|
||||
def document_count(self, obj):
|
||||
return obj.document_count
|
||||
document_count.admin_order_field = "document_count"
|
||||
|
||||
def last_correspondence(self, obj):
|
||||
return obj.last_correspondence
|
||||
last_correspondence.admin_order_field = "last_correspondence"
|
||||
|
||||
|
||||
class TagAdmin(CommonAdmin):
|
||||
|
||||
list_display = ("name", "colour", "match", "matching_algorithm")
|
||||
list_display = ("name", "colour", "match", "matching_algorithm",
|
||||
"document_count")
|
||||
list_filter = ("colour", "matching_algorithm")
|
||||
list_editable = ("colour", "match", "matching_algorithm")
|
||||
|
||||
readonly_fields = ("slug",)
|
||||
|
||||
def get_queryset(self, request):
|
||||
qs = super(TagAdmin, self).get_queryset(request)
|
||||
qs = qs.annotate(document_count=models.Count("documents"))
|
||||
return qs
|
||||
|
||||
def document_count(self, obj):
|
||||
return obj.document_count
|
||||
document_count.admin_order_field = "document_count"
|
||||
|
||||
|
||||
class DocumentAdmin(CommonAdmin):
|
||||
|
||||
@@ -57,25 +170,128 @@ class DocumentAdmin(CommonAdmin):
|
||||
"all": ("paperless.css",)
|
||||
}
|
||||
|
||||
search_fields = ("correspondent__name", "title", "content")
|
||||
list_display = ("title", "created", "thumbnail", "correspondent", "tags_")
|
||||
list_filter = ("tags", "correspondent", MonthListFilter)
|
||||
search_fields = ("correspondent__name", "title", "content", "tags__name")
|
||||
readonly_fields = ("added", "file_type", "storage_type",)
|
||||
list_display = ("title", "created", "added", "thumbnail", "correspondent",
|
||||
"tags_")
|
||||
list_filter = (
|
||||
"tags",
|
||||
("correspondent", RecentCorrespondentFilter),
|
||||
"correspondent",
|
||||
FinancialYearFilter
|
||||
)
|
||||
|
||||
filter_horizontal = ("tags",)
|
||||
|
||||
ordering = ["-created", "correspondent"]
|
||||
|
||||
actions = [
|
||||
add_tag_to_selected,
|
||||
remove_tag_from_selected,
|
||||
set_correspondent_on_selected,
|
||||
remove_correspondent_from_selected
|
||||
]
|
||||
|
||||
date_hierarchy = "created"
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.document_queue = []
|
||||
|
||||
def has_add_permission(self, request):
|
||||
return False
|
||||
|
||||
def created_(self, obj):
|
||||
return obj.created.date().strftime("%Y-%m-%d")
|
||||
created_.short_description = "Created"
|
||||
|
||||
def thumbnail(self, obj):
|
||||
png_img = self._html_tag(
|
||||
"img",
|
||||
src="/fetch/thumb/{}".format(obj.id),
|
||||
width=180,
|
||||
alt="thumbnail",
|
||||
title=obj.file_name
|
||||
def changelist_view(self, request, extra_context=None):
|
||||
|
||||
response = super().changelist_view(
|
||||
request,
|
||||
extra_context=extra_context
|
||||
)
|
||||
return self._html_tag("a", png_img, href=obj.download_url)
|
||||
thumbnail.allow_tags = True
|
||||
|
||||
if request.method == "GET":
|
||||
cl = self.get_changelist_instance(request)
|
||||
self.document_queue = [doc.id for doc in cl.queryset]
|
||||
|
||||
return response
|
||||
|
||||
def change_view(self, request, object_id=None, form_url='',
|
||||
extra_context=None):
|
||||
|
||||
extra_context = extra_context or {}
|
||||
|
||||
if self.document_queue and object_id:
|
||||
if int(object_id) in self.document_queue:
|
||||
# There is a queue of documents
|
||||
current_index = self.document_queue.index(int(object_id))
|
||||
if current_index < len(self.document_queue) - 1:
|
||||
# ... and there are still documents in the queue
|
||||
extra_context["next_object"] = self.document_queue[
|
||||
current_index + 1
|
||||
]
|
||||
|
||||
return super(DocumentAdmin, self).change_view(
|
||||
request,
|
||||
object_id,
|
||||
form_url,
|
||||
extra_context=extra_context,
|
||||
)
|
||||
|
||||
def response_change(self, request, obj):
|
||||
|
||||
# This is mostly copied from ModelAdmin.response_change()
|
||||
opts = self.model._meta
|
||||
preserved_filters = self.get_preserved_filters(request)
|
||||
|
||||
msg_dict = {
|
||||
"name": opts.verbose_name,
|
||||
"obj": format_html(
|
||||
'<a href="{}">{}</a>',
|
||||
urlquote(request.path),
|
||||
obj
|
||||
),
|
||||
}
|
||||
if "_saveandeditnext" in request.POST:
|
||||
msg = format_html(
|
||||
'The {name} "{obj}" was changed successfully. '
|
||||
'Editing next object.',
|
||||
**msg_dict
|
||||
)
|
||||
self.message_user(request, msg, messages.SUCCESS)
|
||||
redirect_url = reverse(
|
||||
"admin:{}_{}_change".format(opts.app_label, opts.model_name),
|
||||
args=(request.POST["_next_object"],),
|
||||
current_app=self.admin_site.name
|
||||
)
|
||||
redirect_url = add_preserved_filters(
|
||||
{
|
||||
"preserved_filters": preserved_filters,
|
||||
"opts": opts
|
||||
},
|
||||
redirect_url
|
||||
)
|
||||
return HttpResponseRedirect(redirect_url)
|
||||
|
||||
return super().response_change(request, obj)
|
||||
|
||||
@mark_safe
|
||||
def thumbnail(self, obj):
|
||||
return self._html_tag(
|
||||
"a",
|
||||
self._html_tag(
|
||||
"img",
|
||||
src=reverse("fetch", kwargs={"kind": "thumb", "pk": obj.pk}),
|
||||
width=180,
|
||||
alt="Thumbnail of {}".format(obj.file_name),
|
||||
title=obj.file_name
|
||||
),
|
||||
href=obj.download_url
|
||||
)
|
||||
|
||||
@mark_safe
|
||||
def tags_(self, obj):
|
||||
r = ""
|
||||
for tag in obj.tags.all():
|
||||
@@ -93,9 +309,10 @@ class DocumentAdmin(CommonAdmin):
|
||||
}
|
||||
)
|
||||
return r
|
||||
tags_.allow_tags = True
|
||||
|
||||
@mark_safe
|
||||
def document(self, obj):
|
||||
# TODO: is this method even used anymore?
|
||||
return self._html_tag(
|
||||
"a",
|
||||
self._html_tag(
|
||||
@@ -108,20 +325,16 @@ class DocumentAdmin(CommonAdmin):
|
||||
),
|
||||
href=obj.download_url
|
||||
)
|
||||
document.allow_tags = True
|
||||
|
||||
@staticmethod
|
||||
def _html_tag(kind, inside=None, **kwargs):
|
||||
|
||||
attributes = []
|
||||
for lft, rgt in kwargs.items():
|
||||
attributes.append('{}="{}"'.format(lft, rgt))
|
||||
attributes = format_html_join(' ', '{}="{}"', kwargs.items())
|
||||
|
||||
if inside is not None:
|
||||
return "<{kind} {attributes}>{inside}</{kind}>".format(
|
||||
kind=kind, attributes=" ".join(attributes), inside=inside)
|
||||
return format_html("<{kind} {attributes}>{inside}</{kind}>",
|
||||
kind=kind, attributes=attributes, inside=inside)
|
||||
|
||||
return "<{} {}/>".format(kind, " ".join(attributes))
|
||||
return format_html("<{} {}/>", kind, attributes)
|
||||
|
||||
|
||||
class LogAdmin(CommonAdmin):
|
||||
|
||||
@@ -15,13 +15,15 @@ class DocumentsConfig(AppConfig):
|
||||
set_tags,
|
||||
run_pre_consume_script,
|
||||
run_post_consume_script,
|
||||
cleanup_document_deletion
|
||||
cleanup_document_deletion,
|
||||
set_log_entry
|
||||
)
|
||||
|
||||
document_consumption_started.connect(run_pre_consume_script)
|
||||
|
||||
document_consumption_finished.connect(set_tags)
|
||||
document_consumption_finished.connect(set_correspondent)
|
||||
document_consumption_finished.connect(set_log_entry)
|
||||
document_consumption_finished.connect(run_post_consume_script)
|
||||
|
||||
post_delete.connect(cleanup_document_deletion)
|
||||
|
||||
39
src/documents/checks.py
Normal file
39
src/documents/checks.py
Normal file
@@ -0,0 +1,39 @@
|
||||
import textwrap
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.checks import Error, register
|
||||
from django.db.utils import OperationalError, ProgrammingError
|
||||
|
||||
|
||||
@register()
|
||||
def changed_password_check(app_configs, **kwargs):
|
||||
|
||||
from documents.models import Document
|
||||
from paperless.db import GnuPG
|
||||
|
||||
try:
|
||||
encrypted_doc = Document.objects.filter(
|
||||
storage_type=Document.STORAGE_TYPE_GPG).first()
|
||||
except (OperationalError, ProgrammingError):
|
||||
return [] # No documents table yet
|
||||
|
||||
if encrypted_doc:
|
||||
|
||||
if not settings.PASSPHRASE:
|
||||
return [Error(
|
||||
"The database contains encrypted documents but no password "
|
||||
"is set."
|
||||
)]
|
||||
|
||||
if not GnuPG.decrypted(encrypted_doc.source_file):
|
||||
return [Error(textwrap.dedent(
|
||||
"""
|
||||
The current password doesn't match the password of the
|
||||
existing documents.
|
||||
|
||||
If you intend to change your password, you must first export
|
||||
all of the old documents, start fresh with the new password
|
||||
and then re-import them."
|
||||
"""))]
|
||||
|
||||
return []
|
||||
@@ -1,294 +1,208 @@
|
||||
import os
|
||||
import re
|
||||
import uuid
|
||||
import shutil
|
||||
from django.db import transaction
|
||||
import datetime
|
||||
import hashlib
|
||||
import logging
|
||||
import datetime
|
||||
import tempfile
|
||||
import itertools
|
||||
import subprocess
|
||||
from multiprocessing.pool import Pool
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import uuid
|
||||
|
||||
import pyocr
|
||||
import langdetect
|
||||
from PIL import Image
|
||||
from operator import itemgetter
|
||||
from django.conf import settings
|
||||
from django.utils import timezone
|
||||
from paperless.db import GnuPG
|
||||
from pyocr.tesseract import TesseractError
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
|
||||
from .models import Tag, Document, FileInfo
|
||||
from .models import Document, FileInfo, Tag
|
||||
from .parsers import ParseError
|
||||
from .signals import (
|
||||
document_consumption_started,
|
||||
document_consumption_finished
|
||||
document_consumer_declaration,
|
||||
document_consumption_finished,
|
||||
document_consumption_started
|
||||
)
|
||||
from .languages import ISO639
|
||||
|
||||
|
||||
class OCRError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class ConsumerError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class Consumer(object):
|
||||
class Consumer:
|
||||
"""
|
||||
Loop over every file found in CONSUMPTION_DIR and:
|
||||
1. Convert it to a greyscale pnm
|
||||
2. Use tesseract on the pnm
|
||||
3. Encrypt and store the document in the MEDIA_ROOT
|
||||
3. Store the document in the MEDIA_ROOT with optional encryption
|
||||
4. Store the OCR'd text in the database
|
||||
5. Delete the document and image(s)
|
||||
"""
|
||||
|
||||
SCRATCH = settings.SCRATCH_DIR
|
||||
CONVERT = settings.CONVERT_BINARY
|
||||
UNPAPER = settings.UNPAPER_BINARY
|
||||
CONSUME = settings.CONSUMPTION_DIR
|
||||
THREADS = int(settings.OCR_THREADS) if settings.OCR_THREADS else None
|
||||
DENSITY = settings.CONVERT_DENSITY if settings.CONVERT_DENSITY else 300
|
||||
# Files are considered ready for consumption if they have been unmodified
|
||||
# for this duration
|
||||
FILES_MIN_UNMODIFIED_DURATION = 0.5
|
||||
|
||||
DEFAULT_OCR_LANGUAGE = settings.OCR_LANGUAGE
|
||||
|
||||
def __init__(self):
|
||||
def __init__(self, consume=settings.CONSUMPTION_DIR,
|
||||
scratch=settings.SCRATCH_DIR):
|
||||
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.logging_group = None
|
||||
|
||||
try:
|
||||
os.makedirs(self.SCRATCH)
|
||||
except FileExistsError:
|
||||
pass
|
||||
|
||||
self.stats = {}
|
||||
self._ignore = []
|
||||
self.consume = consume
|
||||
self.scratch = scratch
|
||||
|
||||
if not self.CONSUME:
|
||||
os.makedirs(self.scratch, exist_ok=True)
|
||||
|
||||
self.storage_type = Document.STORAGE_TYPE_UNENCRYPTED
|
||||
if settings.PASSPHRASE:
|
||||
self.storage_type = Document.STORAGE_TYPE_GPG
|
||||
|
||||
if not self.consume:
|
||||
raise ConsumerError(
|
||||
"The CONSUMPTION_DIR settings variable does not appear to be "
|
||||
"set."
|
||||
)
|
||||
|
||||
if not os.path.exists(self.CONSUME):
|
||||
if not os.path.exists(self.consume):
|
||||
raise ConsumerError(
|
||||
"Consumption directory {} does not exist".format(self.CONSUME))
|
||||
"Consumption directory {} does not exist".format(self.consume))
|
||||
|
||||
self.parsers = []
|
||||
for response in document_consumer_declaration.send(self):
|
||||
self.parsers.append(response[1])
|
||||
|
||||
if not self.parsers:
|
||||
raise ConsumerError(
|
||||
"No parsers could be found, not even the default. "
|
||||
"This is a problem."
|
||||
)
|
||||
|
||||
def log(self, level, message):
|
||||
getattr(self.logger, level)(message, extra={
|
||||
"group": self.logging_group
|
||||
})
|
||||
|
||||
def consume(self):
|
||||
def consume_new_files(self):
|
||||
"""
|
||||
Find non-ignored files in consumption dir and consume them if they have
|
||||
been unmodified for FILES_MIN_UNMODIFIED_DURATION.
|
||||
"""
|
||||
ignored_files = []
|
||||
files = []
|
||||
for entry in os.scandir(self.consume):
|
||||
if entry.is_file():
|
||||
file = (entry.path, entry.stat().st_mtime)
|
||||
if file in self._ignore:
|
||||
ignored_files.append(file)
|
||||
else:
|
||||
files.append(file)
|
||||
|
||||
for doc in os.listdir(self.CONSUME):
|
||||
if not files:
|
||||
return
|
||||
|
||||
doc = os.path.join(self.CONSUME, doc)
|
||||
# Set _ignore to only include files that still exist.
|
||||
# This keeps it from growing indefinitely.
|
||||
self._ignore[:] = ignored_files
|
||||
|
||||
if not os.path.isfile(doc):
|
||||
continue
|
||||
files_old_to_new = sorted(files, key=itemgetter(1))
|
||||
|
||||
if not re.match(FileInfo.REGEXES["title"], doc):
|
||||
continue
|
||||
time.sleep(self.FILES_MIN_UNMODIFIED_DURATION)
|
||||
|
||||
if doc in self._ignore:
|
||||
continue
|
||||
for file, mtime in files_old_to_new:
|
||||
if mtime == os.path.getmtime(file):
|
||||
# File has not been modified and can be consumed
|
||||
if not self.try_consume_file(file):
|
||||
self._ignore.append((file, mtime))
|
||||
|
||||
if not self._is_ready(doc):
|
||||
continue
|
||||
@transaction.atomic
|
||||
def try_consume_file(self, file):
|
||||
"""
|
||||
Return True if file was consumed
|
||||
"""
|
||||
|
||||
if self._is_duplicate(doc):
|
||||
self.log(
|
||||
"info",
|
||||
"Skipping {} as it appears to be a duplicate".format(doc)
|
||||
)
|
||||
self._ignore.append(doc)
|
||||
continue
|
||||
if not re.match(FileInfo.REGEXES["title"], file):
|
||||
return False
|
||||
|
||||
self.logging_group = uuid.uuid4()
|
||||
doc = file
|
||||
|
||||
self.log("info", "Consuming {}".format(doc))
|
||||
if self._is_duplicate(doc):
|
||||
self.log(
|
||||
"info",
|
||||
"Skipping {} as it appears to be a duplicate".format(doc)
|
||||
)
|
||||
return False
|
||||
|
||||
document_consumption_started.send(
|
||||
parser_class = self._get_parser_class(doc)
|
||||
if not parser_class:
|
||||
self.log(
|
||||
"error", "No parsers could be found for {}".format(doc))
|
||||
return False
|
||||
|
||||
self.logging_group = uuid.uuid4()
|
||||
|
||||
self.log("info", "Consuming {}".format(doc))
|
||||
|
||||
document_consumption_started.send(
|
||||
sender=self.__class__,
|
||||
filename=doc,
|
||||
logging_group=self.logging_group
|
||||
)
|
||||
|
||||
parsed_document = parser_class(doc)
|
||||
|
||||
try:
|
||||
thumbnail = parsed_document.get_optimised_thumbnail()
|
||||
date = parsed_document.get_date()
|
||||
document = self._store(
|
||||
parsed_document.get_text(),
|
||||
doc,
|
||||
thumbnail,
|
||||
date
|
||||
)
|
||||
except ParseError as e:
|
||||
self.log("error", "PARSE FAILURE for {}: {}".format(doc, e))
|
||||
parsed_document.cleanup()
|
||||
return False
|
||||
else:
|
||||
parsed_document.cleanup()
|
||||
self._cleanup_doc(doc)
|
||||
|
||||
self.log(
|
||||
"info",
|
||||
"Document {} consumption finished".format(document)
|
||||
)
|
||||
|
||||
document_consumption_finished.send(
|
||||
sender=self.__class__,
|
||||
filename=doc,
|
||||
document=document,
|
||||
logging_group=self.logging_group
|
||||
)
|
||||
return True
|
||||
|
||||
tempdir = tempfile.mkdtemp(prefix="paperless", dir=self.SCRATCH)
|
||||
imgs = self._get_greyscale(tempdir, doc)
|
||||
thumbnail = self._get_thumbnail(tempdir, doc)
|
||||
|
||||
try:
|
||||
|
||||
document = self._store(self._get_ocr(imgs), doc, thumbnail)
|
||||
|
||||
except OCRError as e:
|
||||
|
||||
self._ignore.append(doc)
|
||||
self.log("error", "OCR FAILURE for {}: {}".format(doc, e))
|
||||
self._cleanup_tempdir(tempdir)
|
||||
|
||||
continue
|
||||
|
||||
else:
|
||||
|
||||
self._cleanup_tempdir(tempdir)
|
||||
self._cleanup_doc(doc)
|
||||
|
||||
self.log(
|
||||
"info",
|
||||
"Document {} consumption finished".format(document)
|
||||
)
|
||||
|
||||
document_consumption_finished.send(
|
||||
sender=self.__class__,
|
||||
document=document,
|
||||
logging_group=self.logging_group
|
||||
)
|
||||
|
||||
def _get_greyscale(self, tempdir, doc):
|
||||
def _get_parser_class(self, doc):
|
||||
"""
|
||||
Greyscale images are easier for Tesseract to OCR
|
||||
Determine the appropriate parser class based on the file
|
||||
"""
|
||||
|
||||
self.log("info", "Generating greyscale image from {}".format(doc))
|
||||
options = []
|
||||
for parser in self.parsers:
|
||||
result = parser(doc)
|
||||
if result:
|
||||
options.append(result)
|
||||
|
||||
# Convert PDF to multiple PNMs
|
||||
pnm = os.path.join(tempdir, "convert-%04d.pnm")
|
||||
run_convert(
|
||||
self.CONVERT,
|
||||
"-density", str(self.DENSITY),
|
||||
"-depth", "8",
|
||||
"-type", "grayscale",
|
||||
doc, pnm,
|
||||
)
|
||||
|
||||
# Get a list of converted images
|
||||
pnms = []
|
||||
for f in os.listdir(tempdir):
|
||||
if f.endswith(".pnm"):
|
||||
pnms.append(os.path.join(tempdir, f))
|
||||
|
||||
# Run unpaper in parallel on converted images
|
||||
with Pool(processes=self.THREADS) as pool:
|
||||
pool.map(run_unpaper, itertools.product([self.UNPAPER], pnms))
|
||||
|
||||
# Return list of converted images, processed with unpaper
|
||||
pnms = []
|
||||
for f in os.listdir(tempdir):
|
||||
if f.endswith(".unpaper.pnm"):
|
||||
pnms.append(os.path.join(tempdir, f))
|
||||
|
||||
return sorted(filter(lambda __: os.path.isfile(__), pnms))
|
||||
|
||||
def _get_thumbnail(self, tempdir, doc):
|
||||
"""
|
||||
The thumbnail of a PDF is just a 500px wide image of the first page.
|
||||
"""
|
||||
|
||||
self.log("info", "Generating the thumbnail")
|
||||
|
||||
run_convert(
|
||||
self.CONVERT,
|
||||
"-scale", "500x5000",
|
||||
"-alpha", "remove",
|
||||
doc, os.path.join(tempdir, "convert-%04d.png")
|
||||
)
|
||||
|
||||
return os.path.join(tempdir, "convert-0000.png")
|
||||
|
||||
def _guess_language(self, text):
|
||||
try:
|
||||
guess = langdetect.detect(text)
|
||||
self.log("debug", "Language detected: {}".format(guess))
|
||||
return guess
|
||||
except Exception as e:
|
||||
self.log("warning", "Language detection error: {}".format(e))
|
||||
|
||||
def _get_ocr(self, imgs):
|
||||
"""
|
||||
Attempts to do the best job possible OCR'ing the document based on
|
||||
simple language detection trial & error.
|
||||
"""
|
||||
|
||||
if not imgs:
|
||||
raise OCRError("No images found")
|
||||
|
||||
self.log("info", "OCRing the document")
|
||||
|
||||
# Since the division gets rounded down by int, this calculation works
|
||||
# for every edge-case, i.e. 1
|
||||
middle = int(len(imgs) / 2)
|
||||
raw_text = self._ocr([imgs[middle]], self.DEFAULT_OCR_LANGUAGE)
|
||||
|
||||
guessed_language = self._guess_language(raw_text)
|
||||
|
||||
if not guessed_language or guessed_language not in ISO639:
|
||||
self.log("warning", "Language detection failed!")
|
||||
if settings.FORGIVING_OCR:
|
||||
self.log(
|
||||
"warning",
|
||||
"As FORGIVING_OCR is enabled, we're going to make the "
|
||||
"best with what we have."
|
||||
)
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
raise OCRError("Language detection failed")
|
||||
|
||||
if ISO639[guessed_language] == self.DEFAULT_OCR_LANGUAGE:
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
|
||||
try:
|
||||
return self._ocr(imgs, ISO639[guessed_language])
|
||||
except pyocr.pyocr.tesseract.TesseractError:
|
||||
if settings.FORGIVING_OCR:
|
||||
self.log(
|
||||
"warning",
|
||||
"OCR for {} failed, but we're going to stick with what "
|
||||
"we've got since FORGIVING_OCR is enabled.".format(
|
||||
guessed_language
|
||||
)
|
||||
)
|
||||
raw_text = self._assemble_ocr_sections(imgs, middle, raw_text)
|
||||
return raw_text
|
||||
raise OCRError(
|
||||
"The guessed language is not available in this instance of "
|
||||
"Tesseract."
|
||||
self.log(
|
||||
"info",
|
||||
"Parsers available: {}".format(
|
||||
", ".join([str(o["parser"].__name__) for o in options])
|
||||
)
|
||||
)
|
||||
|
||||
def _assemble_ocr_sections(self, imgs, middle, text):
|
||||
"""
|
||||
Given a `middle` value and the text that middle page represents, we OCR
|
||||
the remainder of the document and return the whole thing.
|
||||
"""
|
||||
text = self._ocr(imgs[:middle], self.DEFAULT_OCR_LANGUAGE) + text
|
||||
text += self._ocr(imgs[middle + 1:], self.DEFAULT_OCR_LANGUAGE)
|
||||
return text
|
||||
if not options:
|
||||
return None
|
||||
|
||||
def _ocr(self, imgs, lang):
|
||||
"""
|
||||
Performs a single OCR attempt.
|
||||
"""
|
||||
# Return the parser with the highest weight.
|
||||
return sorted(
|
||||
options, key=lambda _: _["weight"], reverse=True)[0]["parser"]
|
||||
|
||||
if not imgs:
|
||||
return ""
|
||||
|
||||
self.log("info", "Parsing for {}".format(lang))
|
||||
|
||||
with Pool(processes=self.THREADS) as pool:
|
||||
r = pool.map(image_to_string, itertools.product(imgs, [lang]))
|
||||
r = " ".join(r)
|
||||
|
||||
# Strip out excess white space to allow matching to go smoother
|
||||
return strip_excess_whitespace(r)
|
||||
|
||||
def _store(self, text, doc, thumbnail):
|
||||
def _store(self, text, doc, thumbnail, date):
|
||||
|
||||
file_info = FileInfo.from_path(doc)
|
||||
|
||||
@@ -296,7 +210,7 @@ class Consumer(object):
|
||||
|
||||
self.log("debug", "Saving record to database")
|
||||
|
||||
created = file_info.created or timezone.make_aware(
|
||||
created = file_info.created or date or timezone.make_aware(
|
||||
datetime.datetime.fromtimestamp(stats.st_mtime))
|
||||
|
||||
with open(doc, "rb") as f:
|
||||
@@ -307,7 +221,8 @@ class Consumer(object):
|
||||
file_type=file_info.extension,
|
||||
checksum=hashlib.md5(f.read()).hexdigest(),
|
||||
created=created,
|
||||
modified=created
|
||||
modified=created,
|
||||
storage_type=self.storage_type
|
||||
)
|
||||
|
||||
relevant_tags = set(list(Tag.match_all(text)) + list(file_info.tags))
|
||||
@@ -316,86 +231,28 @@ class Consumer(object):
|
||||
self.log("debug", "Tagging with {}".format(tag_names))
|
||||
document.tags.add(*relevant_tags)
|
||||
|
||||
# Encrypt and store the actual document
|
||||
with open(doc, "rb") as unencrypted:
|
||||
with open(document.source_path, "wb") as encrypted:
|
||||
self.log("debug", "Encrypting the document")
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
|
||||
# Encrypt and store the thumbnail
|
||||
with open(thumbnail, "rb") as unencrypted:
|
||||
with open(document.thumbnail_path, "wb") as encrypted:
|
||||
self.log("debug", "Encrypting the thumbnail")
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
self._write(document, doc, document.source_path)
|
||||
self._write(document, thumbnail, document.thumbnail_path)
|
||||
|
||||
self.log("info", "Completed")
|
||||
|
||||
return document
|
||||
|
||||
def _cleanup_tempdir(self, d):
|
||||
self.log("debug", "Deleting directory {}".format(d))
|
||||
shutil.rmtree(d)
|
||||
def _write(self, document, source, target):
|
||||
with open(source, "rb") as read_file:
|
||||
with open(target, "wb") as write_file:
|
||||
if document.storage_type == Document.STORAGE_TYPE_UNENCRYPTED:
|
||||
write_file.write(read_file.read())
|
||||
return
|
||||
self.log("debug", "Encrypting")
|
||||
write_file.write(GnuPG.encrypted(read_file))
|
||||
|
||||
def _cleanup_doc(self, doc):
|
||||
self.log("debug", "Deleting document {}".format(doc))
|
||||
os.unlink(doc)
|
||||
|
||||
def _is_ready(self, doc):
|
||||
"""
|
||||
Detect whether `doc` is ready to consume or if it's still being written
|
||||
to by the uploader.
|
||||
"""
|
||||
|
||||
t = os.stat(doc).st_mtime
|
||||
|
||||
if self.stats.get(doc) == t:
|
||||
del(self.stats[doc])
|
||||
return True
|
||||
|
||||
self.stats[doc] = t
|
||||
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
def _is_duplicate(doc):
|
||||
with open(doc, "rb") as f:
|
||||
checksum = hashlib.md5(f.read()).hexdigest()
|
||||
return Document.objects.filter(checksum=checksum).exists()
|
||||
|
||||
|
||||
def strip_excess_whitespace(text):
|
||||
collapsed_spaces = re.sub(r"([^\S\r\n]+)", " ", text)
|
||||
no_leading_whitespace = re.sub(
|
||||
"([\n\r]+)([^\S\n\r]+)", '\\1', collapsed_spaces)
|
||||
no_trailing_whitespace = re.sub("([^\S\n\r]+)$", '', no_leading_whitespace)
|
||||
return no_trailing_whitespace
|
||||
|
||||
|
||||
def image_to_string(args):
|
||||
img, lang = args
|
||||
ocr = pyocr.get_available_tools()[0]
|
||||
with Image.open(os.path.join(Consumer.SCRATCH, img)) as f:
|
||||
if ocr.can_detect_orientation():
|
||||
try:
|
||||
orientation = ocr.detect_orientation(f, lang=lang)
|
||||
f = f.rotate(orientation["angle"], expand=1)
|
||||
except (TesseractError, OtherTesseractError):
|
||||
pass
|
||||
return ocr.image_to_string(f, lang=lang)
|
||||
|
||||
|
||||
def run_unpaper(args):
|
||||
unpaper, pnm = args
|
||||
subprocess.Popen(
|
||||
(unpaper, pnm, pnm.replace(".pnm", ".unpaper.pnm"))).wait()
|
||||
|
||||
|
||||
def run_convert(*args):
|
||||
|
||||
environment = os.environ.copy()
|
||||
if settings.CONVERT_MEMORY_LIMIT:
|
||||
environment["MAGICK_MEMORY_LIMIT"] = settings.CONVERT_MEMORY_LIMIT
|
||||
if settings.CONVERT_TMPDIR:
|
||||
environment["MAGICK_TMPDIR"] = settings.CONVERT_TMPDIR
|
||||
|
||||
subprocess.Popen(args, env=environment).wait()
|
||||
|
||||
@@ -1,14 +1,20 @@
|
||||
from django_filters.rest_framework import CharFilter, FilterSet
|
||||
from django_filters.rest_framework import BooleanFilter, FilterSet
|
||||
|
||||
from .models import Correspondent, Document, Tag
|
||||
|
||||
|
||||
CHAR_KWARGS = (
|
||||
"startswith", "endswith", "contains",
|
||||
"istartswith", "iendswith", "icontains"
|
||||
)
|
||||
|
||||
|
||||
class CorrespondentFilterSet(FilterSet):
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Correspondent
|
||||
fields = {
|
||||
'name': [
|
||||
"name": [
|
||||
"startswith", "endswith", "contains",
|
||||
"istartswith", "iendswith", "icontains"
|
||||
],
|
||||
@@ -18,10 +24,10 @@ class CorrespondentFilterSet(FilterSet):
|
||||
|
||||
class TagFilterSet(FilterSet):
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Tag
|
||||
fields = {
|
||||
'name': [
|
||||
"name": [
|
||||
"startswith", "endswith", "contains",
|
||||
"istartswith", "iendswith", "icontains"
|
||||
],
|
||||
@@ -31,28 +37,24 @@ class TagFilterSet(FilterSet):
|
||||
|
||||
class DocumentFilterSet(FilterSet):
|
||||
|
||||
CHAR_KWARGS = {
|
||||
"lookup_expr": (
|
||||
"startswith",
|
||||
"endswith",
|
||||
"contains",
|
||||
"istartswith",
|
||||
"iendswith",
|
||||
"icontains"
|
||||
)
|
||||
}
|
||||
tags_empty = BooleanFilter(
|
||||
label="Is tagged",
|
||||
field_name="tags",
|
||||
lookup_expr="isnull",
|
||||
exclude=True
|
||||
)
|
||||
|
||||
correspondent__name = CharFilter(name="correspondent__name", **CHAR_KWARGS)
|
||||
correspondent__slug = CharFilter(name="correspondent__slug", **CHAR_KWARGS)
|
||||
tags__name = CharFilter(name="tags__name", **CHAR_KWARGS)
|
||||
tags__slug = CharFilter(name="tags__slug", **CHAR_KWARGS)
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Document
|
||||
fields = {
|
||||
"title": [
|
||||
"startswith", "endswith", "contains",
|
||||
"istartswith", "iendswith", "icontains"
|
||||
],
|
||||
"content": ["contains", "icontains"],
|
||||
|
||||
"title": CHAR_KWARGS,
|
||||
"content": ("contains", "icontains"),
|
||||
|
||||
"correspondent__name": CHAR_KWARGS,
|
||||
"correspondent__slug": CHAR_KWARGS,
|
||||
|
||||
"tags__name": CHAR_KWARGS,
|
||||
"tags__slug": CHAR_KWARGS,
|
||||
|
||||
}
|
||||
|
||||
@@ -2,19 +2,16 @@ import magic
|
||||
import os
|
||||
|
||||
from datetime import datetime
|
||||
from hashlib import sha256
|
||||
from time import mktime
|
||||
|
||||
from django import forms
|
||||
from django.conf import settings
|
||||
|
||||
from .models import Document, Correspondent
|
||||
from .consumer import Consumer
|
||||
|
||||
|
||||
class UploadForm(forms.Form):
|
||||
|
||||
SECRET = settings.SHARED_SECRET
|
||||
TYPE_LOOKUP = {
|
||||
"application/pdf": Document.TYPE_PDF,
|
||||
"image/png": Document.TYPE_PNG,
|
||||
@@ -32,10 +29,9 @@ class UploadForm(forms.Form):
|
||||
required=False
|
||||
)
|
||||
document = forms.FileField()
|
||||
signature = forms.CharField(max_length=256)
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
forms.Form.__init__(*args, **kwargs)
|
||||
forms.Form.__init__(self, *args, **kwargs)
|
||||
self._file_type = None
|
||||
|
||||
def clean_correspondent(self):
|
||||
@@ -82,17 +78,6 @@ class UploadForm(forms.Form):
|
||||
|
||||
return document
|
||||
|
||||
def clean(self):
|
||||
|
||||
corresp = self.clened_data.get("correspondent")
|
||||
title = self.cleaned_data.get("title")
|
||||
signature = self.cleaned_data.get("signature")
|
||||
|
||||
if sha256(corresp + title + self.SECRET).hexdigest() == signature:
|
||||
return self.cleaned_data
|
||||
|
||||
raise forms.ValidationError("The signature provided did not validate")
|
||||
|
||||
def save(self):
|
||||
"""
|
||||
Since the consumer already does a lot of work, it's easier just to save
|
||||
@@ -100,13 +85,13 @@ class UploadForm(forms.Form):
|
||||
form do that as well. Think of it as a poor-man's queue server.
|
||||
"""
|
||||
|
||||
correspondent = self.clened_data.get("correspondent")
|
||||
correspondent = self.cleaned_data.get("correspondent")
|
||||
title = self.cleaned_data.get("title")
|
||||
document = self.cleaned_data.get("document")
|
||||
|
||||
t = int(mktime(datetime.now()))
|
||||
t = int(mktime(datetime.now().timetuple()))
|
||||
file_name = os.path.join(
|
||||
Consumer.CONSUME,
|
||||
settings.CONSUMPTION_DIR,
|
||||
"{} - {}.{}".format(correspondent, title, self._file_type)
|
||||
)
|
||||
|
||||
|
||||
@@ -13,7 +13,6 @@ from dateutil import parser
|
||||
|
||||
from django.conf import settings
|
||||
|
||||
from .consumer import Consumer
|
||||
from .models import Correspondent
|
||||
|
||||
|
||||
@@ -21,7 +20,7 @@ class MailFetcherError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class InvalidMessageError(Exception):
|
||||
class InvalidMessageError(MailFetcherError):
|
||||
pass
|
||||
|
||||
|
||||
@@ -43,7 +42,7 @@ class Message(Loggable):
|
||||
and n attachments, and that we don't care about the message body.
|
||||
"""
|
||||
|
||||
SECRET = settings.SHARED_SECRET
|
||||
SECRET = os.getenv("PAPERLESS_EMAIL_SECRET")
|
||||
|
||||
def __init__(self, data, group=None):
|
||||
"""
|
||||
@@ -76,6 +75,9 @@ class Message(Loggable):
|
||||
continue
|
||||
|
||||
dispositions = content_disposition.strip().split(";")
|
||||
if len(dispositions) < 2:
|
||||
continue
|
||||
|
||||
if not dispositions[0].lower() == "attachment" and \
|
||||
"filename" not in dispositions[1].lower():
|
||||
continue
|
||||
@@ -148,20 +150,23 @@ class Attachment(object):
|
||||
|
||||
class MailFetcher(Loggable):
|
||||
|
||||
def __init__(self):
|
||||
def __init__(self, consume=settings.CONSUMPTION_DIR):
|
||||
|
||||
Loggable.__init__(self)
|
||||
|
||||
self._connection = None
|
||||
self._host = settings.MAIL_CONSUMPTION["HOST"]
|
||||
self._port = settings.MAIL_CONSUMPTION["PORT"]
|
||||
self._username = settings.MAIL_CONSUMPTION["USERNAME"]
|
||||
self._password = settings.MAIL_CONSUMPTION["PASSWORD"]
|
||||
self._inbox = settings.MAIL_CONSUMPTION["INBOX"]
|
||||
self._host = os.getenv("PAPERLESS_CONSUME_MAIL_HOST")
|
||||
self._port = os.getenv("PAPERLESS_CONSUME_MAIL_PORT")
|
||||
self._username = os.getenv("PAPERLESS_CONSUME_MAIL_USER")
|
||||
self._password = os.getenv("PAPERLESS_CONSUME_MAIL_PASS")
|
||||
self._inbox = os.getenv("PAPERLESS_CONSUME_MAIL_INBOX", "INBOX")
|
||||
|
||||
self._enabled = bool(self._host)
|
||||
if self._enabled and Message.SECRET is None:
|
||||
raise MailFetcherError("No PAPERLESS_EMAIL_SECRET defined")
|
||||
|
||||
self.last_checked = datetime.datetime.now()
|
||||
self.last_checked = time.time()
|
||||
self.consume = consume
|
||||
|
||||
def pull(self):
|
||||
"""
|
||||
@@ -182,12 +187,12 @@ class MailFetcher(Loggable):
|
||||
self.log("info", 'Storing email: "{}"'.format(message.subject))
|
||||
|
||||
t = int(time.mktime(message.time.timetuple()))
|
||||
file_name = os.path.join(Consumer.CONSUME, message.file_name)
|
||||
file_name = os.path.join(self.consume, message.file_name)
|
||||
with open(file_name, "wb") as f:
|
||||
f.write(message.attachment.data)
|
||||
os.utime(file_name, times=(t, t))
|
||||
|
||||
self.last_checked = datetime.datetime.now()
|
||||
self.last_checked = time.time()
|
||||
|
||||
def _get_messages(self):
|
||||
|
||||
@@ -205,7 +210,7 @@ class MailFetcher(Loggable):
|
||||
self._connection.close()
|
||||
self._connection.logout()
|
||||
|
||||
except Exception as e:
|
||||
except MailFetcherError as e:
|
||||
self.log("error", str(e))
|
||||
|
||||
return r
|
||||
@@ -219,7 +224,7 @@ class MailFetcher(Loggable):
|
||||
if not login[0] == "OK":
|
||||
raise MailFetcherError("Can't log into mail: {}".format(login[1]))
|
||||
|
||||
inbox = self._connection.select("INBOX")
|
||||
inbox = self._connection.select(self._inbox)
|
||||
if not inbox[0] == "OK":
|
||||
raise MailFetcherError("Can't find the inbox: {}".format(inbox[1]))
|
||||
|
||||
|
||||
119
src/documents/management/commands/change_storage_type.py
Normal file
119
src/documents/management/commands/change_storage_type.py
Normal file
@@ -0,0 +1,119 @@
|
||||
import os
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.management.base import BaseCommand, CommandError
|
||||
from termcolor import colored as coloured
|
||||
|
||||
from documents.models import Document
|
||||
from paperless.db import GnuPG
|
||||
|
||||
|
||||
class Command(BaseCommand):
|
||||
|
||||
help = (
|
||||
"This is how you migrate your stored documents from an encrypted "
|
||||
"state to an unencrypted one (or vice-versa)"
|
||||
)
|
||||
|
||||
def add_arguments(self, parser):
|
||||
|
||||
parser.add_argument(
|
||||
"from",
|
||||
choices=("gpg", "unencrypted"),
|
||||
help="The state you want to change your documents from"
|
||||
)
|
||||
parser.add_argument(
|
||||
"to",
|
||||
choices=("gpg", "unencrypted"),
|
||||
help="The state you want to change your documents to"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--passphrase",
|
||||
help="If PAPERLESS_PASSPHRASE isn't set already, you need to "
|
||||
"specify it here"
|
||||
)
|
||||
|
||||
def handle(self, *args, **options):
|
||||
|
||||
try:
|
||||
print(coloured(
|
||||
"\n\nWARNING: This script is going to work directly on your "
|
||||
"document originals, so\nWARNING: you probably shouldn't run "
|
||||
"this unless you've got a recent backup\nWARNING: handy. It "
|
||||
"*should* work without a hitch, but be safe and backup your\n"
|
||||
"WARNING: stuff first.\n\nHit Ctrl+C to exit now, or Enter to "
|
||||
"continue.\n\n",
|
||||
"yellow",
|
||||
attrs=("bold",)
|
||||
))
|
||||
__ = input()
|
||||
except KeyboardInterrupt:
|
||||
return
|
||||
|
||||
if options["from"] == options["to"]:
|
||||
raise CommandError(
|
||||
'The "from" and "to" values can\'t be the same.'
|
||||
)
|
||||
|
||||
passphrase = options["passphrase"] or settings.PASSPHRASE
|
||||
if not passphrase:
|
||||
raise CommandError(
|
||||
"Passphrase not defined. Please set it with --passphrase or "
|
||||
"by declaring it in your environment or your config."
|
||||
)
|
||||
|
||||
if options["from"] == "gpg" and options["to"] == "unencrypted":
|
||||
self.__gpg_to_unencrypted(passphrase)
|
||||
elif options["from"] == "unencrypted" and options["to"] == "gpg":
|
||||
self.__unencrypted_to_gpg(passphrase)
|
||||
|
||||
@staticmethod
|
||||
def __gpg_to_unencrypted(passphrase):
|
||||
|
||||
encrypted_files = Document.objects.filter(
|
||||
storage_type=Document.STORAGE_TYPE_GPG)
|
||||
|
||||
for document in encrypted_files:
|
||||
|
||||
print(coloured("Decrypting {}".format(document), "green"))
|
||||
|
||||
old_paths = [document.source_path, document.thumbnail_path]
|
||||
raw_document = GnuPG.decrypted(document.source_file, passphrase)
|
||||
raw_thumb = GnuPG.decrypted(document.thumbnail_file, passphrase)
|
||||
|
||||
document.storage_type = Document.STORAGE_TYPE_UNENCRYPTED
|
||||
|
||||
with open(document.source_path, "wb") as f:
|
||||
f.write(raw_document)
|
||||
|
||||
with open(document.thumbnail_path, "wb") as f:
|
||||
f.write(raw_thumb)
|
||||
|
||||
document.save(update_fields=("storage_type",))
|
||||
|
||||
for path in old_paths:
|
||||
os.unlink(path)
|
||||
|
||||
@staticmethod
|
||||
def __unencrypted_to_gpg(passphrase):
|
||||
|
||||
unencrypted_files = Document.objects.filter(
|
||||
storage_type=Document.STORAGE_TYPE_UNENCRYPTED)
|
||||
|
||||
for document in unencrypted_files:
|
||||
|
||||
print(coloured("Encrypting {}".format(document), "green"))
|
||||
|
||||
old_paths = [document.source_path, document.thumbnail_path]
|
||||
with open(document.source_path, "rb") as raw_document:
|
||||
with open(document.thumbnail_path, "rb") as raw_thumb:
|
||||
document.storage_type = Document.STORAGE_TYPE_GPG
|
||||
with open(document.source_path, "wb") as f:
|
||||
f.write(GnuPG.encrypted(raw_document, passphrase))
|
||||
with open(document.thumbnail_path, "wb") as f:
|
||||
f.write(GnuPG.encrypted(raw_thumb, passphrase))
|
||||
|
||||
document.save(update_fields=("storage_type",))
|
||||
|
||||
for path in old_paths:
|
||||
os.unlink(path)
|
||||
@@ -1,4 +1,3 @@
|
||||
import datetime
|
||||
import logging
|
||||
import os
|
||||
import time
|
||||
@@ -9,6 +8,11 @@ from django.core.management.base import BaseCommand, CommandError
|
||||
from ...consumer import Consumer, ConsumerError
|
||||
from ...mail import MailFetcher, MailFetcherError
|
||||
|
||||
try:
|
||||
from inotify_simple import INotify, flags
|
||||
except ImportError:
|
||||
INotify = flags = None
|
||||
|
||||
|
||||
class Command(BaseCommand):
|
||||
"""
|
||||
@@ -16,9 +20,6 @@ class Command(BaseCommand):
|
||||
consumption directory, and fetch any mail available.
|
||||
"""
|
||||
|
||||
LOOP_TIME = settings.CONSUMER_LOOP_TIME
|
||||
MAIL_DELTA = datetime.timedelta(minutes=10)
|
||||
|
||||
ORIGINAL_DOCS = os.path.join(settings.MEDIA_ROOT, "documents", "originals")
|
||||
THUMB_DOCS = os.path.join(settings.MEDIA_ROOT, "documents", "thumbnails")
|
||||
|
||||
@@ -28,44 +29,117 @@ class Command(BaseCommand):
|
||||
|
||||
self.file_consumer = None
|
||||
self.mail_fetcher = None
|
||||
self.first_iteration = True
|
||||
|
||||
BaseCommand.__init__(self, *args, **kwargs)
|
||||
|
||||
def add_arguments(self, parser):
|
||||
parser.add_argument(
|
||||
"directory",
|
||||
default=settings.CONSUMPTION_DIR,
|
||||
nargs="?",
|
||||
help="The consumption directory."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--loop-time",
|
||||
default=settings.CONSUMER_LOOP_TIME,
|
||||
type=int,
|
||||
help="Wait time between each loop (in seconds)."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mail-delta",
|
||||
default=10,
|
||||
type=int,
|
||||
help="Wait time between each mail fetch (in minutes)."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--oneshot",
|
||||
action="store_true",
|
||||
help="Run only once."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no-inotify",
|
||||
action="store_true",
|
||||
help="Don't use inotify, even if it's available.",
|
||||
default=False
|
||||
)
|
||||
|
||||
def handle(self, *args, **options):
|
||||
|
||||
self.verbosity = options["verbosity"]
|
||||
directory = options["directory"]
|
||||
loop_time = options["loop_time"]
|
||||
mail_delta = options["mail_delta"] * 60
|
||||
use_inotify = INotify is not None and options["no_inotify"] is False
|
||||
|
||||
try:
|
||||
self.file_consumer = Consumer()
|
||||
self.mail_fetcher = MailFetcher()
|
||||
self.file_consumer = Consumer(consume=directory)
|
||||
self.mail_fetcher = MailFetcher(consume=directory)
|
||||
except (ConsumerError, MailFetcherError) as e:
|
||||
raise CommandError(e)
|
||||
|
||||
for path in (self.ORIGINAL_DOCS, self.THUMB_DOCS):
|
||||
try:
|
||||
os.makedirs(path)
|
||||
except FileExistsError:
|
||||
pass
|
||||
for d in (self.ORIGINAL_DOCS, self.THUMB_DOCS):
|
||||
os.makedirs(d, exist_ok=True)
|
||||
|
||||
logging.getLogger(__name__).info(
|
||||
"Starting document consumer at {}".format(settings.CONSUMPTION_DIR)
|
||||
"Starting document consumer at {}{}".format(
|
||||
directory,
|
||||
" with inotify" if use_inotify else ""
|
||||
)
|
||||
)
|
||||
|
||||
try:
|
||||
while True:
|
||||
self.loop()
|
||||
time.sleep(self.LOOP_TIME)
|
||||
if self.verbosity > 1:
|
||||
print(".")
|
||||
except KeyboardInterrupt:
|
||||
print("Exiting")
|
||||
if options["oneshot"]:
|
||||
self.loop_step(mail_delta)
|
||||
else:
|
||||
try:
|
||||
if use_inotify:
|
||||
self.loop_inotify(mail_delta)
|
||||
else:
|
||||
self.loop(loop_time, mail_delta)
|
||||
except KeyboardInterrupt:
|
||||
print("Exiting")
|
||||
|
||||
def loop(self):
|
||||
def loop(self, loop_time, mail_delta):
|
||||
while True:
|
||||
start_time = time.time()
|
||||
if self.verbosity > 1:
|
||||
print(".", int(start_time))
|
||||
self.loop_step(mail_delta, start_time)
|
||||
# Sleep until the start of the next loop step
|
||||
time.sleep(max(0, start_time + loop_time - time.time()))
|
||||
|
||||
# Consume whatever files we can
|
||||
self.file_consumer.consume()
|
||||
def loop_step(self, mail_delta, time_now=None):
|
||||
|
||||
# Occasionally fetch mail and store it to be consumed on the next loop
|
||||
delta = self.mail_fetcher.last_checked + self.MAIL_DELTA
|
||||
if delta < datetime.datetime.now():
|
||||
# We fetch email when we first start up so that it is not necessary to
|
||||
# wait for 10 minutes after making changes to the config file.
|
||||
next_mail_time = self.mail_fetcher.last_checked + mail_delta
|
||||
if self.first_iteration or time_now > next_mail_time:
|
||||
self.first_iteration = False
|
||||
self.mail_fetcher.pull()
|
||||
|
||||
self.file_consumer.consume_new_files()
|
||||
|
||||
def loop_inotify(self, mail_delta):
|
||||
directory = self.file_consumer.consume
|
||||
inotify = INotify()
|
||||
inotify.add_watch(directory, flags.CLOSE_WRITE | flags.MOVED_TO)
|
||||
|
||||
# Run initial mail fetch and consume all currently existing documents
|
||||
self.loop_step(mail_delta)
|
||||
next_mail_time = self.mail_fetcher.last_checked + mail_delta
|
||||
|
||||
while True:
|
||||
# Consume documents until next_mail_time
|
||||
while True:
|
||||
delta = next_mail_time - time.time()
|
||||
if delta > 0:
|
||||
for event in inotify.read(timeout=delta):
|
||||
file = os.path.join(directory, event.name)
|
||||
if os.path.isfile(file):
|
||||
self.file_consumer.try_consume_file(file)
|
||||
else:
|
||||
break
|
||||
|
||||
self.mail_fetcher.pull()
|
||||
next_mail_time = self.mail_fetcher.last_checked + mail_delta
|
||||
|
||||
82
src/documents/management/commands/document_correspondents.py
Normal file
82
src/documents/management/commands/document_correspondents.py
Normal file
@@ -0,0 +1,82 @@
|
||||
import sys
|
||||
|
||||
from django.core.management.base import BaseCommand
|
||||
|
||||
from documents.models import Correspondent, Document
|
||||
|
||||
from ...mixins import Renderable
|
||||
|
||||
|
||||
class Command(Renderable, BaseCommand):
|
||||
|
||||
help = """
|
||||
Using the current set of correspondent rules, apply said rules to all
|
||||
documents in the database, effectively allowing you to back-tag all
|
||||
previously indexed documents with correspondent created (or modified)
|
||||
after their initial import.
|
||||
""".replace(" ", "")
|
||||
|
||||
TOO_MANY_CONTINUE = (
|
||||
"Detected {} potential correspondents for {}, so we've opted for {}")
|
||||
TOO_MANY_SKIP = (
|
||||
"Detected {} potential correspondents for {}, so we're skipping it")
|
||||
CHANGE_MESSAGE = (
|
||||
'Document {}: "{}" was given the correspondent id {}: "{}"')
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.verbosity = 0
|
||||
BaseCommand.__init__(self, *args, **kwargs)
|
||||
|
||||
def add_arguments(self, parser):
|
||||
parser.add_argument(
|
||||
"--use-first",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="By default this command won't try to assign a correspondent "
|
||||
"if more than one matches the document. Use this flag if "
|
||||
"you'd rather it just pick the first one it finds."
|
||||
)
|
||||
|
||||
def handle(self, *args, **options):
|
||||
|
||||
self.verbosity = options["verbosity"]
|
||||
|
||||
for document in Document.objects.filter(correspondent__isnull=True):
|
||||
|
||||
potential_correspondents = list(
|
||||
Correspondent.match_all(document.content))
|
||||
|
||||
if not potential_correspondents:
|
||||
continue
|
||||
|
||||
potential_count = len(potential_correspondents)
|
||||
correspondent = potential_correspondents[0]
|
||||
|
||||
if potential_count > 1:
|
||||
if not options["use_first"]:
|
||||
print(
|
||||
self.TOO_MANY_SKIP.format(potential_count, document),
|
||||
file=sys.stderr
|
||||
)
|
||||
continue
|
||||
print(
|
||||
self.TOO_MANY_CONTINUE.format(
|
||||
potential_count,
|
||||
document,
|
||||
correspondent
|
||||
),
|
||||
file=sys.stderr
|
||||
)
|
||||
|
||||
document.correspondent = correspondent
|
||||
document.save(update_fields=("correspondent",))
|
||||
|
||||
print(
|
||||
self.CHANGE_MESSAGE.format(
|
||||
document.pk,
|
||||
document.title,
|
||||
correspondent.pk,
|
||||
correspondent.name
|
||||
),
|
||||
file=sys.stderr
|
||||
)
|
||||
@@ -1,8 +1,8 @@
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
import shutil
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.management.base import BaseCommand, CommandError
|
||||
from django.core import serializers
|
||||
|
||||
@@ -10,6 +10,7 @@ from documents.models import Document, Correspondent, Tag
|
||||
from paperless.db import GnuPG
|
||||
|
||||
from ...mixins import Renderable
|
||||
from documents.settings import EXPORTER_FILE_NAME, EXPORTER_THUMBNAIL_NAME
|
||||
|
||||
|
||||
class Command(Renderable, BaseCommand):
|
||||
@@ -44,9 +45,6 @@ class Command(Renderable, BaseCommand):
|
||||
if not os.access(self.target, os.W_OK):
|
||||
raise CommandError("That path doesn't appear to be writable")
|
||||
|
||||
if not settings.PASSPHRASE:
|
||||
settings.PASSPHRASE = input("Please enter the passphrase: ")
|
||||
|
||||
if options["legacy"]:
|
||||
self.dump_legacy()
|
||||
else:
|
||||
@@ -57,19 +55,40 @@ class Command(Renderable, BaseCommand):
|
||||
documents = Document.objects.all()
|
||||
document_map = {d.pk: d for d in documents}
|
||||
manifest = json.loads(serializers.serialize("json", documents))
|
||||
for document_dict in manifest:
|
||||
|
||||
for index, document_dict in enumerate(manifest):
|
||||
|
||||
# Force output to unencrypted as that will be the current state.
|
||||
# The importer will make the decision to encrypt or not.
|
||||
manifest[index]["fields"]["storage_type"] = Document.STORAGE_TYPE_UNENCRYPTED # NOQA: E501
|
||||
|
||||
document = document_map[document_dict["pk"]]
|
||||
|
||||
target = os.path.join(self.target, document.file_name)
|
||||
document_dict["__exported_file_name__"] = target
|
||||
file_target = os.path.join(self.target, document.file_name)
|
||||
|
||||
print("Exporting: {}".format(target))
|
||||
thumbnail_name = document.file_name + "-thumbnail.png"
|
||||
thumbnail_target = os.path.join(self.target, thumbnail_name)
|
||||
|
||||
with open(target, "wb") as f:
|
||||
f.write(GnuPG.decrypted(document.source_file))
|
||||
t = int(time.mktime(document.created.timetuple()))
|
||||
os.utime(target, times=(t, t))
|
||||
document_dict[EXPORTER_FILE_NAME] = document.file_name
|
||||
document_dict[EXPORTER_THUMBNAIL_NAME] = thumbnail_name
|
||||
|
||||
print("Exporting: {}".format(file_target))
|
||||
|
||||
t = int(time.mktime(document.created.timetuple()))
|
||||
if document.storage_type == Document.STORAGE_TYPE_GPG:
|
||||
|
||||
with open(file_target, "wb") as f:
|
||||
f.write(GnuPG.decrypted(document.source_file))
|
||||
os.utime(file_target, times=(t, t))
|
||||
|
||||
with open(thumbnail_target, "wb") as f:
|
||||
f.write(GnuPG.decrypted(document.thumbnail_file))
|
||||
os.utime(thumbnail_target, times=(t, t))
|
||||
|
||||
else:
|
||||
|
||||
shutil.copy(document.source_path, file_target)
|
||||
shutil.copy(document.thumbnail_path, thumbnail_target)
|
||||
|
||||
manifest += json.loads(
|
||||
serializers.serialize("json", Correspondent.objects.all()))
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
import json
|
||||
import os
|
||||
import shutil
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.management.base import BaseCommand, CommandError
|
||||
@@ -10,6 +11,8 @@ from paperless.db import GnuPG
|
||||
|
||||
from ...mixins import Renderable
|
||||
|
||||
from documents.settings import EXPORTER_FILE_NAME, EXPORTER_THUMBNAIL_NAME
|
||||
|
||||
|
||||
class Command(Renderable, BaseCommand):
|
||||
|
||||
@@ -44,12 +47,6 @@ class Command(Renderable, BaseCommand):
|
||||
|
||||
self._check_manifest()
|
||||
|
||||
if not settings.PASSPHRASE:
|
||||
raise CommandError(
|
||||
"You need to define a passphrase before continuing. Please "
|
||||
"consult the documentation for setting up Paperless."
|
||||
)
|
||||
|
||||
# Fill up the database with whatever is in the manifest
|
||||
call_command("loaddata", manifest_path)
|
||||
|
||||
@@ -70,13 +67,13 @@ class Command(Renderable, BaseCommand):
|
||||
if not record["model"] == "documents.document":
|
||||
continue
|
||||
|
||||
if "__exported_file_name__" not in record:
|
||||
if EXPORTER_FILE_NAME not in record:
|
||||
raise CommandError(
|
||||
'The manifest file contains a record which does not '
|
||||
'refer to an actual document file.'
|
||||
)
|
||||
|
||||
doc_file = record["__exported_file_name__"]
|
||||
doc_file = record[EXPORTER_FILE_NAME]
|
||||
if not os.path.exists(os.path.join(self.source, doc_file)):
|
||||
raise CommandError(
|
||||
'The manifest file refers to "{}" which does not '
|
||||
@@ -90,10 +87,40 @@ class Command(Renderable, BaseCommand):
|
||||
if not record["model"] == "documents.document":
|
||||
continue
|
||||
|
||||
doc_file = record["__exported_file_name__"]
|
||||
doc_file = record[EXPORTER_FILE_NAME]
|
||||
thumb_file = record[EXPORTER_THUMBNAIL_NAME]
|
||||
document = Document.objects.get(pk=record["pk"])
|
||||
with open(doc_file, "rb") as unencrypted:
|
||||
with open(document.source_path, "wb") as encrypted:
|
||||
print("Encrypting {} and saving it to {}".format(
|
||||
doc_file, document.source_path))
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
|
||||
document_path = os.path.join(self.source, doc_file)
|
||||
thumbnail_path = os.path.join(self.source, thumb_file)
|
||||
|
||||
if settings.PASSPHRASE:
|
||||
|
||||
with open(document_path, "rb") as unencrypted:
|
||||
with open(document.source_path, "wb") as encrypted:
|
||||
print("Encrypting {} and saving it to {}".format(
|
||||
doc_file, document.source_path))
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
|
||||
with open(thumbnail_path, "rb") as unencrypted:
|
||||
with open(document.thumbnail_path, "wb") as encrypted:
|
||||
print("Encrypting {} and saving it to {}".format(
|
||||
thumb_file, document.thumbnail_path))
|
||||
encrypted.write(GnuPG.encrypted(unencrypted))
|
||||
|
||||
else:
|
||||
|
||||
shutil.copy(document_path, document.source_path)
|
||||
shutil.copy(thumbnail_path, document.thumbnail_path)
|
||||
|
||||
# Reset the storage type to whatever we've used while importing
|
||||
|
||||
storage_type = Document.STORAGE_TYPE_UNENCRYPTED
|
||||
if settings.PASSPHRASE:
|
||||
storage_type = Document.STORAGE_TYPE_GPG
|
||||
|
||||
Document.objects.filter(
|
||||
pk__in=[r["pk"] for r in self.manifest]
|
||||
).update(
|
||||
storage_type=storage_type
|
||||
)
|
||||
|
||||
@@ -50,7 +50,7 @@ class GroupConcat(models.Aggregate):
|
||||
|
||||
def _get_template(self, separator):
|
||||
if self.engine == self.ENGINE_MYSQL:
|
||||
return "%(function)s(%(expressions)s, SEPARATOR '{}')".format(
|
||||
return "%(function)s(%(expressions)s SEPARATOR '{}')".format(
|
||||
separator)
|
||||
return "%(function)s(%(expressions)s, '{}')".format(separator)
|
||||
|
||||
|
||||
@@ -3,6 +3,7 @@
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
@@ -19,7 +20,7 @@ class Migration(migrations.Migration):
|
||||
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
|
||||
('sender', models.CharField(blank=True, db_index=True, max_length=128)),
|
||||
('title', models.CharField(blank=True, db_index=True, max_length=128)),
|
||||
('content', models.TextField(db_index=True)),
|
||||
('content', models.TextField(db_index=("mysql" not in settings.DATABASES["default"]["ENGINE"]))),
|
||||
('created', models.DateTimeField(auto_now_add=True)),
|
||||
('modified', models.DateTimeField(auto_now=True)),
|
||||
],
|
||||
|
||||
@@ -32,7 +32,6 @@ def realign_senders(apps, schema_editor):
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0002_auto_20151226_1316'),
|
||||
]
|
||||
@@ -47,7 +46,11 @@ class Migration(migrations.Migration):
|
||||
],
|
||||
),
|
||||
migrations.RunPython(move_sender_strings_to_sender_model),
|
||||
migrations.AlterField(
|
||||
migrations.RemoveField(
|
||||
model_name='document',
|
||||
name='sender',
|
||||
),
|
||||
migrations.AddField(
|
||||
model_name='document',
|
||||
name='sender',
|
||||
field=models.ForeignKey(blank=True, on_delete=django.db.models.deletion.CASCADE, to='documents.Sender'),
|
||||
|
||||
@@ -6,7 +6,7 @@ from django.db import migrations
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
atomic = False
|
||||
dependencies = [
|
||||
('documents', '0010_log'),
|
||||
]
|
||||
|
||||
@@ -38,6 +38,9 @@ class GnuPG(object):
|
||||
|
||||
def move_documents_and_create_thumbnails(apps, schema_editor):
|
||||
|
||||
os.makedirs(os.path.join(settings.MEDIA_ROOT, "documents", "originals"), exist_ok=True)
|
||||
os.makedirs(os.path.join(settings.MEDIA_ROOT, "documents", "thumbnails"), exist_ok=True)
|
||||
|
||||
documents = os.listdir(os.path.join(settings.MEDIA_ROOT, "documents"))
|
||||
|
||||
if set(documents) == {"originals", "thumbnails"}:
|
||||
@@ -109,7 +112,6 @@ def move_documents_and_create_thumbnails(apps, schema_editor):
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0011_auto_20160303_1929'),
|
||||
]
|
||||
|
||||
@@ -128,7 +128,6 @@ def do_nothing(apps, schema_editor):
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0013_auto_20160325_2111'),
|
||||
]
|
||||
@@ -159,9 +158,4 @@ class Migration(migrations.Migration):
|
||||
name='modified',
|
||||
field=models.DateTimeField(auto_now=True, db_index=True),
|
||||
),
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='checksum',
|
||||
field=models.CharField(editable=False, help_text='The checksum of the original document (before it was encrypted). We use this to prevent duplicate document imports.', max_length=32, unique=True),
|
||||
),
|
||||
]
|
||||
|
||||
@@ -12,6 +12,11 @@ class Migration(migrations.Migration):
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='checksum',
|
||||
field=models.CharField(editable=False, help_text='The checksum of the original document (before it was encrypted). We use this to prevent duplicate document imports.', max_length=32, unique=True),
|
||||
),
|
||||
migrations.AddField(
|
||||
model_name='correspondent',
|
||||
name='is_insensitive',
|
||||
|
||||
21
src/documents/migrations/0016_auto_20170325_1558.py
Normal file
21
src/documents/migrations/0016_auto_20170325_1558.py
Normal file
@@ -0,0 +1,21 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-03-25 15:58
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0015_add_insensitive_to_match'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='content',
|
||||
field=models.TextField(blank=True, db_index=("mysql" not in settings.DATABASES["default"]["ENGINE"]), help_text='The raw, text-only data of the document. This field is primarily used for searching.'),
|
||||
),
|
||||
]
|
||||
25
src/documents/migrations/0017_auto_20170512_0507.py
Normal file
25
src/documents/migrations/0017_auto_20170512_0507.py
Normal file
@@ -0,0 +1,25 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-05-12 05:07
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0016_auto_20170325_1558'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='correspondent',
|
||||
name='matching_algorithm',
|
||||
field=models.PositiveIntegerField(choices=[(1, 'Any'), (2, 'All'), (3, 'Literal'), (4, 'Regular Expression'), (5, 'Fuzzy Match')], default=1, help_text='Which algorithm you want to use when matching text to the OCR\'d PDF. Here, "any" looks for any occurrence of any word provided in the PDF, while "all" requires that every word provided appear in the PDF, albeit not in the order provided. A "literal" match means that the text you enter must appear in the PDF exactly as you\'ve entered it, and "regular expression" uses a regex to match the PDF. (If you don\'t know what a regex is, you probably don\'t want this option.) Finally, a "fuzzy match" looks for words or phrases that are mostly—but not exactly—the same, which can be useful for matching against documents containg imperfections that foil accurate OCR.'),
|
||||
),
|
||||
migrations.AlterField(
|
||||
model_name='tag',
|
||||
name='matching_algorithm',
|
||||
field=models.PositiveIntegerField(choices=[(1, 'Any'), (2, 'All'), (3, 'Literal'), (4, 'Regular Expression'), (5, 'Fuzzy Match')], default=1, help_text='Which algorithm you want to use when matching text to the OCR\'d PDF. Here, "any" looks for any occurrence of any word provided in the PDF, while "all" requires that every word provided appear in the PDF, albeit not in the order provided. A "literal" match means that the text you enter must appear in the PDF exactly as you\'ve entered it, and "regular expression" uses a regex to match the PDF. (If you don\'t know what a regex is, you probably don\'t want this option.) Finally, a "fuzzy match" looks for words or phrases that are mostly—but not exactly—the same, which can be useful for matching against documents containg imperfections that foil accurate OCR.'),
|
||||
),
|
||||
]
|
||||
21
src/documents/migrations/0018_auto_20170715_1712.py
Normal file
21
src/documents/migrations/0018_auto_20170715_1712.py
Normal file
@@ -0,0 +1,21 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-07-15 17:12
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
import django.db.models.deletion
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0017_auto_20170512_0507'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='correspondent',
|
||||
field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, related_name='documents', to='documents.Correspondent'),
|
||||
),
|
||||
]
|
||||
24
src/documents/migrations/0019_add_consumer_user.py
Normal file
24
src/documents/migrations/0019_add_consumer_user.py
Normal file
@@ -0,0 +1,24 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.10.5 on 2017-07-15 17:12
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.contrib.auth.models import User
|
||||
from django.db import migrations
|
||||
|
||||
|
||||
def forwards_func(apps, schema_editor):
|
||||
User.objects.create(username="consumer")
|
||||
|
||||
|
||||
def reverse_func(apps, schema_editor):
|
||||
User.objects.get(username="consumer").delete()
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
dependencies = [
|
||||
('documents', '0018_auto_20170715_1712'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.RunPython(forwards_func, reverse_func),
|
||||
]
|
||||
27
src/documents/migrations/0020_document_added.py
Normal file
27
src/documents/migrations/0020_document_added.py
Normal file
@@ -0,0 +1,27 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
import django.utils.timezone
|
||||
|
||||
|
||||
def set_added_time_to_created_time(apps, schema_editor):
|
||||
Document = apps.get_model("documents", "Document")
|
||||
for doc in Document.objects.all():
|
||||
doc.added = doc.created
|
||||
doc.save()
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
dependencies = [
|
||||
('documents', '0019_add_consumer_user'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AddField(
|
||||
model_name='document',
|
||||
name='added',
|
||||
field=models.DateTimeField(db_index=True, default=django.utils.timezone.now, editable=False),
|
||||
),
|
||||
migrations.RunPython(set_added_time_to_created_time)
|
||||
]
|
||||
30
src/documents/migrations/0021_document_storage_type.py
Normal file
30
src/documents/migrations/0021_document_storage_type.py
Normal file
@@ -0,0 +1,30 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# Generated by Django 1.11.10 on 2018-02-04 13:07
|
||||
from __future__ import unicode_literals
|
||||
|
||||
from django.db import migrations, models
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0020_document_added'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
|
||||
# Add the field with the default GPG-encrypted value
|
||||
migrations.AddField(
|
||||
model_name='document',
|
||||
name='storage_type',
|
||||
field=models.CharField(choices=[('unencrypted', 'Unencrypted'), ('gpg', 'Encrypted with GNU Privacy Guard')], default='gpg', editable=False, max_length=11),
|
||||
),
|
||||
|
||||
# Now that the field is added, change the default to unencrypted
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='storage_type',
|
||||
field=models.CharField(choices=[('unencrypted', 'Unencrypted'), ('gpg', 'Encrypted with GNU Privacy Guard')], default='unencrypted', editable=False, max_length=11),
|
||||
),
|
||||
|
||||
]
|
||||
52
src/documents/migrations/0022_auto_20181007_1420.py
Normal file
52
src/documents/migrations/0022_auto_20181007_1420.py
Normal file
@@ -0,0 +1,52 @@
|
||||
# Generated by Django 2.0.8 on 2018-10-07 14:20
|
||||
|
||||
from django.db import migrations, models
|
||||
from django.utils.text import slugify
|
||||
|
||||
|
||||
def re_slug_all_the_things(apps, schema_editor):
|
||||
"""
|
||||
Rewrite all slug values to make sure they're actually slugs before we brand
|
||||
them as uneditable.
|
||||
"""
|
||||
|
||||
Tag = apps.get_model("documents", "Tag")
|
||||
Correspondent = apps.get_model("documents", "Tag")
|
||||
|
||||
for klass in (Tag, Correspondent):
|
||||
for instance in klass.objects.all():
|
||||
klass.objects.filter(
|
||||
pk=instance.pk
|
||||
).update(
|
||||
slug=slugify(instance.slug)
|
||||
)
|
||||
|
||||
|
||||
class Migration(migrations.Migration):
|
||||
|
||||
dependencies = [
|
||||
('documents', '0021_document_storage_type'),
|
||||
]
|
||||
|
||||
operations = [
|
||||
migrations.AlterModelOptions(
|
||||
name='tag',
|
||||
options={'ordering': ('name',)},
|
||||
),
|
||||
migrations.AlterField(
|
||||
model_name='correspondent',
|
||||
name='slug',
|
||||
field=models.SlugField(blank=True, editable=False),
|
||||
),
|
||||
migrations.AlterField(
|
||||
model_name='document',
|
||||
name='file_type',
|
||||
field=models.CharField(choices=[('pdf', 'PDF'), ('png', 'PNG'), ('jpg', 'JPG'), ('gif', 'GIF'), ('tiff', 'TIFF'), ('txt', 'TXT'), ('csv', 'CSV'), ('md', 'MD')], editable=False, max_length=4),
|
||||
),
|
||||
migrations.AlterField(
|
||||
model_name='tag',
|
||||
name='slug',
|
||||
field=models.SlugField(blank=True, editable=False),
|
||||
),
|
||||
migrations.RunPython(re_slug_all_the_things, migrations.RunPython.noop)
|
||||
]
|
||||
@@ -1,9 +1,4 @@
|
||||
from django.contrib.auth.mixins import AccessMixin
|
||||
from django.contrib.auth import authenticate, login
|
||||
import base64
|
||||
|
||||
|
||||
class Renderable(object):
|
||||
class Renderable:
|
||||
"""
|
||||
A handy mixin to make it easier/cleaner to print output based on a
|
||||
verbosity value.
|
||||
@@ -12,46 +7,3 @@ class Renderable(object):
|
||||
def _render(self, text, verbosity):
|
||||
if self.verbosity >= verbosity:
|
||||
print(text)
|
||||
|
||||
|
||||
class SessionOrBasicAuthMixin(AccessMixin):
|
||||
"""
|
||||
Session or Basic Authentication mixin for Django.
|
||||
It determines if the requester is already logged in or if they have
|
||||
provided proper http-authorization and returning the view if all goes
|
||||
well, otherwise responding with a 401.
|
||||
|
||||
Base for mixin found here: https://djangosnippets.org/snippets/3073/
|
||||
"""
|
||||
|
||||
def dispatch(self, request, *args, **kwargs):
|
||||
|
||||
# check if user is authenticated via the session
|
||||
if request.user.is_authenticated:
|
||||
|
||||
# Already logged in, just return the view.
|
||||
return super(SessionOrBasicAuthMixin, self).dispatch(
|
||||
request, *args, **kwargs
|
||||
)
|
||||
|
||||
# apparently not authenticated via session, maybe via HTTP Basic?
|
||||
if 'HTTP_AUTHORIZATION' in request.META:
|
||||
auth = request.META['HTTP_AUTHORIZATION'].split()
|
||||
if len(auth) == 2:
|
||||
# NOTE: Support for only basic authentication
|
||||
if auth[0].lower() == "basic":
|
||||
authString = base64.b64decode(auth[1]).decode('utf-8')
|
||||
uname, passwd = authString.split(':')
|
||||
user = authenticate(username=uname, password=passwd)
|
||||
if user is not None:
|
||||
if user.is_active:
|
||||
login(request, user)
|
||||
request.user = user
|
||||
return super(
|
||||
SessionOrBasicAuthMixin, self
|
||||
).dispatch(
|
||||
request, *args, **kwargs
|
||||
)
|
||||
|
||||
# nope, really not authenticated
|
||||
return self.handle_no_permission()
|
||||
|
||||
@@ -1,19 +1,26 @@
|
||||
import dateutil.parser
|
||||
# coding=utf-8
|
||||
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import uuid
|
||||
|
||||
from collections import OrderedDict
|
||||
|
||||
import dateutil.parser
|
||||
from django.conf import settings
|
||||
from django.core.urlresolvers import reverse
|
||||
from django.db import models
|
||||
from django.template.defaultfilters import slugify
|
||||
from django.utils import timezone
|
||||
from django.utils.text import slugify
|
||||
from fuzzywuzzy import fuzz
|
||||
|
||||
from .managers import LogManager
|
||||
|
||||
try:
|
||||
from django.core.urlresolvers import reverse
|
||||
except ImportError:
|
||||
from django.urls import reverse
|
||||
|
||||
|
||||
class MatchingModel(models.Model):
|
||||
|
||||
@@ -21,15 +28,17 @@ class MatchingModel(models.Model):
|
||||
MATCH_ALL = 2
|
||||
MATCH_LITERAL = 3
|
||||
MATCH_REGEX = 4
|
||||
MATCH_FUZZY = 5
|
||||
MATCHING_ALGORITHMS = (
|
||||
(MATCH_ANY, "Any"),
|
||||
(MATCH_ALL, "All"),
|
||||
(MATCH_LITERAL, "Literal"),
|
||||
(MATCH_REGEX, "Regular Expression"),
|
||||
(MATCH_FUZZY, "Fuzzy Match"),
|
||||
)
|
||||
|
||||
name = models.CharField(max_length=128, unique=True)
|
||||
slug = models.SlugField(blank=True)
|
||||
slug = models.SlugField(blank=True, editable=False)
|
||||
|
||||
match = models.CharField(max_length=256, blank=True)
|
||||
matching_algorithm = models.PositiveIntegerField(
|
||||
@@ -42,15 +51,19 @@ class MatchingModel(models.Model):
|
||||
"provided appear in the PDF, albeit not in the order provided. A "
|
||||
"\"literal\" match means that the text you enter must appear in "
|
||||
"the PDF exactly as you've entered it, and \"regular expression\" "
|
||||
"uses a regex to match the PDF. If you don't know what a regex "
|
||||
"is, you probably don't want this option."
|
||||
"uses a regex to match the PDF. (If you don't know what a regex "
|
||||
"is, you probably don't want this option.) Finally, a \"fuzzy "
|
||||
"match\" looks for words or phrases that are mostly—but not "
|
||||
"exactly—the same, which can be useful for matching against "
|
||||
"documents containg imperfections that foil accurate OCR."
|
||||
)
|
||||
)
|
||||
|
||||
is_insensitive = models.BooleanField(default=True)
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
abstract = True
|
||||
ordering = ("name",)
|
||||
|
||||
def __str__(self):
|
||||
return self.name
|
||||
@@ -83,7 +96,7 @@ class MatchingModel(models.Model):
|
||||
search_kwargs = {"flags": re.IGNORECASE}
|
||||
|
||||
if self.matching_algorithm == self.MATCH_ALL:
|
||||
for word in self.match.split(" "):
|
||||
for word in self._split_match():
|
||||
search_result = re.search(
|
||||
r"\b{}\b".format(word), text, **search_kwargs)
|
||||
if not search_result:
|
||||
@@ -91,7 +104,7 @@ class MatchingModel(models.Model):
|
||||
return True
|
||||
|
||||
if self.matching_algorithm == self.MATCH_ANY:
|
||||
for word in self.match.split(" "):
|
||||
for word in self._split_match():
|
||||
if re.search(r"\b{}\b".format(word), text, **search_kwargs):
|
||||
return True
|
||||
return False
|
||||
@@ -104,14 +117,38 @@ class MatchingModel(models.Model):
|
||||
return bool(re.search(
|
||||
re.compile(self.match, **search_kwargs), text))
|
||||
|
||||
if self.matching_algorithm == self.MATCH_FUZZY:
|
||||
match = re.sub(r'[^\w\s]', '', self.match)
|
||||
text = re.sub(r'[^\w\s]', '', text)
|
||||
if self.is_insensitive:
|
||||
match = match.lower()
|
||||
text = text.lower()
|
||||
|
||||
return True if fuzz.partial_ratio(match, text) >= 90 else False
|
||||
|
||||
raise NotImplementedError("Unsupported matching algorithm")
|
||||
|
||||
def _split_match(self):
|
||||
"""
|
||||
Splits the match to individual keywords, getting rid of unnecessary
|
||||
spaces and grouping quoted words together.
|
||||
|
||||
Example:
|
||||
' some random words "with quotes " and spaces'
|
||||
==>
|
||||
["some", "random", "words", "with+quotes", "and", "spaces"]
|
||||
"""
|
||||
findterms = re.compile(r'"([^"]+)"|(\S+)').findall
|
||||
normspace = re.compile(r"\s+").sub
|
||||
return [
|
||||
normspace(" ", (t[0] or t[1]).strip()).replace(" ", r"\s+")
|
||||
for t in findterms(self.match)
|
||||
]
|
||||
|
||||
def save(self, *args, **kwargs):
|
||||
|
||||
self.match = self.match.lower()
|
||||
|
||||
if not self.slug:
|
||||
self.slug = slugify(self.name)
|
||||
self.slug = slugify(self.name)
|
||||
|
||||
models.Model.save(self, *args, **kwargs)
|
||||
|
||||
@@ -122,7 +159,7 @@ class Correspondent(MatchingModel):
|
||||
# better safe than sorry.
|
||||
SAFE_REGEX = re.compile(r"^[\w\- ,.']+$")
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
ordering = ("name",)
|
||||
|
||||
|
||||
@@ -154,17 +191,42 @@ class Document(models.Model):
|
||||
TYPE_JPG = "jpg"
|
||||
TYPE_GIF = "gif"
|
||||
TYPE_TIF = "tiff"
|
||||
TYPES = (TYPE_PDF, TYPE_PNG, TYPE_JPG, TYPE_GIF, TYPE_TIF,)
|
||||
TYPE_TXT = "txt"
|
||||
TYPE_CSV = "csv"
|
||||
TYPE_MD = "md"
|
||||
TYPES = (TYPE_PDF, TYPE_PNG, TYPE_JPG, TYPE_GIF, TYPE_TIF,
|
||||
TYPE_TXT, TYPE_CSV, TYPE_MD)
|
||||
|
||||
STORAGE_TYPE_UNENCRYPTED = "unencrypted"
|
||||
STORAGE_TYPE_GPG = "gpg"
|
||||
STORAGE_TYPES = (
|
||||
(STORAGE_TYPE_UNENCRYPTED, "Unencrypted"),
|
||||
(STORAGE_TYPE_GPG, "Encrypted with GNU Privacy Guard")
|
||||
)
|
||||
|
||||
correspondent = models.ForeignKey(
|
||||
Correspondent, blank=True, null=True, related_name="documents")
|
||||
Correspondent,
|
||||
blank=True,
|
||||
null=True,
|
||||
related_name="documents",
|
||||
on_delete=models.SET_NULL
|
||||
)
|
||||
|
||||
title = models.CharField(max_length=128, blank=True, db_index=True)
|
||||
content = models.TextField(db_index=True)
|
||||
|
||||
content = models.TextField(
|
||||
db_index=True,
|
||||
blank=True,
|
||||
help_text="The raw, text-only data of the document. This field is "
|
||||
"primarily used for searching."
|
||||
)
|
||||
|
||||
file_type = models.CharField(
|
||||
max_length=4,
|
||||
editable=False,
|
||||
choices=tuple([(t, t.upper()) for t in TYPES])
|
||||
)
|
||||
|
||||
tags = models.ManyToManyField(
|
||||
Tag, related_name="documents", blank=True)
|
||||
|
||||
@@ -182,7 +244,17 @@ class Document(models.Model):
|
||||
modified = models.DateTimeField(
|
||||
auto_now=True, editable=False, db_index=True)
|
||||
|
||||
class Meta(object):
|
||||
storage_type = models.CharField(
|
||||
max_length=11,
|
||||
choices=STORAGE_TYPES,
|
||||
default=STORAGE_TYPE_UNENCRYPTED,
|
||||
editable=False
|
||||
)
|
||||
|
||||
added = models.DateTimeField(
|
||||
default=timezone.now, editable=False, db_index=True)
|
||||
|
||||
class Meta:
|
||||
ordering = ("correspondent", "title")
|
||||
|
||||
def __str__(self):
|
||||
@@ -196,11 +268,16 @@ class Document(models.Model):
|
||||
|
||||
@property
|
||||
def source_path(self):
|
||||
|
||||
file_name = "{:07}.{}".format(self.pk, self.file_type)
|
||||
if self.storage_type == self.STORAGE_TYPE_GPG:
|
||||
file_name += ".gpg"
|
||||
|
||||
return os.path.join(
|
||||
settings.MEDIA_ROOT,
|
||||
"documents",
|
||||
"originals",
|
||||
"{:07}.{}.gpg".format(self.pk, self.file_type)
|
||||
file_name
|
||||
)
|
||||
|
||||
@property
|
||||
@@ -217,11 +294,16 @@ class Document(models.Model):
|
||||
|
||||
@property
|
||||
def thumbnail_path(self):
|
||||
|
||||
file_name = "{:07}.png".format(self.pk)
|
||||
if self.storage_type == self.STORAGE_TYPE_GPG:
|
||||
file_name += ".gpg"
|
||||
|
||||
return os.path.join(
|
||||
settings.MEDIA_ROOT,
|
||||
"documents",
|
||||
"thumbnails",
|
||||
"{:07}.png.gpg".format(self.pk)
|
||||
file_name
|
||||
)
|
||||
|
||||
@property
|
||||
@@ -251,7 +333,7 @@ class Log(models.Model):
|
||||
|
||||
objects = LogManager()
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
ordering = ("-modified",)
|
||||
|
||||
def __str__(self):
|
||||
@@ -271,7 +353,7 @@ class Log(models.Model):
|
||||
models.Model.save(self, *args, **kwargs)
|
||||
|
||||
|
||||
class FileInfo(object):
|
||||
class FileInfo:
|
||||
|
||||
# This epic regex *almost* worked for our needs, so I'm keeping it here for
|
||||
# posterity, in the hopes that we might find a way to make it work one day.
|
||||
@@ -286,51 +368,52 @@ class FileInfo(object):
|
||||
)
|
||||
)
|
||||
|
||||
formats = "pdf|jpe?g|png|gif|tiff?|te?xt|md|csv"
|
||||
REGEXES = OrderedDict([
|
||||
("created-correspondent-title-tags", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*) - "
|
||||
r"(?P<tags>[a-z0-9\-,]*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("created-title-tags", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<title>.*) - "
|
||||
r"(?P<tags>[a-z0-9\-,]*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("created-correspondent-title", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("created-title", re.compile(
|
||||
r"^(?P<created>\d\d\d\d\d\d\d\d(\d\d\d\d\d\d)?Z) - "
|
||||
r"(?P<title>.*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("correspondent-title-tags", re.compile(
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*) - "
|
||||
r"(?P<tags>[a-z0-9\-,]*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("correspondent-title", re.compile(
|
||||
r"(?P<correspondent>.*) - "
|
||||
r"(?P<title>.*)?"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
)),
|
||||
("title", re.compile(
|
||||
r"(?P<title>.*)"
|
||||
r"\.(?P<extension>pdf|jpe?g|png|gif|tiff)$",
|
||||
r"\.(?P<extension>{})$".format(formats),
|
||||
flags=re.IGNORECASE
|
||||
))
|
||||
])
|
||||
@@ -346,7 +429,10 @@ class FileInfo(object):
|
||||
|
||||
@classmethod
|
||||
def _get_created(cls, created):
|
||||
return dateutil.parser.parse("{:0<14}Z".format(created[:-1]))
|
||||
try:
|
||||
return dateutil.parser.parse("{:0<14}Z".format(created[:-1]))
|
||||
except ValueError:
|
||||
return None
|
||||
|
||||
@classmethod
|
||||
def _get_correspondent(cls, name):
|
||||
@@ -364,8 +450,10 @@ class FileInfo(object):
|
||||
def _get_tags(cls, tags):
|
||||
r = []
|
||||
for t in tags.split(","):
|
||||
r.append(
|
||||
Tag.objects.get_or_create(slug=t, defaults={"name": t})[0])
|
||||
r.append(Tag.objects.get_or_create(
|
||||
slug=slugify(t),
|
||||
defaults={"name": t}
|
||||
)[0])
|
||||
return tuple(r)
|
||||
|
||||
@classmethod
|
||||
@@ -373,6 +461,8 @@ class FileInfo(object):
|
||||
r = extension.lower()
|
||||
if r == "jpeg":
|
||||
return "jpg"
|
||||
if r == "tif":
|
||||
return "tiff"
|
||||
return r
|
||||
|
||||
@classmethod
|
||||
|
||||
131
src/documents/parsers.py
Normal file
131
src/documents/parsers.py
Normal file
@@ -0,0 +1,131 @@
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
import subprocess
|
||||
import tempfile
|
||||
|
||||
import dateparser
|
||||
from django.conf import settings
|
||||
from django.utils import timezone
|
||||
|
||||
# This regular expression will try to find dates in the document at
|
||||
# hand and will match the following formats:
|
||||
# - XX.YY.ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX/YY/ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX-YY-ZZZZ with XX + YY being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - XX. MONTH ZZZZ with XX being 1 or 2 and ZZZZ being 2 or 4 digits
|
||||
# - MONTH ZZZZ, with ZZZZ being 4 digits
|
||||
# - MONTH XX, ZZZZ with XX being 1 or 2 and ZZZZ being 4 digits
|
||||
DATE_REGEX = re.compile(
|
||||
r'\b([0-9]{1,2})[\.\/-]([0-9]{1,2})[\.\/-]([0-9]{4}|[0-9]{2})\b|' +
|
||||
r'\b([0-9]{1,2}[\. ]+[^ ]{3,9} ([0-9]{4}|[0-9]{2}))\b|' +
|
||||
r'\b([^\W\d_]{3,9} [0-9]{1,2}, ([0-9]{4}))\b|' +
|
||||
r'\b([^\W\d_]{3,9} [0-9]{4})\b'
|
||||
)
|
||||
|
||||
|
||||
class ParseError(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class DocumentParser:
|
||||
"""
|
||||
Subclass this to make your own parser. Have a look at
|
||||
`paperless_tesseract.parsers` for inspiration.
|
||||
"""
|
||||
|
||||
SCRATCH = settings.SCRATCH_DIR
|
||||
DATE_ORDER = settings.DATE_ORDER
|
||||
OPTIPNG = settings.OPTIPNG_BINARY
|
||||
|
||||
def __init__(self, path):
|
||||
self.document_path = path
|
||||
self.tempdir = tempfile.mkdtemp(prefix="paperless-", dir=self.SCRATCH)
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.logging_group = None
|
||||
|
||||
def get_thumbnail(self):
|
||||
"""
|
||||
Returns the path to a file we can use as a thumbnail for this document.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def optimise_thumbnail(self, in_path):
|
||||
|
||||
out_path = os.path.join(self.tempdir, "optipng.png")
|
||||
|
||||
args = (self.OPTIPNG, "-o5", in_path, "-out", out_path)
|
||||
if not subprocess.Popen(args).wait() == 0:
|
||||
raise ParseError("Optipng failed at {}".format(args))
|
||||
|
||||
return out_path
|
||||
|
||||
def get_optimised_thumbnail(self):
|
||||
return self.optimise_thumbnail(self.get_thumbnail())
|
||||
|
||||
def get_text(self):
|
||||
"""
|
||||
Returns the text from the document and only the text.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def get_date(self):
|
||||
"""
|
||||
Returns the date of the document.
|
||||
"""
|
||||
|
||||
date = None
|
||||
date_string = None
|
||||
|
||||
try:
|
||||
text = self.get_text()
|
||||
except ParseError:
|
||||
return None
|
||||
|
||||
next_year = timezone.now().year + 5 # Arbitrary 5 year future limit
|
||||
|
||||
# Iterate through all regex matches and try to parse the date
|
||||
for m in re.finditer(DATE_REGEX, text):
|
||||
|
||||
date_string = m.group(0)
|
||||
|
||||
try:
|
||||
date = dateparser.parse(
|
||||
date_string,
|
||||
settings={
|
||||
"DATE_ORDER": self.DATE_ORDER,
|
||||
"PREFER_DAY_OF_MONTH": "first",
|
||||
"RETURN_AS_TIMEZONE_AWARE": True
|
||||
}
|
||||
)
|
||||
except TypeError:
|
||||
# Skip all matches that do not parse to a proper date
|
||||
continue
|
||||
|
||||
if date is not None and next_year > date.year > 1900:
|
||||
break
|
||||
else:
|
||||
date = None
|
||||
|
||||
if date is not None:
|
||||
self.log(
|
||||
"info",
|
||||
"Detected document date {} based on string {}".format(
|
||||
date.isoformat(),
|
||||
date_string
|
||||
)
|
||||
)
|
||||
else:
|
||||
self.log("info", "Unable to detect date for document")
|
||||
|
||||
return date
|
||||
|
||||
def log(self, level, message):
|
||||
getattr(self.logger, level)(message, extra={
|
||||
"group": self.logging_group
|
||||
})
|
||||
|
||||
def cleanup(self):
|
||||
self.log("debug", "Deleting directory {}".format(self.tempdir))
|
||||
shutil.rmtree(self.tempdir)
|
||||
@@ -5,27 +5,36 @@ from .models import Correspondent, Tag, Document, Log
|
||||
|
||||
class CorrespondentSerializer(serializers.HyperlinkedModelSerializer):
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Correspondent
|
||||
fields = ("id", "slug", "name")
|
||||
|
||||
|
||||
class TagSerializer(serializers.HyperlinkedModelSerializer):
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Tag
|
||||
fields = (
|
||||
"id", "slug", "name", "colour", "match", "matching_algorithm")
|
||||
|
||||
|
||||
class CorrespondentField(serializers.HyperlinkedRelatedField):
|
||||
def get_queryset(self):
|
||||
return Correspondent.objects.all()
|
||||
|
||||
|
||||
class TagsField(serializers.HyperlinkedRelatedField):
|
||||
def get_queryset(self):
|
||||
return Tag.objects.all()
|
||||
|
||||
|
||||
class DocumentSerializer(serializers.ModelSerializer):
|
||||
|
||||
correspondent = serializers.HyperlinkedRelatedField(
|
||||
read_only=True, view_name="drf:correspondent-detail", allow_null=True)
|
||||
tags = serializers.HyperlinkedRelatedField(
|
||||
read_only=True, view_name="drf:tag-detail", many=True)
|
||||
correspondent = CorrespondentField(
|
||||
view_name="drf:correspondent-detail", allow_null=True)
|
||||
tags = TagsField(view_name="drf:tag-detail", many=True)
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Document
|
||||
fields = (
|
||||
"id",
|
||||
@@ -48,7 +57,7 @@ class LogSerializer(serializers.ModelSerializer):
|
||||
time = serializers.DateTimeField()
|
||||
messages = serializers.CharField()
|
||||
|
||||
class Meta(object):
|
||||
class Meta:
|
||||
model = Log
|
||||
fields = (
|
||||
"time",
|
||||
|
||||
4
src/documents/settings.py
Normal file
4
src/documents/settings.py
Normal file
@@ -0,0 +1,4 @@
|
||||
# Defines the names of file/thumbnail for the manifest
|
||||
# for exporting/importing commands
|
||||
EXPORTER_FILE_NAME = "__exported_file_name__"
|
||||
EXPORTER_THUMBNAIL_NAME = "__exported_thumbnail_name__"
|
||||
@@ -2,3 +2,4 @@ from django.dispatch import Signal
|
||||
|
||||
document_consumption_started = Signal(providing_args=["filename"])
|
||||
document_consumption_finished = Signal(providing_args=["document"])
|
||||
document_consumer_declaration = Signal(providing_args=[])
|
||||
|
||||
@@ -1,9 +1,12 @@
|
||||
import logging
|
||||
import os
|
||||
|
||||
from subprocess import Popen
|
||||
|
||||
from django.conf import settings
|
||||
from django.contrib.admin.models import ADDITION, LogEntry
|
||||
from django.contrib.auth.models import User
|
||||
from django.contrib.contenttypes.models import ContentType
|
||||
from django.utils import timezone
|
||||
|
||||
from ..models import Correspondent, Document, Tag
|
||||
|
||||
@@ -94,3 +97,18 @@ def cleanup_document_deletion(sender, instance, using, **kwargs):
|
||||
os.unlink(f)
|
||||
except FileNotFoundError:
|
||||
pass # The file's already gone, so we're cool with it.
|
||||
|
||||
|
||||
def set_log_entry(sender, document=None, logging_group=None, **kwargs):
|
||||
|
||||
ct = ContentType.objects.get(model="document")
|
||||
user = User.objects.get(username="consumer")
|
||||
|
||||
LogEntry.objects.create(
|
||||
action_flag=ADDITION,
|
||||
action_time=timezone.now(),
|
||||
content_type=ct,
|
||||
object_id=document.id,
|
||||
user=user,
|
||||
object_repr=document.__str__(),
|
||||
)
|
||||
|
||||
@@ -10,3 +10,14 @@ td a.tag {
|
||||
margin: 1px;
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
#result_list th.column-note {
|
||||
text-align: right;
|
||||
}
|
||||
#result_list td.field-note {
|
||||
text-align: right;
|
||||
}
|
||||
#result_list td textarea {
|
||||
width: 90%;
|
||||
height: 5em;
|
||||
}
|
||||
40
src/documents/templates/admin/base_site.html
Normal file
40
src/documents/templates/admin/base_site.html
Normal file
@@ -0,0 +1,40 @@
|
||||
{% extends 'admin/base_site.html' %}
|
||||
|
||||
{# NOTE: This should probably be extending base.html. See CSS comment below details. #}
|
||||
|
||||
|
||||
{% load custom_css from customisation %}
|
||||
{% load custom_js from customisation %}
|
||||
|
||||
|
||||
{% block blockbots %}
|
||||
|
||||
{% comment %}
|
||||
This really should be extending `extrastyle`, but the the
|
||||
django-flat-responsive package decided that it wanted to put its CSS in
|
||||
this block, so to make sure that overrides are in fact overriding
|
||||
everything else, we have to do the Wrong Thing here.
|
||||
|
||||
Once we switch to Django 2.x and drop django-flat-responsive, we should
|
||||
switch this to `extrastyle` where it should be.
|
||||
{% endcomment %}
|
||||
|
||||
{{ block.super }}
|
||||
|
||||
{% custom_css %}
|
||||
|
||||
{% endblock blockbots %}
|
||||
|
||||
|
||||
{% block footer %}
|
||||
|
||||
{% comment %}
|
||||
The Django admin doesn't have a block for Javascript you'd want placed in
|
||||
the footer, so we have to use this one instead.
|
||||
{% endcomment %}
|
||||
|
||||
{{ block.super }}
|
||||
|
||||
{% custom_js %}
|
||||
|
||||
{% endblock footer %}
|
||||
@@ -1,6 +0,0 @@
|
||||
{% load hacks %}
|
||||
|
||||
{# See documents.templatetags.hacks.change_list_results for an explanation #}
|
||||
|
||||
{% change_list_results %}
|
||||
|
||||
@@ -0,0 +1,29 @@
|
||||
{% extends 'admin/change_form.html' %}
|
||||
|
||||
{% block content %}
|
||||
|
||||
{{ block.super }}
|
||||
|
||||
{% if next_object %}
|
||||
<script type="text/javascript">//<![CDATA[
|
||||
(function($){
|
||||
$('<input type="submit" value="Save and edit next" name="_saveandeditnext" />')
|
||||
.prependTo('div.submit-row');
|
||||
$('<input type="hidden" value="{{next_object}}" name="_next_object" />')
|
||||
.prependTo('div.submit-row');
|
||||
})(django.jQuery);
|
||||
//]]></script>
|
||||
{% endif %}
|
||||
|
||||
{% endblock content %}
|
||||
|
||||
{% block footer %}
|
||||
|
||||
{{ block.super }}
|
||||
|
||||
{# Hack to force Django to make the created date a date input rather than `text` (the default) #}
|
||||
<script>
|
||||
django.jQuery(".field-created input").first().attr("type", "date")
|
||||
</script>
|
||||
|
||||
{% endblock footer %}
|
||||
@@ -0,0 +1,12 @@
|
||||
{% extends 'admin/change_list.html' %}
|
||||
|
||||
|
||||
{% load admin_actions from admin_list%}
|
||||
{% load result_list from hacks %}
|
||||
|
||||
|
||||
{% block result_list %}
|
||||
{% if action_form and actions_on_top and cl.show_admin_actions %}{% admin_actions %}{% endif %}
|
||||
{% result_list cl %}
|
||||
{% if action_form and actions_on_bottom and cl.show_admin_actions %}{% admin_actions %}{% endif %}
|
||||
{% endblock %}
|
||||
@@ -29,18 +29,32 @@
|
||||
.result .header {
|
||||
padding: 5px;
|
||||
background-color: #79AEC8;
|
||||
height: 6em;
|
||||
position: relative;
|
||||
}
|
||||
.result .header .checkbox {
|
||||
margin-right: 5px;
|
||||
}
|
||||
.result .header .checkbox{
|
||||
width: 5%;
|
||||
float: left;
|
||||
position: absolute;
|
||||
z-index: 2;
|
||||
}
|
||||
.result .header .info {
|
||||
width: 90%;
|
||||
float: left;
|
||||
margin-left: 10%;
|
||||
position: relative;
|
||||
}
|
||||
.headerLink {
|
||||
cursor: pointer;
|
||||
opacity: 0;
|
||||
z-index: 1;
|
||||
position: absolute;
|
||||
top: 0;
|
||||
left: 0;
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
}
|
||||
.header > a {
|
||||
z-index: 2;
|
||||
margin-left: 10%;
|
||||
position: relative;
|
||||
}
|
||||
.result .header a,
|
||||
.result a.tag {
|
||||
@@ -134,23 +148,36 @@
|
||||
{# 0: Checkbox #}
|
||||
{# 1: Title #}
|
||||
{# 2: Date #}
|
||||
{# 3: Image #}
|
||||
{# 4: Correspondent #}
|
||||
{# 5: Tags #}
|
||||
{# 3: Added #}
|
||||
{# 4: Image #}
|
||||
{# 5: Correspondent #}
|
||||
{# 6: Tags #}
|
||||
{# 7: Document edit url #}
|
||||
<div class="box">
|
||||
<div class="result">
|
||||
<div class="header">
|
||||
{% comment %}
|
||||
The purpose of 'headerLink' is to make the whole header
|
||||
background clickable.
|
||||
We use an onclick handler here instead of a native link ('<a>')
|
||||
to allow selecting (and copying) the overlying doc title text
|
||||
with the mouse cursor.
|
||||
If the title link were layered upon another link ('<a>'), title text
|
||||
selection would not be possible with mouse click + drag. Instead,
|
||||
the underlying link would be dragged.
|
||||
{% endcomment %}
|
||||
<div class="headerLink" onclick="location.href='{{ result.7 }}';"></div>
|
||||
<div class="checkbox">{{ result.0 }}</div>
|
||||
<div class="info">
|
||||
{{ result.4 }}<br />
|
||||
{{ result.1 }}
|
||||
{{ result.5 }}
|
||||
</div>
|
||||
{{ result.1 }}
|
||||
<div style="clear: both;"></div>
|
||||
</div>
|
||||
<div class="tags">{{ result.5 }}</div>
|
||||
<div class="tags">{{ result.6 }}</div>
|
||||
<div class="date">{{ result.2 }}</div>
|
||||
<div style="clear: both;"></div>
|
||||
<div class="image">{{ result.3 }}</div>
|
||||
<div class="image">{{ result.4 }}</div>
|
||||
</div>
|
||||
</div>
|
||||
{% endfor %}
|
||||
@@ -158,7 +185,7 @@
|
||||
|
||||
|
||||
<script>
|
||||
// We nee to re-build the select-all functionality as the old logic pointed
|
||||
// We need to re-build the select-all functionality as the old logic pointed
|
||||
// to a table and we're using divs now.
|
||||
django.jQuery("#action-toggle").on("change", function(){
|
||||
django.jQuery(".grid .box .result .checkbox input")
|
||||
|
||||
@@ -0,0 +1,50 @@
|
||||
{% extends "admin/base_site.html" %}
|
||||
|
||||
|
||||
{% load i18n l10n admin_urls static %}
|
||||
{% load staticfiles %}
|
||||
|
||||
|
||||
{% block extrahead %}
|
||||
{{ block.super }}
|
||||
{{ media }}
|
||||
<script type="text/javascript" src="{% static 'admin/js/cancel.js' %}"></script>
|
||||
{% endblock %}
|
||||
|
||||
|
||||
{% block bodyclass %}{{ block.super }} app-{{ opts.app_label }} model-{{ opts.model_name }} delete-confirmation delete-selected-confirmation{% endblock %}
|
||||
|
||||
|
||||
{% block breadcrumbs %}
|
||||
<div class="breadcrumbs">
|
||||
<a href="{% url 'admin:index' %}">{% trans 'Home' %}</a>
|
||||
› <a href="{% url 'admin:app_list' app_label=opts.app_label %}">{{ opts.app_config.verbose_name }}</a>
|
||||
› <a href="{% url opts|admin_urlname:'changelist' %}">{{ opts.verbose_name_plural|capfirst }}</a>
|
||||
› {{ title }}
|
||||
</div>
|
||||
{% endblock %}
|
||||
|
||||
{% block content %}
|
||||
<p>Please select the {{itemname}}.</p>
|
||||
<form method="post">{% csrf_token %}
|
||||
<div>
|
||||
{% for obj in queryset %}
|
||||
<input type="hidden" name="{{ action_checkbox_name }}" value="{{ obj.pk|unlocalize }}"/>
|
||||
{% endfor %}
|
||||
<p>
|
||||
<select name="obj_id">
|
||||
{% for obj in objects %}
|
||||
<option value="{{ obj.id }}">{{ obj.name }}</option>
|
||||
{% endfor %}
|
||||
</select>
|
||||
</p>
|
||||
|
||||
<input type="hidden" name="action" value="{{ action }}"/>
|
||||
<input type="hidden" name="post" value="yes" />
|
||||
<p>
|
||||
<input type="submit" value="{% trans 'Confirm' %}" />
|
||||
<a href="#" class="button cancel-link">{% trans "Go back" %}</a>
|
||||
</p>
|
||||
</div>
|
||||
</form>
|
||||
{% endblock %}
|
||||
57
src/documents/templates/admin/index.html
Normal file
57
src/documents/templates/admin/index.html
Normal file
@@ -0,0 +1,57 @@
|
||||
{% extends "admin/index.html" %}
|
||||
|
||||
|
||||
{% load i18n static %}
|
||||
|
||||
|
||||
{# This block adds a search form on the admin start page and on the module start page so that #}
|
||||
{# the user can quickly search for documents #}
|
||||
{% block pretitle %}
|
||||
<div>
|
||||
<h3>{% trans 'Search documents' %}</h3>
|
||||
|
||||
<div id="toolbar"><form id="changelist-search" method="get" action="{% url 'admin:documents_document_changelist' %}">
|
||||
<div><!-- DIV needed for valid HTML -->
|
||||
<label for="searchbar"><img src="{% static "admin/img/search.svg" %}" alt="Search"></label>
|
||||
<input type="text" size="40" name="q" value="" id="searchbar" autofocus="">
|
||||
<input type="submit" value="{% trans 'Search' %}">
|
||||
</div>
|
||||
</form>
|
||||
</div>
|
||||
</div>
|
||||
{% endblock %}
|
||||
|
||||
|
||||
{# This whole block is here just to override the `get_admin_log` line so #}
|
||||
{# that the log entries aren't limited to the current user #}
|
||||
{% block sidebar %}
|
||||
<div id="content-related">
|
||||
<div class="module" id="recent-actions-module">
|
||||
<h2>{% trans 'Recent actions' %}</h2>
|
||||
<h3>{% trans 'My actions' %}</h3>
|
||||
{% load log %}
|
||||
{% get_admin_log 10 as admin_log %}
|
||||
{% if not admin_log %}
|
||||
<p>{% trans 'None available' %}</p>
|
||||
{% else %}
|
||||
<ul class="actionlist">
|
||||
{% for entry in admin_log %}
|
||||
<li class="{% if entry.is_addition %}addlink{% endif %}{% if entry.is_change %}changelink{% endif %}{% if entry.is_deletion %}deletelink{% endif %}">
|
||||
{% if entry.is_deletion or not entry.get_admin_url %}
|
||||
{{ entry.object_repr }}
|
||||
{% else %}
|
||||
<a href="{{ entry.get_admin_url }}">{{ entry.object_repr }}</a>
|
||||
{% endif %}
|
||||
<br/>
|
||||
{% if entry.content_type %}
|
||||
<span class="mini quiet">{% filter capfirst %}{{ entry.content_type }}{% endfilter %}</span>
|
||||
{% else %}
|
||||
<span class="mini quiet">{% trans 'Unknown content' %}</span>
|
||||
{% endif %}
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
{% endif %}
|
||||
</div>
|
||||
</div>
|
||||
{% endblock %}
|
||||
@@ -6,5 +6,6 @@
|
||||
<meta charset="utf-8">
|
||||
</head>
|
||||
<body>
|
||||
{# One day someone (maybe even myself) is going to write a proper web front-end for Paperless, and this is where it'll start. #}
|
||||
</body>
|
||||
</html>
|
||||
|
||||
37
src/documents/templatetags/customisation.py
Normal file
37
src/documents/templatetags/customisation.py
Normal file
@@ -0,0 +1,37 @@
|
||||
import os
|
||||
|
||||
from django import template
|
||||
from django.conf import settings
|
||||
from django.utils.safestring import mark_safe
|
||||
|
||||
register = template.Library()
|
||||
|
||||
|
||||
@register.simple_tag()
|
||||
def custom_css():
|
||||
theme_path = os.path.join(
|
||||
settings.MEDIA_ROOT,
|
||||
"overrides.css"
|
||||
)
|
||||
if os.path.exists(theme_path):
|
||||
return mark_safe(
|
||||
'<link rel="stylesheet" type="text/css" href="{}" />'.format(
|
||||
os.path.join(settings.MEDIA_URL, "overrides.css")
|
||||
)
|
||||
)
|
||||
return ""
|
||||
|
||||
|
||||
@register.simple_tag()
|
||||
def custom_js():
|
||||
theme_path = os.path.join(
|
||||
settings.MEDIA_ROOT,
|
||||
"overrides.js"
|
||||
)
|
||||
if os.path.exists(theme_path):
|
||||
return mark_safe(
|
||||
'<script src="{}"></script>'.format(
|
||||
os.path.join(settings.MEDIA_URL, "overrides.js")
|
||||
)
|
||||
)
|
||||
return ""
|
||||
@@ -1,41 +1,43 @@
|
||||
import os
|
||||
import re
|
||||
|
||||
from django.contrib import admin
|
||||
from django.contrib.admin.templatetags.admin_list import (
|
||||
result_headers,
|
||||
result_hidden_fields,
|
||||
results
|
||||
)
|
||||
from django.template import Library
|
||||
from django.template.loader import get_template
|
||||
|
||||
from ..models import Document
|
||||
|
||||
EXTRACT_URL = re.compile(r'href="(.*?)"')
|
||||
|
||||
register = Library()
|
||||
|
||||
|
||||
@register.simple_tag(takes_context=True)
|
||||
def change_list_results(context):
|
||||
@register.inclusion_tag("admin/documents/document/change_list_results.html")
|
||||
def result_list(cl):
|
||||
"""
|
||||
Django has a lot of places where you can override defaults, but
|
||||
unfortunately, `change_list_results.html` is not one of them. In fact,
|
||||
it's a downright pain in the ass to override this file on a per-model basis
|
||||
and this is the cleanest way I could come up with.
|
||||
|
||||
Basically all we've done here is defined `change_list_results.html` in an
|
||||
`admin` directory which globally overrides that file for *every* model.
|
||||
That template however simply loads this templatetag which determines
|
||||
whether we're currently looking at a `Document` listing or something else
|
||||
and loads the appropriate file in each case.
|
||||
|
||||
Better work arounds for this are welcome as I hate this myself, but at the
|
||||
moment, it's all I could come up with.
|
||||
Copy/pasted from django.contrib.admin.templatetags.admin_list just so I can
|
||||
modify the value passed to `.inclusion_tag()` in the decorator here. There
|
||||
must be a cleaner way... right?
|
||||
"""
|
||||
headers = list(result_headers(cl))
|
||||
num_sorted_fields = 0
|
||||
for h in headers:
|
||||
if h['sortable'] and h['sorted']:
|
||||
num_sorted_fields += 1
|
||||
return {'cl': cl,
|
||||
'result_hidden_fields': list(result_hidden_fields(cl)),
|
||||
'result_headers': headers,
|
||||
'num_sorted_fields': num_sorted_fields,
|
||||
'results': map(add_doc_edit_url, results(cl))}
|
||||
|
||||
path = os.path.join(
|
||||
os.path.dirname(admin.__file__),
|
||||
"templates",
|
||||
"admin",
|
||||
"change_list_results.html"
|
||||
)
|
||||
|
||||
if context["cl"].model == Document:
|
||||
path = "admin/documents/document/change_list_results.html"
|
||||
|
||||
return get_template(path).render(context)
|
||||
def add_doc_edit_url(result):
|
||||
"""
|
||||
Make the document edit URL accessible to the view as a separate item
|
||||
"""
|
||||
title = result[1]
|
||||
match = re.search(EXTRACT_URL, title)
|
||||
edit_doc_url = match.group(1)
|
||||
result.append(edit_doc_url)
|
||||
return result
|
||||
|
||||
17
src/documents/tests/factories.py
Normal file
17
src/documents/tests/factories.py
Normal file
@@ -0,0 +1,17 @@
|
||||
import factory
|
||||
|
||||
from ..models import Document, Correspondent
|
||||
|
||||
|
||||
class CorrespondentFactory(factory.DjangoModelFactory):
|
||||
|
||||
class Meta:
|
||||
model = Correspondent
|
||||
|
||||
name = factory.Faker("name")
|
||||
|
||||
|
||||
class DocumentFactory(factory.DjangoModelFactory):
|
||||
|
||||
class Meta:
|
||||
model = Document
|
||||
25
src/documents/tests/test_checks.py
Normal file
25
src/documents/tests/test_checks.py
Normal file
@@ -0,0 +1,25 @@
|
||||
import unittest
|
||||
|
||||
from django.test import TestCase
|
||||
|
||||
from ..checks import changed_password_check
|
||||
from ..models import Document
|
||||
from .factories import DocumentFactory
|
||||
|
||||
|
||||
class ChecksTestCase(TestCase):
|
||||
|
||||
def test_changed_password_check_empty_db(self):
|
||||
self.assertEqual(changed_password_check(None), [])
|
||||
|
||||
def test_changed_password_check_no_encryption(self):
|
||||
DocumentFactory.create(storage_type=Document.STORAGE_TYPE_UNENCRYPTED)
|
||||
self.assertEqual(changed_password_check(None), [])
|
||||
|
||||
@unittest.skip("I don't know how to test this")
|
||||
def test_changed_password_check_gpg_encryption_with_good_password(self):
|
||||
pass
|
||||
|
||||
@unittest.skip("I don't know how to test this")
|
||||
def test_changed_password_check_fail(self):
|
||||
pass
|
||||
@@ -1,22 +1,71 @@
|
||||
import os
|
||||
from unittest import mock, skipIf
|
||||
|
||||
import pyocr
|
||||
from django.test import TestCase
|
||||
from pyocr.libtesseract.tesseract_raw import \
|
||||
TesseractError as OtherTesseractError
|
||||
from unittest import mock
|
||||
from tempfile import TemporaryDirectory
|
||||
|
||||
from ..models import FileInfo
|
||||
from ..consumer import image_to_string, strip_excess_whitespace
|
||||
from ..consumer import Consumer
|
||||
from ..models import FileInfo, Tag
|
||||
|
||||
|
||||
class TestConsumer(TestCase):
|
||||
|
||||
class DummyParser(object):
|
||||
pass
|
||||
|
||||
def test__get_parser_class_1_parser(self):
|
||||
self.assertEqual(
|
||||
self._get_consumer()._get_parser_class("doc.pdf"),
|
||||
self.DummyParser
|
||||
)
|
||||
|
||||
@mock.patch("documents.consumer.os.makedirs")
|
||||
@mock.patch("documents.consumer.os.path.exists", return_value=True)
|
||||
@mock.patch("documents.consumer.document_consumer_declaration.send")
|
||||
def test__get_parser_class_n_parsers(self, m, *args):
|
||||
|
||||
class DummyParser1(object):
|
||||
pass
|
||||
|
||||
class DummyParser2(object):
|
||||
pass
|
||||
|
||||
m.return_value = (
|
||||
(None, lambda _: {"weight": 0, "parser": DummyParser1}),
|
||||
(None, lambda _: {"weight": 1, "parser": DummyParser2}),
|
||||
)
|
||||
with TemporaryDirectory() as tmpdir:
|
||||
self.assertEqual(
|
||||
Consumer(consume=tmpdir)._get_parser_class("doc.pdf"),
|
||||
DummyParser2
|
||||
)
|
||||
|
||||
@mock.patch("documents.consumer.os.makedirs")
|
||||
@mock.patch("documents.consumer.os.path.exists", return_value=True)
|
||||
@mock.patch("documents.consumer.document_consumer_declaration.send")
|
||||
def test__get_parser_class_0_parsers(self, m, *args):
|
||||
m.return_value = ((None, lambda _: None),)
|
||||
with TemporaryDirectory() as tmpdir:
|
||||
self.assertIsNone(
|
||||
Consumer(consume=tmpdir)._get_parser_class("doc.pdf")
|
||||
)
|
||||
|
||||
@mock.patch("documents.consumer.os.makedirs")
|
||||
@mock.patch("documents.consumer.os.path.exists", return_value=True)
|
||||
@mock.patch("documents.consumer.document_consumer_declaration.send")
|
||||
def _get_consumer(self, m, *args):
|
||||
m.return_value = (
|
||||
(None, lambda _: {"weight": 0, "parser": self.DummyParser}),
|
||||
)
|
||||
with TemporaryDirectory() as tmpdir:
|
||||
return Consumer(consume=tmpdir)
|
||||
|
||||
|
||||
class TestAttributes(TestCase):
|
||||
|
||||
TAGS = ("tag1", "tag2", "tag3")
|
||||
EXTENSIONS = (
|
||||
"pdf", "png", "jpg", "jpeg", "gif",
|
||||
"PDF", "PNG", "JPG", "JPEG", "GIF",
|
||||
"PdF", "PnG", "JpG", "JPeG", "GiF",
|
||||
"pdf", "png", "jpg", "jpeg", "gif", "tiff", "tif",
|
||||
"PDF", "PNG", "JPG", "JPEG", "GIF", "TIFF", "TIF",
|
||||
"PdF", "PnG", "JpG", "JPeG", "GiF", "TiFf", "TiF",
|
||||
)
|
||||
|
||||
def _test_guess_attributes_from_name(self, path, sender, title, tags):
|
||||
@@ -36,6 +85,8 @@ class TestAttributes(TestCase):
|
||||
self.assertEqual(tuple([t.slug for t in file_info.tags]), tags, f)
|
||||
if extension.lower() == "jpeg":
|
||||
self.assertEqual(file_info.extension, "jpg", f)
|
||||
elif extension.lower() == "tif":
|
||||
self.assertEqual(file_info.extension, "tiff", f)
|
||||
else:
|
||||
self.assertEqual(file_info.extension, extension.lower(), f)
|
||||
|
||||
@@ -139,6 +190,20 @@ class TestAttributes(TestCase):
|
||||
()
|
||||
)
|
||||
|
||||
def test_case_insensitive_tag_creation(self):
|
||||
"""
|
||||
Tags should be detected and created as lower case.
|
||||
:return:
|
||||
"""
|
||||
|
||||
path = "Title - Correspondent - tAg1,TAG2.pdf"
|
||||
self.assertEqual(len(FileInfo.from_path(path).tags), 2)
|
||||
|
||||
path = "Title - Correspondent - tag1,tag2.pdf"
|
||||
self.assertEqual(len(FileInfo.from_path(path).tags), 2)
|
||||
|
||||
self.assertEqual(Tag.objects.all().count(), 2)
|
||||
|
||||
|
||||
class TestFieldPermutations(TestCase):
|
||||
|
||||
@@ -225,11 +290,13 @@ class TestFieldPermutations(TestCase):
|
||||
|
||||
def test_created_and_correspondent_and_title_and_tags(self):
|
||||
|
||||
template = ("/path/to/{created} - "
|
||||
"{correspondent} - "
|
||||
"{title} - "
|
||||
"{tags}"
|
||||
".{extension}")
|
||||
template = (
|
||||
"/path/to/{created} - "
|
||||
"{correspondent} - "
|
||||
"{title} - "
|
||||
"{tags}"
|
||||
".{extension}"
|
||||
)
|
||||
|
||||
for created in self.valid_dates:
|
||||
for correspondent in self.valid_correspondents:
|
||||
@@ -248,10 +315,7 @@ class TestFieldPermutations(TestCase):
|
||||
|
||||
def test_created_and_correspondent_and_title(self):
|
||||
|
||||
template = ("/path/to/{created} - "
|
||||
"{correspondent} - "
|
||||
"{title}"
|
||||
".{extension}")
|
||||
template = "/path/to/{created} - {correspondent} - {title}.{extension}"
|
||||
|
||||
for created in self.valid_dates:
|
||||
for correspondent in self.valid_correspondents:
|
||||
@@ -274,9 +338,7 @@ class TestFieldPermutations(TestCase):
|
||||
|
||||
def test_created_and_title(self):
|
||||
|
||||
template = ("/path/to/{created} - "
|
||||
"{title}"
|
||||
".{extension}")
|
||||
template = "/path/to/{created} - {title}.{extension}"
|
||||
|
||||
for created in self.valid_dates:
|
||||
for title in self.valid_titles:
|
||||
@@ -291,10 +353,7 @@ class TestFieldPermutations(TestCase):
|
||||
|
||||
def test_created_and_title_and_tags(self):
|
||||
|
||||
template = ("/path/to/{created} - "
|
||||
"{title} - "
|
||||
"{tags}"
|
||||
".{extension}")
|
||||
template = "/path/to/{created} - {title} - {tags}.{extension}"
|
||||
|
||||
for created in self.valid_dates:
|
||||
for title in self.valid_titles:
|
||||
@@ -309,70 +368,7 @@ class TestFieldPermutations(TestCase):
|
||||
self._test_guessed_attributes(
|
||||
template.format(**spec), **spec)
|
||||
|
||||
|
||||
class FakeTesseract(object):
|
||||
|
||||
@staticmethod
|
||||
def can_detect_orientation():
|
||||
return True
|
||||
|
||||
@staticmethod
|
||||
def detect_orientation(file_handle, lang):
|
||||
raise OtherTesseractError("arbitrary status", "message")
|
||||
|
||||
@staticmethod
|
||||
def image_to_string(file_handle, lang):
|
||||
return "This is test text"
|
||||
|
||||
|
||||
class FakePyOcr(object):
|
||||
|
||||
@staticmethod
|
||||
def get_available_tools():
|
||||
return [FakeTesseract]
|
||||
|
||||
|
||||
class TestOCR(TestCase):
|
||||
|
||||
text_cases = [
|
||||
("simple string", "simple string"),
|
||||
(
|
||||
"simple newline\n testing string",
|
||||
"simple newline\ntesting string"
|
||||
),
|
||||
(
|
||||
"utf-8 строка с пробелами в конце ",
|
||||
"utf-8 строка с пробелами в конце"
|
||||
)
|
||||
]
|
||||
|
||||
SAMPLE_FILES = os.path.join(os.path.dirname(__file__), "samples")
|
||||
TESSERACT_INSTALLED = bool(pyocr.get_available_tools())
|
||||
|
||||
def test_strip_excess_whitespace(self):
|
||||
for source, result in self.text_cases:
|
||||
actual_result = strip_excess_whitespace(source)
|
||||
self.assertEqual(
|
||||
result,
|
||||
actual_result,
|
||||
"strip_exceess_whitespace({}) != '{}', but '{}'".format(
|
||||
source,
|
||||
result,
|
||||
actual_result
|
||||
)
|
||||
)
|
||||
|
||||
@skipIf(not TESSERACT_INSTALLED, "Tesseract not installed. Skipping")
|
||||
@mock.patch("documents.consumer.Consumer.SCRATCH", SAMPLE_FILES)
|
||||
@mock.patch("documents.consumer.pyocr", FakePyOcr)
|
||||
def test_image_to_string_with_text_free_page(self):
|
||||
"""
|
||||
This test is sort of silly, since it's really just reproducing an odd
|
||||
exception thrown by pyocr when it encounters a page with no text.
|
||||
Actually running this test against an installation of Tesseract results
|
||||
in a segmentation fault rooted somewhere deep inside pyocr where I
|
||||
don't care to dig. Regardless, if you run the consumer normally,
|
||||
text-free pages are now handled correctly so long as we work around
|
||||
this weird exception.
|
||||
"""
|
||||
image_to_string(["no-text.png", "en"])
|
||||
def test_invalid_date_format(self):
|
||||
info = FileInfo.from_path("/path/to/06112017Z - title.pdf")
|
||||
self.assertEqual(info.title, "title")
|
||||
self.assertIsNone(info.created)
|
||||
|
||||
@@ -3,6 +3,8 @@ from django.test import TestCase
|
||||
|
||||
from ..management.commands.document_importer import Command
|
||||
|
||||
from documents.settings import EXPORTER_FILE_NAME
|
||||
|
||||
|
||||
class TestImporter(TestCase):
|
||||
|
||||
@@ -27,7 +29,7 @@ class TestImporter(TestCase):
|
||||
|
||||
cmd.manifest = [{
|
||||
"model": "documents.document",
|
||||
"__exported_file_name__": "noexist.pdf"
|
||||
EXPORTER_FILE_NAME: "noexist.pdf"
|
||||
}]
|
||||
# self.assertRaises(CommandError, cmd._check_manifest)
|
||||
with self.assertRaises(CommandError) as cm:
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
from random import randint
|
||||
|
||||
from django.test import TestCase
|
||||
from django.contrib.admin.models import LogEntry
|
||||
from django.contrib.auth.models import User
|
||||
from django.test import TestCase, override_settings
|
||||
|
||||
from ..models import Correspondent, Document, Tag
|
||||
from ..signals import document_consumption_finished
|
||||
@@ -16,9 +18,15 @@ class TestMatching(TestCase):
|
||||
matching_algorithm=getattr(klass, algorithm)
|
||||
)
|
||||
for string in true:
|
||||
self.assertTrue(instance.matches(string))
|
||||
self.assertTrue(
|
||||
instance.matches(string),
|
||||
'"%s" should match "%s" but it does not' % (text, string)
|
||||
)
|
||||
for string in false:
|
||||
self.assertFalse(instance.matches(string))
|
||||
self.assertFalse(
|
||||
instance.matches(string),
|
||||
'"%s" should not match "%s" but it does' % (text, string)
|
||||
)
|
||||
|
||||
def test_match_all(self):
|
||||
|
||||
@@ -54,6 +62,21 @@ class TestMatching(TestCase):
|
||||
)
|
||||
)
|
||||
|
||||
self._test_matching(
|
||||
'brown fox "lazy dogs"',
|
||||
"MATCH_ALL",
|
||||
(
|
||||
"the quick brown fox jumped over the lazy dogs",
|
||||
"the quick brown fox jumped over the lazy dogs",
|
||||
),
|
||||
(
|
||||
"the quick fox jumped over the lazy dogs",
|
||||
"the quick brown wolf jumped over the lazy dogs",
|
||||
"the quick brown fox jumped over the fat dogs",
|
||||
"the quick brown fox jumped over the lazy... dogs",
|
||||
)
|
||||
)
|
||||
|
||||
def test_match_any(self):
|
||||
|
||||
self._test_matching(
|
||||
@@ -89,6 +112,18 @@ class TestMatching(TestCase):
|
||||
)
|
||||
)
|
||||
|
||||
self._test_matching(
|
||||
'"brown fox" " lazy dogs "',
|
||||
"MATCH_ANY",
|
||||
(
|
||||
"the quick brown fox",
|
||||
"jumped over the lazy dogs.",
|
||||
),
|
||||
(
|
||||
"the lazy fox jumped over the brown dogs",
|
||||
)
|
||||
)
|
||||
|
||||
def test_match_literal(self):
|
||||
|
||||
self._test_matching(
|
||||
@@ -131,7 +166,7 @@ class TestMatching(TestCase):
|
||||
def test_match_regex(self):
|
||||
|
||||
self._test_matching(
|
||||
"alpha\w+gamma",
|
||||
r"alpha\w+gamma",
|
||||
"MATCH_REGEX",
|
||||
(
|
||||
"I have alpha_and_gamma in me",
|
||||
@@ -149,8 +184,25 @@ class TestMatching(TestCase):
|
||||
)
|
||||
)
|
||||
|
||||
def test_match_fuzzy(self):
|
||||
|
||||
class TestApplications(TestCase):
|
||||
self._test_matching(
|
||||
"Springfield, Miss.",
|
||||
"MATCH_FUZZY",
|
||||
(
|
||||
"1220 Main Street, Springf eld, Miss.",
|
||||
"1220 Main Street, Spring field, Miss.",
|
||||
"1220 Main Street, Springfeld, Miss.",
|
||||
"1220 Main Street Springfield Miss",
|
||||
),
|
||||
(
|
||||
"1220 Main Street, Springfield, Mich.",
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@override_settings(POST_CONSUME_SCRIPT=None)
|
||||
class TestDocumentConsumptionFinishedSignal(TestCase):
|
||||
"""
|
||||
We make use of document_consumption_finished, so we should test that it's
|
||||
doing what we expect wrt to tag & correspondent matching.
|
||||
@@ -158,6 +210,7 @@ class TestApplications(TestCase):
|
||||
|
||||
def setUp(self):
|
||||
TestCase.setUp(self)
|
||||
User.objects.create_user(username='test_consumer', password='12345')
|
||||
self.doc_contains = Document.objects.create(
|
||||
content="I contain the keyword.", file_type="pdf")
|
||||
|
||||
@@ -194,3 +247,9 @@ class TestApplications(TestCase):
|
||||
document_consumption_finished.send(
|
||||
sender=self.__class__, document=self.doc_contains)
|
||||
self.assertEqual(self.doc_contains.correspondent, None)
|
||||
|
||||
def test_logentry_created(self):
|
||||
document_consumption_finished.send(
|
||||
sender=self.__class__, document=self.doc_contains)
|
||||
|
||||
self.assertEqual(LogEntry.objects.count(), 1)
|
||||
|
||||
31
src/documents/tests/test_models.py
Normal file
31
src/documents/tests/test_models.py
Normal file
@@ -0,0 +1,31 @@
|
||||
from django.test import TestCase
|
||||
|
||||
from ..models import Document, Correspondent
|
||||
from .factories import DocumentFactory, CorrespondentFactory
|
||||
|
||||
|
||||
class CorrespondentTestCase(TestCase):
|
||||
|
||||
def test___str__(self):
|
||||
for s in ("test", "οχι", "test with fun_charÅc'\"terß"):
|
||||
correspondent = CorrespondentFactory.create(name=s)
|
||||
self.assertEqual(str(correspondent), s)
|
||||
|
||||
|
||||
class DocumentTestCase(TestCase):
|
||||
|
||||
def test_correspondent_deletion_does_not_cascade(self):
|
||||
|
||||
self.assertEqual(Correspondent.objects.all().count(), 0)
|
||||
correspondent = CorrespondentFactory.create()
|
||||
self.assertEqual(Correspondent.objects.all().count(), 1)
|
||||
|
||||
self.assertEqual(Document.objects.all().count(), 0)
|
||||
DocumentFactory.create(correspondent=correspondent)
|
||||
self.assertEqual(Document.objects.all().count(), 1)
|
||||
self.assertIsNotNone(Document.objects.all().first().correspondent)
|
||||
|
||||
correspondent.delete()
|
||||
self.assertEqual(Correspondent.objects.all().count(), 0)
|
||||
self.assertEqual(Document.objects.all().count(), 1)
|
||||
self.assertIsNone(Document.objects.all().first().correspondent)
|
||||
@@ -1,16 +1,18 @@
|
||||
from django.http import HttpResponse
|
||||
from django.views.decorators.csrf import csrf_exempt
|
||||
from django.http import HttpResponse, HttpResponseBadRequest
|
||||
from django.views.generic import DetailView, FormView, TemplateView
|
||||
from django_filters.rest_framework import DjangoFilterBackend
|
||||
from rest_framework.filters import SearchFilter, OrderingFilter
|
||||
from django.conf import settings
|
||||
|
||||
from paperless.db import GnuPG
|
||||
from paperless.mixins import SessionOrBasicAuthMixin
|
||||
from paperless.views import StandardPagination
|
||||
from rest_framework.filters import OrderingFilter, SearchFilter
|
||||
from rest_framework.mixins import (
|
||||
DestroyModelMixin,
|
||||
ListModelMixin,
|
||||
RetrieveModelMixin,
|
||||
UpdateModelMixin
|
||||
)
|
||||
from rest_framework.pagination import PageNumberPagination
|
||||
from rest_framework.permissions import IsAuthenticated
|
||||
from rest_framework.viewsets import (
|
||||
GenericViewSet,
|
||||
@@ -27,19 +29,11 @@ from .serialisers import (
|
||||
LogSerializer,
|
||||
TagSerializer
|
||||
)
|
||||
from .mixins import SessionOrBasicAuthMixin
|
||||
|
||||
|
||||
class IndexView(TemplateView):
|
||||
|
||||
template_name = "documents/index.html"
|
||||
|
||||
def get_context_data(self, **kwargs):
|
||||
print(kwargs)
|
||||
print(self.request.GET)
|
||||
print(self.request.POST)
|
||||
return TemplateView.get_context_data(self, **kwargs)
|
||||
|
||||
|
||||
class FetchView(SessionOrBasicAuthMixin, DetailView):
|
||||
|
||||
@@ -56,23 +50,34 @@ class FetchView(SessionOrBasicAuthMixin, DetailView):
|
||||
Document.TYPE_JPG: "image/jpeg",
|
||||
Document.TYPE_GIF: "image/gif",
|
||||
Document.TYPE_TIF: "image/tiff",
|
||||
Document.TYPE_CSV: "text/csv",
|
||||
Document.TYPE_MD: "text/markdown",
|
||||
Document.TYPE_TXT: "text/plain"
|
||||
}
|
||||
|
||||
if self.kwargs["kind"] == "thumb":
|
||||
return HttpResponse(
|
||||
GnuPG.decrypted(self.object.thumbnail_file),
|
||||
self._get_raw_data(self.object.thumbnail_file),
|
||||
content_type=content_types[Document.TYPE_PNG]
|
||||
)
|
||||
|
||||
response = HttpResponse(
|
||||
GnuPG.decrypted(self.object.source_file),
|
||||
self._get_raw_data(self.object.source_file),
|
||||
content_type=content_types[self.object.file_type]
|
||||
)
|
||||
response["Content-Disposition"] = 'attachment; filename="{}"'.format(
|
||||
self.object.file_name)
|
||||
|
||||
DISPOSITION = 'inline' if settings.INLINE_DOC else 'attachment'
|
||||
|
||||
response["Content-Disposition"] = '{}; filename="{}"'.format(
|
||||
DISPOSITION, self.object.file_name)
|
||||
|
||||
return response
|
||||
|
||||
def _get_raw_data(self, file_handle):
|
||||
if self.object.storage_type == Document.STORAGE_TYPE_UNENCRYPTED:
|
||||
return file_handle
|
||||
return GnuPG.decrypted(file_handle)
|
||||
|
||||
|
||||
class PushView(SessionOrBasicAuthMixin, FormView):
|
||||
"""
|
||||
@@ -81,21 +86,12 @@ class PushView(SessionOrBasicAuthMixin, FormView):
|
||||
|
||||
form_class = UploadForm
|
||||
|
||||
@classmethod
|
||||
def as_view(cls, **kwargs):
|
||||
return csrf_exempt(FormView.as_view(**kwargs))
|
||||
|
||||
def form_valid(self, form):
|
||||
return HttpResponse("1")
|
||||
form.save()
|
||||
return HttpResponse("1", status=202)
|
||||
|
||||
def form_invalid(self, form):
|
||||
return HttpResponse("0")
|
||||
|
||||
|
||||
class StandardPagination(PageNumberPagination):
|
||||
page_size = 25
|
||||
page_size_query_param = "page-size"
|
||||
max_page_size = 100000
|
||||
return HttpResponseBadRequest(str(form.errors))
|
||||
|
||||
|
||||
class CorrespondentViewSet(ModelViewSet):
|
||||
|
||||
@@ -3,16 +3,9 @@ import os
|
||||
import sys
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "paperless.settings")
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.management import execute_from_command_line
|
||||
|
||||
# The runserver and consumer need to have access to the passphrase, so it
|
||||
# must be entered at start time to keep it safe.
|
||||
if "runserver" in sys.argv or "document_consumer" in sys.argv:
|
||||
if not settings.PASSPHRASE:
|
||||
settings.PASSPHRASE = input(
|
||||
"settings.PASSPHRASE is unset. Input passphrase: ")
|
||||
|
||||
execute_from_command_line(sys.argv)
|
||||
|
||||
@@ -2,7 +2,7 @@ import os
|
||||
import shutil
|
||||
|
||||
from django.conf import settings
|
||||
from django.core.checks import Error, register, Warning
|
||||
from django.core.checks import Error, Warning, register
|
||||
|
||||
|
||||
@register()
|
||||
@@ -76,7 +76,12 @@ def binaries_check(app_configs, **kwargs):
|
||||
error = "Paperless can't find {}. Without it, consumption is impossible."
|
||||
hint = "Either it's not in your ${PATH} or it's not installed."
|
||||
|
||||
binaries = (settings.CONVERT_BINARY, settings.UNPAPER_BINARY, "tesseract")
|
||||
binaries = (
|
||||
settings.CONVERT_BINARY,
|
||||
settings.OPTIPNG_BINARY,
|
||||
settings.UNPAPER_BINARY,
|
||||
"tesseract"
|
||||
)
|
||||
|
||||
check_messages = []
|
||||
for binary in binaries:
|
||||
|
||||
@@ -3,7 +3,7 @@ import gnupg
|
||||
from django.conf import settings
|
||||
|
||||
|
||||
class GnuPG(object):
|
||||
class GnuPG:
|
||||
"""
|
||||
A handy singleton to use when handling encrypted files.
|
||||
"""
|
||||
@@ -11,15 +11,22 @@ class GnuPG(object):
|
||||
gpg = gnupg.GPG(gnupghome=settings.GNUPG_HOME)
|
||||
|
||||
@classmethod
|
||||
def decrypted(cls, file_handle):
|
||||
return cls.gpg.decrypt_file(
|
||||
file_handle, passphrase=settings.PASSPHRASE).data
|
||||
def decrypted(cls, file_handle, passphrase=None):
|
||||
|
||||
if not passphrase:
|
||||
passphrase = settings.PASSPHRASE
|
||||
|
||||
return cls.gpg.decrypt_file(file_handle, passphrase=passphrase).data
|
||||
|
||||
@classmethod
|
||||
def encrypted(cls, file_handle):
|
||||
def encrypted(cls, file_handle, passphrase=None):
|
||||
|
||||
if not passphrase:
|
||||
passphrase = settings.PASSPHRASE
|
||||
|
||||
return cls.gpg.encrypt_file(
|
||||
file_handle,
|
||||
recipients=None,
|
||||
passphrase=settings.PASSPHRASE,
|
||||
passphrase=passphrase,
|
||||
symmetric=True
|
||||
).data
|
||||
|
||||
14
src/paperless/middleware.py
Normal file
14
src/paperless/middleware.py
Normal file
@@ -0,0 +1,14 @@
|
||||
from django.utils.deprecation import MiddlewareMixin
|
||||
from .models import User
|
||||
|
||||
|
||||
class Middleware(MiddlewareMixin):
|
||||
"""
|
||||
This is a dummy authentication middleware class that creates what
|
||||
is roughly an Anonymous authenticated user so we can disable login
|
||||
and not interfere with existing user ID's. It's only used if
|
||||
login is disabled in paperless.conf (default is to require login)
|
||||
"""
|
||||
|
||||
def process_request(self, request):
|
||||
request.user = User()
|
||||
46
src/paperless/mixins.py
Normal file
46
src/paperless/mixins.py
Normal file
@@ -0,0 +1,46 @@
|
||||
from django.contrib.auth.mixins import AccessMixin
|
||||
from django.contrib.auth import authenticate, login
|
||||
import base64
|
||||
|
||||
|
||||
class SessionOrBasicAuthMixin(AccessMixin):
|
||||
"""
|
||||
Session or Basic Authentication mixin for Django.
|
||||
It determines if the requester is already logged in or if they have
|
||||
provided proper http-authorization and returning the view if all goes
|
||||
well, otherwise responding with a 401.
|
||||
|
||||
Base for mixin found here: https://djangosnippets.org/snippets/3073/
|
||||
"""
|
||||
|
||||
def dispatch(self, request, *args, **kwargs):
|
||||
|
||||
# check if user is authenticated via the session
|
||||
if request.user.is_authenticated:
|
||||
|
||||
# Already logged in, just return the view.
|
||||
return super(SessionOrBasicAuthMixin, self).dispatch(
|
||||
request, *args, **kwargs
|
||||
)
|
||||
|
||||
# apparently not authenticated via session, maybe via HTTP Basic?
|
||||
if 'HTTP_AUTHORIZATION' in request.META:
|
||||
auth = request.META['HTTP_AUTHORIZATION'].split()
|
||||
if len(auth) == 2:
|
||||
# NOTE: Support for only basic authentication
|
||||
if auth[0].lower() == "basic":
|
||||
authString = base64.b64decode(auth[1]).decode('utf-8')
|
||||
uname, passwd = authString.split(':')
|
||||
user = authenticate(username=uname, password=passwd)
|
||||
if user is not None:
|
||||
if user.is_active:
|
||||
login(request, user)
|
||||
request.user = user
|
||||
return super(
|
||||
SessionOrBasicAuthMixin, self
|
||||
).dispatch(
|
||||
request, *args, **kwargs
|
||||
)
|
||||
|
||||
# nope, really not authenticated
|
||||
return self.handle_no_permission()
|
||||
31
src/paperless/models.py
Normal file
31
src/paperless/models.py
Normal file
@@ -0,0 +1,31 @@
|
||||
from django.contrib.auth.models import User as DjangoUser
|
||||
|
||||
|
||||
class User:
|
||||
"""
|
||||
This is a dummy django User used with our middleware to disable
|
||||
login authentication if that is configured in paperless.conf
|
||||
"""
|
||||
|
||||
is_superuser = True
|
||||
is_active = True
|
||||
is_staff = True
|
||||
is_authenticated = True
|
||||
|
||||
@property
|
||||
def id(self):
|
||||
return DjangoUser.objects.order_by("pk").first().pk
|
||||
|
||||
@property
|
||||
def pk(self):
|
||||
return self.id
|
||||
|
||||
|
||||
"""
|
||||
NOTE: These are here as a hack instead of being in the User definition
|
||||
NOTE: above due to the way pycodestyle handles lamdbdas.
|
||||
NOTE: See https://github.com/PyCQA/pycodestyle/issues/379 for more.
|
||||
"""
|
||||
|
||||
User.has_module_perms = lambda *_: True
|
||||
User.has_perm = lambda *_: True
|
||||
@@ -4,10 +4,10 @@ Django settings for paperless project.
|
||||
Generated by 'django-admin startproject' using Django 1.9.
|
||||
|
||||
For more information on this file, see
|
||||
https://docs.djangoproject.com/en/1.9/topics/settings/
|
||||
https://docs.djangoproject.com/en/1.10/topics/settings/
|
||||
|
||||
For the full list of settings and their values, see
|
||||
https://docs.djangoproject.com/en/1.9/ref/settings/
|
||||
https://docs.djangoproject.com/en/1.10/ref/settings/
|
||||
"""
|
||||
|
||||
import os
|
||||
@@ -18,6 +18,16 @@ from dotenv import load_dotenv
|
||||
# Tap paperless.conf if it's available
|
||||
if os.path.exists("/etc/paperless.conf"):
|
||||
load_dotenv("/etc/paperless.conf")
|
||||
elif os.path.exists("/usr/local/etc/paperless.conf"):
|
||||
load_dotenv("/usr/local/etc/paperless.conf")
|
||||
|
||||
|
||||
def __get_boolean(key, default="NO"):
|
||||
"""
|
||||
Return a boolean value based on whatever the user has supplied in the
|
||||
environment based on whether the value "looks like" it's True or not.
|
||||
"""
|
||||
return bool(os.getenv(key, default).lower() in ("yes", "y", "1", "t", "true"))
|
||||
|
||||
|
||||
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
|
||||
@@ -25,7 +35,7 @@ BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||
|
||||
|
||||
# Quick-start development settings - unsuitable for production
|
||||
# See https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/
|
||||
# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
|
||||
|
||||
# The secret key has a default that should be fine so long as you're hosting
|
||||
# Paperless on a closed network. However, if you're putting this anywhere
|
||||
@@ -37,9 +47,9 @@ SECRET_KEY = os.getenv(
|
||||
|
||||
|
||||
# SECURITY WARNING: don't run with debug turned on in production!
|
||||
DEBUG = True
|
||||
DEBUG = __get_boolean("PAPERLESS_DEBUG", "YES")
|
||||
|
||||
LOGIN_URL = '/admin/login'
|
||||
LOGIN_URL = "admin:login"
|
||||
|
||||
ALLOWED_HOSTS = ["*"]
|
||||
|
||||
@@ -47,7 +57,8 @@ _allowed_hosts = os.getenv("PAPERLESS_ALLOWED_HOSTS")
|
||||
if _allowed_hosts:
|
||||
ALLOWED_HOSTS = _allowed_hosts.split(",")
|
||||
|
||||
|
||||
FORCE_SCRIPT_NAME = os.getenv("PAPERLESS_FORCE_SCRIPT_NAME")
|
||||
|
||||
# Application definition
|
||||
|
||||
INSTALLED_APPS = [
|
||||
@@ -58,29 +69,44 @@ INSTALLED_APPS = [
|
||||
"django.contrib.messages",
|
||||
"django.contrib.staticfiles",
|
||||
|
||||
"corsheaders",
|
||||
"django_extensions",
|
||||
|
||||
"documents.apps.DocumentsConfig",
|
||||
"reminders.apps.RemindersConfig",
|
||||
"paperless_tesseract.apps.PaperlessTesseractConfig",
|
||||
"paperless_text.apps.PaperlessTextConfig",
|
||||
|
||||
"flat_responsive",
|
||||
"django.contrib.admin",
|
||||
|
||||
"rest_framework",
|
||||
"crispy_forms",
|
||||
"django_filters",
|
||||
|
||||
]
|
||||
|
||||
MIDDLEWARE_CLASSES = [
|
||||
if os.getenv("PAPERLESS_INSTALLED_APPS"):
|
||||
INSTALLED_APPS += os.getenv("PAPERLESS_INSTALLED_APPS").split(",")
|
||||
|
||||
MIDDLEWARE = [
|
||||
'django.middleware.security.SecurityMiddleware',
|
||||
'django.contrib.sessions.middleware.SessionMiddleware',
|
||||
'corsheaders.middleware.CorsMiddleware',
|
||||
'django.middleware.common.CommonMiddleware',
|
||||
'django.middleware.csrf.CsrfViewMiddleware',
|
||||
'django.contrib.auth.middleware.AuthenticationMiddleware',
|
||||
'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
|
||||
'django.contrib.messages.middleware.MessageMiddleware',
|
||||
'django.middleware.clickjacking.XFrameOptionsMiddleware',
|
||||
]
|
||||
|
||||
# We allow CORS from localhost:8080
|
||||
CORS_ORIGIN_WHITELIST = tuple(os.getenv("PAPERLESS_CORS_ALLOWED_HOSTS", "localhost:8080").split(","))
|
||||
|
||||
# If auth is disabled, we just use our "bypass" authentication middleware
|
||||
if bool(os.getenv("PAPERLESS_DISABLE_LOGIN", "false").lower() in ("yes", "y", "1", "t", "true")):
|
||||
_index = MIDDLEWARE.index("django.contrib.auth.middleware.AuthenticationMiddleware")
|
||||
MIDDLEWARE[_index] = "paperless.middleware.Middleware"
|
||||
|
||||
ROOT_URLCONF = 'paperless.urls'
|
||||
|
||||
TEMPLATES = [
|
||||
@@ -103,7 +129,7 @@ WSGI_APPLICATION = 'paperless.wsgi.application'
|
||||
|
||||
|
||||
# Database
|
||||
# https://docs.djangoproject.com/en/1.9/ref/settings/#databases
|
||||
# https://docs.djangoproject.com/en/1.10/ref/settings/#databases
|
||||
|
||||
DATABASES = {
|
||||
"default": {
|
||||
@@ -118,17 +144,18 @@ DATABASES = {
|
||||
}
|
||||
}
|
||||
|
||||
if os.getenv("PAPERLESS_DBUSER") and os.getenv("PAPERLESS_DBPASS"):
|
||||
if os.getenv("PAPERLESS_DBUSER"):
|
||||
DATABASES["default"] = {
|
||||
"ENGINE": "django.db.backends.postgresql_psycopg2",
|
||||
"NAME": os.getenv("PAPERLESS_DBNAME", "paperless"),
|
||||
"USER": os.getenv("PAPERLESS_DBUSER"),
|
||||
"PASSWORD": os.getenv("PAPERLESS_DBPASS")
|
||||
}
|
||||
if os.getenv("PAPERLESS_DBPASS"):
|
||||
DATABASES["default"]["PASSWORD"] = os.getenv("PAPERLESS_DBPASS")
|
||||
|
||||
|
||||
# Password validation
|
||||
# https://docs.djangoproject.com/en/1.9/ref/settings/#auth-password-validators
|
||||
# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
|
||||
|
||||
AUTH_PASSWORD_VALIDATORS = [
|
||||
{
|
||||
@@ -147,7 +174,7 @@ AUTH_PASSWORD_VALIDATORS = [
|
||||
|
||||
|
||||
# Internationalization
|
||||
# https://docs.djangoproject.com/en/1.9/topics/i18n/
|
||||
# https://docs.djangoproject.com/en/1.10/topics/i18n/
|
||||
|
||||
LANGUAGE_CODE = 'en-us'
|
||||
|
||||
@@ -161,15 +188,15 @@ USE_TZ = True
|
||||
|
||||
|
||||
# Static files (CSS, JavaScript, Images)
|
||||
# https://docs.djangoproject.com/en/1.9/howto/static-files/
|
||||
# https://docs.djangoproject.com/en/1.10/howto/static-files/
|
||||
|
||||
STATIC_ROOT = os.getenv(
|
||||
"PAPERLESS_STATICDIR", os.path.join(BASE_DIR, "..", "static"))
|
||||
MEDIA_ROOT = os.getenv(
|
||||
"PAPERLESS_MEDIADIR", os.path.join(BASE_DIR, "..", "media"))
|
||||
|
||||
STATIC_URL = '/static/'
|
||||
MEDIA_URL = "/media/"
|
||||
STATIC_URL = os.getenv("PAPERLESS_STATIC_URL", "/static/")
|
||||
MEDIA_URL = os.getenv("PAPERLESS_MEDIA_URL", "/media/")
|
||||
|
||||
|
||||
# Paperless-specific stuff
|
||||
@@ -203,10 +230,13 @@ OCR_LANGUAGE = os.getenv("PAPERLESS_OCR_LANGUAGE", "eng")
|
||||
# The amount of threads to use for OCR
|
||||
OCR_THREADS = os.getenv("PAPERLESS_OCR_THREADS")
|
||||
|
||||
# OCR all documents?
|
||||
OCR_ALWAYS = __get_boolean("PAPERLESS_OCR_ALWAYS")
|
||||
|
||||
# If this is true, any failed attempts to OCR a PDF will result in the PDF
|
||||
# being indexed anyway, with whatever we could get. If it's False, the file
|
||||
# will simply be left in the CONSUMPTION_DIR.
|
||||
FORGIVING_OCR = bool(os.getenv("PAPERLESS_FORGIVING_OCR", "YES").lower() in ("yes", "y", "1", "t", "true"))
|
||||
FORGIVING_OCR = __get_boolean("PAPERLESS_FORGIVING_OCR")
|
||||
|
||||
# GNUPG needs a home directory for some reason
|
||||
GNUPG_HOME = os.getenv("HOME", "/tmp")
|
||||
@@ -217,6 +247,9 @@ CONVERT_TMPDIR = os.getenv("PAPERLESS_CONVERT_TMPDIR")
|
||||
CONVERT_MEMORY_LIMIT = os.getenv("PAPERLESS_CONVERT_MEMORY_LIMIT")
|
||||
CONVERT_DENSITY = os.getenv("PAPERLESS_CONVERT_DENSITY")
|
||||
|
||||
# OptiPNG
|
||||
OPTIPNG_BINARY = os.getenv("PAPERLESS_OPTIPNG_BINARY", "optipng")
|
||||
|
||||
# Unpaper
|
||||
UNPAPER_BINARY = os.getenv("PAPERLESS_UNPAPER_BINARY", "unpaper")
|
||||
|
||||
@@ -226,42 +259,46 @@ SCRATCH_DIR = os.getenv("PAPERLESS_SCRATCH_DIR", "/tmp/paperless")
|
||||
# This is where Paperless will look for PDFs to index
|
||||
CONSUMPTION_DIR = os.getenv("PAPERLESS_CONSUMPTION_DIR")
|
||||
|
||||
# (This setting is ignored on Linux where inotify is used instead of a
|
||||
# polling loop.)
|
||||
# The number of seconds that Paperless will wait between checking
|
||||
# CONSUMPTION_DIR. If you tend to write documents to this directory very
|
||||
# slowly, you may want to use a higher value than the default.
|
||||
CONSUMER_LOOP_TIME = int(os.getenv("PAPERLESS_CONSUMER_LOOP_TIME", 10))
|
||||
|
||||
# If you want to use IMAP mail consumption, populate this with useful values.
|
||||
# If you leave HOST set to None, we assume you're not going to use this
|
||||
# feature.
|
||||
MAIL_CONSUMPTION = {
|
||||
"HOST": os.getenv("PAPERLESS_CONSUME_MAIL_HOST"),
|
||||
"PORT": os.getenv("PAPERLESS_CONSUME_MAIL_PORT"),
|
||||
"USERNAME": os.getenv("PAPERLESS_CONSUME_MAIL_USER"),
|
||||
"PASSWORD": os.getenv("PAPERLESS_CONSUME_MAIL_PASS"),
|
||||
"USE_SSL": os.getenv("PAPERLESS_CONSUME_MAIL_USE_SSL", "y").lower() == "y", # If True, use SSL/TLS to connect
|
||||
"INBOX": "INBOX" # The name of the inbox on the server
|
||||
}
|
||||
|
||||
# This is used to encrypt the original documents and decrypt them later when
|
||||
# you want to download them. Set it and change the permissions on this file to
|
||||
# 0600, or set it to `None` and you'll be prompted for the passphrase at
|
||||
# runtime. The default looks for an environment variable.
|
||||
# DON'T FORGET TO SET THIS as leaving it blank may cause some strange things
|
||||
# with GPG, including an interesting case where it may "encrypt" zero-byte
|
||||
# files.
|
||||
# Pre-2.x versions of Paperless stored your documents locally with GPG
|
||||
# encryption, but that is no longer the default. This behaviour is still
|
||||
# available, but it must be explicitly enabled by setting
|
||||
# `PAPERLESS_PASSPHRASE` in your environment or config file. The default is to
|
||||
# store these files unencrypted.
|
||||
#
|
||||
# Translation:
|
||||
# * If you're a new user, you can safely ignore this setting.
|
||||
# * If you're upgrading from 1.x, this must be set, OR you can run
|
||||
# `./manage.py change_storage_type gpg unencrypted` to decrypt your files,
|
||||
# after which you can unset this value.
|
||||
PASSPHRASE = os.getenv("PAPERLESS_PASSPHRASE")
|
||||
|
||||
# If you intend to use the "API" to push files into the consumer, you'll need
|
||||
# to provide a shared secret here. Leaving this as the default will disable
|
||||
# the API.
|
||||
SHARED_SECRET = os.getenv("PAPERLESS_SHARED_SECRET", "")
|
||||
|
||||
# Trigger a script after every successful document consumption?
|
||||
PRE_CONSUME_SCRIPT = os.getenv("PAPERLESS_PRE_CONSUME_SCRIPT")
|
||||
POST_CONSUME_SCRIPT = os.getenv("PAPERLESS_POST_CONSUME_SCRIPT")
|
||||
|
||||
# Whether to display a selected document inline, or download it as attachment:
|
||||
INLINE_DOC = __get_boolean("PAPERLESS_INLINE_DOC")
|
||||
|
||||
# The number of items on each page in the web UI. This value must be a
|
||||
# positive integer, but if you don't define one in paperless.conf, a default of
|
||||
# 100 will be used.
|
||||
PAPERLESS_LIST_PER_PAGE = int(os.getenv("PAPERLESS_LIST_PER_PAGE", 100))
|
||||
|
||||
FY_START = os.getenv("PAPERLESS_FINANCIAL_YEAR_START")
|
||||
FY_END = os.getenv("PAPERLESS_FINANCIAL_YEAR_END")
|
||||
|
||||
# Specify the default date order (for autodetected dates)
|
||||
DATE_ORDER = os.getenv("PAPERLESS_DATE_ORDER", "DMY")
|
||||
|
||||
# Specify for how many years a correspondent is considered recent. Recent
|
||||
# correspondents will be shown in a separate "Recent correspondents" filter as
|
||||
# well. Set to 0 to disable this filter.
|
||||
PAPERLESS_RECENT_CORRESPONDENT_YEARS = int(os.getenv(
|
||||
"PAPERLESS_RECENT_CORRESPONDENT_YEARS", 0))
|
||||
|
||||
@@ -1,47 +1,38 @@
|
||||
"""paperless URL Configuration
|
||||
|
||||
The `urlpatterns` list routes URLs to views. For more information please see:
|
||||
https://docs.djangoproject.com/en/1.9/topics/http/urls/
|
||||
Examples:
|
||||
Function views
|
||||
1. Add an import: from my_app import views
|
||||
2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')
|
||||
Class-based views
|
||||
1. Add an import: from other_app.views import Home
|
||||
2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')
|
||||
Including another URLconf
|
||||
1. Add an import: from blog import urls as blog_urls
|
||||
2. Import the include() function: from django.conf.urls import url, include
|
||||
3. Add a URL to urlpatterns: url(r'^blog/', include(blog_urls))
|
||||
"""
|
||||
from django.conf import settings
|
||||
from django.conf.urls import url, static, include
|
||||
from django.conf.urls import include, static, url
|
||||
from django.contrib import admin
|
||||
|
||||
from django.urls import reverse_lazy
|
||||
from django.views.decorators.csrf import csrf_exempt
|
||||
from django.views.generic import RedirectView
|
||||
from rest_framework.routers import DefaultRouter
|
||||
|
||||
from documents.views import (
|
||||
IndexView, FetchView, PushView,
|
||||
CorrespondentViewSet, TagViewSet, DocumentViewSet, LogViewSet
|
||||
CorrespondentViewSet,
|
||||
DocumentViewSet,
|
||||
FetchView,
|
||||
LogViewSet,
|
||||
PushView,
|
||||
TagViewSet
|
||||
)
|
||||
from reminders.views import ReminderViewSet
|
||||
|
||||
router = DefaultRouter()
|
||||
router.register(r'correspondents', CorrespondentViewSet)
|
||||
router.register(r'tags', TagViewSet)
|
||||
router.register(r'documents', DocumentViewSet)
|
||||
router.register(r'logs', LogViewSet)
|
||||
router.register(r"correspondents", CorrespondentViewSet)
|
||||
router.register(r"documents", DocumentViewSet)
|
||||
router.register(r"logs", LogViewSet)
|
||||
router.register(r"reminders", ReminderViewSet)
|
||||
router.register(r"tags", TagViewSet)
|
||||
|
||||
urlpatterns = [
|
||||
|
||||
# API
|
||||
url(
|
||||
r"^api/auth/",
|
||||
include('rest_framework.urls', namespace="rest_framework")
|
||||
include(
|
||||
('rest_framework.urls', 'rest_framework'),
|
||||
namespace="rest_framework")
|
||||
),
|
||||
url(r"^api/", include(router.urls, namespace="drf")),
|
||||
|
||||
# Normal pages (coming soon)
|
||||
# url(r"^$", IndexView.as_view(), name="index"),
|
||||
url(r"^api/", include((router.urls, 'drf'), namespace="drf")),
|
||||
|
||||
# File downloads
|
||||
url(
|
||||
@@ -50,11 +41,21 @@ urlpatterns = [
|
||||
name="fetch"
|
||||
),
|
||||
|
||||
# File uploads
|
||||
url(r"^push$", csrf_exempt(PushView.as_view()), name="push"),
|
||||
|
||||
# The Django admin
|
||||
url(r"admin/", admin.site.urls),
|
||||
url(r"", admin.site.urls), # This is going away
|
||||
|
||||
# Redirect / to /admin
|
||||
url(r"^$", RedirectView.as_view(
|
||||
permanent=True, url=reverse_lazy("admin:index"))),
|
||||
|
||||
] + static.static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
|
||||
|
||||
if settings.SHARED_SECRET:
|
||||
urlpatterns.insert(0, url(r"^push$", PushView.as_view(), name="push"))
|
||||
# Text in each page's <h1> (and above login form).
|
||||
admin.site.site_header = 'Paperless'
|
||||
# Text at the end of each page's <title>.
|
||||
admin.site.site_title = 'Paperless'
|
||||
# Text at the top of the admin index page.
|
||||
admin.site.index_title = 'Paperless administration'
|
||||
|
||||
@@ -1 +1 @@
|
||||
__version__ = (0, 3, 5)
|
||||
__version__ = (2, 5, 0)
|
||||
|
||||
7
src/paperless/views.py
Normal file
7
src/paperless/views.py
Normal file
@@ -0,0 +1,7 @@
|
||||
from rest_framework.pagination import PageNumberPagination
|
||||
|
||||
|
||||
class StandardPagination(PageNumberPagination):
|
||||
page_size = 25
|
||||
page_size_query_param = "page-size"
|
||||
max_page_size = 100000
|
||||
@@ -4,7 +4,7 @@ WSGI config for paperless project.
|
||||
It exposes the WSGI callable as a module-level variable named ``application``.
|
||||
|
||||
For more information on this file, see
|
||||
https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/
|
||||
https://docs.djangoproject.com/en/1.10/howto/deployment/wsgi/
|
||||
"""
|
||||
|
||||
import os
|
||||
|
||||
0
src/paperless_tesseract/__init__.py
Normal file
0
src/paperless_tesseract/__init__.py
Normal file
16
src/paperless_tesseract/apps.py
Normal file
16
src/paperless_tesseract/apps.py
Normal file
@@ -0,0 +1,16 @@
|
||||
from django.apps import AppConfig
|
||||
|
||||
|
||||
class PaperlessTesseractConfig(AppConfig):
|
||||
|
||||
name = "paperless_tesseract"
|
||||
|
||||
def ready(self):
|
||||
|
||||
from documents.signals import document_consumer_declaration
|
||||
|
||||
from .signals import ConsumerDeclaration
|
||||
|
||||
document_consumer_declaration.connect(ConsumerDeclaration.handle)
|
||||
|
||||
AppConfig.ready(self)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user